ХфЫЭзюЪЪЛЏ
Download as pptx, pdf1 like2,860 views

The overview of optimization problems and vehicle routing problems














![1. ЅЭЅУЅШЅяЉ`ЅЏЄЮЬие
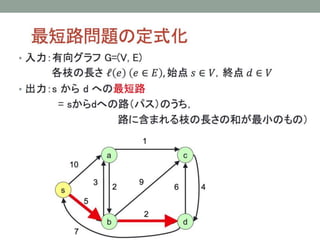
? ссЄЫЄЄВЄыCVRPЄЯЁЂЕуЄЮщgЄЮвЦгЄђПМЄЈЄыю}
? Arc Routing Problem ЄЮіКЯЄЯЁЂconnection ЄоЄПЄЯ link ЄШ
бдЄяЄьЄыЁЂЕРЄЮЅЛЅАЅсЅѓЅШЄђПМЄЈЄы
? Р§ЃЉ ЖЌЄЮбЉЄЋЄЁЂр]БуХфп_ЃЈЕРЄЪЄъЄЫНьЄБЯШЄЌУмМЏЄЗЄЦЄЄЄыЄЮЄЧЃЉ](https://image.slidesharecdn.com/random-150711104312-lva1-app6891/85/-25-320.jpg)










![ЄЊЄоЄБЃКAlgorithms for the Capacitated
VRP(2)
branch-and-cut-and-price(2004)ЄЮАkеЙ
? ЅжЅщЅѓЅС=жІЄЮЗжИю
? ЅЋЅУЅШ=ЅАЅщЅеРэеЄЫЄЊЄБЄыЗжИюМЏКЯ
? ЅзЅщЅЄЅЙ=ЅщЅАЅщЅѓЅИЅхЄЮЮДЖЈ\Ъ§ЗЈЄЧІЫ
ЄђЧѓЄсЄЦжиЄпЄХЄБ
? Ёіcolumn generation
? ЩЯЮЛю}ЃКKЬЈЄЮпxkЅыЉ`ЅШЄЮОрыxЄЮзю
аЁЛЏ
? ЯТЮЛю}ЃКОрыxЄЮЖЬЄЄЅыЉ`ЅШШКЄЮЩњГЩ
? ?ШнСПcЄђКснSЃЌэЕуЄђПkнSЄЫЄШЄУЄПааСа
MЄЧэЕуvЄоЄЧЄЮЕРЄШЄНЄЮыHЄЮОtашвЊdЄђ
БэЄЙЃЎ
? DPЄЧЕРЄђаЮГЩЄЗЄЦЄЄЄЏ
? w(vЄЮНќАјЕу)ЄђvЄЮДЮЄЫзЗМгЄЙЄыЄЋЄЩЄІ
ЄЋЄђХаЖЯЄЗЄЦМгЄЈЄЦЄЄЄЏЃЎ
? ааСаЄЮжаЄЮЕуЄЮЪ§ЄЌncЄЪЄЮЄЧncЛиРR
ЄъЗЕЄЛЄаЕРЄЌ1БОЄЧЄЄыЃЎЅыЉ`ЅШЄЮБОЪ§ЄЯ
nБОЄЧ
? ЄЄыЄЮЄЧcn2ЛиЄЧгЫуПЩФмЃЎ
? Ёіcolumn generationЄЮИпЫйЛЏЃК
? ЯїГ§ЃКЭЈп^ЕуЄђгЄЗЄЦщ]ТЗЄШЄЪЄУЄЦЄЄЄы
ЄЋЄђХаЖЯ
? Ё№ЅвЅхЉ`ЅъЅЙЅЦЅЃЅУЅЏМгЫй
? sparsificationЃК1ЄФЄЮЅАЅщЅеЄђ5ЄФЄЫЗжИю
ЄЗЃЌSpanning treeЄђЄЂЄщЄЋЄИЄсдOЖЈЄЙ
? ЄыЃЎ
? ЁіCut generation
