










Self Rating Research Paper
- 1. An Evaluation of the Impact of Sharing Self Ratings and Performance Standards with Other Raters as a Stimulus for Gathering 360 Ratings Patrick Hauenstein, Ph.D. President, Omni Leadership OMNI LEADERSHIP 620 Mendelssohn Avenue North Suite 156 Golden Valley, MN 55427 952.426.6100 www.omnilx.com
- 2. An Evaluation of the Impact of Sharing Self Ratings and Performance Standards with Other Raters as a Stimulus for Gathering 360 Ratings Patrick Hauenstein, Ph.D. President, Omni Leadership Research Overview The underlying assumption behind developmental 360 feedback systems is that an individualŌĆÖs self -awareness and perceived need for change will be enhanced by a systematic process of introspection and the review and comparison of ratings from others (Church & Bracken, 1997). However, traditional multi-rater approaches have shown a low level of agreement between self and ŌĆ£Others'ŌĆØ ratings. Self- ratings are typically higher than ŌĆ£Others'ŌĆØ ratings by as much as one half a standard deviation (Harris & Schaubroeck, 1988). This presents a challenging feedback situation where there is little agreement between self- perceptions and others' perceptions and others' ratings are generally much lower. Individuals may discount the ratings of others' or become defensive and de-motivated by the lower rating values. Clearly, self-awareness is a key ingredient for performance improvement. The degree to which a discrepancy exists between an individualŌĆÖs self- rating and the average rating made by ŌĆ£Others'ŌĆØ in a 360 process has been conceptualized as an indication of the amount of self-awareness possessed by the individual. Small differences are an indication of high self-awareness while large differences would be seen as indicative of low self-awareness. In addition to self-awareness, other factors have also been shown to have a systematic effect on differences between self and ŌĆ£Others'ŌĆØ ratings. The degree of direct contact between raters and the target individual can contribute to rating differences (Pollack & Pollack, 1996). The nature of the competency being rated can also contribute to differences between self and others' ratings. Lower levels of agreement are associated with ambiguous (difficult to observe) competencies, higher levels of agreement are associated with more concrete (observable) competencies (Dai, Stiles, Hallenbeck, & DeMeuse, 2007). High levels of self ŌĆō others agreement have been associated with a number of positive outcomes relevant for human resource practitioners. Some of these positive outcomes include perceived need for change (London & Smither, 1995), performance improvement after feedback (Atwater & Yazmmarino, 1992; Atwater et al., 2005; Johnson & Ferstl, 1999) and leadership effectiveness (Atwater, Rouch, & Fischthal, 1995). While self-ratings are typically viewed as unreliable and excluded in the calculation of competency performance in 360 feedback reports, there is evidence that self-ratings can be reliable and valid measures in certain circumstances. In a study conducted by the US Army Research Institute, self- ratings were found to have a stronger correlation with leadership ability than either peer or superior ratings (Psotka, Legree, & Gray, 2007). It was hypothesized that a structured process consisting of regular superior reviews facilitated an accurate introspection and was responsible for the strength of the correlation. 2
- 3. Omni has developed a unique approach to multi-rater surveys that was designed to maximize self-awareness and show higher congruence in self-others' ratings compared to traditional approaches. In this process, the individual rates their performance in comparison to structured performance standards for each behavior within a competency. The self -ratings are then shared with the other raters along with the performance standards to gather their perceptions of agreement or disagreement. The combination of structured performance standards with a transparent sharing of the ratings to others is felt to drive higher levels of introspection and self- awareness. The purpose of this study is to investigate the impact of this change in the traditional 360 process. Specifically, we would like to answer the following research questions: 1. How do individualŌĆÖs self-ratings influence other ratersŌĆÖ judgments (are self-ratings generally confirmed by other raters; are high self-rating individuals punished for arrogance; are low self-rating individuals rewarded for humility?) a. It is hypothesized that individuals who rate themselves lower will receive lower ŌĆ£Others'ŌĆØ ratings (indicating a higher rate