

























E-SOINN
- 1. 1/27 E-SOINN ź¬ź¾źķźżź¾Į╠Ĥż╩żĘĘųŅÉż╬ż┐żßż╬ūĘ╝ėč¦┴Ģ╩ųĘ© ¢|Š®╣żśI┤¾č¦ ąĪé}║═┘F, ╔ĻĖ╗ł, ķL╣╚┤©ą▐ ļŖūėŪķł¾═©ą┼č¦╗ßšō╬─šI, D Vol. J90-D, No.6, pp.1610-1622 (2007)
- 2. 2/27 蹊┐▒│Š░ ? Į╠Ĥż╩żĘūĘ╝ėč¦┴Ģż╬ųžę¬ąį Ż©īg╩└ĮńżŪ╗Ņ▄Sż╣żļų¬─▄ż╬īg¼Fż╦Ž“ż▒żŲŻ® ©C Į╠Ĥż╩żĘč¦┴Ģ ? Į╠Ĥż╬ż╩żżč¦┴ĢźŪ®`ź┐ż½żķĪó źŪ®`ź┐ż╬▒│ßßż╦┤µį┌ż╣żļ▒Š┘|Ą─ż╩śŗįņż“ūį┬╔Ą─ż╦½@Ą├ż╣żļż│ż╚ ? č¦┴Ģż╣ż┘żŁīØŽ¾╚½żŲż╦Į╠Ĥż“ėļż©żļż│ż╚żŽ└¦ļy ©C ūĘ╝ėč¦┴Ģ ? ▀^╚źż╬č¦┴ĢĮY╣¹ż“ŲŲē▓żóżļżżżŽ═³╚┤ż╗ż║Īó ą┬ęÄż╬č¦┴ĢźŪ®`ź┐ż╦▀mÅĻż╣żļż│ż╚ ? żóżķż½żĖżß╚½żŲż“č¦┴ĢżĘżŲż¬ż»ż│ż╚żŽ└¦ļy Ż©ŁhŠ│ż╬ēõ╗»ż╦ÅĻżĖżŲĪó╬┤ų¬ż╬ų¬ūRż“ūĘ╝ėĄ─ż╦č¦┴ĢŻ®
- 3. 3/27 Į╠Ĥż╩żĘč¦┴Ģż╬┤·▒ĒĄ─╩ųĘ© ? ź»źķź╣ź┐źĻź¾ź░ ©C źąź├ź┴äI└Ēż╦żĶżļč¦┴Ģ ? Ėé║Žą═ź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»ż╦żĶżļč¦┴Ģ ©C ź¬ź¾źķźżź¾äI└Ēż╦żĶżļč¦┴Ģ Ī·īg╩└ĮńżŪż╬č¦┴Ģż╦Ž“żżżŲżżżļ
- 4. 4/27 Ėé║Žą═ź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»ż╚ ūĘ╝ėč¦┴Ģ─▄┴” ? ūį╝║ĮM┐Ś╗»ź▐ź├źū SOM (T.Kohonen, 1982) ? Neural Gas (T.M.Martinetz, 1993) ©C ź═ź├ź╚ź’®`ź»śŗįņŻ©ź╬®`ź╔╩²ż╩ż╔Ż®ż“╩┬Ū░ż╦øQČ© ©C å¢Ņ}ĄŃŻ║▒Ē¼F─▄┴”ż╦Ž▐Įńż¼żóżļ ? Growing Neural Gas Ż║GNG(B.Fritzke, 1995) ©C ź╬®`ź╔ż“Č©Ų┌Ą─ż╦ÆĘ╚ļż╣żļż│ż╚żŪĪóūĘ╝ėč¦┴Ģż╦īØÅĻ ©C å¢Ņ}ĄŃŻ║ė└ŠAĄ─ż╩č¦┴Ģż╦żŽ▀mżĄż╩żż ? GNG-U (B.Fritzke, 1997) ©C ź╬®`ź╔ż“Ž„│²ż╣żļż│ż╚żŪĪóŁhŠ│ż╬ēõ╗»ż╦īØÅĻ ©C å¢Ņ}ĄŃŻ║╝╚┤µż╬č¦┴ĢĮY╣¹ż“ŲŲē▓
