–ï–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α–Μ–Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α –Ζ–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α –Ψ―²–¥–Β–Μ–Ϋ–Η –¥―É–Φ–Η –≤ –±―ä–Μ–≥–Α―Ä―¹–Κ–Η―è –Β–Ζ–Η–Κ
1 like679 views






![–‰–Ζ–Φ–Β―¹―²–Β–Ϋ–Η―²–Β –Ω–Ψ –€–Β–Μ ―¹–Κ–Α–Μ–Α―²–Α –Κ–Β–Ω―¹―²―Ä–Α–Μ–Ϋ–Η –Κ–Ψ–Β―³–Η―Ü–Η–Β–Ϋ―²–Η. –Ξ–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η―΅–Ϋ–Η –≤–Β–Κ―²–Ψ―Ä–Η –ë–ü–Λ –€–Β–Μ ―³–Η–Μ―²―Ä–Η Log[ ] –î–Η―¹–Κ―Ä–Β―²–Ϋ–Α –Κ–Ψ―¹–Η–Ϋ―É―¹–Ψ–≤–Α ―²―Ä–Α–Ϋ―¹―³–Ψ―Ä–Φ–Α―Ü–Η―è –‰–€–ö–ö](https://image.slidesharecdn.com/diplomnarabota-110128042448-phpapp02/85/-13-320.jpg)






–ï–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α–Μ–Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α –Ζ–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α –Ψ―²–¥–Β–Μ–Ϋ–Η –¥―É–Φ–Η –≤ –±―ä–Μ–≥–Α―Ä―¹–Κ–Η―è –Β–Ζ–Η–Κ
- 1. –ï–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α–Μ–Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α –Ζ–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α –Ψ―²–¥–Β–Μ–Ϋ–Η –¥―É–Φ–Η –≤ –±―ä–Μ–≥–Α―Ä―¹–Κ–Η―è –Β–Ζ–Η–Κ –î–Η–Ω–Μ–Ψ–Φ–Α–Ϋ―²: –¦–Η–Μ―è–Ϋ–Α –®–Α―Ä–Κ–Ψ–≤–Α –Λ–Α–Κ. ⳕ ... –ù–Α―É―΅–Β–Ϋ ―Ä―ä–Κ–Ψ–≤–Ψ–¥–Η―²–Β–Μ: –ü―Ä–Ψ―³. –¥–Φ–Ϋ –™–Β–Ψ―Ä–≥–Η –Δ–Ψ―²–Κ–Ψ–≤ –ü–Μ–Ψ–≤–¥–Η–≤―¹–Κ–Η ―É–Ϋ–Η–≤–Β―Ä―¹–Η―²–Β―² βÄû–ü–Α–Η―¹–Η–Ι –Ξ–Η–Μ–Β–Ϋ–¥–Α―Ä―¹–Κ–ΗβÄ€ –Λ–Α–Κ―É–Μ―²–Β―² –Ω–Ψ –Φ–Α―²–Β–Φ–Α―²–Η–Κ–Α –Η –Η–Ϋ―³–Ψ―Ä–Φ–Α―²–Η–Κ–Α –ö–Α―²–Β–¥―Ä–Α βÄû–ö–Ψ–Φ–Ω―é―²―ä―Ä–Ϋ–Α –Η–Ϋ―³–Ψ―Ä–Φ–Α―²–Η–Κ–ΑβÄ€
- 2. –Π–Β–Μ –Ϋ–Α –¥–Η–Ω–Μ–Ψ–Φ–Ϋ–Α―²–Α ―Ä–Α–±–Ψ―²–Α –Π–Β–Μ―²–Α –Ϋ–Α –¥–Η–Ω–Μ–Ψ–Φ–Ϋ–Α―²–Α ―Ä–Α–±–Ψ―²–Α –Β –¥–Α ―¹–Β –Ω―Ä–Ψ―É―΅–Η ―¹―ä―¹―²–Ψ―è–Ϋ–Η–Β―²–Ψ –Ϋ–Α ―¹―ä–≤―Ä–Β–Φ–Β–Ϋ–Ϋ–Η―²–Β ―¹–Η―¹―²–Β–Φ–Η –Ζ–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α ―Ä–Β―΅, –¥–Α ―¹–Β –Η–Ζ–±–Β―Ä–Α―² –Ω–Ψ–¥―Ö–Ψ–¥―è―â–Η –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Η –Η –¥–Α ―¹–Β ―Ä–Β–Α–Μ–Η–Ζ–Η―Ä–Α –Β–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Α–Μ–Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α –Ζ–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α –Ψ―²–¥–Β–Μ–Ϋ–Η –¥―É–Φ–Η –≤ –±―ä–Μ–≥–Α―Ä―¹–Κ–Η―è –Β–Ζ–Η–Κ.