of agreement with the self-rating and confirming a higher rate of accuracy in self-ratings) b. It is hypothesized that individuals who rate themselves higher will likewise receive higher ŌĆ£Others'ŌĆØ ratings (indicating a higher rate of agreement with the self-ratings and confirming a higher rate of accuracy in self-ratings) c. It is hypothesized that individuals who rate themselves in the middle range will likewise receive middle range ŌĆ£Others'ŌĆØ ratings (indicating a higher rate of agreement with the self-ratings and confirming a higher rate of accuracy in self-ratings) 2. What is the distribution curve for Self-Ratings? How does it compare to the distribution curve based on ŌĆ£All Other Average RatingsŌĆØ? a. It is hypothesized that there will be significantly less inflation in self-ratings compared to traditional rating distributions and there will be no significant differences between the means for the two distributions. 3. Are there significant differences in the analysis of rating patterns for individual competencies? a. It is hypothesized there will be greater self-other differences for more ambiguous competencies that are less observable. 3
- 4. Method There were two 360 feedback projects. The first project included 62 individuals while the second project included 31 individuals. Calculations of descriptive statistics were made separately for each project. Calculations were also made separately for self-ratings only as well as ŌĆ£Others'ŌĆØ ratings (self -ratings excluded). First, means and standard deviations were calculated for each competency individually as well as for the average overall competency rating. The resulting table of results for each project is presented below: Table 1. Project one mean competency ratings and standard deviations by rating type ŌĆ£Others'ŌĆØ Self-Rating ŌĆ£Others'ŌĆØ Rating Competency Self-Rating Mean Standard Deviation Rating Mean Standard Deviation Inspires Hearts & 3.45 .62 3.50 .50 Minds of Team Innovative 3.48 .82 3.52 .56 Financial Acumen 3.52 .76 3.64 .63 Drive Income of 3.52 .72 3.56 .56 Business Line Credible and Passionate 3.55 .67 3.69 .52 Communicator Executes Strategic 3.55 .74 3.66 .59 Partnerships Strategic Thinking 3.60 .66 3.67 .56 Attracts and Develops 3.63 .71 3.61 .53 Talent Effective Collaboration 3.66 .68 3.72 .47 Change Leader 3.68 .72 3.69 .53 Customer Champion 3.74 .68 3.83 .52 Results Driven/ 3.76 .82 3.77 .59 Execution Judgment 3.87 .64 3.92 .43 Adaptability 3.95 .66 3.92 .45 Inspires Trust 4.05 .64 4.07 .48 Overall 3.67 .72 3.72 .55 4
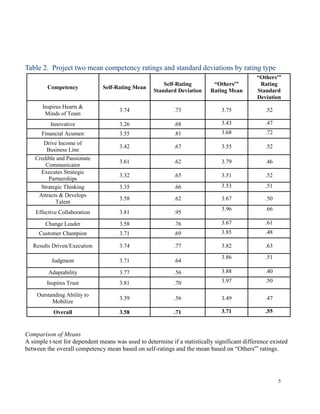
- 5. Table 2. Project two mean competency ratings and standard deviations by rating type ŌĆ£Others'ŌĆØ Self-Rating ŌĆ£Others'ŌĆØ Rating Competency Self-Rating Mean Standard Deviation Rating Mean Standard Deviation Inspires Hearts & 3.74 .73 3.75 .52 Minds of Team Innovative 3.26 .68 3.43 .47 Financial Acumen 3.55 .81 3.68 .72 Drive Income of 3.42 .67 3.55 .52 Business Line Credible and Passionate 3.61 .62 3.79 .46 Communicator Executes Strategic 3.32 .65 3.51 .52 Partnerships Strategic Thinking 3.35 .66 3.53 .51 Attracts & Develops 3.58 .62 3.67 .50 Talent 3.96 .66 Effective Collaboration 3.81 .95 Change Leader 3.58 .76 3.67 .61 Customer Champion 3.71 .69 3.85 .48 Results Driven/Execution 3.74 .77 3.82 .63 3.86 .51 Judgment 3.71 .64 Adaptability 3.77 .56 3.88 .40 Inspires Trust 3.81 .70 3.97 .50 Outstanding Ability to 3.39 .56 3.49 .47 Mobilize Overall 3.58 .71 3.71 .55 Comparison of Means A simple t-test for dependent means was used to determine if a statistically significant difference existed between the overall competency mean based on self-ratings and the mean based on ŌĆ£Others'ŌĆØ ratings. 5
- 6. The results are shown below for each project: Table 3. Project One T-test Results of Significant Differences in Means Based on Rating Type Self- t-value Significance of ŌĆ£Others'ŌĆØ Rating Rating Difference Overall Competency Performance Mean Mean 3.67 3.72 .6867 n.s. Table 4. Project Two T-test Results of Significant Differences in Means Based on Rating Type Self- t-value Significance ŌĆ£Others'ŌĆØ Rating Rating Overall Competency Performance Mean Mean 3.58 3.71 .9128 n.s. Identification of Competencies with Largest Differences Given the lack of an overall difference in means for either project and the probability of taking advantage of chance (finding a significant difference when there is none), individual T-tests for individual competencies were not performed. However, the competencies with the largest differences were identified. We identified the largest differences separately for project one and project two to determine if any surfaced differences