б„Ӣб…ҰбҶҜб„…б…Ўб„үб…іб„җб…өбҶЁб„үб…Ҙб„Һб…ө, лЎңк·ёмҠӨнғңмӢң, нӮӨл°”лӮҳ
92 likes40,002 views

м—ҳлқјмҠӨнӢұм„ңм№ҳ, лЎңк·ёмҠӨнғңмӢң, нӮӨл°”лӮҳ






















![н…Җ(Term) нҷ•мқё - facet
24
$ curl 'localhost:9200/books/_search
?pretty' -d '
{
"facets" : {
"author_terms" : {
"terms" : { "field" : "author" }
}
}
}'
"facets" : {
"author_terms" : {
вҖҰ мӨ‘лһө вҖҰ
"terms" : [ {
"term" : "william",
"count" : 2
}, {
"term" : "shakespeare",
"count" : 2
}, {
"term" : "twain",
"count" : 1
}, {
"term" : "mark",
"count" : 1
} ]](https://image.slidesharecdn.com/random-150604213006-lva1-app6891/85/-24-320.jpg)




![н…Җ(Term) нҷ•мқё - facet
29
$ curl 'localhost:9200/books/_search
?pretty' -d '
{
"facets" : {
"author_terms" : {
"terms" : { "field" : "author" }
}
}
}'
"facets" : {
"author_terms" : {
"_type" : "terms",
"missing" : 0,
"total" : 3,
"other" : 0,
"terms" : [ {
"term" : "William Shakespeare",
"count" : 2
}, {
"term" : "Mark Twain",
"count" : 1
} ]
}
}](https://image.slidesharecdn.com/random-150604213006-lva1-app6891/85/-29-320.jpg)





![м• л„җлқјмқҙм Җ API - _analyze
35
$ curl -XPOST 'http://localhost:9200/books/_analyze?tokenizer=whitespace&filters
=lowercase,stop&pretty' -d 'Around the World in Eighty Days'
{
"tokens" : [ {
"token" : "around", "start_offset" : 0, "end_offset" : 6, "type" : "word", "position" : 1
}, {
"token" : "world", "start_offset" : 11, "end_offset" : 16, "type" : "word", "position" : 3
}, {
"token" : "eighty", "start_offset" : 20, "end_offset" : 26, "type" : "word", "position" : 5
}, {
"token" : "days", "start_offset" : 27, "end_offset" : 31, "type" : "word", "position" : 6
} ]
}](https://image.slidesharecdn.com/random-150604213006-lva1-app6891/85/-35-320.jpg)
![мӮ¬мҡ©мһҗ м •мқҳ м• л„җлқјмқҙм Җ
36
$ curl -XPOST 'localhost:9200/books/_analyze?analyzer=my_analyzer&pretty' -d 'A
round the World in Eighty Days'
curl -XPUT 'http://localhost:9200/books' -d '
{
"settings" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"tokenizer" : "whitespace",
"filter" : [ "lowercase", "stop" ]
}
}
}
}
}'](https://image.slidesharecdn.com/random-150604213006-lva1-app6891/85/-36-320.jpg)









![46
лЎңк·ёмҠӨнғңмӢң (Logstash)
{ "id":"kimjmin", "name":"Jongmin Kim", "age":35 }
curl localhost:9200/tests/_search?pretty
вҖҰ
"hits" : [ {
"_index" : "tests",
"_type" : "test-2015.06.02",
"_id" : "kimjmin",
"_score" : 1.0,
"_source":{"id":"kimjmin","name":"Jongmin Kim","age":35,"@version":"1","@timesta
mp":"2015-06-02T08:44:47.877Z","host":"Jongminui-MacBook-Pro.local"}
} ]](https://image.slidesharecdn.com/random-150604213006-lva1-app6891/85/-46-320.jpg)


![49
лЎңк·ёмҠӨнғңмӢң (Logstash)
вҖў кіөнҶө
вҖў add_field => { "comment" => "My name is %{name}" }
