海鸟の経路予测のための逆强化学习
Download as pptx, pdf2 likes3,140 views

2018年3月16日に开催された,新学术领域「生物ナビゲーションのシステム科学(生物移动情报学)」セミナーで発表したスライドです.

![6
Activity Forecasting
? Markov Decision Process (MDP)
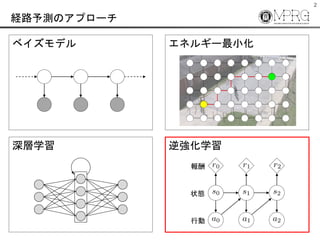
? 現在の状態 と 行動 から状態が遷移
? 現在地 と 移動方向 から現在地が遷移
? 行動選択で移動経路が決まる
? Activity Forecasting [Kitani et al., 2012]
? 対象の行動を予測する問題設定
? 行動により変化した状態(座標)の系列が経路予測結果
※ Path prediction: 各時刻の座標を直接推定?出力
状態
行動
報酬](https://image.slidesharecdn.com/20180316irlprediction-180319003044/85/-6-320.jpg)
![7
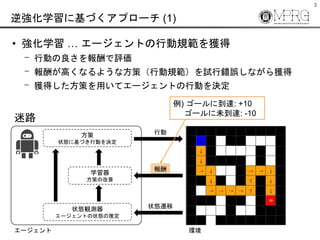
Activity Forecasting [Kitani, et al., 2012]
? 人間の移動経路は周囲の環境に大きく影響
? 車道?歩道?建物
? 逆強化学習を用いて行動規範を獲得
? Maximum Entropy Inverse Reinforcement Learning
(MaxEnt IRL)
Physical attribute Forecast distribution](https://image.slidesharecdn.com/20180316irlprediction-180319003044/85/-7-320.jpg)

![14
逆強化学習のアプローチ
? 線型計画法 [Ng, et al., 2000]
? もっとも古典的なアプローチ
? Apprenticeship learning
[Abbeel, et al., 2004]
? Max margin法?Projection法を使って?を求める
? Maximum entropy IRL [Ziebart, et al., 2008]
? 確率的な手法に拡張
? Maximum Entropy Deep IRL [Wulfmeir, et al., 2015]
? 深層学習を使う形に拡張](https://image.slidesharecdn.com/20180316irlprediction-180319003044/85/-14-320.jpg)



![19
評価実験
? 2種類の設定で実験
実験1: 経路予測 [Hirakawa, et al., 2017]
? スタートからゴールまでの経路を
確率分布で出力
実験2: 欠損した軌跡の補間
? 軌跡の一部分を欠損させ,経路予測
? 各状態での最大の確率の行動を選択し,
軌跡(座標列)を出力
事情によりお見せできません](https://image.slidesharecdn.com/20180316irlprediction-180319003044/85/-19-320.jpg)

海鸟の経路予测のための逆强化学习
- 1. 1 新学術領域「生物ナビゲーションのシステム科学(生物移動情報学)」セミナー March 16, 2018 海鸟の経路予测のための逆强化学习 平川 翼 中部大学 機械知覚ロボティクスグループ
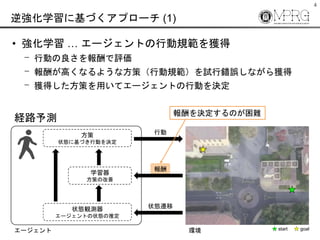