were replicated across the two projects. Table 5. Largest Differences in Means for Individual Competencies ŌĆ£Others'ŌĆØ Rating Competency Self-Rating Mean Difference Mean Inspires Hearts & 3.45 3.75 -.30 Minds of Team Innovative 3.48 3.43 .05 Financial Acumen 3.52 3.68 -.16 Drive Income of 3.52 3.55 -.03 Business Line Credible and Passionate 3.55 3.79 -.24 Communicator Executes Strategic 3.55 3.51 .04 Partnerships Strategic Thinking 3.60 3.53 .07 Attracts and Develops Talent 3.63 3.67 -.04 Effective Collaboration 3.66 3.96 -.30 Change Leader 3.68 3.67 .01 Customer Champion 3.74 3.85 -.11 Results Driven/Execution 3.76 3.82 -.06 Judgment 3.87 3.86 .01 Adaptability 3.95 3.88 .07 Inspires Trust 4.05 3.97 .08 6
- 7. Table 6. Project two Largest Differences in Means Based for Individual Competencies ŌĆ£Others'ŌĆØ Rating Competency Self-Rating Mean Mean Difference Inspires Hearts & 3.74 3.75 -.01 Minds of Team Innovative 3.26 3.43 -.17 Financial Acumen 3.55 3.68 -.13 Drive Income of 3.42 3.55 -.13 Business Line Credible and Passionate 3.61 3.79 -.18 Communicator Executes Strategic 3.32 3.51 -.19 Partnerships Strategic Thinking 3.35 3.53 -.18 Attracts & Develops 3.58 3.67 -.09 Talent Effective Collaboration 3.81 3.96 -.15 Change Leader 3.58 3.67 -.09 Customer Champion 3.71 3.85 -.14 Results Driven/ 3.74 3.82 -.08 Execution Judgment 3.71 3.86 -.15 Adaptability 3.77 3.88 -.11 Inspires Trust 3.81 3.97 -.16 Outstanding Ability to 3.39 3.49 -.10 Mobilize Chi-Square Test of Association in Categorization Frequencies Next, categorization frequency counts were calculated separately for overall self-ratings and overall ŌĆ£Others'ŌĆØ ratings for each of three value range categories corresponding to low, solid, and high overall competency performance (based on default ranges for nine-block report). The resulting tables for each project are presented below: Table 7. Frequency of categorization of individuals into overall performance ranges based on overall competency self-ratings ŌĆō Project one Overall Competency Performance Ranges 1.00 ŌĆō 3.09 3.10 ŌĆō 3.99 4.00 ŌĆō 5.00 Frequency of Occurrence 4 44 14 7
- 8. Table 8. Frequency of categorization of individuals into overall performance ranges based on overall competency ŌĆ£others'ŌĆØ ratings ŌĆō Project one Overall Competency Performance Ranges 1.00 ŌĆō 3.09 3.10 ŌĆō 3.99 4.00 ŌĆō 5.00 Frequency of Occurrence 1 48 13 Table 9. Frequency of categorization of individuals into overall performance ranges based on overall competency self-ratings ŌĆō Project two Overall Performance Ranges 1.00 ŌĆō 3.09 3.10 ŌĆō 3.99 4.00 ŌĆō 5.00 Frequency of Occurrence 3 23 5 Table 10. Frequency of categorization of individuals into overall performance ranges based on overall competency ŌĆ£others'ŌĆØ ratings ŌĆō Project two Overall Performance Ranges 1.00 ŌĆō 3.09 3.10 ŌĆō 3.99 4.00 ŌĆō 5.00 Frequency of Occurrence 2 23 6 A chi-square test of association was used to measure the strength of association (agreement) between categorizations based on self- ratings and categorizations based on others' ratings. Data from both projects were combined for this analysis. The chi-square statistic is sensitive to how often individuals classify their own level of performance in agreement with how others classify their performance. The statistic is based on differences between observed and expected frequencies: The self-rating frequency serves as the expected frequency in this equation and the observed frequency is based on ŌĆ£Others'ŌĆØ frequency. These data are reflected in the table below: Table 11. Observed and expected category frequencies for three performance ranges Observed and Expected Frequencies for Performance Ranges 1.00 ŌĆō 3.09 3.10 ŌĆō 3.99 4.00 ŌĆō 5.00 O=3 O = 71 O = 19 E=7 E = 67 E = 19 Chi-Square value = 2.5245 Degrees of freedom = 2 Significance probability level = <.01 significant association 8
- 9. Correlation Between Overall Competency Scores Based on Self-Ratings and Overall Competency Scores Based on ŌĆ£Others'ŌĆØ Ratings We next evaluated the strength of correlation between overall competency scores based on self-ratings and overall competency ratings based on ŌĆ£Others'ŌĆØ ratings. Data from both projects were combined for this analysis. The Pearson Product Moment Correlation coefficient was computed using a deviation score method: Correlation value = .88 Degrees of freedom = 92 Significance probability level = <.01; significant correlation Impact of Extreme Self-Ratings on Categorization of Performance by Others Finally, individuals with extreme scores were categorized as either very low raters (self-rating of 3.00 or less) or very high raters (self-rating of 4.13 or more). It