вҖў remove_field => [ "name", "age" ]
вҖў grok
вҖў match => { "message" => "Duration: %{NUMBER:duration}" }
вҖў mutate
вҖў convert => { вҖңage" => "integer" }
вҖў lowercase => [ "name" ]
вҖў split => { "fieldname" => "," }](https://image.slidesharecdn.com/random-150604213006-lva1-app6891/85/-49-320.jpg)

















![[OpenInfra Days Korea 2018] (Track 4) - GrafanaлҘј мқҙмҡ©н•ң OpenStack нҒҙлқјмҡ°л“ң м„ұлҠҘ лӘЁлӢҲн„°л§Ғ](https://cdn.slidesharecdn.com/ss_thumbnails/42openinfraday201820180626grafana-180704055533-thumbnail.jpg?width=560&fit=bounds)
![[мҳӨн”ҲмҶҢмҠӨм»Ём„ӨнҢ…] мҝ лІ„л„ӨнӢ°мҠӨмҷҖ мҝ лІ„л„ӨнӢ°мҠӨ on мҳӨн”ҲмҠӨнғқ 비көҗ л°Ҹ кө¬м¶• л°©лІ•](https://cdn.slidesharecdn.com/ss_thumbnails/osck8svsk8sonopenstackkhoj-210310051504-thumbnail.jpg?width=560&fit=bounds)
![[2D1]Elasticsearch б„үб…ҘбҶјб„Ӯб…ібҶј б„Һб…¬б„Ңб…ҘбҶЁб„’б…Ә](https://cdn.slidesharecdn.com/ss_thumbnails/2d1elasticsearch-140929192211-phpapp02-thumbnail.jpg?width=560&fit=bounds)












![[мҳӨн”ҲмҶҢмҠӨм»Ём„ӨнҢ…]мҳӨн”ҲмҠӨнғқм—җ лҢҖн•ҳм—¬](https://cdn.slidesharecdn.com/ss_thumbnails/random-151125103039-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)

![[OpenStack] кіөк°ң мҶҢн”„нҠёмӣЁм–ҙ мҳӨн”ҲмҠӨнғқ мһ…л¬ё & нҢҢн—Өм№ҳкё°](https://cdn.slidesharecdn.com/ss_thumbnails/opensource-skimmingopenstackwithkoreausergroup-180824144737-thumbnail.jpg?width=560&fit=bounds)






![[Pgday.Seoul 2017] 6. GIN vs GiST мқёлҚұмҠӨ мқҙм•јкё° - 박진мҡ°](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106044702-thumbnail.jpg?width=560&fit=bounds)

![[Elasticsearch] кІҖмғүмқҳ м—°кҙҖм„ұ мўҖ лҚ” лҶ’м—¬ліҙкё°](https://cdn.slidesharecdn.com/ss_thumbnails/searching-with-relevancy-141230230553-conversion-gate02-thumbnail.jpg?width=560&fit=bounds)
More Related Content
What's hot (20)
Viewers also liked (7)





Similar to б„Ӣб…ҰбҶҜб„…б…Ўб„үб…іб„җб…өбҶЁб„үб…Ҙб„Һб…ө, лЎңк·ёмҠӨнғңмӢң, нӮӨл°”лӮҳ (20)
















![NaverмҶҚлҸ„мқҳ, мҶҚлҸ„м—җ мқҳн•ң, мҶҚлҸ„лҘј мң„н•ң лӘҪкі DB (л„ӨмқҙлІ„ м»Ён…җмё кІҖмғүкіј лӘҪкі DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=560&fit=bounds)



б„Ӣб…ҰбҶҜб„…б…Ўб„үб…іб„җб…өбҶЁб„үб…Ҙб„Һб…ө, лЎңк·ёмҠӨнғңмӢң, нӮӨл°”лӮҳ
- 1. м—ҳлқјмҠӨнӢұм„ңм№ҳ к№Җмў…лҜј мқҙл©”мқј : jongmin.kim@elastic.co лё”лЎңк·ё : http://kimjmin.net 1
- 2. м—ҳлқјмҠӨнӢұм„ңм№ҳ - Elasticsearch вҖў http://elastic.co вҖў Open Source - https://github.com/elastic/elasticsearch вҖў Java вҖў Apache Lucene вҖў Restful вҖў JSON Document Based вҖў Real-time Search вҖў Full-text Search 2
- 3. Use Cases вҖў Github, SourceforgeвҖҰ 3
- 4. Use Cases - Netflix 4
- 5. лҚ°мқҙн„° м ҖмһҘ вҖ“ кҙҖкі„ DB PK Text Doc 1 blue sky green land red sun Doc 2 blue ocean green land Doc 3 red flower blue sky 5 вҖў PK, Index, м№јлҹјмқ„ кё°мӨҖмңјлЎң мҲңм„ңлҢҖлЎң кІҖмғү.