? ЅЋЅУЅШЅЛЅУЅШЄЮоxЄЮЪ§ЄђжУЄЄЄЦЄЄЄПЄЌЃЌЄН
ЄЮЅЋЅУЅШЅЛЅУЅШЄЮЩњГЩЄђааЄІЃЎ
? жмЛиШнСПжЦМsЄЫзюпmЛЏгЫуЄЮжЦМsЬѕМў
ЄЧЄЯЄЪЄЏЃЌeЭОЅЂЅыЅДЅъЅКЅрЄђдOЖЈЄЙЄыЃЎ
? ЧаЖЯМЏКЯЄЫЪєЄЙЄыЄПЄсЄЮЬѕМў?MЄЌгыЄЈ
ЄщЄьЄПrЄЮS,yЄђГщГіЄЙЄыЬѕМўЄђжЦМsЬѕ
МўЄШЄЗ
? ЄЦГіШыЄъЄЮоxЄЮЪ§ЄђзюаЁЛЏЄЙЄыЃЎ](https://image.slidesharecdn.com/random-150711104312-lva1-app6891/85/-36-320.jpg)
ХфЫЭзюЪЪЛЏ
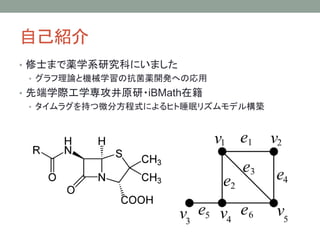
- 2. здМКНBНщ ? аоЪПЄоЄЧЫaбЇЯЕбаОППЦЄЫЄЄЄоЄЗЄП ? ЅАЅщЅеРэеЄШCаЕбЇСЄЮПЙОњЫaщ_АkЄиЄЮъгУ ? ЯШЖЫбЇыHЙЄбЇЙЅОЎдба?iBMathдкМЎ ? ЅПЅЄЅрЅщЅАЄђГжЄФЮЂЗжЗНГЬЪНЄЫЄшЄыЅвЅШЫЏУпЅъЅКЅрЅтЅЧЅыКB
- 3. БОШеЄЮФкШн ? Ъ§РэзюпmЛЏИХвЊ ? ЃЈБивЊЄЌЄЂЄьЄаPЁйNPЄЫЄФЄЄЄЦЄтЃЉ ? нЫЭзюпmЛЏю}ЃЈVRPЃЉЄЮИХвЊ ? VRPЄЮОпЬхР§
- 4. ЅтЅЧЅъЅѓЅАЄЮЄПЄсЄЮЪЎНф 1. ЅтЅЧЅыЄђ gМЛЏЄЛЄшЃЎ 2. аЁЄЕЄЪЅтЅЧЅыЄЋЄщЪМЄсЄшЃЎ 3. ЅЧЉ`ЅПЄЌЄШЄьЄЪЄЄЄшЄІЄЪЅтЅЧЅыЄђзїГЩЄЙЄыЄЪЄЋЄьЃЎ 4. ЪжГжЄСЄЮЅЧЉ`ЅПЄЫЄЂЄІЄшЄІЄЪЅтЅЧЅыЄђзїГЩЄЙЄыЄЪЄЋЄьЃЎ 5. б}ыjЄЪЅтЅЧЅыЄЯЗжИюЄЗЄЦНтQЄЛЄшЃЎ 6. ЫЪЅтЅЧЅыЄиЄЮЂзХЄђПМЄЈЄшЃЎ 7. ЅтЅЧЅыЄђГщЯѓЛЏЄЗЄЦБэЌFЄЛЄшЃЎ 8. ЩЄЋЄщЭбГіЄЙЄыыHЄЫФОЄаЄЋЄъЄпЄыЄЪЄЋЄьЃЎ 9. НтЄЏЄПЄсЄЮЪжЗЈЄЮЄГЄШЄђПМЄЈЄЦЅтЅЧЅыЄђзїГЩЄЛЄшЃЎ 10. ЪжГжЄСЄЮЪжЗЈЄЋЄщЅтЅЧЅыЄђзїГЩЄЙЄыЄЪЄЋЄьЃЎ дМЄЯЁИЅтЅЧЅъЅѓЅАЄЮЄПЄсЄЮвЄЈјЄЁЙ ЅЊЅкЅьЉ`ЅЗЅчЅѓЅК?ЅъЅЕЉ`ЅС ЃДдТКХ Vol.50 No.4 2005
- 5. БОШеЄЮФкШн ? Ъ§РэзюпmЛЏИХвЊ ? ЃЈБивЊЄЌЄЂЄьЄаPЁйNPЄЫЄФЄЄЄЦЄтЃЉ ? нЫЭзюпmЛЏю}ЃЈVRPЃЉЄЮИХвЊ ? VRPЄЮОпЬхР§