- 3. –†–Β―à–Β–Ϋ–Η ―¹–Α ―¹–Μ–Β–¥–Ϋ–Η―²–Β –Ζ–Α–¥–Α―΅–Η: –ü―Ä–Ψ―É―΅–≤–Α–Ϋ–Β –Ϋ–Α ―¹―ä―¹―²–Ψ―è–Ϋ–Η–Β―²–Ψ –Ϋ–Α ―¹―ä–≤―Ä–Β–Φ–Β–Ϋ–Ϋ–Η―²–Β ―¹–Η―¹―²–Β–Φ–Η –Ζ–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α ―Ä–Β―΅; –‰–Ζ–±–Ψ―Ä –Ϋ–Α –Ω–Ψ–¥―Ö–Ψ–¥―è―â–Η –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Η ; –†–Β–Α–Μ–Η–Ζ–Η―Ä–Α–Ϋ–Β; –ü―Ä–Ψ–Β–Κ―²–Η―Ä–Α–Ϋ–Β –Ϋ–Α ―¹―²―Ä―É–Κ―²―É―Ä–Α –Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α―²–Α –Η –Ω―Ä–Ψ–≥―Ä–Α–Φ–Η―Ä–Α–Ϋ–Β; –ï–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Η; –ê–Ϋ–Α–Μ–Η–Ζ.
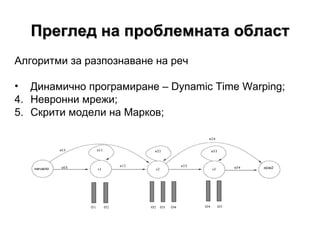
- 4. –ü―Ä–Β–≥–Μ–Β–¥ –Ϋ–Α –Ω―Ä–Ψ–±–Μ–Β–Φ–Ϋ–Α―²–Α –Ψ–±–Μ–Α―¹―² –ê–Μ–≥–Ψ―Ä–Η―²–Φ–Η –Ζ–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α ―Ä–Β―΅ –î–Η–Ϋ–Α–Φ–Η―΅–Ϋ–Ψ –Ω―Ä–Ψ–≥―Ä–Α–Φ–Η―Ä–Α–Ϋ–Β βÄ™ Dynamic Time Warping ; –ù–Β–≤―Ä–Ψ–Ϋ–Ϋ–Η –Φ―Ä–Β–Ε–Η; –Γ–Κ―Ä–Η―²–Η –Φ–Ψ–¥–Β–Μ–Η –Ϋ–Α –€–Α―Ä–Κ–Ψ–≤;
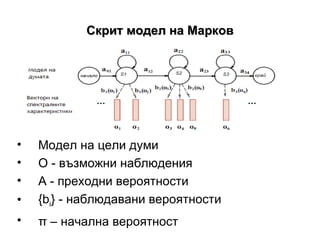
- 5. –Γ–Κ―Ä–Η―² –Φ–Ψ–¥–Β–Μ –Ϋ–Α –€–Α―Ä–Κ–Ψ–≤ –€–Ψ–¥–Β–Μ –Ϋ–Α ―Ü–Β–Μ–Η –¥―É–Φ–Η –û - –≤―ä–Ζ–Φ–Ψ–Ε–Ϋ–Η –Ϋ–Α–±–Μ―é–¥–Β–Ϋ–Η―è –ê - –Ω―Ä–Β―Ö–Ψ–¥–Ϋ–Η –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η { b i } - –Ϋ–Α–±–Μ―é–¥–Α–≤–Α–Ϋ–Η –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η œÄ βÄ™ –Ϋ–Α―΅–Α–Μ–Ϋ–Α –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²
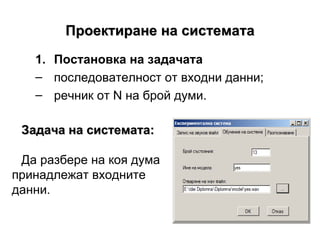
- 6. –ü―Ä–Ψ–Β–Κ―²–Η―Ä–Α–Ϋ–Β –Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α―²–Α –ü–Ψ―¹―²–Α–Ϋ–Ψ–≤–Κ–Α –Ϋ–Α –Ζ–Α–¥–Α―΅–Α―²–Α –Ω–Ψ―¹–Μ–Β–¥–Ψ–≤–Α―²–Β–Μ–Ϋ–Ψ―¹―² –Ψ―² –≤―Ö–Ψ–¥–Ϋ–Η –¥–Α–Ϋ–Ϋ–Η; ―Ä–Β―΅–Ϋ–Η–Κ –Ψ―² N –Ϋ–Α –±―Ä–Ψ–Ι –¥―É–Φ–Η. –½–Α–¥–Α―΅–Α –Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α―²–Α: –î–Α ―Ä–Α–Ζ–±–Β―Ä–Β –Ϋ–Α –Κ–Ψ―è –¥―É–Φ–Α –Ω―Ä–Η–Ϋ–Α–¥–Μ–Β–Ε–Α―² –≤―Ö–Ψ–¥–Ϋ–Η―²–Β –¥–Α–Ϋ–Ϋ–Η.
