








Spark3's new memory model/management
- 2. Major categorization ŌŚÅ Java heap memory ŌŚŗ Characterised by Garbage collection ŌŚÅ JVM off-heap memory / direct memory ŌŚÅ Python memory
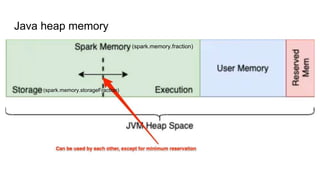
- 4. Java heap memory 1. Storage Memory ŌĆö JVM heap space reserved for cached data 2. Execution (or shuffle) Memory ŌĆö JVM heap space used by data-structures during shuffle operations (joins, group-byŌĆÖs and aggregations). Earlier (before Spark 1.6), the term shuffle memory was also used to describe this section of the memory. 3. User Memory ŌĆö For storing the data-structures created and managed by the userŌĆÖs code 4. Reserved Memory ŌĆö Reserved by Spark for internal purposes.
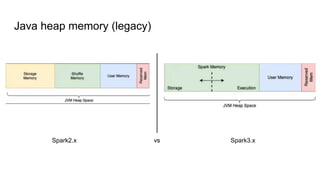
- 6. Java heap memory (legacy) Spark2.x vs Spark3.x
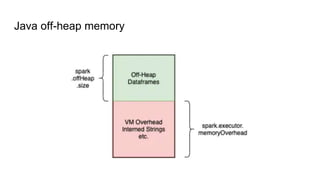
- 8. Java off-heap memory 1. Off heap dataframes 2. VM overheads ŌĆö Interned strings, etc.
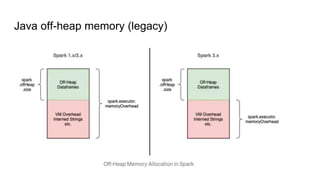
- 10. Java off-heap memory (legacy)
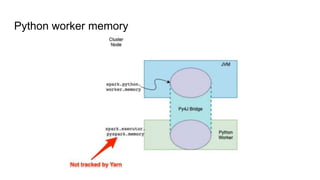
- 12. 1. Python worker memory ŌĆö limits the memory in JVM for Python objects 2. Pyspark Executor memory ŌĆö limits the memory of the actual Python process Python worker memory
- 14. References Monitoring and Instrumentation - Spark 3.3.2 Documentation Decoding Memory in Spark ŌĆö Parameters that are often confused | by Sohom Majumdar | Walmart Global Tech Blog | Medium Apache Spark Memory Management. This blog describes the concepts behindŌĆ” | by Suhas N M | Analytics Vidhya | Medium