- 6. лҚ°мқҙн„° м ҖмһҘ вҖ“ м—ӯнҢҢмқј мғүмқё 6 кІҖмғүм–ҙ (term) кІҖмғүм–ҙк°Җ к°ҖлҰ¬нӮӨлҠ” лҢҖмғҒ л¬ём„ң кІҖмғүм–ҙ (term) кІҖмғүм–ҙк°Җ к°ҖлҰ¬нӮӨлҠ” лҢҖмғҒ л¬ём„ң blue Doc 1, Doc 2, Doc 3 red Doc 1, Doc 3 sky Doc 1, Doc 3 ocean Doc 2 green Doc 1, Doc 2 flower Doc 3 land Doc 1, Doc 2 sun Doc 1 вҖў ліёл¬ёмқҳ кІҖмғүм–ҙлҘј лЁјм Җ 추м¶ңн•ң л’Ө кІҖмғүм–ҙм—җ н•ҙлӢ№н•ҳлҠ” л¬ём„ң лҘј м°ҫмқҢ
- 7. лҚ°мқҙн„° м ҖмһҘ н”„лЎңм„ёмҠӨ 7 мӣҗліё н…ҚмҠӨнҠё мғүмқё кіөк°„ (index) мғүмқё кіјм • (indexing) н…ҚмҠӨнҠё 분м„қ мғүмқём—җ 추к°Җ кІҖмғү (searching) м§Ҳмқҳ мғқм„ұ кІ°кіј м¶ңл Ҙ
- 8. кҙҖкі„DB vs м—ҳлқјмҠӨнӢұм„ңм№ҳ HTTP CRUD SQL GET Read Select PUT Update Update POST Create Insert DELETE Delete Delete 8 кҙҖкі„ DB м—ҳлқјмҠӨнӢұм„ңм№ҳ лҚ°мқҙн„°лІ мқҙмҠӨ (Database) мқёлҚұмҠӨ (index) н…Ңмқҙлё”(Table) нғҖмһ…(Type) м—ҙ(Row) лҸ„нҒҗлЁјнҠё (Document) н–ү(Column) н•„л“ң(Field) мҠӨнӮӨл§Ҳ(Schema) л§Өн•‘(Mapping)
- 9. Restful API вҖў лӢЁмқј URLлҘј нҶөн•ң мһҗмӣҗмқҳ м ‘к·ј вҖў http л©”мҶҢл“ңлҘј мқҙмҡ©н•ҙм„ң мһҗмӣҗ мІҳлҰ¬ вҖў Not Rest вҖў 추к°Җ : http://site.com/user.jsp?cmd=add&id=user1&name=kim вҖў мЎ°нҡҢ : http://site.com/user.jsp?id=user1 вҖў мҲҳм • : http://site.com/user.jsp?cmd=modify&id=user1&name=lee вҖў мӮӯм ң : http://site.com/user.jsp?cmd=delete&id=user1 вҖў Rest вҖў 추к°Җ : -POST http://site.com/user/user1 {name:kim} вҖў мЎ°нҡҢ : -GET http://site.com/user/user1 вҖў мҲҳм • : -PUT http://site.com/user/user1 {name:lee} вҖў мӮӯм ң : -DELETE http://site.com/user/user1 9
- 10. м—ҳлқјмҠӨнӢұм„ңм№ҳ Rest API вҖў http://host:port/мқёлҚұмҠӨ/нғҖмһ…/лҸ„нҒҗлЁјнҠё id вҖў curl -XвҖҳл©”м„ңл“ңвҖҷ http://host:port/мқёлҚұмҠӨ/нғҖмһ…/лҸ„нҒҗлЁјнҠё id -d вҖҳ{лҚ°мқҙн„°}вҖҷ 10 $ curl -XPUT http://localhost:9200/books/book/1 -d ' { "title" : "Elasticsearch Guide", "author" : "Kim", "date" : "2014-05-01", "pages" : 250 } ' {"_index":"books","_type":"book","_id":"1","_version":1,"created":true}
- 11. м—ҳлқјмҠӨнӢұм„ңм№ҳ Rest API 11 $ curl -XGET http://localhost:9200/books/book/1 {"_index":"books","_type":"book","_id":"1","_version":1,"found":true, "_source" : { "title" : "Elasticsearch Guide", "author" : "Kim", "date" : "2014-05-01", "pages" : 250 } }
