














ӨіӨОЛШЗзӨйӨ·ӨӨі§ІПіўӨЛЧЈёЈӨтЈЎ
- 2. ӨӘЗ°ХlӨиЈҝ ӨіӨмЎъӨёӨзӨуӨ№ӨЯӨ№(@__john_smith__) ? ӨЙӨіӨЛӨЗӨвӨӨӨлЖХНЁӨОҘўҘлЦР ? оҠНы ? ұұәЈөАҺўӨкӨҝӨӨ(ҘЖҘуҘЧҘм) ? »ЁқЙПгІЛӨИёЯҳтАоТАӨИДП—lҗЫДЛ ? ЦxЧп ? °kұнӨЛҘӘҘҝҘҜТӘЛШӨ¬ӨўӨЮӨкӨПӨӨӨйӨКӨ«ӨГӨҝ
- 3. ИЛЎ©ӨОУыНыӨИ•rҙъӨОүдЯw ? RDBК№ӨГӨЖӨКӨӨҘ·Ҙ№ҘЖҘаӨИӨ«ӨўӨкӨЁӨКӨӨӨЗӨ·Өз ? УАҫA»Ҝ == RDB ? ЛыӨЛӨКӨуӨ«ӨўӨлӨОЈҝ•rҙъ ? NoSQLЧФМеӨОөҪАҙ ? ҘЗ©`ҘҝӨ¬¶аӨҜӨКӨГӨЖӨӯӨЖRDBӨИӨ«ӨвӨҰҹoАнӨЗӨ·Өзw ? ӨіӨмӨ«ӨйӨО•rҙъӨПNoSQLӨЗӨ№ӨиЈЎ ? ӨдӨГӨСSQLұШТӘ•rҙъ ? RDBӨёӨгӨКӨҜӨЖӨвҪYҫЦSQLӨтҘӨҘуҘҝ©`ҘХҘ§©`Ҙ№ӨЛӨ·ӨҝӨӨ ? ҘЗ©`Ҙҝ·ЦОцӨЗК№ӨГӨЖӨлСФХZӨЗR, PythonӨОҙОӨҜӨйӨӨӨЛSQLӨ¬¬FӨмӨл ? ҘӨҘЮҘіҘі
- 4. AI, ҷCРөС§Б••rҙъӨЛӨӘӨұӨлSQL ? ETLӨИӨ·ӨЖӨОSQL ? ИЛЙъӨИӨПЗ°„IАнӨОРБӨөӨИӨО‘йӨӨ ? HiveӨЗҘЗ©`ҘҝӨтИЎөГӨ·ӨЖSparkӨЗҷCРөС§Б• ? ·ЗҘЧҘнҘ°ҘйҘЮӨ¬ҘЗ©`ҘҝӨтК№ӨҰӨҝӨбӨОSQL ? SQLӨЗҷCРөС§Б•Ө¬іцАҙӨл•rҙъ ? HivemallӨОіц¬F ? Х{ӨЩӨЖӨЯӨлӨИЛыӨЛӨвӨӨӨнӨӨӨнӨўӨГӨҝ ? Postgresql, Microsoft SQL Server, Oracle ? MySQLӨЛӨПӨКӨөӨҪӨҰw
