Sentiment analysis
ŌĆóDownload as PPT, PDFŌĆó
2 likesŌĆó346 views

Progetto di Big Data sulla Sentiment Analysis per le elezioni comunicali a Napoli






![JSON Tweets
{"id"=>12296272736,
"text"=>
"An early look at Annotations:
http://groups.google.com/group/twitter-api-announce/browse_thread/thread/fa5da2608865453",
"created_at"=>"Fri Apr 16 17:55:46 +0000 2010",
"in_reply_to_user_id"=>nil,
"in_reply_to_screen_name"=>nil,
"in_reply_to_status_id"=>nil
"favorited"=>false,
"truncated"=>false,
"user"=>
{"id"=>6253282,
"screen_name"=>"twitterapi",
"name"=>"Twitter API",
"description"=>
"The Real Twitter API. I tweet about API changes, service issues and
happily answer questions about Twitter and our API. Don't get an answer? It's on my website.",
"url"=>"http://apiwiki.twitter.com",
"location"=>"San Francisco, CA",
"profile_background_color"=>"c1dfee",
"profile_background_image_url"=>
"http://a3.twimg.com/profile_background_images/59931895/twitterapi-background-new.png",
"profile_background_tile"=>false,
"profile_image_url"=>"http://a3.twimg.com/profile_images/689684365/api_normal.png",
"profile_link_color"=>"0000ff",
"profile_sidebar_border_color"=>"87bc44",
"profile_sidebar_fill_color"=>"e0ff92",
"profile_text_color"=>"000000",
"created_at"=>"Wed May 23 06:01:13 +0000 2007",
"contributors_enabled"=>true,
"favourites_count"=>1,
"statuses_count"=>1628,
"friends_count"=>13,
"time_zone"=>"Pacific Time (US & Canada)",
"utc_offset"=>-28800,
"lang"=>"en",
"protected"=>false,
"followers_count"=>100581,
"geo_enabled"=>true,
"notifications"=>false,
"following"=>true,
"verified"=>true},
"contributors"=>[3191321],
"geo"=>nil,
"coordinates"=>nil,
"place"=>
{"id"=>"2b6ff8c22edd9576",
"url"=>"http://api.twitter.com/1/geo/id/2b6ff8c22edd9576.json",
"name"=>"SoMa",
"full_name"=>"SoMa, San Francisco",
"place_type"=>"neighborhood",
"country_code"=>"US",
"country"=>"The United States of America",
"bounding_box"=>
{"coordinates"=>
[[[-122.42284884, 37.76893497],
[-122.3964, 37.76893497],
[-122.3964, 37.78752897],
[-122.42284884, 37.78752897]]],
"type"=>"Polygon"}},
"source"=>"web"}
The tweet's unique ID. These
IDs are roughly sorted &
developers should treat them
as opaque (http://bit.ly/dCkppc).
Text of the tweet.
Consecutive duplicate tweets
are rejected. 140 character
max (http://bit.ly/4ud3he).
Tweet's
creation
date.
DEPRECATED
The ID of an existing tweet that
this tweet is in reply to. Won't
be set unless the author of the
referenced tweet is mentioned.
The screen name &
user ID of replied to
tweet author.
Truncated to 140
characters. Only
possible from SMS.
Theauthorofthetweet.This
embeddedobjectcangetoutofsync.
Theauthor's
userID.
The author's
user name.
The author's
screen name.
The author's
biography.
The author's
URL.
The author's "location". This is a free-form text ’¼üeld, and
there are no guarantees on whether it can be geocoded.
Rendering information
for the author. Colors
are encoded in hex
values (RGB).
The creation date
for this account.
Whether this account has
contributors enabled
(http://bit.ly/50npuu). Number of
favorites this
user has.
Numberoftweets
thisuserhas.
Number of
users this user
is following.The timezone and offset
(in seconds) for this user.
The user's selected
language.
Whether this user is protected
or not. If the user is protected,
then this tweet is not visible
except to "friends".
Number of
followers for
this user.
Whetherthisuserhasgeo
enabled(http://bit.ly/4pFY77).
DEPRECATED
in this context
Whether this user
has a veri’¼üed badge.
Thegeotagonthistweetin
GeoJSON(http://bit.ly/b8L1Cp).
The contributors' (if any) user
IDs (http://bit.ly/50npuu).
DEPRECATED
The place associated with this
Tweet (http://bit.ly/b8L1Cp).
