


![public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws
IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
Word count in MapReduce (Java)](https://image.slidesharecdn.com/2015-04-23-spark-150423204538-conversion-gate01/85/Spark-4-320.jpg)







![public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws
IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Word count in Spark(Scala)](https://image.slidesharecdn.com/2015-04-23-spark-150423204538-conversion-gate01/85/Spark-15-320.jpg)



SparkмЭА мЩЬ мЭіл†Зк≤М мЬ†л™ЕнХімІАк≥† мЮИмЭДкєМ?
- 1. SparkмЭА мЩЬ мЭіл†Зк≤М мЬ†л™ЕнХімІАк≥† мЮИмЭДкєМ? 2015-04-23 KSLUG мДЄлѓЄлВШ кєАмГБмЪ∞, VCNC(лєДнКЄмЬИ) kevin@between.us
- 3. лєЕлН∞мЭінД∞лґДмДЭмЭШ мЛЬміИ вАҐ GFS(Google File System) лЕЉлђЄ (2003) вАҐ мЧђлЯђ мїінУ®нД∞л•Љ мЧ∞к≤∞нХШмЧђ м†АмЮ•мЪ©лЯЙк≥Љ I/OмД±лК•мЭД scale вАҐ мЭіл•Љ кµђнШДнХЬ мШ§нФИмЖМмК§ нФДл°Ьм†ЭнКЄмЭЄ Hadoop HDFS вАҐ MapReduceлЕЉлђЄ (2004) вАҐ Mapк≥Љ ReduceмЧ∞мВ∞мЭД м°∞нХ©нХШмЧђ нБілЯђмК§нД∞мЧРмДЬ мЛ§нЦЙ, нБ∞ лН∞мЭінД∞л•Љ м≤Шл¶ђ вАҐ мЭіл•Љ кµђнШДнХЬ мШ§нФИмЖМмК§ нФДл°Ьм†ЭнКЄмЭЄ Hadoop MapReduce
- 4. public class WordCount { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } } Word count in MapReduce (Java)
- 5. лєЕлН∞мЭінД∞ лґДмДЭмЭШ мЛЬміИ (2) вАҐ Hive вАҐ MapReduce мљФлУЬл•Љ мІЬлКФк±і кііл°≠лЛ§ вАҐ мњЉл¶ђл°Ь MapReduceмЭШ к±∞мЭШ л™®лУ† кЄ∞лК•мЭД нСЬнШДнХ† мИШ мЮИлЛ§! вАҐ HDFSлУ±мЧР мЮИлКФ нММмЭЉмЭД мЭљмЦілУ§мЧђ мњЉл¶ђл°Ь лґДмДЭ мИШнЦЙ вАҐ HiveQL мЭД мЮСмД±нХШл©і MapReduce мљФлУЬл°Ь л≥АнЩШлРШмЦі мЛ§нЦЙ
- 6. кЈЄл†Зк≤М 10лЕДмЭі мІАлВШк≥†, мІАкЄИкєМмІАлПД MapReduceмЩА HiveлКФ лІОмЭі мВђмЪ©лРШк≥† мЮИлКФ лєЕлН∞мЭінД∞ кЄ∞мИ†мЮЕлЛИлЛ§ MR, HiveмЧР лПДм†ДнХШлКФ кЄ∞мИ†лУ§ Impala, Pheonix, Pig, Tez лУ±лУ±лУ±лУ±вА¶ мЧДм≤≠ лІОлЛ§
- 7. MapReduce / Hive мЮ•лЛ®м†Р вАҐ мЮ•м†Р вАҐ лєЕлН∞мЭінД∞ мЛЬлМАл•Љ мЧімЦім§А мД†кµђм†БмЭЄ кЄ∞мИ† вАҐ к±∞лМАнХЬ лН∞мЭінД∞л•Љ мХИм†Хм†БмЬЉл°Ь м≤Шл¶ђ вАҐ лІОмЭА мВђлЮМлУ§мЭі мВђмЪ© м§С вАҐ лЛ®м†Р вАҐ мШ§лЮШлРЬ кЄ∞мИ†мЭілЛ§л≥ілЛИ, вАҐ л∞Ьм†ДмЭі лКРл¶ђлЛ§ вАҐ лґИнОЄнХЬм†РмЭі лІОлЛ§
- 8. MapReduceмЭШ лђЄм†Ьм†Р вАҐ MapReduceлКФ MapмЭШ мЮЕмґЬ놕 л∞П ReduceмЭШ мЮЕмґЬ놕мЭД лІ§л≤И HDFSмЧР мУ∞к≥†, мЭљлКФлЛ§ - лКРл¶ђлЛ§ вАҐ MapReduceмљФлУЬлКФ мЮСмД±нХШкЄ∞ лґИнОЄнХШлЛ§ - мҐАлНФ мҐЛмЭА мЭЄнД∞нОШмЭімК§к∞А мЮИмЬЉл©і мҐЛк≤†лЛ§
- 9. Spark вАҐ нХµмЛђ к∞ЬлЕР: RDD (Resilient Distributed Dataset) вАҐ мЭЄнД∞нОШмЭімК§: Scala
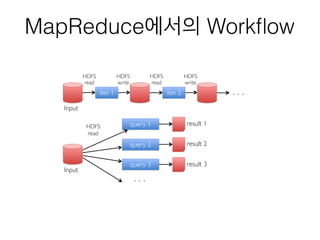