- 5. 5/27 Self-Organizing Incremental Neural Network (SOINN) (F.Shen, Neural Networks, 2006) ? ╝╚┤µż╬č¦┴ĢĮY╣¹ż“ŲŲē▓ż╗ż║ż╦ĪóūĘ╝ėč¦┴Ģż¼┐╔─▄ ? ╚ļ┴”źŪ®`ź┐ż╬ź»źķź╣╩²Īó╬╗ŽÓśŗįņż“ūį┬╔Ą─ż╦½@Ą├ ? ź╬źżź║─═ąįż“│ųż─ Ęų▓╝ż“Į³╦Ų ╚ļ┴”źŪ®`ź┐ č¦┴ĢĮY╣¹
- 6. 6/27 SOINNż╦ż¬ż▒żļč¦┴Ģż╬┴„żņ ╚ļ┴”źŪ®`ź┐ ? Ż▒īė─┐ż╦č¦┴ĢźŪ®`ź┐ż“╚ļ┴” ©C ź╬®`ź╔ż“ēłų│żĄż╗ż╩ż¼żķ╚ļ┴”ż╬ Ęų▓╝ż“Į³╦Ų Ż▒īė─┐ ©C ╩┬Ū░ż╦øQČ©żĄżņż┐╗ž╩²ż¼╚ļ┴” żĄżņżļż╚Īóč¦┴Ģż“═Żų╣ ? Ż▒īė─┐ż╬č¦┴ĢĮY╣¹ż“Ż▓īė─┐ż╦ ╚ļ┴” Ż▓īė─┐ ©C ūŅĮKĄ─ż╩č¦┴ĢĮY╣¹ż“╚ĪĄ├
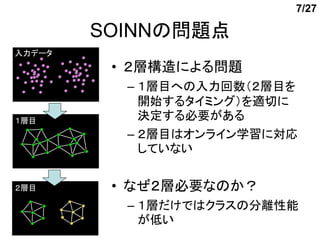
- 7. 7/27 SOINNż╬å¢Ņ}ĄŃ ╚ļ┴”źŪ®`ź┐ ? Ż▓īėśŗįņż╦żĶżļå¢Ņ} ©C Ż▒īė─┐żžż╬╚ļ┴”╗ž╩²Ż©Ż▓īė─┐ż“ ķ_╩╝ż╣żļź┐źżź▀ź¾ź░Ż®ż“▀mŪąż╦ Ż▒īė─┐ øQČ©ż╣żļ▒žę¬ż¼żóżļ ©C Ż▓īė─┐żŽź¬ź¾źķźżź¾č¦┴Ģż╦īØÅĻ żĘżŲżżż╩żż Ż▓īė─┐ ? ż╩ż╝Ż▓īė▒žę¬ż╩ż╬ż½Ż┐ ©C Ż▒īėż└ż▒żŪżŽź»źķź╣ż╬Ęųļxąį─▄ ż¼Ą═żż
- 8. 8/27 ▒ŠčąŠ┐ż╬─┐Ą─ ? SOINNż╦Ė─┴╝ż“╝ėż© ©C ź»źķź╣Ęųļxąį─▄ż“Ž“╔ŽżĄż╗żļ ©C Ż▓īė─┐ż¼▓╗ꬿ╦ż╩żĻĪóSOINNż╬å¢Ņ}ĄŃż“ĮŌøQ ╚ļ┴”źŪ®`ź┐ Ż▒īė─┐ Ż▓īė─┐
- 9. 9/27 ź»źķź╣Ęųļxąį─▄ż╬Ž“╔Ž ? ╗∙▒ŠĄ─ż╩┐╝ż© ©C ź╬®`ź╔ż╬├▄Č╚ż“Č©┴x ©C źĄźųź»źķź╣ż“Č©┴x ©C ▐xż╬▒žę¬ąįż“┼ąČ©Ż©▓╗ꬿ╩▐xż“Ž„│²Ż®