The place ID
The URL to fetch a detailed
polygon for this placeThe printable names of this place
The type of this
place - can be a
"neighborhood"
or "city"
The country this place is in
The bounding
box for this
place
The application
that sent this
tweet
Map of a Twitter Status Object
Raf’¼ü Krikorian <raffi@twitter.com>](https://image.slidesharecdn.com/sentimentanalysis-160722151032/85/Sentiment-analysis-8-320.jpg)


















Sentiment analysis
- 1. Twitter Sentimental Analysis Pagliaro Alessandro
- 2. Elezioni Comunali Napoli 2016
- 3. Sentiment Analysis Workflow Twitter Crawler
- 4. Per scaricare i tweet in maniera ŌĆ£legaleŌĆØ ├© possibile utilizzare 3 tipologie di API, attraverso chiavi generate durante la registazione a Twitter secondo il protocollo OAuth. ŌłŚRest API : permettono di ricavare informazioni sul proprio profilo (tweets, followers, info account ) senza alcuna limitazione temporale. ŌłŚSearch API : permettono di cercare qualsiasi tweet con limiti nellŌĆÖindicizzazione (circa 7 giorni). ŌłŚStreaming API : mi permettono di collezionare tutti i tweet che vengono postati in tempo reale. About Twitter
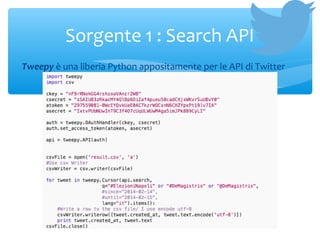
- 5. Tweepy ├© una liberia Python appositamente per le API di Twitter Sorgente 1 : Search API
- 6. ŌłŚLe Twitter API ufficiali non permettono di accedere a tweets pi├╣ vecchi di circa una settimana. Alcuni tools forniti da terze parti permettono di accedere allŌĆÖindicizzazione completa di Twitter (Gnip) ma richiedono dei costi proporzionati al numero di tweets da scaricare. ŌłŚPer evitare tutte queste limitazioni ├© stato usato un crawler. Questo programma si basa sulla normale ricerca che ├© possibile fare attraverso la Twitter Search da browser, infatti, specificando una ricerca e facendo lo scroll della pagine un JSON provider genera tutti i tweet secondo il loro ordine di pubblicazione senza alcuna limitazione temporale. Sorgente 2 : Twitter Crawler
- 7. ŌłŚ Query per hashtag e mentions (anche per emoticon) sui candidati ŌłŚ Recupero solo determinati campi (tweetid, username, tetx, date, etcŌĆ”) dagli oggetti JSON relativi ai tweets ŌłŚ Memorizzazione in un CSV definendo il Dataset Tweets
- 8. JSON Tweets {"id"=>12296272736, "text"=> "An early look at Annotations: http://groups.google.com/group/twitter-api-announce/browse_thread/thread/fa5da2608865453", "created_at"=>"Fri Apr 16 17:55:46 +0000 2010", "in_reply_to_user_id"=>nil, "in_reply_to_screen_name"=>nil, "in_reply_to_status_id"=>nil "favorited"=>false, "truncated"=>false, "user"=> {"id"=>6253282, "screen_name"=>"twitterapi", "name"=>"Twitter API", "description"=> "The Real Twitter API. I tweet about API changes, service issues and happily answer questions about Twitter and our API. Don't get an answer? It's on my website.", "url"=>"http://apiwiki.twitter.com", "location"=>"San Francisco, CA", "profile_background_color"=>"c1dfee", "profile_background_image_url"=> "http://a3.twimg.com/profile_background_images/59931895/twitterapi-background-new.png", "profile_background_tile"=>false, "profile_image_url"=>"http://a3.twimg.com/profile_images/689684365/api_normal.png", "profile_link_color"=>"0000ff", "profile_sidebar_border_color"=>"87bc44", "profile_sidebar_fill_color"=>"e0ff92", "profile_text_color"=>"000000", "created_at"=>"Wed May 23 06:01:13 +0000 2007", "contributors_enabled"=>true, "favourites_count"=>1, "statuses_count"=>1628, "friends_count"=>13, "time_zone"=>"Pacific Time (US & Canada)", "utc_offset"=>-28800, "lang"=>"en", "protected"=>false, "followers_count"=>100581, "geo_enabled"=>true, "notifications"=>false, "following"=>true, "verified"=>true}, "contributors"=>[3191321], "geo"=>nil, "coordinates"=>nil, "place"=> {"id"=>"2b6ff8c22edd9576", "url"=>"http://api.twitter.com/1/geo/id/2b6ff8c22edd9576.json", "name"=>"SoMa", "full_name"=>"SoMa, San Francisco", "place_type"=>"neighborhood", "country_code"=>"US", "country"=>"The United States of America", "bounding_box"=> {"coordinates"=> [[[-122.42284884, 37.76893497], [-122.3964, 37.76893497], [-122.3964, 37.78752897], [-122.42284884, 37.78752897]]], "type"=>"Polygon"}}, "source"=>"web"} The tweet's unique ID. These IDs are roughly sorted & developers should treat them as opaque (http://bit.ly/dCkppc). Text of the tweet. Consecutive duplicate tweets are rejected. 140 character max (http://bit.ly/4ud3he). Tweet's creation date. DEPRECATED The ID of an existing tweet that this tweet is in reply to. Won't be set unless the author of the referenced tweet is mentioned. The screen name & user ID of replied to tweet author. Truncated to 140 characters. Only possible from SMS. Theauthorofthetweet.This embeddedobjectcangetoutofsync. Theauthor's userID. The author's user name. The author's screen name. The author's biography. The author's URL. The author's "location". This is a free-form text ’¼üeld, and there are no guarantees on whether it can be geocoded. Rendering information for the author. Colors are encoded in hex values (RGB). The creation date for this account. Whether this account has contributors enabled (http://bit.ly/50npuu). Number of favorites this user has. Numberoftweets thisuserhas. Number of users this user is following.The timezone and offset (in seconds) for this user. The user's selected language. Whether this user is protected or not. If the user is protected, then this tweet is not visible except to "friends". Number of followers for this user. Whetherthisuserhasgeo enabled(http://bit.ly/4pFY77). DEPRECATED in this context Whether this user has a veri’¼üed badge. Thegeotagonthistweetin GeoJSON(http://bit.ly/b8L1Cp). The contributors' (if any) user IDs (http://bit.ly/50npuu). DEPRECATED The place associated with this Tweet (http://bit.ly/b8L1Cp). The place ID The URL to fetch a detailed polygon for this placeThe printable names of this place The type of this place - can be a "neighborhood" or "city" The country this place is in The bounding box for this place The application that sent this tweet Map of a Twitter Status Object Raf’¼ü Krikorian <raffi@twitter.com>
- 9. Dataset : 1 Maggio/ 9Giugno
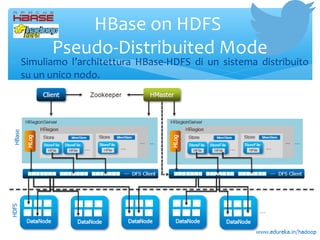
- 10. ŌłŚ Hbase ├© un database distribuito column-oriented usato sulla sommit├Ā di HDFS. ŌłŚ Il suo data model colonnare ├© simile a Google Big Table ed ├© progettato per fornire un acceso rapido in lettura/scrittura ad un enorme quanit├Ā di dati memorizzati in HDFS (Hadoop File System). ŌłŚ HBase fornisce una scalabilit├Ā orizzontale lineare. ŌłŚ Possiede meccanismi di failover automatico (reliability, availability) ŌłŚ Garantisce letture e scritture consistenti. (timestamp) ŌłŚ EŌĆÖ scritto in Java ed ├© possibile sfruttarlo attraverso API client Java. ŌłŚ Fornisce meccanismi di replicazione dei dati. (HDFS ŌĆō fattore 3 ) ŌłŚ Nasce perch├© HDFS consente un accesso solo sequenziale ai dati. HBase
- 11. HBase on HDFS Pseudo-Distribuited Mode ŌłŚ Simuliamo lŌĆÖarchitettura HBase-HDFS di un sistema distribuito su un unico nodo.
