





![fitから簡単に数値取り出せない問題発生
? stanfit ファイル(今回でいう fit )はS4クラス形式で保存
? S4クラス形式とは?
? 普通のオブジェクトよりも複雑な形式で保存されている(っていう認識
でここでは問題ないと思う)。
? 普通のオブジェクトとは異なり、$で引き出すのではなく、@を用いて
中身を取り出す。
? ちなみに、JAGSの結果はS3クラスで保存されていて、これが同じよう
な操作ができないことの理由。最近はggmcmcなるパッケージがありま
すので便利ですけれども(わからない人は聞き流してください)
? 例えばこんな感じ(下記はモデルのパラメータを抽出している)
> fit@model_pars
[1] "mu" "tau" "eta" "theta" "lp__"
(飛ばしても良い)
7](https://image.slidesharecdn.com/stan-161224205656/85/Stan-7-320.jpg)

![やりたいこと①
? 魔法の言葉「 」で抽出して解決
? そして、一括判定してあげる。
※「 ,na.rm = T 」をつける意味
stanモデル上でパラメータに直接数値を代入している場合、 ??は当然算出されず、
??=NaNとなります。そのような場合、欠損値の除去を行わないと正常に判定するこ
とが出来ません。
??で収束判定
> all(summary(fit)$summary[,“Rhat”] <= 1.10, na.rm = T)
# all() ()内で論理式を全て満たしたらTRUEを返す関数
[1] TRUE
9](https://image.slidesharecdn.com/stan-161224205656/85/Stan-9-320.jpg)

![やりたいこと③
? 魔法の言葉「 」をまたまた使う
? ??を取り出してきたとき同様に、[, ”mean”]としてあげるだけ
? 他の変数も“”で指定すれば抽出可能。
小数第3位表示の事後平均値を抜き出したい 11](https://image.slidesharecdn.com/stan-161224205656/85/Stan-11-320.jpg)


![補足
? 事後平均が知りたいのではなく、特定のパラメータの各点推
定値が知りたい。
? たとえば、“mu”の場合
? このように、[,]の行にあたる部分でパラメータの指定すれば取
り出すことが出来る。
14](https://image.slidesharecdn.com/stan-161224205656/85/Stan-14-320.jpg)


![stan_trace
? この関数はトレースプロットを出力することが出来る。
eta[7] eta[8]
eta[3] eta[4] eta[5] eta[6]
mu tau eta[1] eta[2]
500 600 700 800 900 1000 500 600 700 800 900 1000
500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000
500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000
-2
0
2
4
-4
-2
0
2
-2
0
2
-2
0
2
0
10
20
30
40
-2
0
2
-2
0
2
0
10
20
-2
0
2
-2
0
2
chain
1
2
3
4
今回はプロットするパラメータを
設定していないので10個分の
パラメータが表示、
バーンイン期間が非表示(デフォルト)
stan_trace(fit)
17](https://image.slidesharecdn.com/stan-161224205656/85/Stan-17-320.jpg)








![これを応用して...
? 先ほど収束判定で以下を用いましたが
? 以下でも可能です。
> all(summary(fit)$summary[,“Rhat”] <= 1.10, na.rm = T)
# all() ()内で論理式を全て満たしたらTRUEを返す関数
[1] TRUE
> all(stan_rhat(fit)$data <= 1.10, na.rm = T)
# all() ()内で論理式を全て満たしたらTRUEを返す関数
[1] TRUE
28](https://image.slidesharecdn.com/stan-161224205656/85/Stan-28-320.jpg)

![おまけ extract()
? おれは要約統計量ではなく、発生させた乱数列全てがほしいんだ!!!と
言う方は、
? extract(fit)とすれば発生させた乱数列を抽出出来ます
? extractで抽出した乱数を用いて、median、mean等々を求めれば、もちろん、それがMAP、
EAP等になります。
この関数のオプションとして,,,
? inc_warmup=Tをつければ、バーンイン期間を含む乱数列がとれます。
? permuted=Tをつけると、同パラメータのchainが縦につながった状態で出
ます(list形式)。permuted=Fにすると同パラメータのchainが区別された状
態で出ます(3次元配列[ iter, chain, parameter ]形式)。
30](https://image.slidesharecdn.com/stan-161224205656/85/Stan-30-320.jpg)



