[лЕЉлђЄлґДмДЭ] Segmentation based lyrics-audio alignment using dynamic programming
вАҐ
2 likesвАҐ45 views

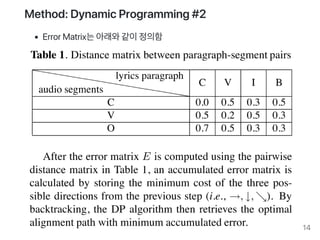
2008лЕДмЧР л∞ЬнСЬнХЬ SEGMENTATION-BASED LYRICS-AUDIO ALIGNMENT USING DYNAMIC PROGRAMMINGлЭЉлКФ лЕЉлђЄмЭД лґДмДЭнЫД к∞ДлЮµнЮИ лВімЪ©мЭД м†Хл¶ђнХЬлЛ§.