











![│§Ų┌ż╬šnŅ}
Ī± HTMLż“ĮŌ╬÷ż╣żļ▓┐ĘųżŽ║╬Č╚żŌĖ─╔ŲżĘżŲąņĪ®ż╦
ŲĘ┘|ż“╔Žż▓żŲżżż»▒žę¬ż¼żóż├ż┐
Ī żĮż╬Č╚ż╦į┘ź»źĒ®`źļż╩ż¾żŲżõż├żŲżķżņż╩żż
Ī± źŪ®`ź┐┴┐żŽēł╝ėż╬ę╗═ŠżŪŽļČ©┴┐ż“┐╝æ]ż╣żļż╚Īó
źŌź╬źĻźĘź├ź»żŪżŽ╠½ĄČ┤“ż┴żŪżŁż╩żż
Ī źąź├ź┴äI└Ēźšźņ®`źÓź’®`ź»ĪóĘų╔óäI└Ēż¼źŁ®`ź’®`ź╔
żĮż│żŪSparkżŪż╣żĶŻĪ](https://image.slidesharecdn.com/sparkwithelasticsearch-150605103257-lva1-app6891/85/Spark-in-small-or-middle-scale-data-processing-with-Elasticsearch-15-320.jpg)



![ż╩ż╝Ʊė├żĘż┐ż½
Ī± ┤ŪĢ°Ė³ą┬ż¼ūŅ┤¾ż╬æę─Ņ
Ī ╠žż╦│§Ų┌żŽ┤ŪĢ°Ė³ą┬ż¼ŅlĘ▒ż╦░k╔·
Ī į┘źżź¾źŪź├ź»ź╣ż“┐╝æ]żĘż┐źó®`źŁźŲź»ź┴źŃ
Ī± rawźŪ®`ź┐ż╬Ė³ą┬?Ž„│²ż╬▒žę¬ąį
Ī źšźĪźżźļż└ż╚ģŚżĘżż
Ī± źó®`źŁźŲź»ź┴źŃż╬Įyę╗ż╦żĶżļ▀\ė├ż╬żĘżõż╣żĄ](https://image.slidesharecdn.com/sparkwithelasticsearch-150605103257-lva1-app6891/85/Spark-in-small-or-middle-scale-data-processing-with-Elasticsearch-22-320.jpg)
![Ī± ┤ŪĢ°Ė³ą┬ż¼ūŅ┤¾ż╬æę─Ņ
Ī ╠žż╦│§Ų┌żŽ┤ŪĢ°Ė³ą┬ż¼ŅlĘ▒ż╦░k╔·
Ī į┘źżź¾źŪź├ź»ź╣ż“┐╝æ]żĘż┐źó®`źŁźŲź»ź┴źŃ
Ī± rawźŪ®`ź┐ż╬Ė³ą┬?Ž„│²ż╬▒žę¬ąį
Ī źšźĪźżźļż└ż╚ģŚżĘżż
Ī± źó®`źŁźŲź»ź┴źŃż╬Įyę╗ż╦żĶżļ▀\ė├ż╬żĘżõż╣żĄ
╩┬╝■░k╔·ŻĪŻĪ
ż╩ż╝Ʊė├żĘż┐ż½](https://image.slidesharecdn.com/sparkwithelasticsearch-150605103257-lva1-app6891/85/Spark-in-small-or-middle-scale-data-processing-with-Elasticsearch-23-320.jpg)






Spark in small or middle scale data processing with Elasticsearch
- 1. Spark in small or middle scale data processing with Elasticsearch 2015-06-01 Ą┌10╗želasticsearch├ŃÅŖ╗ß
