今年こそ始めたい!SQL超入門 セミナー資料 2024年5月22日 富士通クラウドミートアップ
?Download as PPT, PDF?
0 likes?191 views

今年こそ始めたい!SQL超入門 セミナー資料 2024年5月22日 富士通クラウドミートアップ















![データベースクラスタの初期化
? OSユーザーpostgresで実行
? postgresql-setup --initdbコマンドを使用
– [admin@host ~]$ su - postgres
– [postgres@host ~]$ postgresql-setup --initdb
– /var/lib/pgsql/dataディレクトリにデータベースク
ラスターが作成される
20
参考](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-20-320.jpg)

![PostgreSQLの起動と停止
? systemctlコマンドでサービスを起動
– [postgres@host ~]$ systemctl start postgresql
? サービスの自動起動を設定
– [postgres@host ~]$ systemctl enable postgresql
22
参考](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-22-320.jpg)
![データベースの作成
? データベースクラスタ内にデータベースを
作成する
? createdbコマンド
– createdb [db_name]
– db_nameを省略すると、実行ユーザーの名前
のデータベースが作成される
– データベースの所有者は作成したユーザーと
なる
23
参考](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-23-320.jpg)


![psqlツール
対話型SQL実行ツール
? データベースの一覧
– psql -l
? データベースへの接続
– psql [db_name [user]]
– db_nameを省略するとpsqlコマンドの実行ユー
ザー名と同じデータベースへ接続を行う
– userを省略すると、psqlコマンドを実行したOS
ユーザー名でデータベースへ接続を行う
26](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-26-320.jpg)

![表の作成(CREATE TABLE)
? 列を定義し、表の作成を行う
CREATE TABLE table
(column datatype [NULL|NOT NULL]
[DEFAULT value]
| [UNIQUE]
| [PRIMARY KEY (column[,...])]
| [REFERNCES ref_table
(ref_column)]
[,...])
28](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-28-320.jpg)
![行データの作成(INSERT)
? 表に行データを作成(挿入)する
INSERT INTO table[(column[,...])]
VALUES(value[,...])
– 列は明示的に指定した方がよい
– NULLを許されている列を指定しないでもよい
29](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-29-320.jpg)
![データの検索(SELECT)
? 表から行データを検索する
SELECT [DISTINCT] select_list
FROM table[,...]
[WHERE search_condition]
[GROUP BY group_by_expression]
[HAVING search_condition]
[ORDER BY order_expression]
30](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-30-320.jpg)


![ORDER BY句によるソート
? リレーショナルデータベースでは取り出さ
れる行の順序は保証されていない → 明示
的に取り出し行の順序を指定する必要あり
? ORDER BY句によりソートを行う列を指定
? ORDER BY sort_column[,...] [DESC]
– DESC句により逆順ソートが行える
– 複数列が指定された場合、順番に優先して
ソートされる
33](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-33-320.jpg)
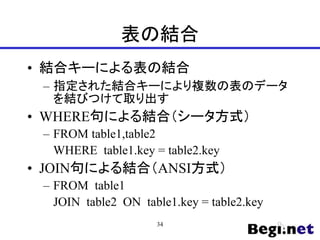
![データの更新(UPDATE)
? 表のデータを更新する
UPDATE table
SET column = expression[,...]
[WHERE conditions]
35](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-35-320.jpg)
![データの削除(DELETE)
? 表のデータを削除する
DELETE FROM table
[WHERE conditions]
– 条件を指定しない場合、表の全ての行データ
を削除する
36](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-36-320.jpg)






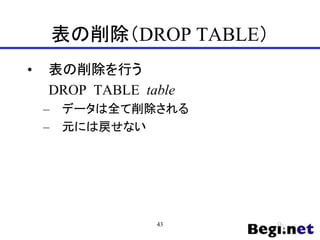


![LIKE演算子
? WHERE expression [NOT] LIKE pattern
? ワイルドカード演算子によるパターンマッチ
ングを行える
– % 0文字以上の全ての文字に一致
– _ 任意の1文字に一致
? 例)
– ○ ‘abc LIKE ‘abc’ 文字列が一致
– ○ ‘abc’ LIKE ‘a%’ aで始まる
– ○ ‘abc’ LIKE ‘_b_’ 3文字で2文字目がb
46](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-46-320.jpg)










![主キー
? 表の各行を一意に識別できる1つ以上の
列
? 表の作成時に指定
PRIMARY KEY (column[,...])