was then determined how frequently each type of rater was clas- sified into the three previously described performance ranges based on the average ŌĆ£others'ŌĆØ ratings. Data was combined for the two projects. The resulting table is presented below: Table 12. Categorization frequencies of rater types into performance ranges based on average ŌĆ£others'ŌĆØ ratings Performance Ranges Based On ŌĆ£Others'ŌĆØ Ratings 1.00 ŌĆō 3.09 3.10 ŌĆō 3.99 4.00 ŌĆō 5.00 Rater Types Lo Self Raters (5) 2 3 0 Hi Self Raters (10) 0 0 10 Note: All Lo raters placed in middle category based on ŌĆ£others'ŌĆØ ratings were rated below the mean of their re- spective project group (highest rating = 3.44) Results Hypothesis One: The Omni process will result in a high rate of agreement between how individuals rate their own competency performance and how others rate the same performance. This hypothesis was confirmed based on overall competency scores. The correlation of overall competency scores based on self-ratings with overall competency ratings based on ŌĆ£others'ŌĆØ ratings was highly significant. The obtained correlation is markedly higher than the low correlations reported based on traditional 360 processes. It appears that the Omni process does drive higher self ŌĆō other agreement. There was also a corresponding significant association in how individuals were categorized into performance categories based on self-ratings compared to ŌĆ£others'ŌĆØ ratings. A chi-square test of association proved to be significant. An inspection of observed versus expected 9
- 10. frequencies did show that individuals were more likely to classify themselves in lower performance categories than were other raters. Others' placed fewer individuals in the lowest performance category and more individuals in the middle category compared to the categorizations based on self-ratings. This would seem to indicate that individuals were more critical of their performance compared to others' perceptions. Again, this is markedly different than the typical findings reported for traditional 360 processes where self- ratings are significantly higher than others' ratings. It appears that the Omni process does drive a more critical review from individuals which results in lower self-ratings. An inspection of extreme self-ratings showed limited influence on the rating patterns of others. Others reacted to extreme ratings as being indicative of actual performance. Individuals who rated themselves very high were confirmed by others as being superior performers. While ŌĆ£others'ŌĆØ were reluctant to categorize low rating individuals in the lowest performance category, they did however confirm their performance was low compared to other individuals. Hypothesis 2: There will be no significant differences between the overall mean self-ratings and the overall mean of ŌĆ£others'ŌĆØ ratings. This hypothesis was confirmed. A statistical comparison of means showed no difference between self-rating means and ŌĆ£others'ŌĆØ ratings means for either project. Not only did the Omni process not result in overly inflated self-ratings, the mean self-ratings were actually slightly lower than the mean ratings of others. Again, this is a very different outcome compared to results reported for traditional 360 processes. It appears that the Omni process eliminates the problem of overly inflated self-ratings. However, the ŌĆ£others'ŌĆØ mean and distribution curve obtained with the Omni process was similar to results obtained in traditional 360 processes reflecting a positively skewed score distribution with an inflated mean (3.72) . The obtained distribution parameters indicate that in order to equate the lower performance range (low performance) with the upper performance range (high performance) used in this study, the lower range limit should be raised to 3.4 (one standard deviation below the mean). This would have resulted in 23 individuals being classified as ŌĆ£lowŌĆØ, 51 individuals being classified as ŌĆ£solidŌĆØ, and 19 individuals being classified as ŌĆ£highŌĆØ. However, in order to avoid the potentially de-motivating impact of being in a lower category, the current range limits may be satisfactory. Hypothesis 3: There will be larger mean differences between self and others' ratings for more ambiguous competencies. There was little supporting evidence for this hypothesis. The competency mean differences were generally small, consistent with the findings of high self-other agreement. An inspection of largest differences showed little consistency between the two projects. One competency, Credible and Passionate Communicator, appeared in both projects as having one of the larger differences in means. However, it could be argued that this competency should be highly observable and should not be considered as overly ambiguous. It appears that the Omni process generally drives high self-other agreement across all competencies. 10
