Svm light at E-commerce Website
?Download as PPT, PDF?
0 likes?625 views

Svm is a widely used for Text Categorization on many B2B website .The author of this ppt is an architect on http://www.mfrbee.com
![WhatˇŻs svm
? In machine learning, support vector machines
(SVMs, also support vector networks[1]
) are
supervised learning models with associated
learning algorithms that analyze data and
recognize patterns, used for classification and
regression analysis . ItˇŻs widely used at many
International Trade Site for product classification
.
? The author of this ppt. work for taobao.com and
mfrbee.com about 10 years](https://image.slidesharecdn.com/svmlight-140609083634-phpapp01/85/Svm-light-at-E-commerce-Website-1-320.jpg)

![Training Step
? svm-learn [-option] train_file model_file
?train_file contains training data;
?The filename of train_file can be any filename;
?The extension of train_file can be defined by user arbitrarily;
?model_file contains the model built based on training data by SVM;](https://image.slidesharecdn.com/svmlight-140609083634-phpapp01/85/Svm-light-at-E-commerce-Website-3-320.jpg)






Svm light at E-commerce Website
- 1. WhatˇŻs svm ? In machine learning, support vector machines (SVMs, also support vector networks[1] ) are supervised learning models with associated learning algorithms that analyze data and recognize patterns, used for classification and regression analysis . ItˇŻs widely used at many International Trade Site for product classification . ? The author of this ppt. work for taobao.com and mfrbee.com about 10 years
- 2. SVMLight ? SVMLight is an implementation of Support Vector Machine (SVM) in C. ? Download source from : http://svmlight.joachims.org/ Detailed description about: ?What are the features of SVMLight? ?How to install it? ?How to use it? ?ˇ
- 3. Training Step ? svm-learn [-option] train_file model_file ?train_file contains training data; ?The filename of train_file can be any filename; ?The extension of train_file can be defined by user arbitrarily; ?model_file contains the model built based on training data by SVM;
- 4. Format of input file (training data) ? For text classification, training data is a collection of documents; ? Each line represents a document; ? Each feature represents a term (word) in the document; ¨C The label and each of the feature: value pairs are separated by a space character ¨C Feature: value pairs MUST be ordered by increasing feature number ? Feature value : e.g., tf-idf;
- 5. Testing Step ? svm-classify test_file model_file predictions ?The format of test_file is exactly the same as train_file; ?Needs to be scaled into same range; ?We use the model built based on training data to classify test data, and compare the predictions with the original label of each test document;
- 6. Which means the first document is classified correctly but the second one is incorrectly. Example ? In test_file, we have: 1 101:0.2 205:4 209:0.2 304:0.2ˇ -1 202:0.1 203:0.1 208:0.1 209:0.3ˇ ˇ ˇ After running the svm_classify, the Predictions may be: 1.045 -0.987 ˇ ˇ Which means this classifier classify these two documents Correctly. 1.045 0.987 ˇ ˇ or
- 7. Confusion Matrix ?a is the number of correct predictions that an instance is negative; ?b is the number of incorrect predictions that an instance is positive; ?c is the number of incorrect predictions that an instance if negative; ?d is the number of correct predictions that an instance is positive; Predicted negative positive Actual negative a b positive c d
- 8. Evaluations of Performance ? Accuracy (AC) is the proportion of the total number of predictions that were correct. AC = (a + d) / (a + b + c + d) ? Recall is the proportion of positive cases that were correctly identified. R = d / (c + d) ? Precision is the proportion of the predicted positive cases that were correct. P = d / (b + d) ? Actual positive cases number predicted positive cases number
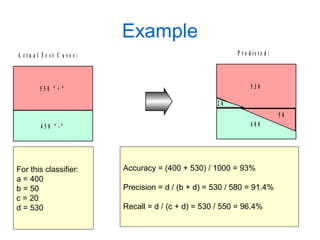
- 9. Example 4 5 0 " - " 5 5 0 " + " A c t u a l T e s t C a s e s : 4 0 0 5 3 0 P r e d i c t e d : 5 0 2 0 For this classifier: a = 400 b = 50 c = 20 d = 530 Accuracy = (400 + 530) / 1000 = 93% Precision = d / (b + d) = 530 / 580 = 91.4% Recall = d / (c + d) = 530 / 550 = 96.4%
- 10. Example 4 5 0 " - " 5 5 0 " + " A c t u a l T e s t C a s e s : 4 0 0 5 3 0 P r e d i c t e d : 5 0 2 0 For this classifier: a = 400 b = 50 c = 20 d = 530 Accuracy = (400 + 530) / 1000 = 93% Precision = d / (b + d) = 530 / 580 = 91.4% Recall = d / (c + d) = 530 / 550 = 96.4%