- 7. –ü―Ä–Ψ–Β–Κ―²–Η―Ä–Α–Ϋ–Β –Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α―²–Α –‰–Ζ–±–Ψ―Ä –Ϋ–Α –Α–Μ–≥–Ψ―Ä–Η―²–Φ–Η –Ζ–Α: –Η–Ζ–≤–Μ–Η―΅–Α–Ϋ–Β –Ϋ–Α ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η–Κ–Η―²–Β –Α–Ϋ–Α–Μ–Η–Ζ –Ϋ–Α –Λ―É―Ä–Η–Β, –Ω―Ä–Ψ–Ζ–Ψ―Ä–Β―Ü –Ϋ–Α –Ξ–Β–Φ–Η–Ϋ–≥, MFCC –Φ–Ψ–¥–Β–Μ–Η―²–Β –Ϋ–Α –¥―É–Φ–Η―²–Β –Γ–€–€ –Ψ–±―É―΅–Β–Ϋ–Η–Β –Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α―²–Α –£–Η―²–Β―Ä–±–Η ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η―è ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Ϋ–Α –¥―É–Φ–Α –£―ä–Ζ―Ö–Ψ–¥―è―â –Α–Μ–≥–Ψ―Ä–Η―²―ä–Φ
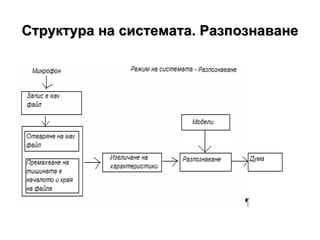
- 8. –Γ―²―Ä―É–Κ―²―É―Ä–Α –Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α―²–Α. –û–±―É―΅–Β–Ϋ–Η–Β
- 9. –Γ―²―Ä―É–Κ―²―É―Ä–Α –Ϋ–Α ―¹–Η―¹―²–Β–Φ–Α―²–Α. –†–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β
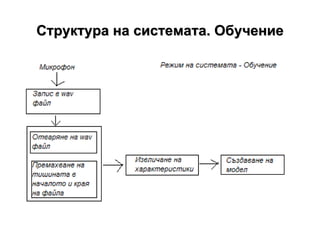
- 10. –†–Α–±–Ψ―²–Α ―¹ wav -―³–Α–Ι–Μ 1. –½–Α–Ω–Η―¹ –Ϋ–Α ―¹–Η–≥–Ϋ–Α–Μ –≤ wav - ―³–Α–Ι–Μ 2. –û―²–≤–Α―Ä―è–Ϋ–Β –Ϋ–Α wav -―³–Α–Ι–Μ 3. –‰–Ζ–≤–Μ–Η―΅–Α–Ϋ–Β –Ϋ–Α ―¹―ä―â–Η–Ϋ―¹–Κ–Η―²–Β –¥–Α–Ϋ–Ϋ–Η –Ψ―² wav - ―³–Α–Ι–Μ–Α –ë–Η–±–Μ–Η–Ψ―²–Β–Κ–Α WaveLib
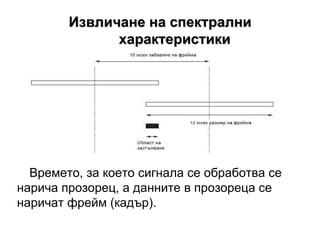
- 11. –‰–Ζ–≤–Μ–Η―΅–Α–Ϋ–Β –Ϋ–Α ―¹–Ω–Β–Κ―²―Ä–Α–Μ–Ϋ–Η ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η–Κ–Η –£―Ä–Β–Φ–Β―²–Ψ, –Ζ–Α –Κ–Ψ–Β―²–Ψ ―¹–Η–≥–Ϋ–Α–Μ–Α ―¹–Β –Ψ–±―Ä–Α–±–Ψ―²–≤–Α ―¹–Β –Ϋ–Α―Ä–Η―΅–Α –Ω―Ä–Ψ–Ζ–Ψ―Ä–Β―Ü, –Α –¥–Α–Ϋ–Ϋ–Η―²–Β –≤ –Ω―Ä–Ψ–Ζ–Ψ―Ä–Β―Ü–Α ―¹–Β –Ϋ–Α―Ä–Η―΅–Α―² ―³―Ä–Β–Ι–Φ (–Κ–Α–¥―ä―Ä).