- 5. AI, ҷCРөС§Б••rҙъӨЛӨӘӨұӨлSQL ? ETLӨИMLӨИSQLӨИӨДӨйӨЯ ? З°„IАнӨЗАэНвӨАӨйӨұӨОҘЗ©`ҘҝӨтӨӨӨёӨҜӨГӨЖӨл•rӨиӨкӨПӨЮӨ·ӨАӨұӨЙЎЈЎЈ ? MLӨОҘйҘӨҘЦҘйҘкӨ¬ұШТӘӨИӨ№ӨлҘХҘ©©`ҘЮҘГҘИӨтӨДӨҜӨлӨОӨГӨЖ ? өШО¶ӨЛЧчӨлӨОӨ¬Гжө№ ? …gјғӨЛidүд“QӨЗӨвҘбҘвҘкӨЛҒ\ӨйӨКӨӨӨҜӨйӨӨӨОМШҸХКэӨ¬ӨўӨлӨИЎЈЎЈ ? ҘЗ©`ҘҝҘХҘм©`ҘаҙуәГӨӯ ? …gјғӨКSQLӨИӨ¬ӨГӨДӨкDFІЩЧчӨЗӨӨӨӨӨуӨёӨгӨ«ӨКЈҝ ? ЧоҪьӨО·ЗҘЁҘуҘёҘЛҘўӨ¬ҘЗ©`ҘҝӨӨӨёӨлӨГӨЖ°kПлӨЛ·ҙӨ·ӨЖӨл ? SQLӨЗҷCРөС§Б•ӨО¬FЧҙ ? ҘўҘлҘҙҘкҘәҘаӨПй_°kХЯӨ¬ӨАӨӨӨҝӨӨҢgЧ°Ө·ӨЖӨл
- 6. ӨИӨӨӨҰӨпӨұӨЗ ? ӨіӨуӨКӨОӨ¬ӨўӨлӨИжТӨ·ӨӨӨуӨёӨгӨКӨ«ӨнӨҰӨ« ? ӨиӨҜӨўӨлҘХҘ©©`ҘЮҘГҘИӨЛүд“QӨ№ӨлйvКэ ? ӨӨӨпӨжӨлlibsvm formatӨИӨ« ? ҢgӨПҘйҘӨҘЦҘйҘкӨЛНиН¶ӨІӨ·ӨЖӨлӨАӨұӨОйvКэ ? ӨЮӨАӨЮӨАЎўӨҪӨуӨКҘўҘлҘҙҘкҘәҘаӨ¬ӨўӨлӨ«ӨЗІо„e»ҜӨЗӨӯӨлоIУтӨЗӨ№Ө· ? ӨИӨӨӨҰӨпӨұӨКӨОӨЗ ? ЧчӨнӨҰӨИӨ·ӨЖӨЯӨҝ ? РиТӘӨ¬ӨўӨкӨҪӨҰӨКӨйҪсббӨвӨдӨлӨ«ӨвӨ·ӨмӨКӨӨ ? ӨиӨҰӨ№ӨлӨЛӨҝӨАӨдӨГӨЖӨЯӨҝӨ«ӨГӨҝӨАӨұ
- 7. Өҝ©`ӨІӨГӨИ ? PostgreSQLӨтПаКЦӨЛӨ№Өл ? MySQLӨП·ЦОцӯhҫіӨИӨ·ӨЖӨПҘӨҘЮҘӨҘБӨГӨЭӨӨ ? Oracle, SQL SeverӨтПаКЦӨЛӨ·ӨЖӨлҪрӨ¬ӨўӨГӨҝӨйӨҪӨО·ЦҫЖӨтЩIӨҰ ? Hive, Spark SQLӨКӨЙ·ЦЙўӯhҫіӨПЯB·¬ӨОIDӨтХсӨлӨОӨ¬РБӨӨ ? FeatureӨЛIDХсӨлӨОӨПSQLӨОҷCДЬӨЛӨӘИОӨ»Ө№ӨлӨіӨИӨЛӨ·ӨҝӨОӨЗ ? ӨЗӨӯӨКӨҜӨПӨКӨӨӨұӨЙ·ЦЙўӯhҫіӨЗҘжҘЛ©`ҘҜIDХсӨлӨОӨПГжө№ӨКӨОӨПӨБӨзӨГӨИҝјӨЁӨмӨР ·ЦӨ«ӨГӨЖӨӨӨҝӨАӨұӨлӨИЛјӨпӨмӨл ? ӨКӨӘЎўЛҪӨПӨҪӨуӨКӨЛSQLӨЛӨПФ”Ө·ӨҜӨКӨӨДЈҳ”