- 12. нҒҙлҹ¬мҠӨн„°(cluster) вҖў м—ҳлқјмҠӨнӢұм„ңм№ҳ мӢңмҠӨн…ңмқҳ к°ҖмһҘ нҒ° лӢЁмң„ вҖў н•ҳлӮҳмқҳ нҒҙлҹ¬мҠӨн„°лҠ” лӢӨмҲҳмқҳ л…ёл“ңлЎң кө¬м„ұ вҖў н•ҳлӮҳмқҳ нҒҙлҹ¬мҠӨн„°лҘј лӢӨмҲҳмқҳ м„ңлІ„лЎң л°”мқёл”© н•ҙм„ң мҡҙмҳҒ, лҳҗлҠ” м—ӯмңјлЎң н•ҳлӮҳмқҳ м„ңлІ„м—җм„ң лӢӨмҲҳмқҳ нҒҙлҹ¬мҠӨн„° мҡҙмҡ© к°ҖлҠҘ 12 config/elasticsearch.yml cluster.name: elasticsearch $ bin/elasticsearch --cluster.name=elasticsearch
- 13. л…ёл“ң (Node) вҖў м—ҳлқјмҠӨнӢұм„ңм№ҳлҘј кө¬м„ұн•ҳлҠ” н•ҳлӮҳмқҳ лӢЁмң„ н”„лЎңм„ёмҠӨ вҖў лӢӨмҲҳмқҳ мғӨл“ңлЎң кө¬м„ұлҗЁ вҖў к°ҷмқҖ нҒҙлҹ¬мҠӨн„°лӘ…мқ„ к°Җ진 л…ёл“ңл“ӨмқҖ мһҗлҸҷмңјлЎң л°”мқёл”© лҗЁ 13 config/elasticsearch.yml node.name: "Node1" $ bin/elasticsearch --node.name=Node1
- 14. л…ёл“ң (Node) вҖў http нҶөмӢ нҸ¬нҠё : 9200~ м°ЁлЎҖлҢҖлЎң мҰқк°Җ вҖў л…ёл“ң к°„ лҚ°мқҙн„° көҗнҷҳ нҸ¬нҠё : 9300~ м°ЁлЎҖлҢҖлЎң мҰқк°Җ 14 нҒҙлҹ¬мҠӨн„° : elasticsearch Node1 Node2 9300 9301 9200 9201 REST API REST API
- 15. head н”Ңлҹ¬к·ёмқё 15 $ bin/plugin --install mobz/elasticsearch-head
- 16. нҒҙлҹ¬мҠӨн„° : elasticsearch Node1 Node2 9300 9301 9200 9201 REST API нҒҙлҹ¬мҠӨн„° : elasticsearch2 Node3 9302 9202 REST API $ bin/elasticsearch --cluster.name=elasticsearch --node.name=Node1 $ bin/elasticsearch --cluster.name=elasticsearch --node.name=Node2 $ bin/elasticsearch --cluster.name=elasticsearch2 --node.name=Node3 16
- 17. master node & data node вҖў л§ҲмҠӨн„° л…ёл“ң : нҒҙлҹ¬мҠӨн„° мғҒнғң кҙҖлҰ¬ вҖў лҚ°мқҙн„° л…ёл“ң : лҚ°мқҙн„° мһ…/м¶ңл Ҙ, кІҖмғү мҲҳн–ү 17 config/elasticsearch.yml node.master: true node.data: true $ bin/elasticsearch --node.master=true --node.data=true
- 18. $ bin/elasticsearch --node.name=Node1 --node.master=true --node.data=false $ bin/elasticsearch --node.name=Node2 --node.master=false --node.data=true $ bin/elasticsearch --node.name=Node3 --node.master=false --node.data=true $ bin/elasticsearch --node.name=Node4 --node.master=false --node.data=true 18
- 19. мғӨл“ң (shard) & л Ҳн”ҢлҰ¬м№ҙ (replica) вҖў мғӨл“ң : лҚ°мқҙн„° кІҖмғү лӢЁмң„ мқёмҠӨн„ҙмҠӨ вҖў л Ҳн”ҢлҰ¬м№ҙ : мғӨл“ңмқҳ ліөмӮ¬ліё 19 config/elasticsearch.yml index.number_of_shards: 5 index.number_of_replicas: 1 $ curl -XPUT localhost:9200/books -d ' { "settings" : { "number_of_shards" : 5, "number_of_replicas" : 1 } }'