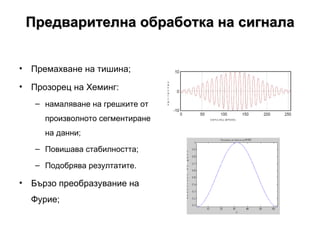
- 12. –ü―Ä–Β–¥–≤–Α―Ä–Η―²–Β–Μ–Ϋ–Α –Ψ–±―Ä–Α–±–Ψ―²–Κ–Α –Ϋ–Α ―¹–Η–≥–Ϋ–Α–Μ–Α –ü―Ä–Β–Φ–Α―Ö–≤–Α–Ϋ–Β –Ϋ–Α ―²–Η―à–Η–Ϋ–Α; –ü―Ä–Ψ–Ζ–Ψ―Ä–Β―Ü –Ϋ–Α –Ξ–Β–Φ–Η–Ϋ–≥: –Ϋ–Α–Φ–Α–Μ―è–≤–Α–Ϋ–Β –Ϋ–Α –≥―Ä–Β―à–Κ–Η―²–Β –Ψ―² –Ω―Ä–Ψ–Η–Ζ–≤–Ψ–Μ–Ϋ–Ψ―²–Ψ ―¹–Β–≥–Φ–Β–Ϋ―²–Η―Ä–Α–Ϋ–Β –Ϋ–Α –¥–Α–Ϋ–Ϋ–Η; –ü–Ψ–≤–Η―à–Α–≤–Α ―¹―²–Α–±–Η–Μ–Ϋ–Ψ―¹―²―²–Α; –ü–Ψ–¥–Ψ–±―Ä―è–≤–Α ―Ä–Β–Ζ―É–Μ―²–Α―²–Η―²–Β. –ë―ä―Ä–Ζ–Ψ –Ω―Ä–Β–Ψ–±―Ä–Α–Ζ―É–≤–Α–Ϋ–Η–Β –Ϋ–Α –Λ―É―Ä–Η–Β;
- 13. –‰–Ζ–Φ–Β―¹―²–Β–Ϋ–Η―²–Β –Ω–Ψ –€–Β–Μ ―¹–Κ–Α–Μ–Α―²–Α –Κ–Β–Ω―¹―²―Ä–Α–Μ–Ϋ–Η –Κ–Ψ–Β―³–Η―Ü–Η–Β–Ϋ―²–Η. –Ξ–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η―΅–Ϋ–Η –≤–Β–Κ―²–Ψ―Ä–Η –ë–ü–Λ –€–Β–Μ ―³–Η–Μ―²―Ä–Η Log[ ] –î–Η―¹–Κ―Ä–Β―²–Ϋ–Α –Κ–Ψ―¹–Η–Ϋ―É―¹–Ψ–≤–Α ―²―Ä–Α–Ϋ―¹―³–Ψ―Ä–Φ–Α―Ü–Η―è –‰–€–ö–ö
- 14. –û–±―É―΅–Β–Ϋ–Η–Β –Ϋ–Α –Φ–Ψ–¥–Β–Μ–Η –ü―Ä–Β–¥–Η –¥–Α –Ζ–Α–Ω–Ψ―΅–Ϋ–Β –¥–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α –¥―É–Φ–Η ―¹–Η―¹―²–Β–Φ–Α―²–Α ―²―Ä―è–±–≤–Α –¥–Α –±―ä–¥–Β –Ψ–±―É―΅–Β–Ϋ–Α. –ê–Μ–≥–Ψ―Ä–Η―²―ä–Φ –Ϋ–Α –ë–Α―É–Φ-–Θ–Β–Μ―΅; –ê–Μ–≥–Ψ―Ä–Η―²―ä–Φ –Ζ–Α ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η―è –Ω–Ψ –ö - ―¹―Ä–Β–¥–Ϋ–Α ―¹―²–Ψ–Ι–Ϋ–Ψ―¹―² (–£–Η―²–Β―Ä–±–Η ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η―è) - –Η–Ζ–Η―¹–Κ–≤–Α –Φ–Ϋ–Ψ–≥–Ψ –Ω–Ψ-–Φ–Α–Μ–Κ–Ψ –Η–Ζ―΅–Η―¹–Μ–Β–Ϋ–Η―è.