- 10. 10/27 ź╬®`ź╔ż╬├▄Č╚ ? ä┘š▀ź╬®`ź╔Ż©╚ļ┴”ź┘ź»ź╚źļż╦ūŅżŌĮ³żżź╬®`ź╔Ż®ż╦ż╩ż├ż┐ļHĪó ęįŽ┬ż╬ź▌źżź¾ź╚ż“ėļż©żļ Ż║ļOĮėź╬®`ź╔żžż╬ŲĮŠ∙ŠÓļx ? ĪĖę╗Č©Ų┌ķg”╦ż╦ėļż©żķżņżļź▌źżź¾ź╚ż╬ŲĮŠ∙éÄĪ╣ ż“├▄Č╚ż╚żĘżŲČ©┴x Ż©ż┐ż└żĘĪóź╬®`ź╔Į³░°ż╦╚ļ┴”ż¼ėļż©żķżņż╩ż½ż├ż┐Ų┌ķgżŽ│²ż»Ż® Ż╬Ż║ėļż©żķżņż┐ź▌źżź¾ź╚ż¼Ż░ęį╔Žż╬Ų┌ķg Ż║jĘ¼─┐ż╬Ų┌ķgż╦ż¬ż▒żļkĘ¼─┐ż╬ ╚ļ┴”ż╦żĶż├żŲėļż©żķżņż┐ź▌źżź¾ź╚
- 11. 11/27 źĄźųź»źķź╣ż╬øQČ© ? ź╬®`ź╔ż╬├▄Č╚ż¼Šų╦∙Ą─ż╦ūŅ┤¾żŪżóżļź╬®`ź╔ Ī·«Éż╩żļźĄźųź»źķź╣ż╬źķź┘źļż“┘Nżļ ? żĮżņęį═Ōż╬ź╬®`ź╔ Ī·├▄Č╚ż¼ūŅ┤¾ż╬ļOĮėź╬®`ź╔ż╚═¼żĖźķź┘źļż“┘Nżļ ź╬®`ź╔ż╬├▄Č╚
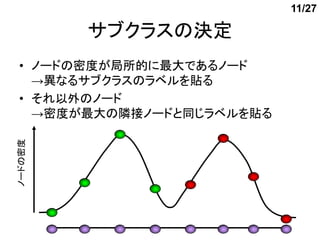
- 12. 12/27 ▐xż╬▒žę¬ąįŻ©Ż▒Ż® ? ź╬źżź║ż¼żóżļł÷║ŽĪóź╬®`ź╔ż╬├▄Č╚ż╦żŽ ╝Üż½żż░╝═╣ż¼żóżļ Ī·╠žČ©ż╬╠§╝■ż“£║ż┐ż╣▐xżŽ▓ąż╣▒žę¬ż¼żóżļ ź╬®`ź╔ż╬├▄Č╚
- 13. 13/27 ▐xż╬▒žę¬ąįŻ©Ż▓Ż® ? ęįŽ┬ż╬╠§╝■ż“£║ż┐ż╣▐xżŽ▓ąż╣ ź╬®`ź╔ż╬├▄Č╚ A Amax Ī┴”┴A ż│ż│żŪĪó”┴żŽęįŽ┬ż╬╩ĮżŪ╦Ń│÷ B Bmax Ī┴”┴B m Ż║źĄźųź»źķź╣Aż╦ż¬ż▒żļ├▄Č╚ż╬ūŅ┤¾éÄ Ż║źĄźųź»źķź╣Aż╦ż¬ż▒żļ├▄Č╚ż╬ŲĮŠ∙éÄ
- 14. 14/27 Ęųļxąį─▄Ž“╔Žż╦żĶżļä┐╣¹ ? Ż▓īė─┐ż¼▓╗ꬿ╦ ©C ═Ļ╚½ż╩ź¬ź¾źķźżź¾č¦┴Ģż¼┐╔─▄ż╦ ©C ĪĖź»źķź╣─┌ÆĘ╚ļĪ╣ż¼▓╗ꬿ╦Ż©żŌż”Ż▒ż─ż╬ä┐╣¹Ż®
- 15. 15/27 ź»źķź╣─┌ÆĘ╚ļż╬Ž„│² ? ź»źķź╣─┌ÆĘ╚ļż╚żŽŻ┐ ©C ź╬®`ź╔ż“ēłų│żĄż╗żļäI└Ēż╬Ż▒ż─ ©C Ż▓īė─┐ż╦ż¬żżżŲĪó╗Ņė├żĄżņżļ ? ź»źķź╣─┌ÆĘ╚ļż╬Ž„│²ż╦żĶżļ└¹ĄŃ ©C ėŗ╦Ń┴┐ż╬▌X£p ©C źčźķźß®`ź┐╩²ż╬Ž„£p ÅŠ└┤╩ųĘ©Ż©ŻĖż─Ż®Ī·╠ß░Ė╩ųĘ©Ż©Ż┤ż─Ż®