- 10. MapReduceмЧРмДЬмЭШ WorkпђВow iter. 1 iter. 2 . . . Input HDFSвА® read HDFSвА® write HDFSвА® read HDFSвА® write Input query 1 query 2 query 3 result 1 result 2 result 3 . . . HDFSвА® read
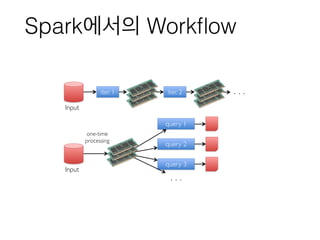
- 11. SparkмЧРмДЬмЭШ WorkпђВow iter. 1 iter. 2 . . . Input Input query 1 query 2 query 3 . . . one-timeвА® processing
- 12. RDD вАҐ Resilient Distributed Dataset - нГД놕м†БмЬЉл°Ь лґДмВ∞лРЬ лН∞мЭінД∞мЕЛ вАҐ нБілЯђмК§нД∞мЧР лґДмВ∞лРЬ л©Фл™®л¶ђл•Љ нЩЬмЪ©нХШмЧђ к≥ДмВ∞лРШлКФ List вАҐ лН∞мЭінД∞л•Љ мЦілЦїк≤М кµђнХілВЉмІАл•Љ нСЬнШДнХШлКФ Transformation мЭД кЄ∞мИ†нХЬ Lineage(к≥Дл≥і)л•Љ interactiveнХШк≤М лІМлУ§мЦі лВЄ нЫД, ActionмЭД нЖµнХі lazyнХШк≤М к∞ТмЭД кµђнХілГД вАҐ нБілЯђмК§нД∞ м§С мЭЉлґАмЭШ к≥†мЮ• лУ±мЬЉл°Ь мЮСмЧЕмЭі м§Ск∞ДмЧР мЛ§нМ®нХШ лНФлЭЉлПД, Lineageл•Љ нЖµнХі лН∞мЭінД∞л•Љ л≥µкµђ
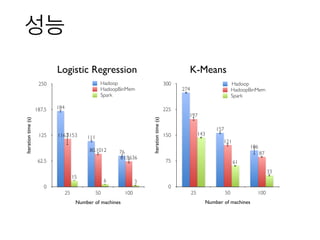
- 13. мД±лК•Iterationtime(s) 0 62.5 125 187.5 250 Number of machines 25 50 100 36 15 61.9636 80.1012 116.3153 76 111 184 Hadoop HadoopBinMem Spark Iterationtime(s) 0 75 150 225 300 Number of machines 25 50 100 33 61 143 87 121 197 106 157 274 Hadoop HadoopBinMem Spark Logistic Regression K-Means
- 14. Interface - Scala вАҐ лІ§мЪ∞ к∞Дк≤∞нХЬ нСЬнШДмЭі к∞АлК•нХЬ мЦЄмЦі вАҐ REPL(aka Shell) м†Ьк≥µ, interactiveнХШк≤М лН∞мЭінД∞л•Љ лЛ§л£®лКФк≤ГмЭі к∞А лК• вАҐ Functional ProgrammingмЭі к∞АлК•нХШлѓАл°Ь MapReduceмЩА к∞ЩмЭА functionalнХЬ к∞ЬлЕРмЭД нСЬнШДнХШкЄ∞мЧР м†БнХ©нХ®
- 15. public class WordCount { public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { JobConf conf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } } val file = spark.textFile("hdfs://...") val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...") Word count in Spark(Scala)
- 16. нЩХмЮ• нФДл°Ьм†ЭнКЄлУ§ вАҐ Spark SQL вАҐ Spark Streaming вАҐ MLLib вАҐ GraphX вАҐ SparkR вАҐ Zeppelin вАҐ лУ±лУ±лУ±вА¶
- 17. мЮ•м†РлУ§ вАҐ мЛЬк∞Дк≥Љ лєДмЪ©мЭД мХДкїім§АлЛ§ вАҐ мИШмЛ≠лМАмЭШ Hadoop Clusterл•Љ 10лМА мЭінХШмЭШ Clusterл°Ь лМАм≤інХ† мИШ мЮИлЛ§ вАҐ мИШмЛ≠лґД кЄ∞л˧놧мХЉ нХШлНШ мЮСмЧЕмЭі 1лґДлІМмЧР мЩДл£МлРЬлЛ§ вАҐ мЮСмЧЕ лʕ땆 нЦ•мГБ вАҐ MR мЮСмЧЕ мљФлУЬ лІМлУ§к≥†, нМ®нВ§мІХнХШк≥†, submitнХШк≥† нХШлНШ л≥µмЮ°нХЬ к≥Љм†ХмЭі, shellмЧРмДЬ мљФлУЬ нХЬм§Д мєШлКФк≤ГмЬЉл°Ь лМАм≤ілРЬлЛ§ вАҐ м≤ШмЭМ м†СнХШлКФ мВђлЮМлПД л∞∞мЪ∞кЄ∞ мЙљлЛ§ вАҐ лЛ§мЦСнХЬ м†ЬнТИмЭД м°∞нХ©нХімХЉ нЦИлНШ мЮСмЧЕмЭі SparkмЬЉл°Ь лЛ§ к∞АлК•нХШлЛ§
- 18. к∞РмВђ«к©лЛИлЛ§