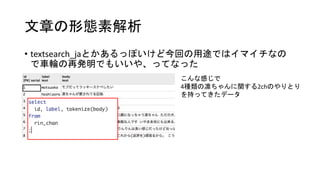
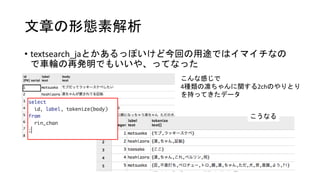
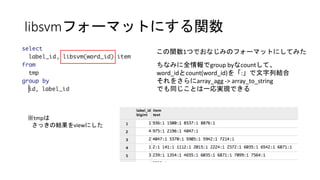
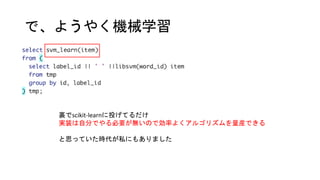
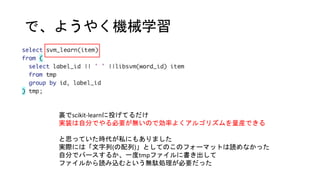
- 15. libsvmҘХҘ©©`ҘЮҘГҘИӨЛӨ№ӨлйvКэ ӨіӨОйvКэ1ӨДӨЗӨӘӨКӨёӨЯӨОҘХҘ©©`ҘЮҘГҘИӨЛӨ·ӨЖӨЯӨҝ ӨБӨКӨЯӨЛИ«ЗйҲуӨЗgroup byӨКcountӨ·ӨЖЎў word_idӨИcount(word_id)ӨтЎё:Ў№ӨЗОДЧЦБРҪYәП ӨҪӨмӨтӨөӨйӨЛarray_agg -> array_to_string ӨЗӨвН¬ӨёӨіӨИӨПТ»ҸкҢg¬FӨЗӨӯӨл ЎщtmpӨП ӨөӨГӨӯӨОҪY№ыӨтviewӨЛӨ·Өҝ
- 19. ӨҪӨ·ӨЖ??? ? predictӨПӨЙӨҰӨ·ӨҝӨвӨОӨ« ? ӨАӨӨӨҝӨӨӨіӨБӨйӨОЛјӨӨНЁӨкӨЛӨПӨӨӨ«ӨКӨӨ ? ИлБҰӨИӨ·ӨЖИлӨГӨЖӨҜӨлҘХҘ©©`ҘЮҘГҘИ ? ҘйҘӨҘЦҘйҘкӨ¬ТӘЗуӨ№ӨлРОКҪ ? ҘвҘЗҘлӨЛә¬ӨаДЪИЭ ? predictҢқПуӨОҘЗ©`ҘҝӨ¬іЦӨГӨЖӨКӨӨМШҸХӨЙӨҰӨ№ӨуӨОЈҝ ? Ҙ№ҘС©`Ҙ№ӨКҘЗ©`ҘҝӨЗұШТӘӨКМШҸХӨ·Ө«іЦӨГӨЖӨКӨӨӨИ С§Б••rӨИН¬ӨёМШҸХӨЛіЦӨГӨЖӨҜӨОӨтӨЙӨҰӨ№ӨлӨ« ? ҙОФӘКэӨвТэКэӨЛӨ№ӨлӨОӨПГАӨ·ӨҜӨКӨӨ ? longӨЗӨвwideӨЗӨвИ«Іҝ0ӨЗВсӨбӨлӨОӨв„IАнЛЩ¶ИӨ¬РБӨӨӨіӨИӨЛӨКӨкӨҪӨҰ ? Ҙ№ҘҜҘйҘГҘБӨЗҢgЧ°Ө·ӨЖӨмӨРӨҪӨОЮxТвЧRӨ·ӨҝҘвҘЗҘлӨОЦРЙнӨЛӨЗӨӯӨлӨұӨЙ
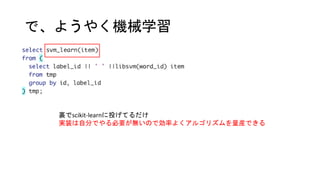