? 主キーに指定された列は以下の制約を受
ける
– 一意である(重複した値を持たない)
– NULLではない(必ず値を持つ)
57](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-57-320.jpg)
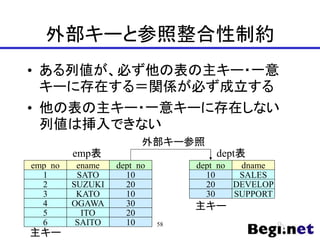




![シーケンス(順序)
? 連番を生成する機能
CREATE SEQUENCE seq_name
[INCREMENT increment]
[MINVALUE minvalue]
[MAXVALUE maxvalue]
[START start]
[CYCLE]
63](https://image.slidesharecdn.com/240522startuppostgresql-240522095632-3cc22813/85/SQL-2024-5-22-63-320.jpg)
















今年こそ始めたい!SQL超入門 セミナー資料 2024年5月22日 富士通クラウドミートアップ
- 2. 自己紹介 ? 本名:宮原 徹 ? 1972年1月 神奈川県生まれ ? 1994年3月 中央大学法学部法律学科卒業 ? 1994年4月 日本オラクル株式会社入社 – PCサーバ向けRDBMS製品マーケティングに従事 – Linux版Oracle8の日本市場向け出荷に貢献 ? 2000年3月 株式会社デジタルデザイン 東京支社長および株 式会社アクアリウムコンピューター 代表取締役社長に就任 – 2000年6月 (株)デジタルデザイン、ナスダック?ジャパン上場(4764) ? 2001年1月 株式会社びぎねっと 設立 ? 2006年12月 日本仮想化技術株式会社 設立 ? 2008年10月 IPA「日本OSS貢献者賞」受賞 ? 2009年10月 日中韓OSSアワード 「特別貢献賞」受賞 2
- 3. 『OSS-DB標準教科書』 ? 本資料はLPI-Japan標準教科書プロジェク トが無償配布している『OSS-DB標準教科 書』と組み合わせて使用することを想定し ています – 印刷版は実費有償配布 – 最新版はGitHubで公開 3 https://oss-db.jp/ossdbtext https://github.com/lpi-japan/ossdb-text
- 4. 本資料のアジェンダ ? データベースとは ? PostgreSQL ? SQLによるデータベースの操作 基礎編 ? データ型 ? 表の作成 ? SQLによるデータベースの操作 応用編 ? データベース定义の応用 ? マルチユーザーでの利用 ? パフォーマンスチューニング/バックアップと 回復 4
- 5. データベースとは 5
- 6. データベースの役割 ? アプリケーションからデータ管理を分離 – 高度なデータ管理機能を提供 – アプリケーションはデータ処理に集中 ? データ管理機能 – 汎用的なデータの入出力を実現 ? データの加工も可能 – マルチユーザーサポート – バックアップと回復 6
- 7. Webアプリケーションサーバーの例 ? Webアプリケーションが必要とするデータ はデータベースが管理 ? データを利用してHTML等を作成し、Web ブラウザとやり取りを行う DB Web APサーバー Web ブラウザ HTTP データ アプリ 7
- 8. リレーショナルデータベース ? 「集合理論」に基づくデータベース ? データの集合を「表」として表す ? 「表」と「表」の間をリレーション(関係)で結 び、新たな「仮想表」を作り出せる ? SQL(Structured Query Language)を使用し てデータベースの操作を行うのが一般的 – 他にもデータベース操作言語は存在したが、 事実上の標準としてSQLが残った 8
- 9. その他のデータベースの例 ? ツリー型データベース – ディレクトリなどに採用されている – 最近ではLDAPなどで注目 – 情報の重複を排除しにくいのが難点 ? オブジェクト型データベース – データを永続オブジェクトとして格納 – オブジェクト指向言語との親和性が高い – リレーショナル型と融合させたオブジェクト?リ レーショナル型データベースもある 9 参考
- 10. SQLの種類 SQLはその目的によって分類される ? DDL(Data Definition Language) – データベースの定義を行うための文 ? DML(Data Manupilition Language) – データベースの操作を行うための文 ? DCL(Data Control Language) – データベースの管理を行うための文 10
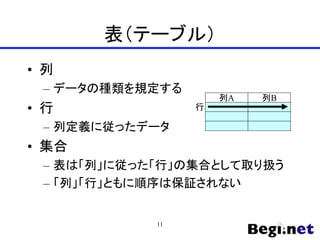