- 7. Ъ§РэгЛю} ? ЯпаЮМЦЛЮЪЬт ? ЅЭЅУЅШЅяЉ`ЅЏгЛю} ? ЗЧЯпаЮМЦЛЮЪЬт ? НMКЯЄЛгЛю}
- 8. ЯпаЮМЦЛЮЪЬт
- 22. БОШеЄЮФкШн ? Ъ§РэзюпmЛЏИХвЊ ? ЃЈБивЊЄЌЄЂЄьЄаPЁйNPЄЫЄФЄЄЄЦЄтЃЉ ? нЫЭзюпmЛЏю}ЃЈVRPЃЉЄЮИХвЊ ? VRPЄЮОпЬхР§
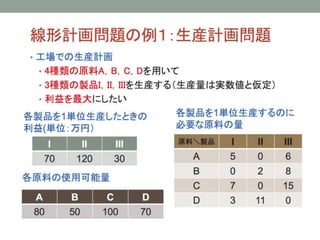
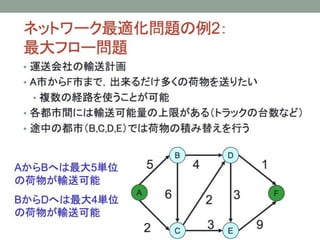
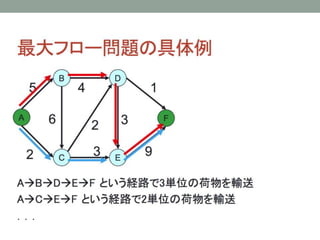
- 23. Vehicle Routing ProblemЄШЄЯ ? ЖЈСxЃК ? нЫЭЄЮЅъЅЏЅЈЅЙЅШЄШ\ЄъЮяЄЮвЛмЄЮМЏКЯЄЌгыЄЈЄщЄьЄПrЄЫ ? зюаЁЄЮЅГЅЙЅШЄЧШЋЄЦЄЮЅъЅЏЅЈЅЙЅШЄђКЄПЄЙ\ЄъЮяЄЮЅыЉ`ЅШЄђQЖЈЄЙЄыЄГЄШ ? ЅГЅѓЅдЅхЉ`ЅПЉ`ЄЮзюпmЛЏгЫуЅЂЅыЅДЅъЅКЅрЄЫЄшЄУЄЦИпЦЗй|ЄЪ gЌFПЩФмЄЪНтЄЌЕУЄщЄьЁЂrщgЄфЅГЅЙЅШЄђЯїpЄЧЄЄыЁЃ ? 1959ФъЄЮDantzig and Ramser ЄЮбаОПЄЫЄЯЄИЄоЄУЄЦ50ФъЄл ЄЩЄЮбаОПЄЮsЪЗЄЌЄЂЄъЁЂжївЊЄЪЅИЅуЉ`ЅЪЅыЄЯвдЯТЄЮЄЪЄтЄЮ ЄЌЄЂЄыЁЃ ? Operations Research, Transportation Science, Computers and Operations Research ? ЅИЅуЉ`ЅЪЅы?бЇЛс?баОПCщvЄђдЄЗЄЏжЊЄъЄПЄЄЗНЄЯНЬЄЈЄЦЯТЄЕЄЄЃЁ
- 24. VRPЄЮГЩвЊЫи 1. the (road) network structure 2. the type of transportation requests 3. the constraints that affect each route individually 4. the fleet composition and location 5. the inter-route constraints 6. the optimization objectives
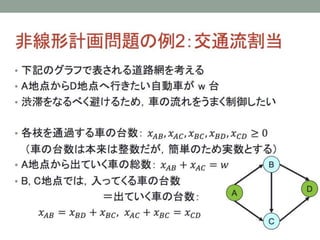
- 25. 1. ЅЭЅУЅШЅяЉ`ЅЏЄЮЬие ? ссЄЫЄЄВЄыCVRPЄЯЁЂЕуЄЮщgЄЮвЦгЄђПМЄЈЄыю} ? Arc Routing Problem ЄЮіКЯЄЯЁЂconnection ЄоЄПЄЯ link ЄШ бдЄяЄьЄыЁЂЕРЄЮЅЛЅАЅсЅѓЅШЄђПМЄЈЄы ? Р§ЃЉ ЖЌЄЮбЉЄЋЄЁЂр]БуХфп_ЃЈЕРЄЪЄъЄЫНьЄБЯШЄЌУмМЏЄЗЄЦЄЄЄыЄЮЄЧЃЉ
