Supply frame high availability in web content delivery
?Download as PPTX, PDF?
0 likes?652 views

This document discusses strategies for achieving high availability and maximizing uptime for applications and services. It outlines the need to engineer data centers, networks, servers, operating systems, applications, and staffing. Some key aspects covered include eliminating single points of failure, automatically detecting and addressing errors through redundant backup systems, balancing high availability with increased complexity, and monitoring systems and services.















Supply frame high availability in web content delivery
- 1. Aleksandar Bilanovic, SRE at Supply Frame, Inc. 14.10.2014
- 2. ? Minimizing risk associated with service failure and providing maximum uptime for application. ? In order to achieve it we need to engineer and plan data center, network, servers, OS, applications and people. ? It is about eliminating SPOF, detection of errors and building automated and reliable crossover to backup infrastructure. ? Pros: high uptime, faster web content delivery, satisfied users, dealing with capacities and not with service denials. ? Cons: high price, risk that HA arch became unmaintainable due to complexity, high complexity can contribute to failure and downtime.
- 4. ? Physical vs. virtual ? Carrier neutral ? Redundant power with industrial UPS / diesel generators ? Climate control ? Fire suppression ? Physical access control ? Backup data center with redundant dark fiber cross connect
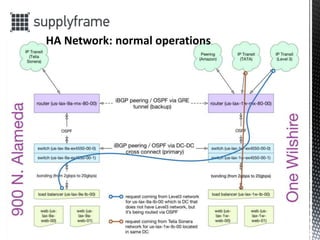
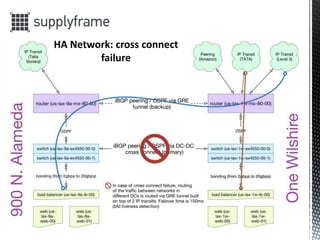
- 5. ? Internet access: BGP routing with multiple IP transits ? Local network: switch clusters for core/distribution/access layers ? Primary and backup data center routing ? Link aggregation ? Redundant power supplies
- 12. ? Server class machines only ? Redundant power supplies ? Redundant Array of Inexpensive / Independent Disks (RAID) ? Remote server console (iDRAC)
- 13. ? OS performance tuning (TCP/IP / number of open files, various memory buffers etc ˇ ) ? Redundant databases / API backends ? Protection servers / app performances from aggressive crawlers (iptables recent module on LBs) ? OS/ App services monitoring (nagios, riemann, graphite, dynect, pingdom, new relic) ? Data backup (online and offline)
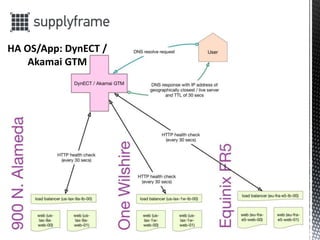
- 14. ?DynECT / Akamai GTM probing services for server/services failures / DC failover ?Pacemaker / Corosync cluster ?Load balancing services using haproxy (http/TCP load balancer) ? uninterrupted services during deploy ? high performance in web content delivery (number of web nodes scales number of requests almost linear) ? eliminating SPOF
- 18. ? Human error - no HA arch can predict that ? HA people: Follow the Sun ? Everyone has to know something about everything and everything about something (network, systems, application, automation, programming ...)