–Ь–∞—И–Є–љ–љ–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ –≤ —А–∞–љ–ґ–Є—А–Њ–≤–∞–љ–Є–Є –њ–Њ–Є—Б–Ї–∞
–Ф–Њ–Ї—Г–Љ–µ–љ—В –Њ–њ–Є—Б—Л–≤–∞–µ—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –Љ–∞—И–Є–љ–љ–Њ–≥–Њ –Њ–±—Г—З–µ–љ–Є—П –≤ —Б–Є—Б—В–µ–Љ–µ —А–∞–љ–ґ–Є—А–Њ–≤–∞–љ–Є—П –њ–Њ–Є—Б–Ї–∞, –≥–і–µ –∞–љ–∞–ї–Є–Ј–Є—А—Г–µ—В—Б—П –Ї–∞—З–µ—Б—В–≤–Њ –њ–Њ–Є—Б–Ї–∞ –љ–∞ –Њ—Б–љ–Њ–≤–µ –Љ–љ–Њ–ґ–µ—Б—В–≤–∞ —Д–∞–Ї—В–Њ—А–Њ–≤. –Ю—Б–љ–Њ–≤–љ–Њ–є –∞–Ї—Ж–µ–љ—В —Б–і–µ–ї–∞–љ –љ–∞ –Њ—Ж–µ–љ–Ї–µ —А–µ–ї–µ–≤–∞–љ—В–љ–Њ—Б—В–Є –і–Њ–Ї—Г–Љ–µ–љ—В–Њ–≤ –Є –њ—А–Є–Љ–µ–љ–µ–љ–Є–Є —А–∞–Ј–ї–Є—З–љ—Л—Е –Љ–µ—В–Њ–і–Њ–≤, —В–∞–Ї–Є—Е –Ї–∞–Ї –і–µ—А–µ–≤—М—П —А–µ—И–µ–љ–Є–є –Є –±—Г—Б—В–Є–љ–≥, –і–ї—П –і–Њ—Б—В–Є–ґ–µ–љ–Є—П –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ–Њ–≥–Њ –Ј–љ–∞—З–µ–љ–Є—П ndcg. –Ґ–∞–Ї–ґ–µ —Г–њ–Њ–Љ–Є–љ–∞—О—В—Б—П –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ –Ј–∞–і–∞—З–Є, —В–∞–Ї–Є–µ –Ї–∞–Ї —А–∞–Ј–±–Є–µ–љ–Є–µ —В–µ–Ї—Б—В–∞ –љ–∞ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П –Є –і–µ—В–µ–Ї—Ж–Є—П –Ї–Њ–љ—В–µ–љ—В–∞.






Recommended
More Related Content
Viewers also liked (17)
More from tfmailru (11)
–Ь–∞—И–Є–љ–љ–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ –≤ —А–∞–љ–ґ–Є—А–Њ–≤–∞–љ–Є–Є –њ–Њ–Є—Б–Ї–∞
- 1. –Ь–∞—И–Є–љ–љ–Њ–µ –Њ–±—Г—З–µ–љ–Є–µ –≤ —А–∞–љ–ґ–Є—А–Њ–≤–∞–љ–Є–Є –њ–Њ–Є—Б–Ї–∞
- 2. –£ –љ–∞—Б –µ—Б—В—М —Б–≤–Њ–є –њ–Њ–Є—Б–Ї! вАҐ –Т–µ–± вАҐ –Ъ–∞—А—В–Є–љ–Ї–Є вАҐ –Т–Є–і–µ–Њ вАҐ –Э–Њ–≤–Њ—Б—В–Є вАҐ –Ю–±—Б—Г–ґ–і–µ–љ–Є—П вАҐ –Ю—В–≤–µ—В—Л вАҐ –°–ї–Њ–≤–∞—А–Є
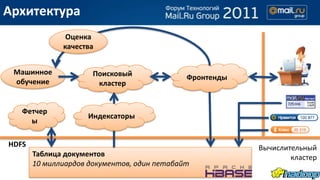