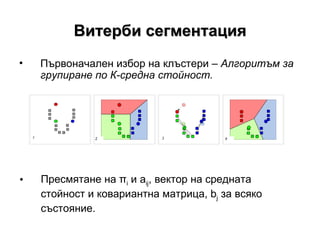
- 15. –£–Η―²–Β―Ä–±–Η ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η―è –ü―ä―Ä–≤–Ψ–Ϋ–Α―΅–Α–Μ–Β–Ϋ –Η–Ζ–±–Ψ―Ä –Ϋ–Α –Κ–Μ―ä―¹―²–Β―Ä–Η βÄ™ –ê–Μ–≥–Ψ―Ä–Η―²―ä–Φ –Ζ–Α –≥―Ä―É–Ω–Η―Ä–Α–Ϋ–Β –Ω–Ψ –ö-―¹―Ä–Β–¥–Ϋ–Α ―¹―²–Ψ–Ι–Ϋ–Ψ―¹―². –ü―Ä–Β―¹–Φ―è―²–Α–Ϋ–Β –Ϋ–Α œÄ i –Η a ij , –≤–Β–Κ―²–Ψ―Ä –Ϋ–Α ―¹―Ä–Β–¥–Ϋ–Α―²–Α ―¹―²–Ψ–Ι–Ϋ–Ψ―¹―² –Η –Κ–Ψ–≤–Α―Ä–Η–Α–Ϋ―²–Ϋ–Α –Φ–Α―²―Ä–Η―Ü–Α, b j –Ζ–Α –≤―¹―è–Κ–Ψ ―¹―ä―¹―²–Ψ―è–Ϋ–Η–Β.
- 17. –ù–Α–Φ–Η―Ä–Α–Φ–Β –Ψ–Ω―²–Η–Φ–Α–Μ–Ϋ–Α―²–Α –Ω–Ψ―Ä–Β–¥–Η―Ü–Α ―¹―ä―¹―²–Ψ―è–Ϋ–Η―è - –ê–Μ–≥–Ψ―Ä–Η―²―ä–Φ –Ϋ–Α –£–Η―²–Β―Ä–±–Η –ê–Κ–Ψ –Η–Φ–Α ―Ä–Α–Ζ–Φ–Β―¹―²–≤–Α–Ϋ–Β –Ϋ–Α –≤–Β–Κ―²–Ψ―Ä–Η ―¹ ―Ö–Α―Ä–Α–Κ―²–Β―Ä–Η―¹―²–Η–Κ–Η –≤ –Γ―²―ä–Ω–Κ–Α 3, –Η–Ζ–Ω–Ψ–Μ–Ζ–≤–Α–Ι–Κ–Η –Ϋ–Ψ–≤–Α―²–Α –Ω–Ψ―Ä–Β–¥–Η―Ü–Α –Ω–Ψ–≤―²–Α―Ä―è–Φ–Β –¥–Β–Ι―¹―²–≤–Η―è―²–Α –Ψ―² –Γ―²―ä–Ω–Κ–Α 2; –Η–Ϋ–Α―΅–Β, ―¹–Ω–Η―Ä–Α–Φ–Β. –£ ―²–Β–Κ―¹―²–Ψ–≤ ―³–Α–Ι–Μ –Ζ–Α–Ω–Η―¹–≤–Α–Φ–Β –Ω―Ä–Β–Η–Ζ―΅–Η―¹–Μ–Β–Ϋ–Η―²–Β –Ϋ–Α―΅–Α–Μ–Ϋ–Η―²–Β –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η, –Ω―Ä–Β―Ö–Ψ–¥–Ϋ–Η―²–Β –≤–Β―Ä–Ψ―è―²–Ϋ–Ψ―¹―²–Η –Η ―¹―Ä–Β–¥–Ϋ–Η―²–Β ―¹―²–Ψ–Ι–Ϋ–Ψ―¹―²–Η. –£–Η―²–Β―Ä–±–Η ―¹–Β–≥–Φ–Β–Ϋ―²–Α―Ü–Η―è
- 18. Χΐ