- 26. 2. нЫЭЅъЅЏЅЈЅЙЅШЄЮЗNю(1/2 ? Delivery and collectionЃЈpickupsЃЉ ? яЄпЮяЄЮМЏКЩЄШХфЫЭЄЪЄЩ ? many-to-one VRP ? one-to-many VRP ? Simple Visits and Vehicle Scheduling ? ПДзoЄЮЅБЅЂЁЂаоРэЄЪЄЩ ? Vehicle Scheduling problem ЄШКєЄаЄьЄы ? Alternative and Indirect Services ? аЁАќЄђНьЄБЄыЃЈНьЄБЯШЄЮКђбaЄЌЄЂЄыЃЉ ? Multi-Vehicle Covering Tour Problem ? Point-to-Point Transportation ? ЖўЕущgЄЮШЫЄфЅАЅУЅКЄЮвЦгЃЈНЛЭЈЄЪЄЩЃЉ ? pickup-and-delivery problems ? Repeated Supply ? ЄвЄШЄъЄЮЅЋЅЙЅПЅоЉ`ЄЌЖЈЦкЕФЄЫЃЈпL2ЄЪЄЩЃЉХфп_ЄЕЄьЄы ? Periodic VRP
- 27. 2. нЫЭЅъЅЏЅЈЅЙЅШЄЮЗNю(2/2 ? Non-split and Split Services ? б}Ъ§ЄЮЅШЅщЅУЅЏЄЧЄвЄШЄФЄЮашвЊЄђКЄПЄЙ ? The Split Delivery VRP ? Combined Shipment and Multi-model Service ? б}Ъ§ЄЮНЛЭЈЪжЖЮЄђЪЙЄУЄЦвЦгЄЙЄы ? ЖМЪагЛЄиЄЮъгУ ? hub-and-spoke or crossdocking 2-Echelon VRP ? Routing with Profits and Service Selection ? ашвЊЄЌШЋЄЦКЄПЄЕЄьЄЪЄЄіКЯЁЂКЄПЄЙашвЊЄђпxЄж ? Profitable Tour Problem ? Team Orienteering Problem ? Prize-Collecting VRP ? Dynamic and Stochastic Routing ? dynamic: ИїrщgЄДЄШЄЫЅЗЅЙЅЦЅрЄЮзДBЄЮЧщѓЄЌЕУЄщЄьЄы ? Sctochastic: зДBЄЌВЛУїЄРЄЌД_ТЪЗжВМЄЧБэЄЛЄы
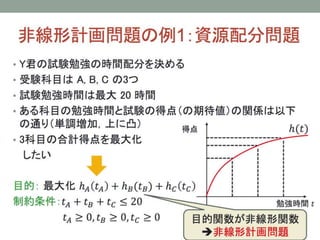