- 5. źĻźĻ®`ź╣ż▐żŪż╬ķ_░kŲ┌ķg Ī± ż¬ż¬żĶżĮ1─Ļ Ī ż│ż╬ķgż╦║╬Č╚żŌźó®`źŁźŲź»ź┴źŃż“ēõĖ³ Ī ╚½▓┐Æ╬żŲżŲ1ż½żķū„żĻų▒ż╣ż│ż╚żŌ Ī± ElasticsearchżŪżŽż╩żżĢrŲ┌żŌżóż├ż┐
- 6. Elasticsearch vs CloudSearch Ī± źĄ®`źėź╣ż╬ż█ż╚ż¾ż╔żŽAWS╔Žż╦śŗ║B Ī± ūį╚╗ż╚CloudSearchż╚żżż”▀xÆkų½ż╦ Ī± īgļHCloudSearchżŪäėżżżŲżżż┐ż│ż╚żŌżóż├ż┐ Ī aws-cloudsearch-scalaż╚żżż”źķźżźųźķźĻżŌū„ż├ż┐
- 7. Elasticsearchż╦øQżßż┐└Ēė╔ Ī± Ą▒ĢrżŽÖC─▄▓╗ūŃż¼Ę±żßż╩ż½ż├ż┐ Ī Ą▒ĢrżŽźµ®`źČ┤ŪĢ°ż¼╩╣ż©ż╩ż½ż├ż┐Īón-gramż¼╩╣ż©ż╩ ż½ż├ż┐ż╩ż╔ė¹żĘżżÖC─▄ż¼▓╗ūѿʿŲżżż┐ Ī± Ś╩╦„ż╬╝Üż½żżź┴źÕ®`ź╦ź¾ź░ż¼Ė╬ż╦ż╩żļ Ī Į½└┤Ą─ż╦żŌźūźķź░źżź¾║¼żßūįĘų▀_żŪ╩ųż“╚ļżņżķżņżļżŌż╬ ż“▀xÆkż╣żļ▒žę¬ż¼żóż├ż┐
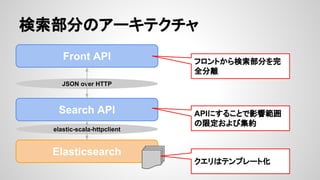
- 8. Ś╩╦„▓┐Ęųż╬źó®`źŁźŲź»ź┴źŃ Front API JSON over HTTP Search API Elasticsearch elastic-scala-httpclient źšźĒź¾ź╚ż½żķŚ╩╦„▓┐Ęųż“═Ļ ╚½Ęųļx APIż╦ż╣żļż│ż╚żŪė░Ēæ╣Āćņ ż╬Ž▐Č©ż¬żĶżė╝»╝s ź»ź©źĻżŽźŲź¾źūźņ®`ź╚╗»
- 9. ż═żķżż Ī± źšźĒź¾ź╚źĄźżź╔ż╚Ś╩╦„źĄźżź╔żŪźķźżźšźĄźżź»źļż¼ «Éż╩żļżŪż╬äeĪ®ż╦źŪźūźĒźżżŪżŁżļżĶż”ż╦ Ī± ź»ź©źĻźĻźķźżź╚żõŚ╩╦„ź»ź¬źĻźŲźŻżžż╬ę¬╝■ż½żķźš źĒź¾ź╚źĄźżź╔ż“ŪążĻļxżĘż┐żż Ī± ź»ź©źĻż╬ą▐š²żŽźŲź¾źūźņ®`ź╚ż└ż▒żŪ═ĻĮ߿ʿ┐żż
- 11. (▓╬┐╝)ż│ż¾ż╩ż╬żŌ Ī± ĮėŠAĘĮ╩ĮżŽTransport Client or Node Client Ī± ź»ź©źĻż“DSLżŪĢ°ż▒żļ
- 12. żõż├żŲż▀żŲ╦╝ż├ż┐ż│ż╚ Ī± ź»ź©źĻż¼JSONżŪą┴żż Ī ź»ź©źĻż¼źąź░ż├żŲżżżļż╚ĮY╣¹ż¼šµż├░ūż╦ Ī Ś╩╦„ĮY╣¹(ź»ź¬źĻźŲźŻ)ż“Ė─╔ŲżĘżŲżżż»╣▄└ĒÖC─▄ż“ė├ęŌ Ī± ę¬╝■ż¼░▓Č©ż╣żļż▐żŪź╣źŁ®`ź▐ż“║╬Č╚żŌū„żĻų▒ ż╣ĪŻż│ż╬ū„śIż¼ĮYśŗą┴żż Ī Alter╬─ż╚ż½¤ożżż╬żŪūŅ│§ż½żķżõżĻų▒żĘ Ī Į±ßßżŌēõĖ³żŽżóżļż╬żŪdynamicźšźŻ®`źļź╔ż“Ʊė├żž