- 3. 3 逆強化学習に基づくアプローチ (1) ? 強化学習 … エージェントの行動規範を獲得 ? 行動の良さを報酬で評価 ? 報酬が高くなるような方策(行動規範)を試行錯誤しながら獲得 ? 獲得した方策を用いてエージェントの行動を決定 エージェント 方策 状態に基づき行動を決定 学習器 方策の改善 状態観測器 エージェントの状態の推定 環境 行動 報酬 状態遷移 迷路 例) ゴールに到達: +10 ゴールに未到達: -10
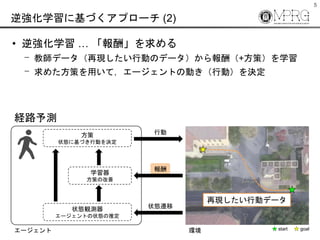
- 4. 4 逆強化学習に基づくアプローチ (1) ? 強化学習 … エージェントの行動規範を獲得 ? 行動の良さを報酬で評価 ? 報酬が高くなるような方策(行動規範)を試行錯誤しながら獲得 ? 獲得した方策を用いてエージェントの行動を決定 経路予測 エージェント 方策 状態に基づき行動を決定 学習器 方策の改善 状態観測器 エージェントの状態の推定 環境 行動 報酬 状態遷移 報酬を決定するのが困難
- 5. 5 逆強化学習に基づくアプローチ (2) ? 逆強化学習 … 「報酬」を求める ? 教師データ(再現したい行動のデータ)から報酬(+方策)を学習 ? 求めた方策を用いて,エージェントの動き(行動)を決定 経路予測 エージェント 方策 状態に基づき行動を決定 学習器 方策の改善 状態観測器 エージェントの状態の推定 環境 行動 状態遷移 報酬 再現したい行動データ
- 6. 6 Activity Forecasting ? Markov Decision Process (MDP) ? 現在の状態 と 行動 から状態が遷移 ? 現在地 と 移動方向 から現在地が遷移 ? 行動選択で移動経路が決まる ? Activity Forecasting [Kitani et al., 2012] ? 対象の行動を予測する問題設定 ? 行動により変化した状態(座標)の系列が経路予測結果 ※ Path prediction: 各時刻の座標を直接推定?出力 状態 行動 報酬
- 7. 7 Activity Forecasting [Kitani, et al., 2012] ? 人間の移動経路は周囲の環境に大きく影響 ? 車道?歩道?建物 ? 逆強化学習を用いて行動規範を獲得 ? Maximum Entropy Inverse Reinforcement Learning (MaxEnt IRL) Physical attribute Forecast distribution
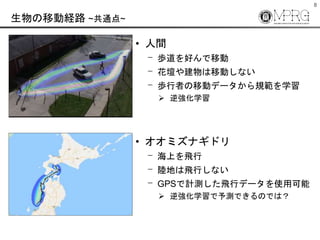
- 8. 8 生物の移動経路 ~共通点~ ? 人間 ? 歩道を好んで移動 ? 花壇や建物は移動しない ? 歩行者の移動データから規範を学習 ? 逆強化学習 ? オオミズナギドリ ? 海上を飛行 ? 陸地は飛行しない ? GPSで計測した飛行データを使用可能 ? 逆強化学習で予測できるのでは?
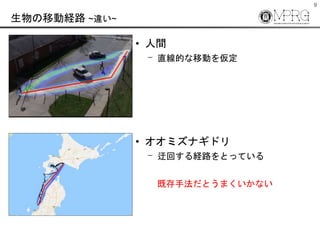
- 9. 9 生物の移動経路 ~違い~ ? 人間 ? 直線的な移動を仮定 ? オオミズナギドリ ? 迂回する経路をとっている 既存手法だとうまくいかない
- 10. 10 目的 ? 直線的でない移動経路の予測 ? 人間以外の対象の移動経路を予測可能に アプローチ ? 状態空間を時間方向に拡張 ? 対象がゴールに到達するまでの時間(行動回数)を与える ? 直線的でない動きを考慮
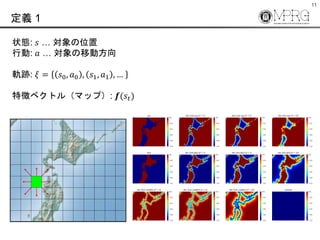
- 11. 11 定義 1 状態: ? … 対象の位置 行動: ? … 対象の移動方向 軌跡: ? = ?0, ?0 , ?1, ?1 , … 特徴ベクトル(マップ): ?(??)