- 28. 3. ФПЕФщvЪ§ЄЮдOЖЈ ? Single Objective Optimization ? ЄвЄШЄФЄЮжИЫЄђзюпmЛЏЄЙЄы ? РћвцЁЂЅГЅЙЅШЁЂetc ? Hierarchical Objectives ? б}Ъ§ЄЮжИЫЄЯЄНЄьЄОЄьЯрЗДЄЙЄыЄЮЄЧЁЂЯШэЮЛЄђЄФЄБЄыЁЃ ? Multi-criteria Optimization ? нЫЭЄЫщvЄяЄыЅбЅщЅсЉ`ЅПЉ`ЄЌЖрЛЏЄЗЄЦЄЊЄъЁЂНќФъЅлЅУЅШЄЪюIгђ
- 30. БОШеЄЮФкШн ? Ъ§РэзюпmЛЏИХвЊ ? ЃЈБивЊЄЌЄЂЄьЄаPЁйNPЄЫЄФЄЄЄЦЄтЃЉ ? нЫЭзюпmЛЏю}ЃЈVRPЃЉЄЮИХвЊ ? VRPЄЮОпЬхР§
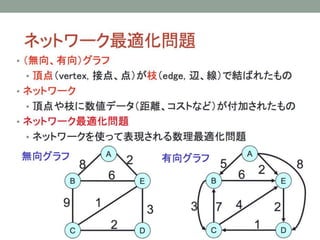
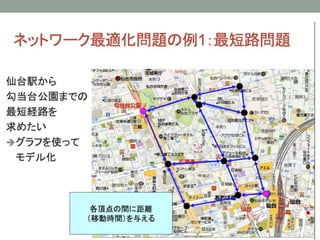
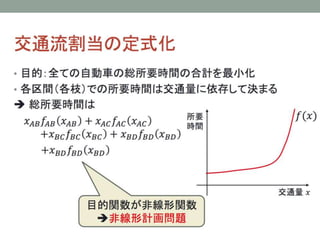
- 31. The Capacitated Vehicle Routing Problem ? зюЄтбаОПЄЕЄьЄЦЄЄЄыVRPЄЮЄвЄШЄФЃЈбВЛиЅЛЉ`ЅыЅЙЅоЅѓю}ЄЫЫЦЄЦЄЄЄыЃЉ ? ЅЂЅЋЅЧЅпЅУЅЏЕФЄЪвЊЫиЄЌЄЄ ? ЅтЅЧЅы ? 1ЄФЄЮ}ь(0)ЄШЁЂNШЫЄЮюПЭN={1, Ё, N}щgЄђвЦгЁЃ ? ЅЋЅЙЅПЅоЉ`iЄЮашвЊЃКqi ЄЯКЩЮяЄЮжиЄЕЁЃ0вдЩЯЄЮЅЙЅЋЅщЉ`ЁЃ ? ЅШЅщЅУЅЏЄЮМЏКЯ: K={1, 2, Ё, |K|} ? ЅШЅщЅУЅЏЄЮЅЅуЅбЅЗЅЦЅЃ Q >0 ЄЯвЛЖЈЁЃ ? ЄвЄШЄФЄЮЅШЅщЅУЅЏЄЌЁЂ}ьЄђГіАkЄЗЁЂЅЋЅЙЅПЅоЉ`ЄЮВПЗжМЏКЯS?NЄђЄоЄяЄЦ}ьЄЫјЄыЁЃ ? ЅЋЅЙЅПЅоЉ`iЄЋЄщjЄиЄЮвЦгЄЫЄЯЅГЅЙЅШ cij ЄЌЄЋЄЋЄыЁЃ ? }ь0ЄЮашвЊЄђЂЄЫq0ЄШЄЗЄЦгаЯђ?oЯђЅАЅщЅеЄЧБэЄЙЁЃ ? ЅАЅщЅеЄЯo(n2)ЄЮЅъЅѓЅЏЄђГжЄФЁЃ ? ЅПЅЙЅЏ ? ЅЋЅЙЅПЅоЉ`ЄђЅШЅщЅУЅЏЄДЄШЄЫgааПЩФмЄЪЅЏЅщЅЙЅПЉ`ЄЫЗжИюЄЙЄыЁЃ ? ИїЅШЅщЅУЅЏЄЮЅыЉ`ЅШЄђQЄсЄы ? НтЄЗНЃКЭЈГЃЁЂcompact formulations, (Mixed) Integer Programming modelЄђгУЄЄЄыЃЈдМЄЯссЄлЄЩЃЉ
