


![? 2016 IBM Corporation14
? MLlibとRが利用可能
MLlibはScalaで、SparkRはRで
記述可能
? アルゴリズム(MLlib)
? SVM、ロジスティック回帰、決定木、K-
means、ALSなど
? IBMはSystemMLをSparkに提供
val data = spark.textFile("kdata.txt")
val parsedData = data.map(x =>
Vectors.dense(x.split(',').map(_.toDouble))).cache()
val numClusters = 3
val numIterations = 10
val clusters = KMeans.train(parsedData, numClusters, numIterations)
? Sparkで機械学習
SparkR, Mllib
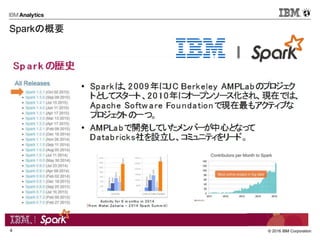
データ: ( 直近購買月[n日前], 期間内購買回数 )
(5,1),(4,2),(5,3),(1,2),(2,4),(2,5),(2,6),(1,4),(1,5),(1,2),(1,5),(5,5)
クラスタ結果: ([中心], 人数)
([1.0, 2.0], 2), ([1.5, 4.833333333333333], 6),
([4.666666666666666, 2.0], 3), ([5.0, 5.0], 1)
例:顧客のクラスタ分け
0
2
4
6
0 2 4 6](https://image.slidesharecdn.com/html5conference-160903045852/85/Spark-JupyterNotebook-Html5-conference-9-320.jpg)
![? 2016 IBM Corporation15
? グラフデータを並列分散環境で処理するための
フレームワーク
? グラフ構造データを用いた解析を行う
? 「点」と「辺」からなるデータ
? SNSでのつながり、データ間の関連性
など
? 表構造では扱うことが難しい関係を見つけ出す
? データ間のつながりの抽出
? 輪の抽出
? 距離の計測
? 影響の計測
? グラフDBとの兼ね合い(これから)
val graphWithDistance = Pregel(
graph.mapVertices((id:VertexId, attr:Int) => List((id, 0))),
List[(VertexId, Int)](),
Int.MaxValue,EdgeDirection.Out)((id, attr, msg) =>
mergeVertexRoute(attr, msg.map(a=> (a._1, a._2 + 1))),edge
=> {
val isCyclic = edge.srcAttr.filter(_._1 ==
edge.dstId).nonEmpty
if(isCyclic) Iterator.empty
else Iterator((edge.dstId, edge.srcAttr))
},(m1, m2) => m1 ++ m2
)
? Sparkでグラフ処理を
Spark GraphX
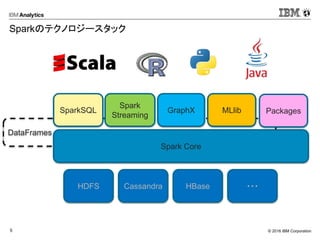
つながりの検索
例: つながりと距離を見つけ出す
1,((1,0), (6,1), (9,1), (7,1), (4,2))
1
2 3
4
5
6
7
89](https://image.slidesharecdn.com/html5conference-160903045852/85/Spark-JupyterNotebook-Html5-conference-10-320.jpg)






SparkとJupyterNotebookを使った分析処理 [Html5 conference]
- 1. ? 2016 IBM Corporation SparkとJupyterNotebookを使った分析処理 Tanaka Y.P 2016-09-03
- 2. ? 2016 IBM Corporation2 自己紹介 田中裕一(yuichi tanaka) 主にアーキテクチャとサーバーサイドプログラムを担当 することが多い。Hadoop/Spark周りをよく触ります。 Node.js、Python、最近はSpark周りの仕事でScalaを書く ことが多い気がします。 休日はOSS周りで遊んだり。 詳解 Apache Spark