- 20. кІҖмғү 20 $ curl -XPUT localhost:9200/books/book/1 -d ' { "title": "Romeo and Juliet", "author": "William Shakespeare", "category":"Tr agedies", "written": "1562-12-01T20:40:00", "pages" : 125 }' $ curl -XPUT localhost:9200/books/book/3 -d ' { "title": "The Prince and the Pauper", "author": "Mark Twain", "category":"Children literature", "written": "1881-08-01T10:34:00", "pages" : 79}' $ curl -XPUT localhost:9200/books/book/2 -d ' { "title" : "Hamlet", "author": "William Shakespeare", "category":"Tragedies", "written": "1599-06-01T12:34:00", "pages" : 172 }'
- 21. кІҖмғү 21 $ curl localhost:9200/books/_search?pretty=true { вҖҰ мӨ‘лһө вҖҰ }, "hits" : { "total" : 3, "max_score" : 1.0, "hits" : [ { вҖҰ мӨ‘лһө вҖҰ "_source": { "title": "Romeo and Juliet", "author": "William Shakespeare", "category":"Tragedies", "written ": "1562-12-01T20:40:00", "pages" : 125 } }, вҖҰ мӨ‘лһө вҖҰ
- 22. кІҖмғү - URI кІҖмғү 22 $ curl 'http://localhost:9200/books/_search?q=william&pretty=true' $ curl 'http://localhost:9200/books/_search?q=author:william&pretty=true' $ curl 'http://localhost:9200/books/_search?q=author:william&fields=title,auth or,pages&pretty=true'
- 23. кІҖмғү - Request Body кІҖмғү 23 $ curl 'http://localhost:9200/books/_search?pretty=true' -d ' { "query" : { "match" : { "author" : "William" } } }'
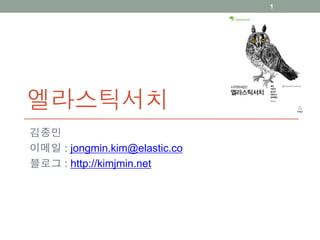
- 24. н…Җ(Term) нҷ•мқё - facet 24 $ curl 'localhost:9200/books/_search ?pretty' -d ' { "facets" : { "author_terms" : { "terms" : { "field" : "author" } } } }' "facets" : { "author_terms" : { вҖҰ мӨ‘лһө вҖҰ "terms" : [ { "term" : "william", "count" : 2 }, { "term" : "shakespeare", "count" : 2 }, { "term" : "twain", "count" : 1 }, { "term" : "mark", "count" : 1 } ]
- 25. н…Җ(Term) 25 кІҖмғүм–ҙ (term) кІҖмғүм–ҙк°Җ к°ҖлҰ¬нӮӨлҠ” лҢҖмғҒ л¬ём„ң william books/book/1, books/book/2 shakespeare books/book/1, books/book/2 twain books/book/3 mark books/book/3
- 26. кІҖмғү - Request Body кІҖмғү 26 $ curl 'http://localhost:9200/books/_search?pretty=true' -d ' { "query" : { "match" : { "author" : "William" } } }' $ curl 'http://localhost:9200/books/_search?pretty=true' -d ' { "query" : { "term" : { "author" : "William" } } }'
- 27. л§Өн•‘ 27 $ curl -XPUT localhost:9200/books -d ' { "mappings" : { "book" : { "properties" : { "author" : { "type" : "string", "index" : "not_analyzed" } } } } }'