- 11. Discussion This study provides supporting evidence for the benefits of sharing self-ratings and performance standards with other raters as a stimulus for gathering 360 ratings. This process seems to correct the past problems of overly inflated self-ratings and low self-other rating agreement reported for traditional 360 processes. It suggests that the transparency of the self-rating and the structure of performance standards may drive a more reflective approach that heightens the self-awareness of the individual. The benefits of this approach are most likely to be seen in performance feedback sessions and subsequent developmental planning. These sessions will not have the difficult task of overcoming potential defensiveness associated with presenting data showing others' perceptions being much lower than the individualŌĆÖs self-perceptions. The higher agreement between self and others should also make it easier for the individual to accept identified development needs as being accurately measured which should increase their willingness to act on the data. Finally, the more thoughtful introspection driven by the Omni process should help predispose the individual for receiving feedback since they have already thought carefully about their true strengths and development needs. There are likely to be other benefits to higher self-other agreement including a higher willingness to participate in future 360 surveys. The process should be seen as less threatening by the target individuals. The higher efficiency of the Omni process for gathering ŌĆ£others'ŌĆØ ratings should also increase overall willingness of all participants to use 360 surveys for tracking performance improvements and guiding developmental planning efforts. Cautions concerning the results of this study include the relatively small sample size (93) and the single organizational context of the study. Past research has shown both organizational context and leader effectiveness to moderate self-other agreement. It may be that the culture of this organization drives greater self-awareness or that the leaders included in the sample were generally higher performing leaders with high self-awareness. It should also be noted that self and other ratings are not independently obtained in the Omni process. The visibility of the self-ratings to others may have resulted in a tendency to avoid disagreeing with the target individual. 11
- 12. References Atwater, L.E, Rouch, P., & Fischtal, A. (1995). The influence of upward feedback on self and follower raters of leadership. Personnel Psychology, 48: 34-60. Atwater, L.E., Waldman, D., Ostroff, C., Robie, C., & Johnson, K.M. (2005). Self-other agreement: Comparing its relationship with performance in the U.S. and Europe. International Journal of Selection and Assessment. 13: 25-40. Atwater, L.E., & Yammarino, F.J. (1992). Does self-other agreement on leadership perceptions moderate the validity of leadership and performance predictions? Personnel Psychology, 45: 141-164. Church, A.H., & Bracken, D.W. (1997). Advancing the state of the art of 360-degree feedback: Guest editorsŌĆÖ comments on the research and practice of multirater assessment methods. Group & Organization Management, 22: 149-191. Dai, G., Stiles, P., Hallenbeck, G., & De Meuse, K.P. (2007). Self-other agreement on leadership competency ratings: The moderating effects of rater perspectives and rating ambiguity. Paper Presented at 2007 Annual Meeting of the Academy of Management. Harris, M.M., & Schaubroeck, J. (1988). A meta-analysis of self-supervisor, self-peer, and peer-supervisor ratings. Personnel Psychology, 41: 43-62. Johnson, J.W., & Ferstl, K.L. (1999). The effects of interrater and self-other agreement on performance improvement following upward feedback. Personnel Psychology, 52: 271-303. London, M., &Smither, J.W. (1995). Can multi-source feedback change perceptions of goal accomplishment, self-evaluations, and performance-related outcomes? Theory based applications and directions for research. Personnel Psychology, 48: 803-839. Pollack, D. M., & Pollack, L. J. (1996). Using 360┬░ feedback in performance appraisal. Public Personnel Management, 25, 507-528. Psotka, J., Legree, P.J., & Gray, D.M. (2007). Collaboration and self-assessment: How to combine 360 assessments to increase self-understanding. United States Army Research Institute for the Behavioral and Social Sciences. 12