- 3. ? 2016 IBM Corporation3 アジェンダ ? Sparkの概要 ? Jupyter notebookの概要 ? 本日のサンプル(分類器) ? Notebook
- 4. ? 2016 IBM Corporation4 Sparkの概要
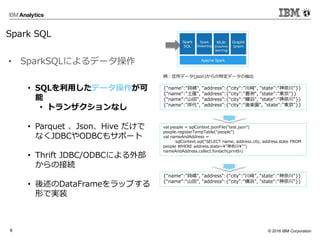
- 5. ? 2016 IBM Corporation5 DataFrames Sparkのテクノロジースタック Spark Core SparkSQL Spark Streaming GraphX MLlib HDFS Cassandra HBase ??? Packages
- 6. ? 2016 IBM Corporation8 ? Java, Scala, Pythonを利用してETLを実行可能 ? RDD(Reslient Distributed Datasets)はScalaのコレクションの Seqのようなもので、データを順番に保持 ? RDDの内部はパーティションに分かれている。パーティション 毎にデータを保持(HDFSブロック数に依存) ? 分散処理する際にはパーティション毎に並列に処理 ? mapやfilter等の基本的な操作の場合、データの順序は変わ らない。 val csv = spark.textFile("tokyo.csv") val pairs = csv.map(line => (line.split(","))) .map(x => (x(0).take(8), (x(4).toFloat, 1))) .reduceByKey( (x,y) => (x._1 + y._1, x._2 + y._2) ) .map(x => (x._1, x._2._1/x._2._2) ) .sortByKey() ? Spark CoreはSparkのエンジン Spark Core 20150614 22:00:00,0,1,8,20.9,8,3.0,8,南南西,8,85,8 20150614 23:00:00,0,1,8,20.9,8,2.6,8,南南西,8,86,8 20150615 00:00:00,0,1,8,20.5,8,1.0,8,南,8,86,8 20150615 1:00:00,0,1,8,20.4,8,0.7,8,南,8,88,8 (2015/6/14,22.565218) (2015/6/15,24.550001) (2015/6/16,23.358332) (2015/6/17,21.583334) 例:平均気温の計算
- 7. ? 2016 IBM Corporation9 ? SQLを利用したデータ操作が可 能 ? トランザクションなし ? Parquet 、Json、Hive だけで なくJDBCやODBCもサポート ? Thrift JDBC/ODBCによる外部 からの接続 ? 後述のDataFrameをラップする 形で実装 {"name":"貝嶋", "address":{"city":"川崎", "state":"神奈川"}} {"name":"土屋", "address":{"city":"豊洲", "state":"東京"}} {“name”:“山田", "address":{"city":"横浜", "state":"神奈川"}} {"name":"岸代", "address":{"city":"後楽園", "state":"東京"}} val people = sqlContext.jsonFile("test.json") people.registerTempTable("people") val nameAndAddress = sqlContext.sql("SELECT name, address.city, address.state FROM people WHERE address.state="神奈川"") nameAndAddress.collect.foreach(println) {"name":"貝嶋", "address":{"city":"川崎", "state":"神奈川"}} {“name”:“山田", "address":{"city":"横浜", "state":"神奈川"}} 例:住所データ(json)からの特定データの抽出 ? SparkSQLによるデータ操作 Spark SQL