- 16. 16/27 īg“YŻ▒Ż║╚╦╣żźŪ®`ź┐żĮż╬Ż▒ ? ŻĄź»źķź╣Ż©ź¼ź”ź╣Ęų▓╝Ī┴Ż▓Īó═¼ą─āęĪ┴Ż▓Ī󟥟żź¾ź½®`źųŻ® ? Ż▒Ż░Żźż╬ę╗śöź╬źżź║ ? ÅŠ└┤╩ųĘ©żŽš²żĘż»č¦┴ĢżŪżŁżļŻ©šō╬─żĶżĻŻ® ūĘ╝ėč¦┴Ģż╦ż¬ż▒żļ╚ļ┴” 1 2 3 4 5 6 7 A Ī Ī B Ī Ī C Ī Ī D Ī Ī E1 Ī E2 Ī E3 Ī
- 17. 17/27 ╚╦╣żźŪ®`ź┐żĮż╬Ż▒ Ż║īg“YĮY╣¹ ? ÅŠ└┤╩ųĘ©ż╚═¼śöż╬ĮY╣¹ż¼Ą├żķżņż┐ ©C ÅŠ└┤╩ųĘ©ż╬└¹ĄŃż“Š@│ą Ż©ź╬źżź║─═ąįĪ󟻟ķź╣╩²?╬╗ŽÓśŗįņż╬ūį┬╔Ą─½@Ą├Ż® ═©│Żż╬č¦┴Ģ ūĘ╝ėč¦┴Ģ
- 18. 18/27 īg“YŻ▓Ż║╚╦╣żźŪ®`ź┐żĮż╬Ż▓ ? Ż│ź»źķź╣Ż©ź¼ź”ź╣Ęų▓╝Ī┴Ż│Ż® ? Ż▒Ż░Żźż╬ę╗śöź╬źżź║ ? īg“YŻ▒żĶżĻĖ▀├▄Č╚ż╩ųžż╩żĻż“│ųż─ ūĘ╝ėč¦┴Ģż╦ż¬ż▒żļ╚ļ┴” Ż▒ Ż▓ Ż│ A Ī B Ī C Ī
- 19. 19/27 ╚╦╣żźŪ®`ź┐żĮż╬Ż▓Ż║ÅŠ└┤╩ųĘ© Input First layer Second layer ? Ė▀├▄Č╚ż╬ųžż╩żĻż“│ųż─ź»źķź╣ż“ĘųļxżŪżŁż╩żż Input First layer Second layer ═©│Żż╬č¦┴Ģ ūĘ╝ėč¦┴Ģ
- 20. 20/27 ╚╦╣żźŪ®`ź┐żĮż╬Ż▓Ż║╠ß░Ė╩ųĘ© ? ÅŠ└┤╩ųĘ©ż“│¼ż©żļĘųļx─▄┴”ż“īg¼F ©C Input Ė▀├▄Č╚ż╬ųžż╩żĻż“│ųż─ź»źķź╣ż“ĘųļxżŪżŁżļ ═©│Żż╬č¦┴Ģ ūĘ╝ėč¦┴Ģ źŪźŌ
- 21. 21/27 īg“YŻ│Ż║AT&T_FACE ? 10╚╦ż╬Ņå╗ŁŽ±Ż©Ė„ź»źķź╣Ż▒Ż░źĄź¾źūźļŻ® ? Ż▒Ż»Ż┤ż╦┐sąĪżĘĪóŲĮ╗¼╗»żĘż┐╗ŁŽ±ż“╩╣ė├ Ż©Ż▓Ż│Ī┴Ż▓ŻĖŻĮŻČŻ┤Ż┤┤╬į¬Ż® ? ÅŠ└┤╩ųĘ©żŪżŽš²żĘż»ĘųŅÉżŪżŁżļŻ©šō╬─żĶżĻŻ®
- 22. 22/27 AT&T_FACEŻ║īg“YĮY╣¹ ? ÅŠ└┤╩ųĘ©ż╚═¼Ą╚ż╬ĮY╣¹ż¼Ą├żķżņż┐ ©C č¦┴Ģ└²Ż©Ė„ź»źķź╣ż╬źūźĒź╚ź┐źżźūź┘ź»ź╚źļŻ® šJūR┬╩Ż©ŻźŻ® ═©│Żż╬č¦┴Ģ ūĘ╝ėč¦┴Ģ ╠ß░Ė╩ųĘ© Ż╣Ż░ ŻĖŻČ ÅŠ└┤╩ųĘ©Ż©šō╬─żĶżĻŻ® Ż╣Ż░ ŻĖŻČ Ī∙Ą├żķżņż┐ź»źķź╣ż╬źķź┘źļŻ©šlż╬Ņåż½Ż®żŽ╚╦ż¼øQČ©żĘĪóšJūRīg“Yż“ąąż├ż┐