- 28. 28 $ curl -XPUT localhost:9200/books/book/1 -d ' { "title": "Romeo and Juliet", "author": "William Shakespeare", "category":"Tr agedies", "written": "1562-12-01T20:40:00", "pages" : 125 }' $ curl -XPUT localhost:9200/books/book/3 -d ' { "title": "The Prince and the Pauper", "author": "Mark Twain", "category":"Children literature", "written": "1881-08-01T10:34:00", "pages" : 79}' $ curl -XPUT localhost:9200/books/book/2 -d ' { "title" : "Hamlet", "author": "William Shakespeare", "category":"Tragedies", "written": "1599-06-01T12:34:00", "pages" : 172 }'
- 29. н…Җ(Term) нҷ•мқё - facet 29 $ curl 'localhost:9200/books/_search ?pretty' -d ' { "facets" : { "author_terms" : { "terms" : { "field" : "author" } } } }' "facets" : { "author_terms" : { "_type" : "terms", "missing" : 0, "total" : 3, "other" : 0, "terms" : [ { "term" : "William Shakespeare", "count" : 2 }, { "term" : "Mark Twain", "count" : 1 } ] } }
- 30. кІҖмғү - Request Body кІҖмғү 30 $ curl 'http://localhost:9200/books/_search?pretty=true' -d ' { "query" : { "term" : { "author" : "William Shakespeare" } } }'
- 31. 분м„қ(Analyze) вҖў м• л„җлқјмқҙм Җ(Analyzer)лҘј мқҙмҡ©н•ҙм„ң мһ…л Ҙлҗң л¬ёмһҘмқ„ н…Җ(term) мңјлЎң 분н•ҙн•ҳлҠ” кіјм • вҖў 1 к°ңмқҳ нҶ нҒ¬лӮҳмқҙм Җ (Tokenizer) вҖў 0~n к°ңмқҳ нҶ нҒ° н•„н„° (Token Filter) 31
- 32. нҶ нҒ¬лӮҳмқҙм Җ(Toknizer) вҖў Whitespace нҶ нҒ¬лӮҳмқҙм Җ - кіөл°ұ, нғӯ, к°ңн–ү л¬ёмһҗ л“ұмқ„ кё°мӨҖмңј лЎң л¬ёмһҘ 분лҰ¬. 32 Around the World in Eighty Days Whitespace Around the World in Eighty Days
- 33. нҶ нҒ°н•„н„°(Token Filter) вҖў Lowercase нҶ нҒ°н•„н„° - мҶҢл¬ёмһҗлЎң ліҖнҷҳ 33 Lowercase around the world in eighty days Around the World in Eighty Days
- 34. нҶ нҒ°н•„н„°(Token Filter) вҖў Stop нҶ нҒ° н•„н„° - stopword л°°м ң 34 Stop around world eighty days around the world in eighty days
- 35. м• л„җлқјмқҙм Җ API - _analyze 35 $ curl -XPOST 'http://localhost:9200/books/_analyze?tokenizer=whitespace&filters =lowercase,stop&pretty' -d 'Around the World in Eighty Days' { "tokens" : [ { "token" : "around", "start_offset" : 0, "end_offset" : 6, "type" : "word", "position" : 1 }, { "token" : "world", "start_offset" : 11, "end_offset" : 16, "type" : "word", "position" : 3 }, { "token" : "eighty", "start_offset" : 20, "end_offset" : 26, "type" : "word", "position" : 5 }, { "token" : "days", "start_offset" : 27, "end_offset" : 31, "type" : "word", "position" : 6 } ] }