- 8. ? 2016 IBM Corporation13 ? Sparkによるミニ(マイクロ)バッチの実行 ? DStreamと呼ばれるRDDを操作 ? 指定間隔ごとにまとめられたRDDを処理(Windows処 理も可能) ? 通常のSparkプログラミングとほぼ同様 たとえば、定期的に流入するデータの「移動平均値」の連続計 算 val tstream = ssc.socketTextStream(hostname, port) var mdtxt = tstream.map(x => x.split(",")) .map(x => ( x(0), (x(0), x(1), x(2).toInt) ) ) .updateStateByKey(updateFunc _) mdtxt.print() センサーデータ: (Dev1, 201501010000, 0) (Dev2, 201501010000, 0) (Dev1, 201501010001, 1) Alert: Dev1 Status changed : 1 ? Sparkでストリーム処理 Spark Streaming 例:センサーデータの出力値変更時にアラート DStream RDD data data RDD data data RDD data data
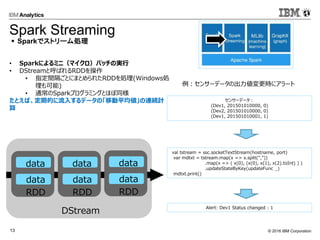
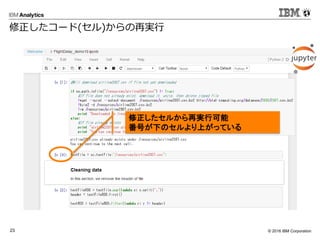
- 9. ? 2016 IBM Corporation14 ? MLlibとRが利用可能 MLlibはScalaで、SparkRはRで 記述可能 ? アルゴリズム(MLlib) ? SVM、ロジスティック回帰、決定木、K- means、ALSなど ? IBMはSystemMLをSparkに提供 val data = spark.textFile("kdata.txt") val parsedData = data.map(x => Vectors.dense(x.split(',').map(_.toDouble))).cache() val numClusters = 3 val numIterations = 10 val clusters = KMeans.train(parsedData, numClusters, numIterations) ? Sparkで機械学習 SparkR, Mllib データ: ( 直近購買月[n日前], 期間内購買回数 ) (5,1),(4,2),(5,3),(1,2),(2,4),(2,5),(2,6),(1,4),(1,5),(1,2),(1,5),(5,5) クラスタ結果: ([中心], 人数) ([1.0, 2.0], 2), ([1.5, 4.833333333333333], 6), ([4.666666666666666, 2.0], 3), ([5.0, 5.0], 1) 例:顧客のクラスタ分け 0 2 4 6 0 2 4 6
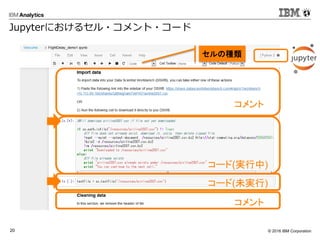
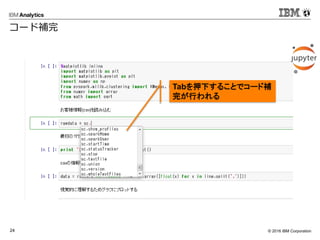
- 10. ? 2016 IBM Corporation15 ? グラフデータを並列分散環境で処理するための フレームワーク ? グラフ構造データを用いた解析を行う ? 「点」と「辺」からなるデータ ? SNSでのつながり、データ間の関連性 など ? 表構造では扱うことが難しい関係を見つけ出す ? データ間のつながりの抽出 ? 輪の抽出 ? 距離の計測 ? 影響の計測 ? グラフDBとの兼ね合い(これから) val graphWithDistance = Pregel( graph.mapVertices((id:VertexId, attr:Int) => List((id, 0))), List[(VertexId, Int)](), Int.MaxValue,EdgeDirection.Out)((id, attr, msg) => mergeVertexRoute(attr, msg.map(a=> (a._1, a._2 + 1))),edge => { val isCyclic = edge.srcAttr.filter(_._1 == edge.dstId).nonEmpty if(isCyclic) Iterator.empty else Iterator((edge.dstId, edge.srcAttr)) },(m1, m2) => m1 ++ m2 ) ? Sparkでグラフ処理を Spark GraphX つながりの検索 例: つながりと距離を見つけ出す 1,((1,0), (6,1), (9,1), (7,1), (4,2)) 1 2 3 4 5 6 7 89