厂迟补苍の便利な事后処理関数
- 2. 動機 ? Stan Advent Calendar 2016 という素晴らしいものがある。 http://qiita.com/advent-calendar/2016/stan ? すごいためになるモデルばかり...(お菓子力も、サンシャイン力もあがる) ? レベル高すぎない??(もちろん素晴らしいですけど) ? 初心者は記事通りモデル回してStan結果ファイルを自由に扱 えるだろうか? ? Stanには、結果処理の上質な関数が整っているけど、初心者 にはあまり知られていないのでは!? ?X’mas暇 2
- 3. この資料 ? Stan結果処理の便利な関数をまとめてみた(20161225時点)。 ? Stan動かせるようになったばかりの人向け。 ? 今回の実行環境?人 ?Windows 10 ?Rstudio version 1.0.44 ?RStan ver 2.13.2 ?ggplot2 ver 2.2.0 ?Stan歴 2年 ? 内容等、間違っていたら教えてください。 3
- 4. おなじみのデモデータ ? まずは 8schools.stan を実行 詳しくは (https://github.com/stan-dev/rstan/wiki/RStan-Getting-Started) setwd(“ディレクトリ") # rm(list=ls()) #Enviroment をきれいにします。 library(rstan) #パッケージ読み込み rstan_options(auto_write = TRUE) #並列処理(下と合わせて) options(mc.cores = parallel::detectCores()) # options(max.print = 99999) #Consoleに表示する個数の設定 schools_dat <- list(J = 8, y = c(28, 8, -3, 7, -1, 1, 18, 12), sigma = c(15, 10, 16, 11, 9, 11, 10, 18)) fit <- stan(file = '8schools.stan', data = schools_dat, iter = 1000, chains = 4) 4
- 5. summary & get_ 編 魔法の言葉「 」 5
- 6. 先ほどのモデルを普通に結果出力してみる。 よし! 結果出力できた。 やりたいこと 1. ??で収束判定を して、 2. 小数点以下は3 桁まで表示して 3. 事後平均値を抽 出したい fitから抽出すりゃいいか 6
- 7. fitから簡単に数値取り出せない問題発生 ? stanfit ファイル(今回でいう fit )はS4クラス形式で保存 ? S4クラス形式とは? ? 普通のオブジェクトよりも複雑な形式で保存されている(っていう認識 でここでは問題ないと思う)。 ? 普通のオブジェクトとは異なり、$で引き出すのではなく、@を用いて 中身を取り出す。 ? ちなみに、JAGSの結果はS3クラスで保存されていて、これが同じよう な操作ができないことの理由。最近はggmcmcなるパッケージがありま すので便利ですけれども(わからない人は聞き流してください) ? 例えばこんな感じ(下記はモデルのパラメータを抽出している) > fit@model_pars [1] "mu" "tau" "eta" "theta" "lp__" (飛ばしても良い) 7
- 8. やりたいこと① ? ??とは... ? chain内分散とchain間分散を用いた定常分布への収束確認に用いられる 指標。 ? ?? < 1.10であれば収束 ? 今回の例であれば、パラメータ数も多くないので、全てのパラメータの ?? を見て即座に判断出来る。 ? だけど、パラメータの多いモデルでは、それが困難な場合がある ? (ちなみに私がよく使用するIRTモデルだとパラメータ数30000個ぐらいあるので 一目で確認するのは困難)。 ? そんなときにどう判断するのが効率的か?? ??で収束判定 8
- 9. やりたいこと① ? 魔法の言葉「 」で抽出して解決 ? そして、一括判定してあげる。 ※「 ,na.rm = T 」をつける意味 stanモデル上でパラメータに直接数値を代入している場合、 ??は当然算出されず、 ??=NaNとなります。そのような場合、欠損値の除去を行わないと正常に判定するこ とが出来ません。 ??で収束判定 > all(summary(fit)$summary[,“Rhat”] <= 1.10, na.rm = T) # all() ()内で論理式を全て満たしたらTRUEを返す関数 [1] TRUE 9
- 10. やりたいこと② ? 魔法の言葉「 」をまた使う ? 今回round()を使う ? round()は数値を丸める関数(stan専用関数ではない。) ? digits= で小数点以下の桁数を設定 小数点以下を3桁まで表示にしたい 10
- 11. やりたいこと③ ? 魔法の言葉「 」をまたまた使う ? ??を取り出してきたとき同様に、[, ”mean”]としてあげるだけ ? 他の変数も“”で指定すれば抽出可能。 小数第3位表示の事後平均値を抜き出したい 11
- 13. 他にも ? get_logposterior(fit) ? 発生させた対数事後確率の乱数を取り出す ? get_inits(fit) ? 推定の際の各パラメータの初期値を取り出す ? get_seeds(fit) ? 推定の際の各パラメータの乱数の種を取り出す ? get_stanmodel(fit) ? 推定に用いたstanモデルを取り出す ? get_elapsed_time(fit) ? 推定時間(warmupとsampleが分かれてでる) 等々 13
- 14. 補足 ? 事後平均が知りたいのではなく、特定のパラメータの各点推 定値が知りたい。 ? たとえば、“mu”の場合 ? このように、[,]の行にあたる部分でパラメータの指定すれば取 り出すことが出来る。 14
- 15. stan_ 編 ※最近 rstan と ggplot2 のver違いでうまく回せないことがあるらしいです。 そのうち対応すると思われます。 15