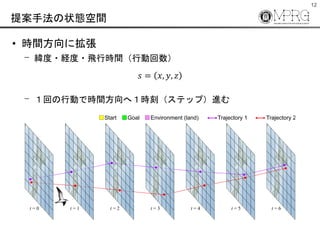
- 12. 12 提案手法の状態空間 ? 時間方向に拡張 ? 緯度?経度?飛行時間(行動回数) ? 1回の行動で時間方向へ1時刻(ステップ)進む Start Goal Environment (land) Trajectory 1 Trajectory 2 t = 0 t = 1 t = 2 t = 3 t = 4 t = 5 t = 6 ? = ?, ?, ?
- 13. 13 定義 2 ? 逆強化学習における報酬 ? 重みベクトルと特徴ベクトルの線形結合で表現 ある状態??で得られる報酬 ある軌跡?で得られる報酬 ? ??; ? = ?T ?(??) ? ?; ? = ? ?(??; ?) = ? ? ? ?(??) ↑ 与えられている (自分で準備する) ↑ これを求めたい! 学習データの行動を再現するような報酬を求める → 重みベクトルを求める 逆強化学習
- 14. 14 逆強化学習のアプローチ ? 線型計画法 [Ng, et al., 2000] ? もっとも古典的なアプローチ ? Apprenticeship learning [Abbeel, et al., 2004] ? Max margin法?Projection法を使って?を求める ? Maximum entropy IRL [Ziebart, et al., 2008] ? 確率的な手法に拡張 ? Maximum Entropy Deep IRL [Wulfmeir, et al., 2015] ? 深層学習を使う形に拡張
- 15. 15 軌跡を確率的に定義 ? ある特徴ベクトル?とパラメータ?が与えられたとする ? ?のもとで,軌跡?を取りうる確率 ? Maximum entropy distributionで定義 ? = ? = 0.1 ? 0.6 ? ? ? = exp ? ?T ? ?? ?(?) ∝ exp ? ?T ? ??
- 16. 16 期待値報酬 ? 確率?(?|?)のもとで得られる報酬の期待値 ? 学習データと同じような軌跡を予測(生成)する ? エキスパートと同じ報酬が得られるはず ? 得られる特徴ベクトルの累積値(期待値)が同じになるはず ? ? ? ? ?(?; ?) = ? ? ? ? ? ?T ?(??) = ?T ? ? ? ? ? ? ?(??) ? ? ? ? ? ?(??) = ? ?( ??) ※ ?? 学習データの座標(列)
- 17. 17 学習方法 ? 最尤推定(maximum likelihood estimation; MLE) ? 学習データの軌跡 ?の尤度を最大化する ?を求める ? Exponentiated gradient descentで?更新 1. 勾配を計算 2. 重みベクトル?を更新 ? = ?????? ? ? ? = ?????? ? log ?( ?|?) ?? ? = ? ?( ??) ? ? ? ? ? ? ?(??) ? ← ? exp{ ???(?)}
- 18. 18 学習?テスト方法(確率分布の計算方法) ? Backward pass ? ある状態からゴールへ向かう行動を推定 ? 隣接する状態の報酬との差分を計算 ? 報酬が大きいほど行動の確率が高くなる ? Forward pass ? 推定した行動をもとに確率分布を生成 ? スタートに最大の確率を保持 ? 推定した確率分布を使って,確率値を伝搬
- 19. 19 評価実験 ? 2種類の設定で実験 実験1: 経路予測 [Hirakawa, et al., 2017] ? スタートからゴールまでの経路を 確率分布で出力 実験2: 欠損した軌跡の補間 ? 軌跡の一部分を欠損させ,経路予測 ? 各状態での最大の確率の行動を選択し, 軌跡(座標列)を出力 事情によりお見せできません
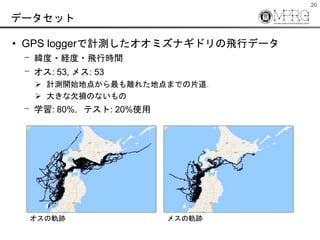