- 11. ? 2016 IBM Corporation18 JupyterはNotebook… “Notebook”とは? ? 紙と鉛筆 ? 紙と鉛筆は、これまで長い間、科学者がメモや 図面を通して進捗状況を文書化するための重 要なツールである: ? 表現力 ? 累積した情報 ? コラボレーション ? Notebooks ? Notebooks は、これまでの紙と鉛筆のデジタ ル版であり、再現性のある分析と文書化を可 能にする: ? マークダウンとグラフ化 ? 反復探索 ? 共有が容易
- 12. ? 2016 IBM Corporation19 データ整形と分析の実行「Jupyter Notebook」 ? リリース ? 2001年にリリースされたIPythonをベースに、2015年にJupyterとしてリリース ? ノートブック ? WebブラウザからのGUI操作可能 ? コード実行、コメント記述、グラフの描画を実行可能 ? カーネル ? Data Scientist Workbenchでは、Scala,Python, Rを実行可能
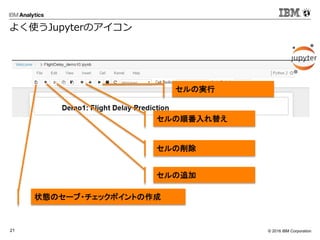
- 13. ? 2016 IBM Corporation20 Jupyterにおけるセル?コメント?コード コメント コード(実行中) コード(未実行) コメント セルの種類
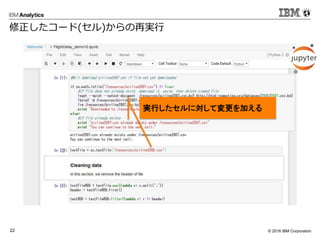
- 14. ? 2016 IBM Corporation21 よく使うJupyterのアイコン 状態のセーブ?チェックポイントの作成 セルの削除 セルの順番入れ替え セルの実行 セルの追加
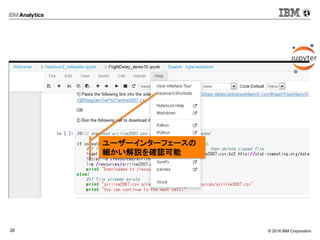
- 15. ? 2016 IBM Corporation22 修正したコード(セル)からの再実行 実行したセルに対して変更を加える
- 16. ? 2016 IBM Corporation23 修正したコード(セル)からの再実行 修正したセルから再実行可能 番号が下のセルより上がっている
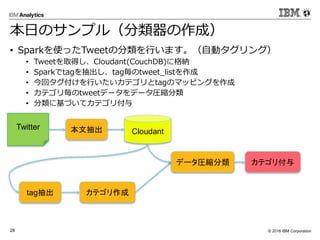
- 17. ? 2016 IBM Corporation24 コード補完 Tabを押下することでコード補 完が行われる
- 18. ? 2016 IBM Corporation25 キーボードショートカット キーボードショートカットによるviライクな操作が可能 (j、kでセ ル間を移動) Enterでセル毎の編集モードに入り、EscでNotebookへのコマンドモードに変更
- 19. ? 2016 IBM Corporation26 ユーザーインターフェースの 細かい解説を確認可能
- 20. ? 2016 IBM Corporation27 本日のサンプル(分類器の作成) ? Sparkを使ったTweetの分類を行います。(自動タグリング) ? SNS分析などで利用される分析 ? 例えば評判の取得や調査の為の関連tweetの抽出などで利用可能 ? 短文(tweetなど)の課題 ? kuromojiを使って形態素解析を行う ? 新語?略語?間違いなどに弱い(というか辞書にないのはできない) ? kMeansを用いた分類 ? 辞書の精度に依存してしまう ? 日本語以外の形態素解析が難しい ? データ圧縮による分類 ? 似たような短文を複数集め、それぞれデータ圧縮し分類器を作る ? 判定したい短文と複数集めた短文をデータ圧縮する ? どの程度圧縮されたか圧縮比を計算し、圧縮比の高いものと同じ分類とする ー> 新語や略語に強い 言語を問わない?画像や映像もいける
- 21. ? 2016 IBM Corporation28 Twitter 本文抽出 tag抽出 カテゴリ作成 カテゴリ付与 Cloudant データ圧縮分類 本日のサンプル(分類器の作成) ? Sparkを使ったTweetの分類を行います。(自動タグリング) ? Tweetを取得し、Cloudant(CouchDB)に格納 ? Sparkでtagを抽出し、tag毎のtweet_listを作成 ? 今回タグ付けを行いたいカテゴリとtagのマッピングを作成 ? カテゴリ毎のtweetデータをデータ圧縮分類 ? 分類に基づいてカテゴリ付与