- 3. –Р—А—Е–Є—В–µ–Ї—В—Г—А–∞ –Ю—Ж–µ–љ–Ї–∞ –Ї–∞—З–µ—Б—В–≤–∞ –Ь–∞—И–Є–љ–љ–Њ–µ –Я–Њ–Є—Б–Ї–Њ–≤—Л–є –§—А–Њ–љ—В–µ–љ–і—Л –Њ–±—Г—З–µ–љ–Є–µ –Ї–ї–∞—Б—В–µ—А –§–µ—В—З–µ—А –Ш–љ–і–µ–Ї—Б–∞—В–Њ—А—Л —Л HDFS –Т—Л—З–Є—Б–ї–Є—В–µ–ї—М–љ—Л–є –Ґ–∞–±–ї–Є—Ж–∞ –і–Њ–Ї—Г–Љ–µ–љ—В–Њ–≤ –Ї–ї–∞—Б—В–µ—А 10 –Љ–Є–ї–ї–Є–∞—А–і–Њ–≤ –і–Њ–Ї—Г–Љ–µ–љ—В–Њ–≤, –Њ–і–Є–љ –њ–µ—В–∞–±–∞–є—В
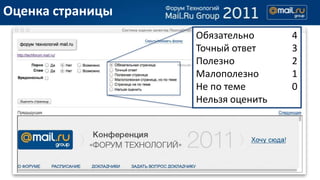
- 5. –Ю—Ж–µ–љ–Ї–∞ —Б—В—А–∞–љ–Є—Ж—Л –Ю–±—П–Ј–∞—В–µ–ї—М–љ–Њ 4 –Ґ–Њ—З–љ—Л–є –Њ—В–≤–µ—В 3 –Я–Њ–ї–µ–Ј–љ–Њ 2 –Ь–∞–ї–Њ–њ–Њ–ї–µ–Ј–љ–Њ 1 –Э–µ –њ–Њ —В–µ–Љ–µ 0 –Э–µ–ї—М–Ј—П –Њ—Ж–µ–љ–Є—В—М
- 6. –Ю—Ж–µ–љ–Ї–∞ –Ї–∞—З–µ—Б—В–≤–∞ –њ–Њ–Є—Б–Ї–∞ вДЦ –Ю—Ж–µ–љ–Ї–∞ CG DCG 1 –Ґ–Њ—З–љ—Л–є –Њ—В–≤–µ—В 3 3 2 –Ґ–Њ—З–љ—Л–є –Њ—В–≤–µ—В 3 3 3 –Я–Њ–ї–µ–Ј–љ–Њ 2 1,26 4 –Ґ–Њ—З–љ—Л–є –Њ—В–≤–µ—В 3 1,5 5 –Я–Њ–ї–µ–Ј–љ–Њ 2 0,86 6 –Ь–∞–ї–Њ–њ–Њ–ї–µ–Ј–љ–Њ 1 0,38 7 –Я–Њ–ї–µ–Ј–љ–Њ 2 0,71 8 –Ь–∞–ї–Њ–њ–Њ–ї–µ–Ј–љ–Њ 1 0,33 –Ш—В–Њ–≥–Њ 17 11,04
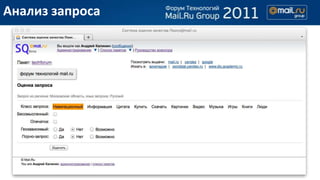
- 7. –Ю–±—Й–Є–є –љ–∞–±–Њ—А –Њ—Ж–µ–љ–Њ–Ї –Ч–∞–њ—А–Њ—Б –Ф–Њ–Ї—Г–Љ–µ–љ—В –Ю—Ж–µ–љ–Ї–∞ —Б–њ–µ—Ж–Є–∞–ї—М–љ–∞—П –Љ—Л—И—Ж–∞ —С–ґ–Є–Ї–∞ http://digest-news.ru/833-Zachemezhikuigolki- 1 Interesniefakti.html –Њ–і–љ–Њ–Ї–ї–∞—Б—Б–љ–Є–Ї–Є http://www.odnoklassniki.ru/ 4 вА¶ вА¶ вА¶ –Ш–Ј–≤–ї–µ—З–µ–љ–Є–µ —Д–∞–Ї—В–Њ—А–Њ–≤ tf tf*idf –Є—Ж вА¶ вА¶ вА¶ вА¶ –Ю—Ж–µ–љ–Ї–∞ 4 12 8 4 3 7 вА¶ 1 вА¶ вА¶ вА¶ вА¶ вА¶ вА¶ вА¶ вА¶
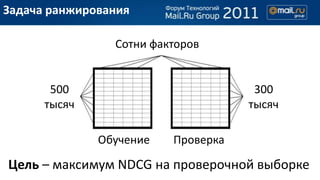
- 8. –Ч–∞–і–∞—З–∞ —А–∞–љ–ґ–Є—А–Њ–≤–∞–љ–Є—П –°–Њ—В–љ–Є —Д–∞–Ї—В–Њ—А–Њ–≤ 500 300 —В—Л—Б—П—З —В—Л—Б—П—З –Ю–±—Г—З–µ–љ–Є–µ –Я—А–Њ–≤–µ—А–Ї–∞ –¶–µ–ї—М вАУ –Љ–∞–Ї—Б–Є–Љ—Г–Љ NDCG –љ–∞ –њ—А–Њ–≤–µ—А–Њ—З–љ–Њ–є –≤—Л–±–Њ—А–Ї–µ