- 16. stan_ シリーズ ? 実は、stan_?? で様々な便利な関数が保存されている (ggplot2書式のplotをはき出してくれる。) 16
- 17. stan_trace ? この関数はトレースプロットを出力することが出来る。 eta[7] eta[8] eta[3] eta[4] eta[5] eta[6] mu tau eta[1] eta[2] 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 500 600 700 800 900 1000 -2 0 2 4 -4 -2 0 2 -2 0 2 -2 0 2 0 10 20 30 40 -2 0 2 -2 0 2 0 10 20 -2 0 2 -2 0 2 chain 1 2 3 4 今回はプロットするパラメータを 設定していないので10個分の パラメータが表示、 バーンイン期間が非表示(デフォルト) stan_trace(fit) 17
- 18. stan_trace ? オプションを加えてあげると stan_trace(fit, pars = c("eta"), inc_warmup = T) # pars = で出力パラメータ設定 # inc_warmup =T でバーンイン期間も出力 バーンイン期間は 灰色で出力される 18
- 19. stan_hist ? この関数は(事後分布の)ヒストグラムを書くことが出来る関数 stan_hist(fit, bins = 100) # bins = でヒストグラムの“細かさ”を設定(デフォルトは30) # 先ほどのオプションも使える 19
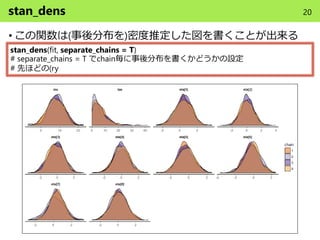
- 20. stan_dens ? この関数は(事後分布を)密度推定した図を書くことが出来る stan_dens(fit, separate_chains = T) # separate_chains = T でchain毎に事後分布を書くかどうかの設定 # 先ほどの(ry 20
- 21. stan_plot ? この関数は各事後分布を1枚の図で出力できる。 stan_plot(fit, point_est = “median”, #点推定値(黒縦棒)を何で表示するか(mean/median) show_density = T, #密度推定した分布を表示するか ci_level = 0.95, #確信区間(ベイズ信頼区間)の範囲指定 outer_level = 1.00, #分布の端っこをどこまで表示するか show_outer_line = T) #分布の端っこを表示するか 21
- 24. stan_rhat ? この関数は ??を視覚的に確認できる関数(chain = 1だと回せません) ? ?? < 1.10であれば収束 stan_rhat(fit) 1.10以内に全て おさまっている ?OK 24
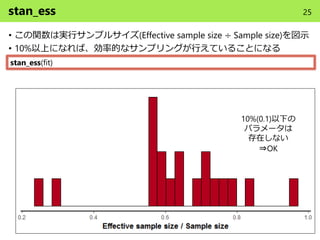
- 25. stan_ess ? この関数は実行サンプルサイズ(Effective sample size ÷ Sample size)を図示 ? 10%以上になれば、効率的なサンプリングが行えていることになる stan_ess(fit) 10%(0.1)以下の パラメータは 存在しない ?OK 25
- 26. 他にも??? ←stan_diag(fit) ↓ stan_par(fit, par = “mu”) 26
- 27. さらに... ? 各 stan_ シリーズの最後に$dataをつけることでplotに用いた dataを抽出することが出来ます。 ? たとえば...stan_plotの場合 mean = 事後平均値 ll=outer_levelで設定した点(低い方) l = ci_levelで設定した点(低い方) m = median h, hh = l, llの逆。高い方。 27
- 28. これを応用して... ? 先ほど収束判定で以下を用いましたが ? 以下でも可能です。 > all(summary(fit)$summary[,“Rhat”] <= 1.10, na.rm = T) # all() ()内で論理式を全て満たしたらTRUEを返す関数 [1] TRUE > all(stan_rhat(fit)$data <= 1.10, na.rm = T) # all() ()内で論理式を全て満たしたらTRUEを返す関数 [1] TRUE 28
- 30. おまけ extract() ? おれは要約統計量ではなく、発生させた乱数列全てがほしいんだ!!!と 言う方は、 ? extract(fit)とすれば発生させた乱数列を抽出出来ます ? extractで抽出した乱数を用いて、median、mean等々を求めれば、もちろん、それがMAP、 EAP等になります。 この関数のオプションとして,,, ? inc_warmup=Tをつければ、バーンイン期間を含む乱数列がとれます。 ? permuted=Tをつけると、同パラメータのchainが縦につながった状態で出 ます(list形式)。permuted=Fにすると同パラメータのchainが区別された状 態で出ます(3次元配列[ iter, chain, parameter ]形式)。 30
- 31. おまけ Stanfitの中身 ? fit@ と打つと... ? いっぱい出てくる ? これがS4くらすか!! 31
- 32. おまけ Stanfitの中身 ? 全部出してみた。 ? 上から ? モデル名 ? モデル内のパラメータ ? パラメータの次元 ? 推定がうまく出来ているか??(通常は0) ? 発生させた乱数と採択率等 ? 各パラメータの初期値 32
- 33. おまけ Stanfitの中身 ? 全部出してみた(続き) ? 上から ? 各引数(iterやseed等々) ? モデル ? 推定日 33
- 34. Enjoy your Stan Life. Merry Christmas...