- 20. ҪYХ“ ? SQLӨОЙоӨЯӨЛӨПӨЮӨлӨИҘўҘм ? ЛШИЛӨЗӨвSQLӨЗҷCРөС§Б•ӨЮӨЗіцАҙӨБӨгӨҰӨиӨҰӨЛйvКэӨтУГТвӨ№ӨлӨҜӨйӨӨӨКӨйЎў PipelineӨтGUIӨЗҳӢәBӨЗӨӯӨлӨиӨҰӨКҘӨҘуҘҝ©`ҘХҘ§©`Ҙ№ӨОӨЫӨҰӨ¬ӨиӨҜӨНЈҝ ? ӨЮӨЎЎўӨҪӨвӨҪӨвЬҮЭҶӨОФЩ°kГчӨЗӨ№Ө· ? scikit-learnӨАӨұӨёӨгӨКӨҜgensimӨЛИлӨГӨЖӨлӨиӨҰӨК„IАнӨдdeep learning ПөӨКӨЙЎўpythonӨөӨЁЦӘӨГӨЖӨмӨРUDFӨПҘөҘҜҘГӨИБҝ®bӨЗӨӯӨлӨИӨіӨнӨЮ ӨЗРРӨӯӨҝӨ«ӨГӨҝӨұӨЙЎўӨЮӨЎ ? ҪYҫЦӨОӨИӨіӨнЎўdata frameӨ¬ЧоҸҠ ? ЧтИХ1ИХӨЗӨіӨОӨ№ӨР3ЦЬӨ·Өҝ ? ҘҪ©`Ҙ№ӨПХыАнӨ·ӨҝӨйgithubӨЛӨўӨІӨЮӨ№ ? ӨдӨлҡЭӨ¬ӨўӨмӨРҘйҘӨҘ»ҘуҘ№ӨИӨ«ӨвЧ·јУӨ·ӨЖOSSӨГӨЭӨҜӨ·ӨЮӨ№
- 21. ҪсббӨОФ’ ? UDFӨОДЪНвӨОӨдӨкӨИӨкӨПjsonӨИӨ«ӨЗҪyТ»Ө·ӨЖӨ·ӨЮӨГӨҝӨЫӨҰӨ¬ӨӨӨӨ Ө«Өв ? ҘЗ©`ҘҝӨОРНӨтҝјӨЁӨЖӨдӨкӨИӨкӨ№ӨлӨОӨ¬өШО¶ӨЛРБӨӨ ? complex typeӨОЕдБРӨПӨЗӨӯӨКӨӨӨұӨЙЎўЦРӨОТӘЛШӨПЕдБРӨЛӨЗӨӯӨлӨИӨ« ? ЧоҪьӨОpostgresqlӨПjsonҘөҘЭ©`ҘИӨ·ӨЖӨлӨГӨЭӨӨӨ«ӨйSQLӨЗӨӨӨёӨкӨҝӨӨІҝ·Ц ӨПparseӨ·ӨЖӨИӨ« ? ҘЧҘнҘ°ҘйҘаӮИӨПpandasӨИӨ«ӨЛүд“QӨ·ӨЖҘҙҘкҘҙҘк»ШӨ»ӨлӨ· ? ӨЯӨуӨКӨ¬ҝаӨ·ӨЯӨ«ӨйҪв·ЕӨөӨмӨлӯhҫіӨт ? ҘУҘёҘНҘ№ҘөҘӨҘЙӨЛӨӨӨлИЛӨПsqlӨөӨЁЦӘӨГӨЖӨмӨРudfК№ӨҰӨАӨұ ? СРРЮХЯҘөҘӨҘЙӨПҘҙҘкҘҙҘкҘўҘлҘҙҘкҘәҘаҢgЧ° ? ҘЁҘуҘёҘЛҘўӨ¬ӨҪӨіӨОҝҺӨ®ӨіӨЯӨЗІЎӨЮӨКӨӨҘӨҘуҘҝ©`ҘХҘ§©`Ҙ№ҪyТ»