Switch transformers paper review
?
0 likes?597 views

2021? ?? ????? ??? ??? ?? ?????. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity https://arxiv.org/abs/2101.03961
















Switch transformers paper review
- 1. Switch Transformer SCALING TO TRILLION PARAMETER MODELS WITH SIMPLE AND EFFICIENT SPARSITY M B T 2021.02 Review by Seong Hoon Jung hoondori@gmail.com
- 2. ?? ???? ? Motivation ? Parameter ?? ??? ??? ????? ???ĪŁ ? ? ??? ??ĪŁ ??? ?? 13 Billion(T5-XXL) ?? ? ??? ??? Computation Budget ? ??? ??! ? ??? ?? ? ??? dimension?? Mixture of Expert(MoE)? ????. ? Expert ???? parameter? ???? ????. ? ????? Single Expert? ???? FLOP? ???? ???. ? ???? ? (+) 10x param up, ? ?? sample efficiency, ? ?? ??, FLOP? ?? ? (-) ?? ??/???? memory ? ?? ?? T5 : Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- 3. Motivation ? ?? ?? ??? ??? ??? ??? ? ?? ??, ???? ??, ?? ?? ??(Budget) Scaling Laws for Neural Language Models (Kaplan, 2020) increase the parameter count while keeping the floating point operations (FLOPs) per example constant. We achieve this by designing a sparsely activated model that efficiently uses hardware designed for dense matrix multiplications such as GPUs and TPUs.
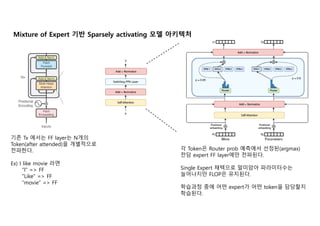
- 4. ?? Tx ??? FF layer? N?? Token(after attended)? ????? ????. Ex) I like movie ?? Ī░IĪ▒ => FF Ī░LikeĪ▒ => FF Ī░movieĪ▒ => FF ? Token? Router prob ???? ???(argmax) ?? expert FF layer?? ????. Single Expert ???? ???? ?????? ????? FLOP? ????. ???? ?? ?? expert? ?? token? ???? ????. Mixture of Expert ?? Sparsely activating ?? ????
- 5. Mixture of Expert Routing The sparsely-gated mixture-of-experts layer, Shazeer, 2017 Shazeer? ??? token?? topK=2 ? expert ?? ? expert layer ??? output?? ????? representation ??? ??? topK=1 (Single Expert)? ?????. - For same FLOP - For reducing communication cost (device to device) - For better performance
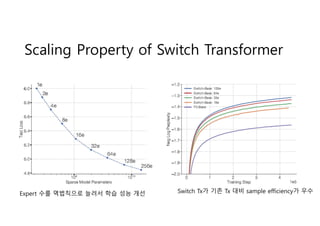
- 6. Scaling Property of Switch Transformer Expert ?? ????? ??? ?? ?? ?? Switch Tx? ?? Tx ?? sample efficiency? ??
- 7. Data / Model / Expert Parallism W W L1 L2 L3 Agg for gradient D D D DĪ» L1 L2 L3 L4 E1 E2 ?? Expert? ??? ?? Data ????? ??/???? ??. => ?? Hadoop ??? ?? expert? ??? machine? fit? ?? ??? Shardding ? ?
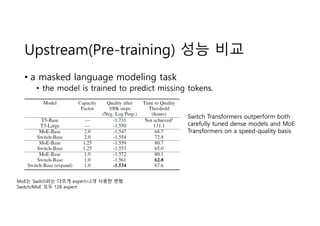
- 8. Upstream(Pre-training) ?? ?? ? a masked language modeling task ? the model is trained to predict missing tokens. MoE? Switch?? ??? expert=2? ??? ?? Switch/MoE ?? 128 expert Switch Transformers outperform both carefully tuned dense models and MoE Transformers on a speed-quality basis
- 9. Multilingual pre-training ?? ?? mT5-base
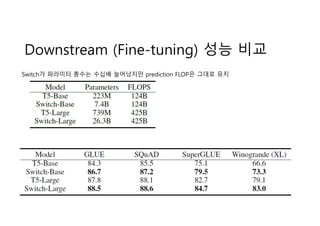
- 10. Downstream (Fine-tuning) ?? ?? Switch? ???? ??? ??? ????? prediction FLOP? ??? ??