- 36. мӮ¬мҡ©мһҗ м •мқҳ м• л„җлқјмқҙм Җ 36 $ curl -XPOST 'localhost:9200/books/_analyze?analyzer=my_analyzer&pretty' -d 'A round the World in Eighty Days' curl -XPUT 'http://localhost:9200/books' -d ' { "settings" : { "analysis" : { "analyzer" : { "my_analyzer" : { "tokenizer" : "whitespace", "filter" : [ "lowercase", "stop" ] } } } } }'
- 38. н•ңкёҖ нҳ•нғңмҶҢ 분м„қкё° 38 н•ңкёҖ нҳ•нғңмҶҢ лҸҷн•ҙ лҸҷн•ҙл¬ј лҸҷн•ҙл¬јкіј л°ұл‘җ л°ұл‘җмӮ° л°ұл‘җмӮ°мқҙ лҸҷн•ҙл¬јкіј л°ұл‘җмӮ°мқҙ
- 39. м—ҳлқјмҠӨнӢұм„ңм№ҳ мӮ¬мҡ©мӢң кі л ӨмӮ¬н•ӯ вҖў м ҖмһҘн• лҚ°мқҙн„° нҳ•нғңмҷҖ кІҖмғү кІ°кіј м„Өкі„ вҖў лҚ°мқҙн„° л§Өн•‘ кө¬мЎ°мҷҖ м• л„җлқјмқҙм Җ м„Өкі„ вҖў м ҖмһҘн• лҚ°мқҙн„°мқҳ мң нҡЁм„ұ кІҖмҰқ вҖў мӣҗліё лҚ°мқҙн„° ліҙкҙҖc 39
- 40. лЎңк·ёмҠӨнғңмӢң (Logstash) 40 лЎңк·ёмҠӨнғңмӢңн‘ңмӨҖ мһ…л Ҙ нҢҢмқј Syslog н‘ңмӨҖ м¶ңл Ҙ нҢҢмқј м—ҳлқјмҠӨнӢұм„ңм№ҳ вҖҰ вҖҰ input filter output Network (TCP/UDP) Email Twitter
- 42. 42 лЎңк·ёмҠӨнғңмӢң (Logstash) $ bin/logstash -f standard.confstandard.conf input { stdin { } } output { stdout { } } вҖў н‘ңмӨҖ мһ…л Ҙ пғ н‘ңмӨҖ м¶ңл Ҙ Hello World 2015-06-01T07:19:27.594Z Jongminui- MacBook-Pro.local Hello World
- 43. 43 лЎңк·ёмҠӨнғңмӢң (Logstash) вҖў н‘ңмӨҖ мһ…л Ҙ пғ н‘ңмӨҖ м¶ңл Ҙ {codec => json} standard.conf input { stdin { } } output { stdout { codec => json } } Hello World {"message":"Hello World","@version":"1 ","@timestamp":"2015-06-01T07:21:33. 876Z","host":"Jongminui-MacBook-Pro.l ocal"}
- 44. 44 лЎңк·ёмҠӨнғңмӢң (Logstash) вҖў н‘ңмӨҖ мһ…л Ҙ {codec => json} пғ н‘ңмӨҖ м¶ңл Ҙ {codec => json} standard.conf input { stdin { codec => json } } output { stdout { codec => json } } { "name":"Jongmin Kim", "age":35 } {"name":"Jongmin Kim","age":35,"@ver sion":"1","@timestamp":"2015-06-01T07 :25:52.784Z","host":"Jongminui-MacBoo k-Pro.local"}
- 45. 45 лЎңк·ёмҠӨнғңмӢң (Logstash) вҖў м—ҳлқјмҠӨнӢұм„ңм№ҳ м¶ңл Ҙ elasticsearch.conf output { elasticsearch { cluster => "elasticsearch" node_name => "node-logstash" index => "tests" document_type => "test- %{+YYYY.MM.dd}" id => "%{id}" } }