- 22. ? 2016 IBM Corporation29 本日のサンプルの反省 1. もうちょっと学習用データのtagを考えれば良かった??? ? 学習用のデータ収集 ? #economy,#経済 ? #seiji,#政治 ? #sports,#スポーツ ? #anime,#アニメ ? #IT,#エンジニア ? #science,#科学 ー> これらのタグは各分野の「ニュース」が大量に含まれてしまい、ワードが似通ってしまった。 経済のタグは実はFX関連が多いなど、タグだけで機械的に学習データを集めると分類結果が??? 2. Sparkでの実装 1. SparkSQLや前処理部分での恩恵は大きい(???) 2. 肝心の圧縮部分が分散処理されていない 3. 今日のサンプルの応用 1. Twetterなどの短文、新語や略語が多く含まれる分類には有効 2. 同様にブログ記事など同じ性質を持つものにも有効そう 3. EC系の説明分などを使った自動タグリングにも応用が利きそう
- 23. ? 2016 IBM Corporation30 参考 ? http://db-event.jpn.org/deim2011/proceedings/pdf/a1-6.pdf ? http://dbsj.org/wp-content/uploads/journal/vol10/no1/dbsj-journal-10-01-001.pdf
Editor's Notes
- #2: 1
- #3: 会社では厂辫补谤办と贬补诲辞辞辫のスペシャリストやってます。
- #6: Apache Sparkの概要を簡単におさらいします。 SparkはSparkCoreモジュールとそれを利用したSparkSQL,GraphX,Streaming,Mllibからなります。 SparkCore:RDDを始めとる、メモリ管理やタスクスケジューリングなどの機能を提供するコンポーネント SparkSQL:構造化データを操作するため、SQLのインタフェースを提供するコンポーネント GraphX:グラフ演算処理を行い、グラフ操作するための機能を提供するコンポーネント Spark Streaming:ストリーミングデータの処理を提供するコンポーネント、RDDの拡張であるDStreamを用いてRDDと似た操作が可能 MLlib: 分類、推薦、クラスタリングなどの機械学習アルゴリズムを提供するコンポーネント
- #7: MapReduceと比較してオンメモリでの分散処理に特化しています。 まずはMapReduceを用いてデータ処理を行った場合の処理例です。 MapReduceがスループットを重視し、バッチ処理に特化しているのに対して、 Sparkはレイテンシを重視し、インタラクティブにデータ分析が可能となっています。
- #8: 次にSparkのRDD&DAGの場合の処理例です。 後ほど出てきますが、SparkはSparkSQLを使うことでRDBの直接参照が可能です。 MapReduceがスループットを重視し、バッチ処理に特化しているのに対して、 Sparkはレイテンシを重視し、メモリ上で操作を行うことで、インタラクティブにデータ分析が可能となっています。
- #10: そこで搁顿叠惭厂と同様な厂蚕尝を用いて搁顿顿の操作を行うのが厂辫补谤办厂蚕尝です。
- #11: DataFrameAPIを使うメリットとしては2つ Performance(catalystオプティマイザによる処理の最適化) Less Code(より簡素なコード)
- #13: Catalystの主な役割は論理最適化と物理実行計画の最適化を行う Analysis:DataFrameの分析 Logical Optimization: 主に処理順序の最適化 Physical Planning: 幾つかの計画を実行コストで比較し、コストの低いものを選択 Code Generation: RDDの処理を生成
- #17: RDDとDataFrameの相互変換は可能 RDDはJVMオブジェクトである為コンパイル時のタイプセーフ(DataFrameはタイプセーフにならない) RDDで書くほうが処理ロジックは容易 基本的に速い対してDataFrameは メモリアカウンティングをやってくれる などそれぞれメリットがある