- 10. –Ъ–∞–Ї –њ–Њ–ї—Г—З–∞–µ–Љ –≤—Л–і–∞—З—Г? вАҐ –†–µ–ї–µ–≤–∞–љ—В–љ–Њ—Б—В—М –і–Њ–Ї—Г–Љ–µ–љ—В–∞. вАҐ –°—А–∞–≤–љ–µ–љ–Є–µ –і–≤—Г—Е –§–∞–Ї—В–Њ—А-2 –і–Њ–Ї—Г–Љ–µ–љ—В–Њ–≤. вАҐ –Т—Б—О –і–µ—Б—П—В–Ї—Г —Б—А–∞–Ј—Г. –Х—Б–ї–Є –±—Л —Д–∞–Ї—В–Њ—А–Њ–≤ –±—Л–ї–Њ –Љ–∞–ї–Њ, —В–Њ –Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ –±—Л –і–µ–ї–∞—В—М —В–∞–Ї: –§–∞–Ї—В–Њ—А-1
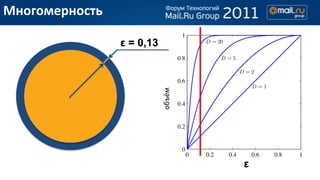
- 11. –Ь–љ–Њ–≥–Њ–Љ–µ—А–љ–Њ—Б—В—М ќµ = 0,13 –Њ–±—К—С–Љ ќµ
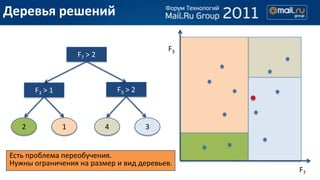
- 12. –Ф–µ—А–µ–≤—М—П —А–µ—И–µ–љ–Є–є F3 F7 > 2 F3 > 1 F3 > 2 2 1 4 3 –Х—Б—В—М –њ—А–Њ–±–ї–µ–Љ–∞ –њ–µ—А–µ–Њ–±—Г—З–µ–љ–Є—П. –Э—Г–ґ–љ—Л –Њ–≥—А–∞–љ–Є—З–µ–љ–Є—П –љ–∞ —А–∞–Ј–Љ–µ—А –Є –≤–Є–і –і–µ—А–µ–≤—М–µ–≤. F7
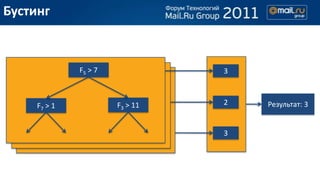
- 13. –С—Г—Б—В–Є–љ–≥ F5 > 7 3 F7 > 1 F3 > 11 2 –†–µ–Ј—Г–ї—М—В–∞—В: 3 3
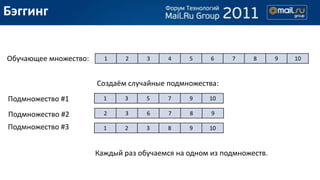
- 14. –С—Н–≥–≥–Є–љ–≥ –Ю–±—Г—З–∞—О—Й–µ–µ –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ: 1 2 3 4 5 6 7 8 9 10 –°–Њ–Ј–і–∞—С–Љ —Б–ї—Г—З–∞–є–љ—Л–µ –њ–Њ–і–Љ–љ–Њ–ґ–µ—Б—В–≤–∞: –Я–Њ–і–Љ–љ–Њ–ґ–µ—Б—В–≤–Њ #1 1 3 5 7 9 10 –Я–Њ–і–Љ–љ–Њ–ґ–µ—Б—В–≤–Њ #2 2 3 6 7 8 9 –Я–Њ–і–Љ–љ–Њ–ґ–µ—Б—В–≤–Њ #3 1 2 3 8 9 10 –Ъ–∞–ґ–і—Л–є —А–∞–Ј –Њ–±—Г—З–∞–µ–Љ—Б—П –љ–∞ –Њ–і–љ–Њ–Љ –Є–Ј –њ–Њ–і–Љ–љ–Њ–ґ–µ—Б—В–≤.
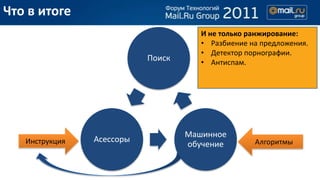
- 15. –І—В–Њ –≤ –Є—В–Њ–≥–µ –Ш –љ–µ —В–Њ–ї—М–Ї–Њ —А–∞–љ–ґ–Є—А–Њ–≤–∞–љ–Є–µ: вАҐ –†–∞–Ј–±–Є–µ–љ–Є–µ –љ–∞ –њ—А–µ–і–ї–Њ–ґ–µ–љ–Є—П. вАҐ –Ф–µ—В–µ–Ї—В–Њ—А –њ–Њ—А–љ–Њ–≥—А–∞—Д–Є–Є. –Я–Њ–Є—Б–Ї вАҐ –Р–љ—В–Є—Б–њ–∞–Љ. –Ь–∞—И–Є–љ–љ–Њ–µ –Ш–љ—Б—В—А—Г–Ї—Ж–Є—П –Р—Б–µ—Б—Б–Њ—А—Л –Р–ї–≥–Њ—А–Є—В–Љ—Л –Њ–±—Г—З–µ–љ–Є–µ
- 16. –°–Я–Р–°–Ш–С–Ю! –Т–Ю–Я–†–Ю–°–Ђ? –Р–љ–і—А–µ–є –Ъ–∞–ї–Є–љ–Є–љ —А—Г–Ї–Њ–≤–Њ–і–Є—В–µ–ї—М —А–∞–Ј—А–∞–±–Њ—В–Ї–Є –њ–Њ–Є—Б–Ї–∞ kalinin@corp.mail.ru