- 46. 46 лЎңк·ёмҠӨнғңмӢң (Logstash) { "id":"kimjmin", "name":"Jongmin Kim", "age":35 } curl localhost:9200/tests/_search?pretty вҖҰ "hits" : [ { "_index" : "tests", "_type" : "test-2015.06.02", "_id" : "kimjmin", "_score" : 1.0, "_source":{"id":"kimjmin","name":"Jongmin Kim","age":35,"@version":"1","@timesta mp":"2015-06-02T08:44:47.877Z","host":"Jongminui-MacBook-Pro.local"} } ]
- 47. 47 лЎңк·ёмҠӨнғңмӢң (Logstash) вҖў нҢҢмқј мһ…л Ҙ standard.conf input { file { codec => json path => "/Users/kimjmin/git/elastic-demo/data/*.log" } }
- 48. 48 лЎңк·ёмҠӨнғңмӢң (Logstash) - Filter вҖў мһ…л Ҙ лҚ°мқҙн„°лҘј 분н•ҙ, 추к°Җ, мӮӯм ң, ліҖнҳ• л“ұмқҳ кіјм •мқ„ кұ°м№ң л’Ө м¶ңл ҘмңјлЎң м „мҶЎ вҖў grok, mutate, date вҖҰ вҖў мһ…л Ҙн•ң мҲңм„ң лҢҖлЎң мң„м—җм„ң л¶Җн„° м°ЁлЎҖлҢҖлЎң м Ғмҡ©лҗЁ
- 49. 49 лЎңк·ёмҠӨнғңмӢң (Logstash) вҖў кіөнҶө вҖў add_field => { "comment" => "My name is %{name}" } вҖў remove_field => [ "name", "age" ] вҖў grok вҖў match => { "message" => "Duration: %{NUMBER:duration}" } вҖў mutate вҖў convert => { вҖңage" => "integer" } вҖў lowercase => [ "name" ] вҖў split => { "fieldname" => "," }
- 50. 50 лЎңк·ёмҠӨнғңмӢң (Logstash) вҖў grok filter.conf filter { grok { match => { "message" => "%{IP:client} %{WORD:method} %{ URIPATHPARAM:request} %{NUMB ER:bytes} %{NUMBER:duration}" } } } 55.3.244.1 GET /index.html 15824 0.0 43 {"message":"55.3.244.1 GET /index.htm l 15824 0.043","@version":"1","@timest amp":"2015-06-03T05:25:30.529Z","hos t":"Jongminui-MacBook-Pro.local","clien t":"55.3.244.1","method":"GET","request ":"/index.html","bytes":"15824","duration ":"0.043"}
- 51. нӮӨл°”лӮҳ (Kibana) - 3 51
- 52. нӮӨл°”лӮҳ (Kibana) - 3 вҖў Only HTML, Javascript (AngularJS) вҖў нҒҙлқјмқҙм–ёнҠём—җм„ң мӢӨн–ү вҖў 9200 нҸ¬нҠё к°ңл°© н•„мҡ” - ліҙм•Ҳм—җ м·Ём•Ҫ вҖў лі„лҸ„ мӣ№м„ңлІ„ н•„мҡ”. Tomcat, Nginx л“ұ. вҖў Facet based 52
- 53. нӮӨл°”лӮҳ (Kibana) - 4 вҖў Elasticsearch 1.4.4 мқҙмғҒ н•„мҡ”. вҖў NodeJS м„ңлІ„ мӮ¬мҡ© - port : 5601 вҖў Aggregation based. 53 bin/kibana
- 54. нӮӨл°”лӮҳ (Kibana) - 4 вҖў кё°мӨҖ index, time-field м„Өм •. 54
- 55. нӮӨл°”лӮҳ (Kibana) - 4 вҖў Discover пғ Time Filter м„Өм • 55
- 56. нӮӨл°”лӮҳ (Kibana) - 4 56
- 57. нӮӨл°”лӮҳ (Kibana) - 4 57
- 58. нӮӨл°”лӮҳ (Kibana) - 4 58
- 59. нӮӨл°”лӮҳ (Kibana) - 4 59
- 60. нӮӨл°”лӮҳ (Kibana) - 4 60
- 61. нӮӨл°”лӮҳ (Kibana) - 4 вҖў Visualize нғӯм—җм„ң лҜёлҰ¬ м ҖмһҘн•ң мӢңк°Ғ лҸ„кө¬лҘј к°Җм§Җкі Dashboard нғӯм—җм„ң лҢҖмӢңліҙл“ң мһ‘м„ұ. 61
- 62. нӮӨл°”лӮҳ (Kibana) - 4 62