- 13. źŪ®`ź┐ż╬═Č╚ļ
- 15. │§Ų┌ż╬šnŅ} Ī± HTMLż“ĮŌ╬÷ż╣żļ▓┐ĘųżŽ║╬Č╚żŌĖ─╔ŲżĘżŲąņĪ®ż╦ ŲĘ┘|ż“╔Žż▓żŲżżż»▒žę¬ż¼żóż├ż┐ Ī żĮż╬Č╚ż╦į┘ź»źĒ®`źļż╩ż¾żŲżõż├żŲżķżņż╩żż Ī± źŪ®`ź┐┴┐żŽēł╝ėż╬ę╗═ŠżŪŽļČ©┴┐ż“┐╝æ]ż╣żļż╚Īó źŌź╬źĻźĘź├ź»żŪżŽ╠½ĄČ┤“ż┴żŪżŁż╩żż Ī źąź├ź┴äI└Ēźšźņ®`źÓź’®`ź»ĪóĘų╔óäI└Ēż¼źŁ®`ź’®`ź╔ żĮż│żŪSparkżŪż╣żĶŻĪ
- 16. Apache Sparkż╚żŽ Ī± Scalačuż╬Ė▀╦┘źąź├ź┴äI└Ēźšźņ®`źÓź’®`ź» Ī± Hadoopż¼┐Ó╩ųż╚żĘżŲżżżļź╣źļ®`źūź├ź╚ż╚źņźżźŲ ź¾źĘż╬üI┴óż¼▒žę¬ż╩å¢Ņ}ŅIė“ż╦źóźūźĒ®`ź┴ż╣żļ ż┐żßż╦ķ_░kżĄżņż┐ Ī± ║åģgż╩ź│®`ź╔żŪĘų╔óäI└Ēż¼┐╔─▄ Ī± Spark SQLĪóSpark StreamingĪóMLlibż╩ż╔Īó śöĪ®ż╩źĄźųźūźĒźĖź¦ź»ź╚ż¼┤µį┌
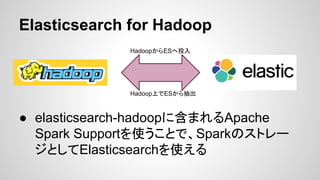
- 17. Elasticsearch for Hadoop Ī± elasticsearch-hadoopż╦║¼ż▐żņżļApache Spark Supportż“╩╣ż”ż│ż╚żŪĪóSparkż╬ź╣ź╚źņ®` źĖż╚żĘżŲElasticsearchż“╩╣ż©żļ Hadoopż½żķESżž═Č╚ļ Hadoop╔ŽżŪESż½żķ│ķ│÷
- 19. ż═żķżż Ī± HTMLĮŌ╬÷żõźżź¾źŪźŁźĘź¾ź░▓┐Ęųż└ż▒ż“▓┐ĘųĄ─ ż╦īgąążŪżŁżļ Ī │§Ų┌ż╬šnŅ}ż“ĮŌøQż╣żļą╬ Ī± č}╩²ż╬źżź¾źŪź├ź»ź╣ż“ĮY║ŽżŪżŁżļ Ī Ģrķgż╬ż½ż½żļźŪ®`ź┐ż“Ū░żŌż├żŲū„ż├żŲż¬żŁĪóźżź¾źŪźŁźĘ ź¾ź░Ģrż╦_idżŪĮY║Žż╣żļ
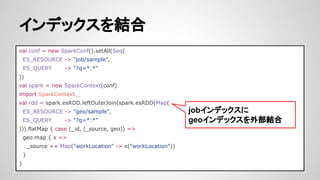
- 20. źżź¾źŪź├ź»ź╣ż“ĮY║Ž val conf = new SparkConf().setAll(Seq( ES_RESOURCE -> "job/sample", ES_QUERY -> "?q=*:*" )) val spark = new SparkContext(conf) import SparkContext._ val rdd = spark.esRDD.leftOuterJoin(spark.esRDD(Map( ES_RESOURCE -> "geo/sample", ES_QUERY -> "?q=*:*" ))).flatMap { case (_id, (_source, geo)) => geo.map { x => _source ++ Map("workLocation" -> x("workLocation")) } } jobźżź¾źŪź├ź»ź╣ż╦ geoźżź¾źŪź├ź»ź╣ż“═Ō▓┐ĮY║Ž