- 11. Toward Trillion Parameter Model Switch-XXL - T5-XXL FLOP? ?? ??? ??? ?? - Num head, num layer ? ??? single machine fitting? ???? Expert/Model Parallel - ?? ?? communication cost? ??. Switch-C ? Trillion - Expert Parallel Only ? ???? ? ( num head? num layer? ?? single machine fitting ??) - ?? expert ?? ?? ?? ?? ? ?? (64 => 2048) - ?? dimension?? ??? FLOP? 1/10 ? ??
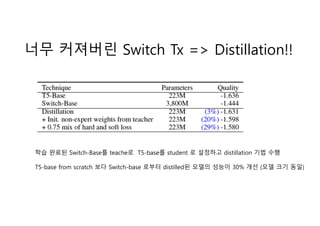
- 12. ?? ???? Switch Tx => Distillation!! ?? ??? Switch-Base? teache? T5-base? student ? ???? distillation ?? ?? T5-base from scratch ?? Switch-base ??? distilled? ??? ??? 30% ?? (?? ?? ??)
- 13. ?? ???? Expert ?? ?? ?? ?? ?? heuristic (???) ???? ???? ??
- 14. Expert Routing Balancing ? ?? ????? ?(work)? ??? ??? ????. Expert3? ??? ??(capacity=2) ?? ?? Batch? ?? Expert1? ??? ??(capacity=2) ?? ? Batch? ?? (??? ??? ??? ?? ?? => overflow) Overflow? ???? ??? globally?? capacity factor? ?? ? ??? ? ?? ??? ?? ????? expert?? ? ??? ? ??.
- 15. Expert Routing Balancing ? Balancing? ???? Loss? ??? ?? ?? ??? i?? token?? ?? ?? Ex) ?? ?? ? 100?? token? ?? ? ? ?? ??? i?? assig???? N?? ??? ?? ??? i?? assign? ??? ?? Ex) Ī«helloĪ»? 0.3, Ī«musicĪ»? 0.6? assig???? ? ?? ?=0.9 ? uniform routing distribution across experts? ???
- 16. ?? ??? ?? ?(?)?? ? Smaller parameter initialization for stability. ? ???? MoE? ???? ???? ?? ??? ??? ?? ??? ????(large ?? variance) ? ?? Tx?? ???? truncated normal random ??? variance?? 10? ?? ? ?? variance? ????? ????? ?? ??
- 17. ?? ??? ?? ?(?)?? ? Large Expert Dropout ? Dropout @Non-expert layer < Dropout @expert-layer ? Ex) 0.1 < 0.4
- 18. ?? ??? ?? ?(?)?? ? Selective precision with large sparse models. ? ?? ???? Float32 ?? ?? ? ??? ???. ??? ??? ? ?? ???? bFloat16 ?? ?? ? ??? ???. ??? ??? ? Expert Expert layer ???? bFloat16 cast to float32 ? ?? ? ???? bFloat16 ?? ?? ? (+) device ?? communication ?? ?? (compared to float32 ??) ? (+) expert layer? ?? ??? ??
- 19. ?? ???? ????? ? Switching self-attention ? Attention layer?? MoE ? ??????.
- 20. ?? ???? ????? ? No-Token-Left-Behind ? Expert capacity? ??? ??? ?? ???? token?? next layer ? skip (??? skip connection?) Expert 1?? assign???? overflow? ??? ???? Token? next stage?? second winning expert?? assign
- 21. ?? ???? ????? ? Exploration across experts ? ? 1? expert?? token? assign?? ?? ????? ? Exploit v.s Explore ???? ??? sub-optimal?? ?? ??