- 11. 表(テーブル) ? 列 – データの種類を規定する ? 行 – 列定義に従ったデータ ? 集合 – 表は「列」に従った「行」の集合として取り扱う – 「列」「行」ともに順序は保証されない 列B 列A 行 11
- 12. RDBの基本関係演算 ? 射影 – 取り出すデータ列を特定する関係演算 – SELECT項目リスト(後述) ? 選択 – 取り出すデータ行を特定する 関係演算 – WHERE句による絞り込み検索(後述) ? 結合 – 複数の表を関連付ける関係演算(後述) 12
- 14. 笔辞蝉迟驳谤别厂蚕尝について
- 15. PostgreSQLの特徴 ? オープンソースのデータベース – オブジェクト?リレーショナルデータベース ? ANSI SQL標準に準拠 ? 多機能 – 同時実行制御 – 副問い合わせ – 制約 – トリガー などなど 15
- 16. PostgreSQLの情報源 ? 日本PostgreSQLユーザ会(JPUG) – https://www.postgresql.jp/ ? ソースコードのダウンロード – https://www.postgresql.org/ftp/source/ ? マニュアル – https://www.postgresql.jp/index.php/docupage 16 参考
- 17. PostgreSQLのセットアップ 1. PostgreSQLのインストール 2. データベースクラスタの作成 3. PostgreSQLの起動 4. データベースの作成 5. データベースユーザーの作成 17 参考
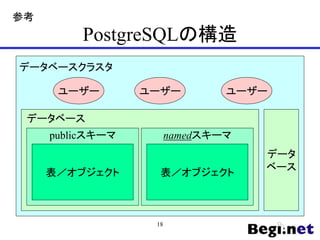
- 18. PostgreSQLの構造 データ ベース publicスキーマ namedスキーマ ユーザー データベース データベースクラスタ ユーザー ユーザー 表/オブジェクト 表/オブジェクト 18 参考
- 19. PostgreSQLのインストール AlmaLinux 9.3にインストールする場合 1. 事前にユーザーとグループを作成 – ユーザーpostgres グループpostgres 2. dnfコマンドでインストール – $ sudo dnf install postgresql-server – インターネットに接続していない場合にはイ ンストールISOイメージから 19 参考
- 20. データベースクラスタの初期化 ? OSユーザーpostgresで実行 ? postgresql-setup --initdbコマンドを使用 – [admin@host ~]$ su - postgres – [postgres@host ~]$ postgresql-setup --initdb – /var/lib/pgsql/dataディレクトリにデータベースク ラスターが作成される 20 参考
- 21. 初期化ユーザー ? 初期化ユーザーはPostgreSQLに対しての 管理者権限を持つ ? initdbを実行したOSユーザーの名前で初 期化ユーザーがPostgreSQLに登録される – 一般的にはユーザーpostgres ? テンプレートデータベース(template0? template1)はこのユーザーの所有となる ? その他の利用ユーザーの作成は初期化 ユーザーで行う 21 参考
- 22. PostgreSQLの起動と停止 ? systemctlコマンドでサービスを起動 – [postgres@host ~]$ systemctl start postgresql ? サービスの自動起動を設定 – [postgres@host ~]$ systemctl enable postgresql 22 参考
- 23. データベースの作成 ? データベースクラスタ内にデータベースを 作成する ? createdbコマンド – createdb [db_name] – db_nameを省略すると、実行ユーザーの名前 のデータベースが作成される – データベースの所有者は作成したユーザーと なる 23 参考
- 25. DB利用の基本パターン 1. 表を作成する(CREATE TABLE) 2. データを挿入する(INSERT) 3. データを検索する(SELECT) 4. データを更新する(UPDATE) 5. データを削除する(DELETE) 25
- 26. psqlツール 対話型SQL実行ツール ? データベースの一覧 – psql -l ? データベースへの接続 – psql [db_name [user]] – db_nameを省略するとpsqlコマンドの実行ユー ザー名と同じデータベースへ接続を行う – userを省略すると、psqlコマンドを実行したOS ユーザー名でデータベースへ接続を行う 26