- 20. 20 データセット ? GPS loggerで計測したオオミズナギドリの飛行データ ? 緯度?経度?飛行時間 ? オス: 53, メス: 53 ? 計測開始地点から最も離れた地点までの片道. ? 大きな欠損のないもの ? 学習: 80%,テスト: 20%使用 オスの軌跡 メスの軌跡
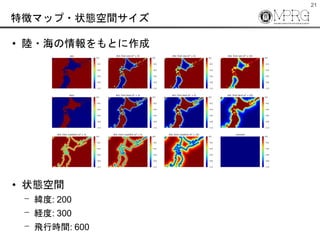
- 21. 21 特徴マップ?状態空間サイズ ? 陸?海の情報をもとに作成 ? 状態空間 ? 緯度: 200 ? 経度: 300 ? 飛行時間: 600
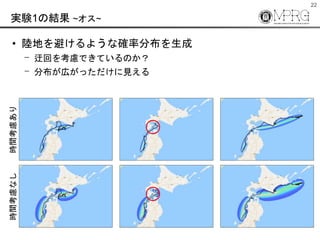
- 22. 22 実験1の結果 ~オス~ ? 陸地を避けるような確率分布を生成 ? 迂回を考慮できているのか? ? 分布が広がっただけに見える 時間考慮あり時間考慮なし
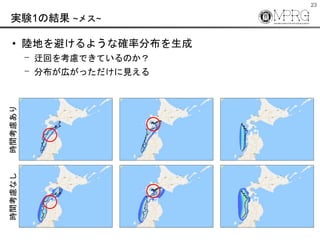
- 23. 23 実験1の結果 ~メス~ ? 陸地を避けるような確率分布を生成 ? 迂回を考慮できているのか? ? 分布が広がっただけに見える 時間考慮あり時間考慮なし
- 24. 24 まとめ ? 迂回するような移動を考慮した経路予測手法を提案 ? 逆強化学習(MaxEnt IRL)ベース ? 状態空間を時間方向に拡張 ? ゴールへ到達するまでの行動回数を明示的に与える ? 直線的な経路以外を予測可能 ? 今後の予定 ? 時間方向に変化する特徴の導入 ? 昼夜 ? 天候 ? 効率的な計算アルゴリズムの考案 ? 現在の学習時間: 3~4日(32スレッド処理)
Editor's Notes
- #4: 文字通り,強化学習の枠組みに基づいて経路予測が行われます. まず,強化学習にはエージェントと呼ばれる何らかの行動を行う対象とそのエージェントが行動を行う環境が存在します. ここではロボットがある迷路内で,スタートからゴールまでたどり着くような学習を例にとって考えてみます. この場合のエージェントはロボットで,環境は迷路となります. 強化学習ではゴールへたどり着くための学習を試行錯誤しながら行なっていきます. はじめのうちはゴールへたどり着けいない場合もありますが,試行錯誤を繰り返すうちに最適な行動が選択できるようになります. この時,行動の良し悪しを図る指標として報酬が与えられ,この報酬が大きくなるように方策を改善することで学習が進んでいきます.
- #5: この迷路の問題を実際の経路予測に置き換えてみます. エージェントは歩行者などの予測対象となり,環境は動画像などのシーンとなります. この環境下で試行錯誤を行えば良さそうですが,この問題では現実世界のデータを扱うため,試行錯誤が困難であり,そもそも,報酬を決めることが難しいという問題があります.
- #6: そこで,その報酬を再現したい行動データから求めようというのが逆強化学習です. 逆強化学習では教師データの動きをうまく再現できるような報酬を学習し求めます. 学習が終わると,スタートとゴールを設定し,求めた報酬及び方策を用いてエージェントを動かすことで経路予測を実現します.
- #7: この強化学習の枠組みは一般的にマルコフ決定過程MDPで定式化されます. MDPには状態と行動と呼ばれる変数が各時刻に存在しており,いまの状態から行動を決定し,その行動によって状態が変化するというモデルになっています. これを経路予測として言い換えると,現在地から移動方向を決定し,移動することで現在地が遷移するということになります. つまり,強化学習の枠組みでは行動の選択が重要となるわけです. これを踏まえた上で,逆強化学習による経路予測は主にActivity Forecastingと呼ばれています.これはKitaniらによって提案された比較的新しい問題設定です. Activity forecastingでは各時刻での対象のとる行動を予測する問題となっており,行動によって変化した状態の系列が経路予測の結果となります.