- 19. –†–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β. –£―ä–Ζ―Ö–Ψ–¥―è―â –Α–Μ–≥–Ψ―Ä–Η―²―ä–Φ –ü―Ä–Β–¥–Ψ―¹―²–Α–≤―è–Φ–Β –Ϋ–Α–±–Μ―é–¥–Β–Ϋ–Η―è –Ϋ–Α –Φ–Ψ–¥–Β–Μ–Α –Η ―²–Ψ–Ι –Ϋ–Η –≤―Ä―ä―â–Α ―΅–Η―¹–Μ–Ψ; –†–Β–Ζ―É–Μ―²–Α―²―ä―² –Β –Ω–Ψ–Κ–Α–Ζ–Α―²–Β–Μ, –Ζ–Α ―²–Ψ–≤–Α –¥–Ψ–Κ–Ψ–Μ–Κ–Ψ –Φ–Ψ–¥–Β–Μ–Α –Η –¥–Α–Ϋ–Ϋ–Η―²–Β –Ψ―² wav -―³–Α–Ι–Μ–Α ―¹–Β –¥–Ψ–±–Μ–Η–Ε–Α–≤–Α―²; –½–Α –Ω―Ä–Ψ–Η–Ζ–Ϋ–Β―¹–Β–Ϋ–Α –¥―É–Φ–Α ―¹–Β ―¹–Φ―è―²–Α ―²–Α–Ζ–Η ―¹ –Ϋ–Α–Ι-–¥–Ψ–±―ä―Ä ―Ä–Β–Ζ―É–Μ―²–Α―².
- 20. –†–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β. –ï–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Η –Η –Α–Ϋ–Α–Μ–Η–Ζ. –ï–Κ―¹–Ω–Β―Ä–Η–Φ–Β–Ϋ―²–Η ―¹ –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Ψ –Ψ―² –¥―É–Φ–Η {βĉ–¥–ΑβÄô, βÄô–Ϋ–ΒβÄô} : 6 –Ζ–Α–Ω–Η―¹–Α –Ϋ–Α –¥―É–Φ–Α―²–Α βĉ –¥–Α βÄô 11 –Ζ–Α–Ω–Η―¹–Α –Ϋ–Α –¥―É–Φ–Α―²–Α βĉ –Ϋ–Β βÄô –†–Β–Ζ―É–Μ―²–Α―²: –Θ―¹–Ω–Β―à–Ϋ–Ψ ―¹–Α ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α―²–Η 9 –Ψ―² –Ω―Ä–Ψ–Η–Ζ–Ϋ–Β―¹–Β–Ϋ–Η―²–Β –¥―É–Φ–Η. –‰–Ζ–≤–Ψ–¥: –½–Α –¥–Α –Φ–Ψ–Ε–Β ―¹–Η―¹―²–Β–Φ–Α―²–Α –¥–Α –¥–Α–≤–Α –Ω–Ψ-―²–Ψ―΅–Ϋ–Η ―Ä–Β–Ζ―É–Μ―²–Α―²–Η –Ω―Ä–Η ―Ä–Α–Ζ–Ω–Ψ–Ζ–Ϋ–Α–≤–Α–Ϋ–Β –Β –Ϋ–Β–Ψ–±―Ö–Ψ–¥–Η–Φ–Ψ –Β –¥–Α –±―ä–¥–Α―² –Ω―Ä–Β–¥–Ψ―¹―²–Α–≤–Β–Ϋ–Η –Ω–Ψ-–≥–Ψ–Μ–Β–Φ–Η –Φ–Ϋ–Ψ–Ε–Β―¹―²–≤–Α –Ψ―² –¥–Α–Ϋ–Ϋ–Η –Ζ–Α –Ψ–±―É―΅–Β–Ϋ–Η–Β.