- 27. SQLの実行 ? psqlにSQL文を入力することで、SQLを対 話的に実行 ? 「;」セミコロンでSQL文の終了を指示 – ;がない場合、SQL文は複数行にまたがる ? で始まるのはpsqlコマンド – ;は不要 ? psqlの履歴機能が利用可能 – カーソルキーの上下で履歴を呼び出し 27
- 28. 表の作成(CREATE TABLE) ? 列を定義し、表の作成を行う CREATE TABLE table (column datatype [NULL|NOT NULL] [DEFAULT value] | [UNIQUE] | [PRIMARY KEY (column[,...])] | [REFERNCES ref_table (ref_column)] [,...]) 28
- 29. 行データの作成(INSERT) ? 表に行データを作成(挿入)する INSERT INTO table[(column[,...])] VALUES(value[,...]) – 列は明示的に指定した方がよい – NULLを許されている列を指定しないでもよい 29
- 30. データの検索(SELECT) ? 表から行データを検索する SELECT [DISTINCT] select_list FROM table[,...] [WHERE search_condition] [GROUP BY group_by_expression] [HAVING search_condition] [ORDER BY order_expression] 30
- 31. SELECT項目リスト ? 検索したい列名をカンマ区切りで並べる ? *(アスタリスク)でFROM句で指定した表 の全ての列を指定できる ? FROM句で複数の表を指定した場合には 「表名.列名」と指定する – FROM句で表名に対して別名を指定できる ? 表名 別名(表名の後に空白を入れて別名) 31
- 32. WHERE句による絞り込み検索 ? 集合として取り出すデータ行を絞り込む ? WHERE column operator expression > < >= <= LIKE BETWEEN = <> operator 演算内容 等しい 等しくない ~よりも大きい ~よりも小さい(未満) ~以上 ~以下 部分一致 範囲指定 条件演算子一覧 32
- 33. ORDER BY句によるソート ? リレーショナルデータベースでは取り出さ れる行の順序は保証されていない → 明示 的に取り出し行の順序を指定する必要あり ? ORDER BY句によりソートを行う列を指定 ? ORDER BY sort_column[,...] [DESC] – DESC句により逆順ソートが行える – 複数列が指定された場合、順番に優先して ソートされる 33
- 34. 表の結合 ? 結合キーによる表の結合 – 指定された結合キーにより複数の表のデータ を結びつけて取り出す ? WHERE句による結合(シータ方式) – FROM table1,table2 WHERE table1.key = table2.key ? JOIN句による結合(ANSI方式) – FROM table1 JOIN table2 ON table1.key = table2.key 34
- 35. データの更新(UPDATE) ? 表のデータを更新する UPDATE table SET column = expression[,...] [WHERE conditions] 35
- 36. データの削除(DELETE) ? 表のデータを削除する DELETE FROM table [WHERE conditions] – 条件を指定しない場合、表の全ての行データ を削除する 36
- 37. データ型 37
- 38. 数値データ型 ? integer/int – バイト数:4バイト(32ビット) – 値の範囲:-2147483648~ +2147483647 ? decimal(p,s) #p=桁数?s=位取り – バイト数:可変長 – 値の範囲:無制限 ? numeric(p,s) #p=桁数?s=位取り – バイト数:可変長 – 値の範囲:無制限 38
- 39. 文字列データ型?日付データ型 ? 文字列 – char(n) 固定長文字列 – varchar(n) 制限付き可変長文字列 ? nは日本語のようなマルチバイト文字の場合、文字数ではなく バイト数で定義 – text 可変長文字列 ? 日付 – date 日付 – time 時刻 – timestamp 日付と時刻 39
- 40. 表の作成 40