- 32. Algorithms for the Capacitated VRP(1) ? Tree search method based on ЗжжІЯоЖЈЗЈ ? Tree searchЃЈФОЬНЫїЃЉWikipediaЄшЄъ ? ЬНЫїЅЂЅыЅДЅъЅКЅрЄШЄЯЁЂДѓЄоЄЋЄЫбдЄЈЄаЁЂю}ЄђШыСІЄШЄЗЄЦЁЂПМЄЈЄщЄьЄыЄЄЄЏЄФ ЄтЄЮНтЄђдu§ЄЗЄПссЁЂНтЄђЗЕЄЙЅЂЅыЅДЅъЅКЅрЄЧЄЂЄыЁЃ ? ЄоЄКНтЄЏЄйЄю}ЄђзДBЄШзДBфЛЏЄЫЗжЄыЁЃ зюГѕЄЫгыЄЈЄщЄьЄызДBЄђГѕЦкзД BЃЈгЂ: initial stateЃЉЄШЄЄЄЄЁЂФПЕФЄШЄЙЄызДBЄЯзюНKзДBЃЈЅДЉ`ЅыЁЂгЂ: final state, goalЃЉЄШКєЄаЄьЄыЁЃ ГѕЦкзДBЄЋЄщзюНKзДBЄЫжСЄыЁЂзДBМАЄгзДBфЛЏ ЄЮKЄгЄЌНтЄЧЄЂЄыЁЃ НЋЦхЄЪЄщЄаЁЂБPУцЄЮёxЄЮХфжУЄШжИЄЗЪжЄЮГжЄСёxЄЌзДBЄЧ ЄЂЄъЁЂНЛЛЅЄЫёxЄђгЄЋЄЙЄГЄШЄЌзДBфЛЏЄЫЕБЄПЄыЁЃ ? ю}ЄђНтЄЏюЄШЄЗЄЦбаОПЄЕЄьЄЦЄЄЄыЅЂЅыЅДЅъЅКЅрЄЮЖрЄЏЄЯЬНЫїЅЂЅыЅДЅъЅКЅрЄЧ ЄЂЄыЁЃЄЂЄыю}ЄЮПМЄЈЄщЄьЄыЄЂЄщЄцЄыНтЄЮМЏКЯЄђЬНЫїПещgЄШКєЄжЁЃСІЄоЄЋЄЛ ЬНЫїЄфЫиЦгЄЪЃЈжЊзRЄђгУЄЄЄЪЄЄЃЉЬНЫїЅЂЅыЅДЅъЅКЅрЄЯЁЂЬНЫїПещgЄђЬНЫїЄЙЄыЪж ЗЈЄШЄЗЄЦЄЯзюЄт gМЄЧжБгQЕФЄЧЄЂЄыЁЃвЛЗНЁЂжЊзRЄђгУЄЄЄПЬНЫїЅЂЅыЅДЅъЅКЅрЄЯ ЅвЅхЉ`ЅъЅЙЅЦЅЃЅЏЅЙЄђЪЙЄУЄЦЬНЫїПещgЄЮдьЄЫщvЄЙЄыжЊзRЄђРћгУЄЗЁЂЬНЫїЄЫЄЋ ЄЋЄыrщgЄђЯїpЄЗЄшЄІЄШЄЙЄыЁЃ
- 33. Algorithms for the Capacitated VRP(1) ? Tree search method based on ЗжжІЯоЖЈЗЈ(branch-) ? ШЋЄЦЄЮНтКђбaЄђЬхЯЕЕФЄЫСаЄЄЙЄыЄтЄЮЄЧЁЂзюпmЛЏЄЕЄьЄПСПЄЮЩЯЯоЄШЯТЯоЄЮ ИХЫуЄђЪЙЄУЄЦЁЂзюпmЄЧЄЪЄЄКђбaЄЯЄоЄШЄсЄЦЮЄЦЄщЄьЄыЁЃ ? ю}ЄђЄЄЄЏЄФЄЋЄЮаЁвФЃЄЪю}ЄЫЗжИюЄЗЃЌЄНЄЮШЋЄЦЄђНтЄЏЄГЄШЄЧЕШ§ЕФЄЫдЊ ЄЮю}ЄђНтЄЏ ? аЁвФЃЄЪю}ЄиЄЮЗжИюЄЯЃЌР§ЄЈЄаЃЌЄЂЄы 1 ЄФЄЮфЪ§ЄЮЄђ 0 ЄоЄПЄЯ 1 ЄЫ ЙЬЖЈЄЗЃЌЄНЄьЄОЄьЄЮіКЯЄђeЄЫПМВьЄЙЄыЄГЄШЄЫЄшЄУЄЦgЌFЄЧЄЄы. ЄГЄЮЄш ЄІЄЫю}ЄђЗжИюЄЙЄыВйзїЄђЗжжІВйзїЃЈbranching operationЃЉЄШЄЄЄІЃЎ ? ЗжжІВйзїЄђРRЄъЗЕЄЗааЄІЄГЄШЄЧЃЌЄЙЄйЄЦЄЮіКЯЄђСаЄЄЙЄыЄГЄШЄЌЄЧЄЄыЄЌЃЌ ЄНЄЮп^ГЬЄЯЩњГЩФОЄШКєЄаЄьЄыИљИЖЄФО ? ЄђгУЄЄЄЦБэЌFЄЧЄЄыЃЎ ЗжжІЯоЖЈЗЈЄЮЬНЫїЄђЭОжаЄЧДђЄСЧаЄьЄаНќЫЦНтЗЈЄШЄЗЄЦЄтРћгУЄЧЄЃЌЄГЄЮі КЯЃЌзюпmЄЯЗжЄЋЄщЄЪЄЏЄШЄтзюпmЄЮЯТНчЄђжЊЄыЄГЄШЄЌЄЧЄЄыЃЈзюаЁЛЏю} ЄђЂЖЈЄЗЄЦЄЄЄыЃЉ ? ЪжЗЈЄЮПТЪЄЯЁЂЅЮЉ`ЅЩЗжИюЪжОAЄЄШЩЯЯоЄЊЄшЄгЯТЯоЄђЭЦЖЈЄЙЄыЪжОAЄЄЫ ЄЏвРДцЄЙЄыЁЃЫћЄЮШЋЄЦЄЮЬѕМўЄЌЭЌЄИЄЪЄщЁЂЅЊЉ`ЅаЉ`ЅщЅУЅзЄЗЄЪЄЄВПЗжМЏКЯЄЫ ЗжИюЄЙЄыЄЮЄЌзюЄтЄшЄЄЁЃ
- 34. Algorithms for the Capacitated VRP(2) ? Column Generation and Brand-and-Cut algorithm ? жаДЈЄЕЄѓЄЌеhУїгшЖЈЄЮVRP with Time WindowsЄЮЬиЪтЄЪЅБЉ`ЅЙЄШЄЗЄЦ НтЄЋЄьЄыЃЈtime windowЄЌЪЎЗжЄЫДѓЄЄЄіКЯЃЉ ? вдЯТЄЮ2ЄФЄЮЅЂЅзЅэЉ`ЅСЄЮЅГЅѓЅгЅЭЉ`ЅЗЅчЅѓ ? Fukasawa, R., Longo, H., Lysgchoa, E., Werneck, RF. ? Robust branch-and-cut-and-price for the capacitated vehicle routing problem, Mathematical Programming, Vol. 106, No.3, pp. 491-511, 2006. ? Baldacci, Christofides, and Mingozzi ? An exact algorithm for the vehicle routing problem based on the set partitioning formulation with additional cuts ? Mathematical Programming, Vol 115, Issue 2, pp 351-385, 2008
- 35. й|вЩъД№ ? вЛЗЌЅлЅУЅШЄЪюIгђЄЯЃП ? ЅвЅхЉ`ЅъЅЙЅЦЅЃЅУЅЏЄЪгЫуЅЂЅыЅДЅъЅКЅрЄЮщ_Аk ? multiple optimization ? ЁЉЄЪЬНЫїЗНЗЈЃЈGAЁЂЗжжІЯоЖЈЗЈЄЪЄЩЄЪЄЩЃЉЄђБШн^ЄЙЄыЁЃ ? https://ja.wikipedia.org/wiki/%E6%8E%A2%E7%B4%A2 ? ЅЏЅэЅЭЅГЅфЅоЅШЄЪЄЩп\ЫЭЛсЩчЄЯgыHЄЫЄГЄЮЄшЄІЄЪЅЂЅыЅДЅъЅКЅр ЄђЪЙЄУЄЦЄЄЄыЄЮЄРЄэЄІЄЋЃП ? ЪЙЄУЄЦЄЄЄыПЩФмадЄЯИпЄЄЁЃ ? ЕигђЄЮп\АсЕЃЕБЄЮШЫЄЮВУСПЄЫШЮЄЕЄьЄЦЄЄЄыЅБЉ`ЅЙЄтЖрЄЄЁЃ ? гЫуПЩФмЄЪСПЄЌаЁЄЕЄЄЄЮЄЧЁЂЪЙЄІЄШЄЗЄПЄщЕигђЄДЄШЄЫЗжИюЄЗЄЦгЫуЄЪЄЩ ЄЙЄыЄЮЄЧЄЯЃП
- 36. ЄЊЄоЄБЃКAlgorithms for the Capacitated VRP(2) branch-and-cut-and-price(2004)ЄЮАkеЙ ? ЅжЅщЅѓЅС=жІЄЮЗжИю ? ЅЋЅУЅШ=ЅАЅщЅеРэеЄЫЄЊЄБЄыЗжИюМЏКЯ ? ЅзЅщЅЄЅЙ=ЅщЅАЅщЅѓЅИЅхЄЮЮДЖЈ\Ъ§ЗЈЄЧІЫ ЄђЧѓЄсЄЦжиЄпЄХЄБ ? Ёіcolumn generation ? ЩЯЮЛю}ЃКKЬЈЄЮпxkЅыЉ`ЅШЄЮОрыxЄЮзю аЁЛЏ ? ЯТЮЛю}ЃКОрыxЄЮЖЬЄЄЅыЉ`ЅШШКЄЮЩњГЩ ? ?ШнСПcЄђКснSЃЌэЕуЄђПkнSЄЫЄШЄУЄПааСа MЄЧэЕуvЄоЄЧЄЮЕРЄШЄНЄЮыHЄЮОtашвЊdЄђ БэЄЙЃЎ ? DPЄЧЕРЄђаЮГЩЄЗЄЦЄЄЄЏ ? w(vЄЮНќАјЕу)ЄђvЄЮДЮЄЫзЗМгЄЙЄыЄЋЄЩЄІ ЄЋЄђХаЖЯЄЗЄЦМгЄЈЄЦЄЄЄЏЃЎ ? ааСаЄЮжаЄЮЕуЄЮЪ§ЄЌncЄЪЄЮЄЧncЛиРR ЄъЗЕЄЛЄаЕРЄЌ1БОЄЧЄЄыЃЎЅыЉ`ЅШЄЮБОЪ§ЄЯ nБОЄЧ ? ЄЄыЄЮЄЧcn2ЛиЄЧгЫуПЩФмЃЎ ? Ёіcolumn generationЄЮИпЫйЛЏЃК ? ЯїГ§ЃКЭЈп^ЕуЄђгЄЗЄЦщ]ТЗЄШЄЪЄУЄЦЄЄЄы ЄЋЄђХаЖЯ ? Ё№ЅвЅхЉ`ЅъЅЙЅЦЅЃЅУЅЏМгЫй ? sparsificationЃК1ЄФЄЮЅАЅщЅеЄђ5ЄФЄЫЗжИю ЄЗЃЌSpanning treeЄђЄЂЄщЄЋЄИЄсдOЖЈЄЙ ? ЄыЃЎ ? ЁіCut generation ? ЅЋЅУЅШЅЛЅУЅШЄЮоxЄЮЪ§ЄђжУЄЄЄЦЄЄЄПЄЌЃЌЄН ЄЮЅЋЅУЅШЅЛЅУЅШЄЮЩњГЩЄђааЄІЃЎ ? жмЛиШнСПжЦМsЄЫзюпmЛЏгЫуЄЮжЦМsЬѕМў ЄЧЄЯЄЪЄЏЃЌeЭОЅЂЅыЅДЅъЅКЅрЄђдOЖЈЄЙЄыЃЎ ? ЧаЖЯМЏКЯЄЫЪєЄЙЄыЄПЄсЄЮЬѕМў?MЄЌгыЄЈ ЄщЄьЄПrЄЮS,yЄђГщГіЄЙЄыЬѕМўЄђжЦМsЬѕ МўЄШЄЗ ? ЄЦГіШыЄъЄЮоxЄЮЪ§ЄђзюаЁЛЏЄЙЄыЃЎ