- 23. 23/27 AT&T_FACEŻ║│÷┴”ź»źķź╣╩²ż╬ŅlČ╚ ? ÅŠ└┤╩ųĘ©ż“│¼ż©żļ░▓Č©ąįż“īg¼F ©C ╠ß░Ė╩ųĘ©żŽ░▓Č©Ą─ż╦Ż▒Ż░ź»źķź╣Ū░ßßż“│÷┴” 400 350 ╠ß░Ė╩ųĘ©ĪĪĪĪ (═©│Żż╬č¦┴Ģ) 300 250 ╠ß░Ė╩ųĘ© ĪĪ ╗ž (ūĘ╝ėč¦┴Ģ) ╩² 200 150 ÅŠ└┤╩ųĘ© ĪĪĪĪ (═©│Żż╬č¦┴Ģ) 100 50 ÅŠ└┤╩ųĘ© (ūĘ╝ėč¦┴Ģ) 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ź»źķź╣╩²
- 24. 24/27 īg“YŻ┤Ż║Optdigits ? Ż░Ī½Ż╣ż▐żŪż╬╩ųĢ°żŁ╩²ūųŻ©Ż▒Ż░ź»źķź╣Ż® ? ŻĖĪ┴ŻĖźĄźżź║Ż©64┤╬į¬Ż® ? źŪ®`ź┐╩²Ż║Ż│ŻĖŻ▓Ż│Ż©č¦┴Ģė├Ż®ĪóŻ▒ŻĘŻ╣ŻĘŻ©źŲź╣ź╚ė├Ż® č¦┴ĢźŪ®`ź┐ż╬└²Ż©Ė„ź»źķź╣ż╬ŲĮŠ∙ź┘ź»ź╚źļŻ®
- 25. 25/27 OptdigitsŻ║īg“YĮY╣¹ ? ÅŠ└┤╩ųĘ©żĶżĻ▀mŪąż╩ĘųŅÉż“īg¼F ©C č¦┴Ģ└²Ż©Ė„ź»źķź╣ż╬ŲĮŠ∙ź┘ź»ź╚źļŻ® ? ╠ß░Ė╩ųĘ© ? ÅŠ└┤╩ųĘ© ūŅŅl│÷ż╬ šJūR┬╩Ż©ŻźŻ® ź»źķź╣╩² ═©│Żż╬č¦┴Ģ ūĘ╝ėč¦┴Ģ ╠ß░Ė╩ųĘ© Ż▒Ż▓ Ż╣Ż┤Ż«Ż│ Ż╣ŻĄŻ«ŻĖ ÅŠ└┤╩ųĘ© Ż▒Ż░ Ż╣Ż▓Ż«Ż▓ Ż╣Ż░Ż«Ż┤ Ī∙Ą├żķżņż┐ź»źķź╣ż╬źķź┘źļŻ©ż╔ż╬╩²ūųż½Ż®żŽ╚╦ż¼øQČ©żĘĪóšJūRīg“Yż“ąąż├ż┐
- 26. 26/27 ż▐ż╚żß ? SOINNŻ©F.Shen, Neural Networks, 2006Ż®ż“ Ė─┴╝żĘż┐ą┬żĘżżĮ╠Ĥż╩żĘč¦┴Ģ╩ųĘ©ż“╠ß░Ė ©C ÅŠ└┤╩ųĘ©Ż©SOINNŻ®ż╬└¹ĄŃż“Š@│ą ? ź╬źżź║─═ąį ? ź»źķź╣╩²Īó╬╗ŽÓśŗįņż╬ūį┬╔Ą─½@Ą├ ©C Ęų▓╝ż╦ųžż╩żĻż“│ųż─ź»źķź╣ż╬Ęųļxąį─▄ż“Ž“╔Ž ©C ═Ļ╚½ż╩ź¬ź¾źķźżź¾č¦┴Ģż¼┐╔─▄ż╦ ©C ░▓Č©ąįż╬Ž“╔Ž ©C źčźķźß®`ź┐╩²ż╬Ž„£p
- 27. 27/27 Į±ßßż╬šnŅ} ? Ė³ż╩żļ░▓Č©ąįż╬Ž“╔Ž ? Ė³ż╩żļźčźķźß®`ź┐╩²ż╬Ž„£p ? č¦┴ĢĮY╣¹ż╬═³╚┤