- 41. 表定義の確認 ? psqlによる表の定義の確認方法 ? d – 利用可能な表の一覧 ? d table – tableの表定義確認 ※はフォントによりバックスラッシュで表示されることがあります 41
- 42. 表定義の修正(ALTER TABLE) ? 列の追加 ALTER TABLE table ADD COLUMN column datatype ? 列の削除 ALTER TABLE table DROP COLUMN column ? 表定義の修正はできるだけ行うべきでは ない。表の再作成で対応すること。 42
- 43. 表の削除(DROP TABLE) ? 表の削除を行う DROP TABLE table – データは全て削除される – 元には戻せない 43
- 45. AND/OR演算子 ? 複数の条件演算に対してAND/ORの論理演算を 行う – 真(TRUE)となったデータのみ選択される ? AND演算子 – 両方の演算がTRUEの場合のみTRUE – TRUE AND TRUE → TRUE ? OR演算 – どちらかの演算がTRUEならばTRUE – TRUE OR FALSE → TRUE – FALSE OR TRUE → TRUE 45
- 46. LIKE演算子 ? WHERE expression [NOT] LIKE pattern ? ワイルドカード演算子によるパターンマッチ ングを行える – % 0文字以上の全ての文字に一致 – _ 任意の1文字に一致 ? 例) – ○ ‘abc LIKE ‘abc’ 文字列が一致 – ○ ‘abc’ LIKE ‘a%’ aで始まる – ○ ‘abc’ LIKE ‘_b_’ 3文字で2文字目がb 46
- 47. BETWEEN演算子 ? WHERE expression BETWEEN expression AND expression ? 値の範囲にあるかを検査する – 指定された値は含まれる(以上?以下) ? 例) – 列salの値が200以上250以下のデータを選択 – WHERE sal BETWEEN 200 AND 300 47
- 48. 正規表現による検索 ? WHERE expression ~ pattern ? 正規表現によるパターンマッチング – ~(チルダ)演算子を使用する – PostgreSQL独自の拡張仕様 ? 例) – 文字列で始まる ~ ‘^文字列’ – 文字列で終わる ~ ‘文字列$’ – 全ての文字列 ~ ‘.*’ 48
- 49. 集約関数の利用 ? GROUP BY句 – 指定した列の値が同じデータをまとめる ? HAVING句 – GROUP BY句で指定した列の値に対して選択条件を 与える ? 主な集約関数 – COUNT(column) データの行数を数える – SUM(column) 列値の合計 – MAX(column) 列値の最大値 – MIN(column) 列値の最小値 – AVG(column) 列値の平均値 49
- 50. 副問い合わせ ? 問い合わせを行い、その結果を選択条件 として利用する WHERE expression IN ( subquery ) – 副問い合わせの結果は1列を返す – 返された列値と等しいものがあれば真 WHERE EXISTS ( subquery ) – 副問い合わせが行を返せば真 – 副問い合わせが行を返さなければ偽 50
- 51. 日時データの取り扱い ? 日付形式を確認?設定する – SHOW DATESTYLE – SET DATESTYLE TO ‘style’ – デフォルトはISO形式 ? 現在の日付を確認する – SELECT TIMESTAMP ‘NOW’ ? 日時データを特定のタイムゾーンで扱う – AT TIME ZONE ‘timezone’ 51
- 52. 複雑な結合 ? 通常の結合(等価結合?内部結合) ? 直積結合 – 全ての行の組み合わせを返す ? 外部結合 – 一致しない行も返す ? 自己結合 – 1つの表を2つの仮想表に見立てて結合を行う 52
- 53. 外部結合 ? 一方の結合表に存在する行データと結 合されない行も返す – 例)マスター表(外部キー参照表)との結合 ? ANSI方式による結合を行う 1. SELECT select_list FROM table1 LFET OUTER JOIN table2 ON ( join_condition ) 2. SELECT select_list FROM table1 LFET OUTER JOIN table2 USING ( join_col ) 53
- 54. 自己結合 ? 1つの表を2つの仮想表に見立てて、結合 を行う ? 同じ表に対して、別々の表別名を設定する – FROM table t1, table t2 WHERE t1.col=t2.col ? 一方の表から検索される行データがきちん と絞り込まれていないと、直積結合になっ てしまうので注意 54