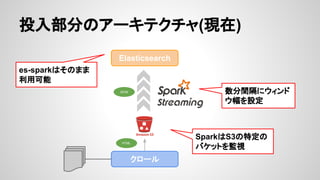
- 21. ūŅ▀mż╩ź╣ź╚źņ®`źĖ Ī± ĪĖSparkżŽĖ▀╦┘Ī╣ĪĖSparkż╬─═šŽ║”ąįżŽĖ▀żżĪ╣ż╚żż ż”ż╬żŽĪóź╣ź╚źņ®`źĖż╚żĘżŲźšźĪźżźļż“ŽļČ©żĘż┐įÆ Ī Į±ßßźšźĪźżźļęį═ŌżŌĖ─╔ŲżĘżŲżżżŁż┐żżżĮż” Ī± źšźĪźżźļęį═Ōż╬ź╣ź╚źņ®`źĖż“ÆQż”ł÷║ŽżŽūóęŌż¼ ▒žę¬ Ī es-sparkż╦żŽ─═šŽ║”ąįż╬ż┐żßż╦▒žę¬ż╩ź┴ź¦ź├ź»ź▌źżź¾ź╚ ż╬īgū░ż¼¤ożż
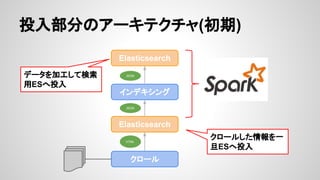
- 22. ż╩ż╝Ʊė├żĘż┐ż½ Ī± ┤ŪĢ°Ė³ą┬ż¼ūŅ┤¾ż╬æę─Ņ Ī ╠žż╦│§Ų┌żŽ┤ŪĢ°Ė³ą┬ż¼ŅlĘ▒ż╦░k╔· Ī į┘źżź¾źŪź├ź»ź╣ż“┐╝æ]żĘż┐źó®`źŁźŲź»ź┴źŃ Ī± rawźŪ®`ź┐ż╬Ė³ą┬?Ž„│²ż╬▒žę¬ąį Ī źšźĪźżźļż└ż╚ģŚżĘżż Ī± źó®`źŁźŲź»ź┴źŃż╬Įyę╗ż╦żĶżļ▀\ė├ż╬żĘżõż╣żĄ
- 23. Ī± ┤ŪĢ°Ė³ą┬ż¼ūŅ┤¾ż╬æę─Ņ Ī ╠žż╦│§Ų┌żŽ┤ŪĢ°Ė³ą┬ż¼ŅlĘ▒ż╦░k╔· Ī į┘źżź¾źŪź├ź»ź╣ż“┐╝æ]żĘż┐źó®`źŁźŲź»ź┴źŃ Ī± rawźŪ®`ź┐ż╬Ė³ą┬?Ž„│²ż╬▒žę¬ąį Ī źšźĪźżźļż└ż╚ģŚżĘżż Ī± źó®`źŁźŲź»ź┴źŃż╬Įyę╗ż╦żĶżļ▀\ė├ż╬żĘżõż╣żĄ ╩┬╝■░k╔·ŻĪŻĪ ż╩ż╝Ʊė├żĘż┐ż½
- 25. ź┐ź╣ź»ż¼ĘųĖŅżĄżņż╩żż Ī± ESż½żķźūźķźżź▐źĻźĘźŃ®`ź╔ż╬Ūķł¾ż“╚ĪĄ├ Ī źņźūźĻź½żŽ╩╣ż’ż╩żż Ī± Ė„źĘźŃ®`ź╔ż¼│ųż─ź╔źŁźÕźßź¾ź╚ż“ĘųĖŅżĘż┐╚ļ┴”éÄ ż╚żĘżŲÆQż” Ī Ą▒│§żŽ1źĘźŃ®`ź╔ż╬ż┐żßĪóźĘźŃ®`ź╔╩²ż“ēłżõżĘż┐
- 27. źĘźŃ®`ź╔ż¼ŪĘōp Ī± Sparkż╦żĶż├żŲżŌż╬ż╣ż┤żżä▌żżżŪĢ°żŁ▐zż▀ż“ ąąż├żŲżżżļż╚żŁż╦źĻź½źąźĻż¼ū▀ż├ż┐ł÷║ŽĪó─═ż©żŁ żņż║ę╗▓┐źĘźŃ®`ź╔ż¼ē▓żņżļ Ī± źĻź½źąźĻż╬žō║╔ż“Ž┬ż▓żļż│ż╚żŪź│źį®`żĘż╩ż¼żķĢ° żŁ▐zż▀ż“╩▄ż▒ĖČż▒żķżņżļżĶż”ż╦ĪóęįŽ┬ż╬éÄż“ąĪ żĄż»żĘż┐ Ī indices.recovery.max_bytes_per_sec Ī indices.recovery.concurrent_streams
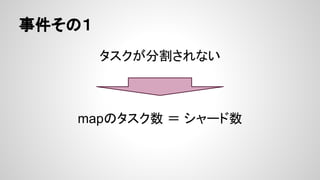