- 12. ŌłŚ Master-Slave : ├© costruito sulla sommit├Ā di HDFS, si adatta alla sua architettura e ne sfrutta I benefici di scale out e affidabilit├Ā. (HMaster-Namenode e HRegionServer-Datanode). ŌłŚ Random access: usa meccanismi in-memory (MemStore) e di log per garantire letture e scritture performanti e affidabili. ŌłŚ ColumnŌĆōOriented data model: memorizza le tabelle per column family in ogni HStore, perci├▓ ├© possibile definire un data model che sfrutti I vantaggi di queste tecniche di memorizzazione. ŌłŚ Auto-Sharding: allŌĆÖinterno di ogni HRegionServer vengono memorizzate le tabelle per column family in range di row_id ordinati allŌĆÖinterno delle HRegion, man mano che queste si riempiono ne vengono definite di nuove su cui ridistribuire I dati. HBase: Pro
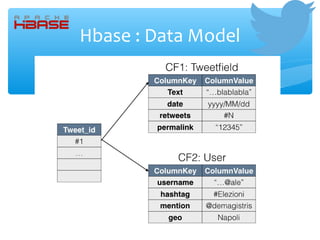
- 13. Hbase : Data Model
- 14. ŌłŚ HBase fornisce 5 operazioni di base sui dati: Put, Get, Delete, Scan e Increment. ŌłŚ HBase fornisce sia delle API Java sia altre API di tipo Thrift, Avro, REST e la Shell. (No SQL-like) ŌłŚ API Java: Per lŌĆÖinserimento dei dati ├© stata usata la classe Put dopo aver creato la HTable, mentre per la lettura la Scan (a cui ├© stato settato un filter sulla data, per poter ottenere i tweet giornalieri su cui ciclare). HBase client interface
- 15. Hbase : Put
- 17. ŌłŚ Il vocabolario ├© stato ricavato dalla repository GitHub del progetto openNER (Open Polarity Enhanced Name Entity Recognition) che punta al supporto dei tool di natural processing language. ŌłŚ https://github.com/opener-project/public-sentiment-lexicons/t ŌłŚ Attraverso il WordCount in MapReduce sul Dataset contente i tweets sono state recuperati gli hashtag e le emoticon pi├╣ utilizzate ed aggiunte al Vocabolario. Sentiment: VocabolarioIta
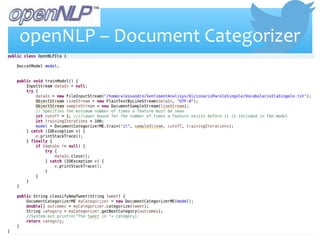
- 19. ŌłŚ Apache OpenNLP ├© una libreria open-source di machine learning che permette di elaborare testi in linguaggio naturale. ŌłŚ Alcuni delle funzionalit├Ā che supporta sono: ŌłŚ Tokenization ŌłŚ Sentence segmentation ŌłŚ Part-of-speech tagging ŌłŚ Named entity extraction ŌłŚ Document categorizer Sentiment: OpenNLP
- 20. ŌłŚ Questa funzionalit├Ā permette di classificare del testo in categorie predefinite, questo ├© possibile attraverso un algoritmo di massima entropia (MaxEnt). 1. LŌĆÖentropia viene usata nel contesto della teoria dellŌĆÖinformazione per misurare lŌĆÖincertezza del contenuto informativo, pi├╣ ho incertezza pi├╣ ho informazione 2. LŌĆÖalgoritmo prevede quindi di addestrare il nostro modello con un training set etichettato (VocabolarioIta) con un buon livello di entropia. 3. Nella fase di addestramento del modello possiamo regolare alcuni paramenti (cutoff, iterations). 4.Alla fine dellŌĆÖaddestramento, il modello analizzando il singolo tweet ├© capace di classificarlo (positive, negative). openNLP ŌĆō Document Categorizer
- 21. openNLP ŌĆō Document Categorizer
- 22. Sentiment: Algoritmo ŌłŚ Selezionando i tweet per ogni candidato e per ogni giorno, ├© stato determinato: ŌłŚ Un sentimento non normalizzato e pesato per retweets ŌłŚ Un sentimento normalizzato e pesato per retweets ŌłŚ Se non ci sono retweets la formula si riduce a
- 24. MicroStrategy ŌłŚ MicroStrategy ├© un provider di soluzioni di BI, mobile software e cloud-based services. ŌłŚ Nel Magic Quadrant di Gartnet ├© collocato tra i Visionaries. ŌłŚ Fornisce solo soluzioni di BI ŌĆ£puroŌĆØ. ŌłŚ Si basa su un sistema di OLAP relazionale (ROLAP) che permette agli utenti di analizzare lŌĆÖintero database relazionale a tutti i ŌłŚ La sua piattaforma di BI permette di ottenere dashboard interattive, scorecard, report altamente formattati, query ad hoc, soglie e alert.
- 25. Risultati : Eventi influenti ŌłŚ Per analizzare i risultati ├© possibile fare riferimento ad una serie di eventi che possono aver condizionato il sentimento in uno dei due modi ŌłŚ 9 maggio - DeMagistris: ŌĆ£Mi hanno strappato la toga ma non possono strapparmi l'anima. Renzi, vattene a casa! Devi avere paura! Ti devi cagare sottoŌĆØ. ŌłŚ 25/30 maggio - http://www.liberiamonapoli.it/pure-de-magistris-tiene- famiglia/ ŌłŚ 27 maggio - Berlusconi a Napoli per Lettieri ŌłŚ 3 Giugno - Renzi a Napoli per Valeria Valente
- 26. Risultati
- 27. Risultati
- 28. Risultati
Editor's Notes
- While Twitter displays no advertising, advertisers can target users based on their history of tweets and may quote tweets in ads directed specifically to the user.