- 55. LIMIT句による検索行数制限 ? LIMIT句で出力行データ数を制限する ? sql_statement LIMIT n – nは出力される行データ数 ? OFFSET句で出力開始位置を変更する ? sql_statement OFFSET n – nは出力を飛ばした行データ数 – n+1行目から出力 ? 必ずORDER BY句で順序を指定すること 55
- 56. データベース定义の応用
- 57. 主キー ? 表の各行を一意に識別できる1つ以上の 列 ? 表の作成時に指定 PRIMARY KEY (column[,...]) ? 主キーに指定された列は以下の制約を受 ける – 一意である(重複した値を持たない) – NULLではない(必ず値を持つ) 57
- 59. 主キー?外部キーを指定する ? 主キーに指定したい項目にPRIMARY KEY句を付加する – 例)(emp_id int primary key,ename ... – 自動的にインデックスが作成される ? 外部キーを設定したい項目に REFERENCES句を付加する – 参照先の表は予め存在しなくてはならない – 例) dept_no int references dept) 59
- 60. 主キー?外部キーの動作を確認 ? 主キー制約 – 主キーに指定された項目は、列値が重複する ことができない ? 外部キー制約(参照整合性制約) – 外部キーに指定された項目は、参照先に存在 しない値を列値にすることができない – 外部キーの参照先に指定された表は、参照が 存在している限りデータの削除、参照値の変 更ができない 60
- 61. 正規化 ? データをリレーショナルデータベースで扱 いやすい構造にする作業 ? 第1正規形(1NF) – 列に含まれる情報は全て単一 ? 第2正規形(2NF) – 列は全て主キーに依存する ? 第3正規形(3NF) – 列は全て主キーに完全に依存する 参考 61
- 62. NULLについて ? 「未知」または「未定」と定義される ? 「ゼロ」、「空白」とは区別される ? NULLの取り扱い – NOT NULL制約の列には挿入できない – IS NULL、IS NOT NULLで判定を行う – 各種関数では無視される ? 例)平均値算出時の除数に数えられない 62
- 63. シーケンス(順序) ? 連番を生成する機能 CREATE SEQUENCE seq_name [INCREMENT increment] [MINVALUE minvalue] [MAXVALUE maxvalue] [START start] [CYCLE] 63
- 64. シーケンスの利用 ? 次の値を返し、値を更新する – nextval(‘sequence’) ? 現在の値を返す – currval(‘sequence’) ? シーケンスの値を設定する – setval(‘sequence’,value) 64
- 65. シーケンスを主キーとして利用 ? シーケンスを作成 ? 主キーにDEFAULT句でシーケンスを指定 – column type primary key default nextval(‘seq’) ? シーケンスを作成 ? 表にデータを挿入 – 主キーに値を与えない – 主キーの値をnextval(‘seq’)とする 65
- 66. マルチユーザーでの利用
- 67. マルチユーザーでの利用 ? 1つのデータベースを複数のユーザーで共 用する際に考慮すべきポイント ? ユーザーに対するアクセス権の設定 – 読み取り専用にするなど ? トランザクションと読み取り一貫性を理解 する ? 更新競合の発生と回避 ? 接続制限と認証 67
- 68. 接続制限と認証 ? data/pg_hba.confファイルで設定する ? 接続元を指定 – local :ローカル接続 – host :ネットワーク経由接続 – hostssl :ネットワーク経由接続(SSL使用) ? データベースを指定 ? ユーザーを指定 ? 発信元IPアドレス/ネットマスクを指定 68
- 69. 認証方法 ? 各種認証方法が設定可能 – trust 認証なしに接続 – reject 接続拒否 – scram-sha-256 SCRAM認証 – md5 MD5パスワード認証 – password 平文パスワード – ident IDENT認証 – その他マニュアルを参照 69