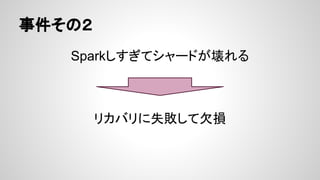
- 28. šnŅ} Ī± źŪ®`ź┐ż╬§rČ╚ż¼┬õż┴żļ Ī 1╚š1╗žż╬źąź├ź┴Ę┤ė│żŪżŽ▀Wżż Ī ŽļČ©ęį╔Žż╦źŪ®`ź┐ż╬╔·┤µŲ┌ķgż¼Č╠żż Ī÷ ūį╚╗╠į╠Łż╦ż▐ż½ż╗żŲżŌżĶżżż╬żŪżŽ Ī÷ ╚½╝■źżź¾źŪź├ź»ź╣żŽżżż║żņ┴┐Ą─Ž▐Įń Ī± źĻźĮ®`ź╣ż╦¤o±jż¼żóżļ Ī ╦▓ķgĄ─ż╦Ė▀ź╣ź┌ź├ź»ż¼Ū¾żßżķżņżļż¼Īó▀[ż¾żŪżżżļĢrķgż¼ ĮYśŗżóżļ
- 29. Spark Streaming Ī± SparkżŪöM╦ŲĄ─ż╦ź╣ź╚źĻ®`źÓäI└Ēż“ąąż”źķźżźųźķ źĻ Ī SparkżŽżóż»ż▐żŪźąź├ź┴äI└ĒżŪĪóäI└Ēż“│¼ĘųĖŅżĘżŲźĘźń®` ź╚źąź├ź┴ż╦żĘżŲīgąą Ī źąź├ź┴ż╚ź╣ź╚źĻ®`źÓżŪ╗∙▒Pż“Įyę╗żŪżŁżļźßźĻź├ź╚ż¼żóżļ Ī± ź»źĒ®`źļż“ę╗Č©ķgĖ¶żŪąąż├żŲżżżļż╬żŪĪóSpark Streamingż╬żĘż»ż▀ż╚ź▐ź├ź┴
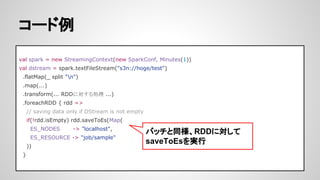
- 31. ź│®`ź╔└² val spark = new StreamingContext(new SparkConf, Minutes(1)) val dstream = spark.textFileStream("s3n://hoge/test") .flatMap(_ split "n") .map(...) .transform(... RDDż╦īØż╣żļäI└Ē ...) .foreachRDD { rdd => // saving data only if DStream is not empty if(!rdd.isEmpty) rdd.saveToEs(Map( ES_NODES -> "localhost", ES_RESOURCE -> "job/sample" )) } źąź├ź┴ż╚═¼śöĪóRDDż╦īØżĘżŲ saveToEsż“īgąą
- 32. ä┐╣¹ Ī± ElasticsearchżŽŚ╩╦„▓┐Ęųż╦╠ž╗» Ī ▒Š└┤ż╬ę█ĖŅżž Ī± inputż“źšźĪźżźļż╦żĘż┐ż│ż╚żŪMapź┐ź╣ź»╩²ż¼ źĘźŃ®`ź╔╩²ż╬żĶż”ż╩═ŌĄ─ę¬ę“ż╦ę└┤µżĘż╩żżą╬ż╦ Ī ģ¦╝»żĘżŲ╩²ĘųżŪ▒ĒżžĘ┤ė│
- 33. ż▐ż╚żß Ī± ūŅ│§żŽ╩²╠©ż╬ź»źķź╣ź┐żŪ╩╝żßżŲĪóąņĪ®ż╦ź╣ź▒®` źļźóź”ź╚ż¼▒╚▌^Ą─╚▌ęūż╦┐╔─▄ Ī ż┴żńż├ż╚żĘż┐Ś╩į^ż╦Docker╩╣ż├ż┐żĻ Ī± elasticsearch-sparkżŽbeta░µż└ż¼└¹ė├ż╦żŽå¢ Ņ}ż╩żż Ī ż┐ż└żĘĪóįOČ©żĘżŲżŌä┐ż½ż╩żżĒŚ─┐ż¼żóż├ż┐żĻintegration ķgżŪš¹║Žąįż¼╚ĪżņżŲż╩żż▓┐ĘųżŌ