- 70. ユーザー?パスワードの設定 ? ユーザー作成時にパスワード設定 CREATE USER user WITH PASSWORD ‘pass’ $ createuser –pwprompt user ? 既存ユーザーにパスワード設定 – ALTER USER user WITH PASSWORD ‘pass’ ? パスワードはpg_shadowシステムカタログ 表に格納される ? パスワードが設定されていない場合、パス ワード認証は常に失敗する 70
- 71. アクセス権限 ? 表などに対してアクセスできるのは作成者のみ ? 他のユーザーに対してアクセス権限を与える GRANT {ALL | SELECT | INSERT | DELETE | UPDATE} ON object TO {user|PUBLIC} 71
- 72. トランザクション ? トランザクションの開始 BEGIN ? トランザクションのコミット(確定) COMMIT ? トランザクションのロールバック(破棄) ROLLBACK ? コミットせず終了するとロールバックされる 72
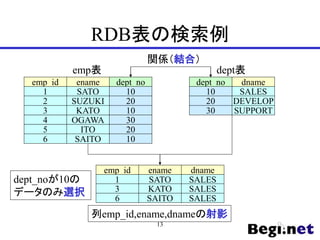
- 73. 読み取り一貫性 ? ユーザーAが未確定なトランザクション内 で行った処理は、ユーザーBに対して影響 しない ename SATO SUZUKI OGAWA ITO SAITO emp_id 1 2 4 5 6 dept_no 10 20 30 20 10 emp表 3 KATO 10 → 20 ユーザーA ユーザーB ○ 10 AのSQL:UPDATE emp SET dept_no=20 WHERE emp_id=3 BのSQL:SELECT dept_no FROM emp WHERE emp_id=3 73
- 74. 更新の競合とロック機構 ? マシンAが更新を行っている行データは ロックされ、マシンBから更新できない ename SATO SUZUKI OGAWA ITO SAITO emp_id 1 2 4 5 6 dept_no 10 20 30 20 10 emp表 3 KATO 10 → 20 ユーザーA AのSQL:UPDATE emp SET dept_no=20 WHERE emp_id=3 ユーザーB BのSQL:UPDATE emp SET dept_no=30 WHERE emp_id=3 ○ × 74
- 76. インデックスの作成 ? 予め指定された項目に関する列値の集合をイン デックス化しておく – 表データ全てにスキャンを行わないため、論理的?物 理的なアクセス量が削減される ? 主キーに指定した項目には自動的にインデック スが作成される – 主キーが検索キー(WHERE句で指定される) ? 頻繁に更新が発生する表ではインデックス更新 のためパフォーマンス低下を招く場合がある 76
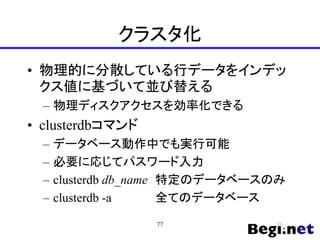
- 77. クラスタ化 ? 物理的に分散している行データをインデッ クス値に基づいて並び替える – 物理ディスクアクセスを効率化できる ? clusterdbコマンド – データベース動作中でも実行可能 – 必要に応じてパスワード入力 – clusterdb db_name 特定のデータベースのみ – clusterdb -a 全てのデータベース 77
- 78. SQL実行プランの分析 ? EXPLAIN文により、SQLがどのように実行 されるのか実行プランを分析できる – EXPLAIN SQL statement 78
- 79. VACUUMの実行 ? PostgreSQLでは実際にはUPDATEおよび DELETEで古い行データを即座に削除しない – UPDATE?DELETEで更新?削除された行データ は内部的にマークがつけられて見えなくなる – データの追加と削除を繰り返すことでデータの分 断化(フラグメント)が発生し、パフォーマンスが低 下する ? VACUUMコマンドで削除マークのついた行 データを実際に削除する ? 現在は自動VACUUMされるのであまり気に しないでもいいかも 79
- 80. バックアップと回復 バックアップ ? pg_dump db_name > dumpfile ? PostgreSQLが停止している状態であれば、 /usr/local/pgsql/data以下をコピーする方法 でもバックアップ可能 – 設定ファイルも同時にコピーされる 回復 ? psql db_name < dumpfile 80
- 81. 今後への課題 ? 解説していない機能の修得 – その他のSQL文 – その他のデータ型 – 一時テーブル、ビュー、ルール、トリガーなど ? フロントエンドツールの修得 – PHP、Javaなどの開発言語 – Webアプリケーションサーバー ? セキュリティとパフォーマンス(大規模DB) 81