















Technical debt in machine learning - Data Natives Berlin 2018
- 1. Technical debt in ML by Jaroslaw Szymczak, Senior Data Scientist @ OLX Group
- 2. 2 Agenda ● Introduction ● Basic concepts ● Components of technical debt in machine learning... ● … and how can we tackle them ● Q&A
- 3. 3 Few words about OLX 350+ million active users 40+ countries 60+ million new listings per month Market leader in 35 countries
- 4. 4 â—Ź M. Sc. in computer science with speciality in machine learning â—Ź Senior Data Scientist @ OLX Group â—Ź Focusing on content quality as well as trust and safety topics â—Ź Responsible for full ML projects lifecycle - research, productization, development and maintenance â—Ź Having experience in delivering anti-fraud solutions for tier one European insurance companies as well as retail and investment banks â—Ź Worked on external data science projects for churn prediction, sales estimation and predictive maintenance for various companies in Germany and Poland And few words about me jaroslaw.szymczak@olx.com
- 5. Basic concepts What is technical debt? How this concept works with relation to ML?
- 6. 6 Technical debt Technical debt is a concept in software development that reflects the implied cost of additional rework caused by choosing an easy solution now instead of using a better approach that would take longer. (by Wikipedia) ● Main components increasing technical debt: ○ lack of testing ○ inadequate system monitoring ○ code complexity ○ “dependency jungle” ○ lack of documentation (especially painful in connection with high staff turnover) ● Main reasons of technical debt: ○ time pressure ○ using prototypes as base for production system ○ lack of technical debt awareness
- 7. 7 Technical debt in machine learning Technical debt in machine learning is a usual technical debt plus more. ML has unique capability of increasing the debt in extremely fast pace. Image source: https://c.pxhere.com/photos/29/fb/money_euro_coin_coins_bank_note_calculator_budget_save-1021960.jpg!d (labelled for reuse)
- 8. Components of technical debt in ML Or at least some of them
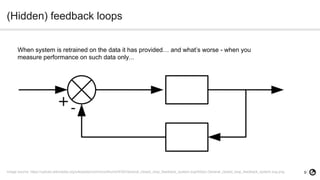
- 9. 9 (Hidden) feedback loops Image source: https://upload.wikimedia.org/wikipedia/commons/thumb/5/50/General_closed_loop_feedback_system.svg/400px-General_closed_loop_feedback_system.svg.png When system is retrained on the data it has provided… and what’s worse - when you measure performance on such data only...
- 10. 10 Breaking the loop Sampling Model retraining Testing & monitoring There’s an area for footnotes too! ● should be seen as a necessity, not as optional feature ● make sure to make it unbiased ● or take bias into account ● cannot be used everywhere, but A/B tests can ● very often majority of training data will come from feedback loop ● try to account for this, e.g. with weighting ● establish process for frequent retraining ● think of it as part of your MVP product ● as without it you’re just guessing that things work ● use real distributions for offline testing ● and ensure it is aligned with what you see live
- 11. 11 Undeclared consumers Image source:https://www.flickr.com/photos/texese/106442115 (labeled for reuse) When your system is so great, that everyone wants to use it, not necessarily letting you know about it… And then you improve it - are they happy?
- 12. 12 OLX way of handling the data Catalog Data lake Amazon S3 AWS GlueAmazon EMR Reservoir Reservoir Reservoir Reservoir Reservoir Reservoir
- 13. 13 Data dependencies Image source:https://de.wikipedia.org/wiki/Datei:Data.jpg ML model = algorithm + data What happens when Google changes ranking algorithm? What will happen to our models when the incoming data changes? Do we really need all these features?
- 14. 14 Robust feature encoding example Before (on raw data): â—Ź one hot encoded on id â—Ź no encoded hierarchy â—Ź extremely sensitive to any changes After (on enhanced data): â—Ź encoding the hierarchy â—Ź using names to have meaningful features â—Ź still data dependent (as ML will always be) â—Ź should survive our challenges though Challenges - what will happen: â—Ź when we split large category into more sub-categories? â—Ź when merge subcategories? â—Ź when we do some other changes in hierarchy?
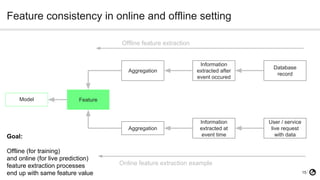
- 15. 15 Feature consistency in online and offline setting Model Feature Aggregation Information extracted after event occured Database record Aggregation Information extracted at event time User / service live request with data Offline feature extraction Online feature extraction example Goal: Offline (for training) and online (for live prediction) feature extraction processes end up with same feature value
- 16. 16 Decision cascades Image source: https://www.maxpixel.net/Cascade-By-The-Sautadet-Cascade-Gard-567383 (labeled for reuse) Rules are everywhere... And sometimes it really makes sense to use them (or another model) in combination with your model But then why this automatic decision was made? Which part of system is responsible for it? Oh, we have very bad automatic decisions affecting our clients - how can we fix it?
- 17. 17 Zoo of rules - how do we manage it? Image source: https://c1.staticflickr.com/9/8044/8445978554_1d1716447b_b.jpg (marked for reuse) â—Ź define a clear decision logic in single component of your system â—Ź make it very transparent, allow for partial decisions and incomplete input decisions (because you will need it) â—Ź audit every partial decision on every version of your input â—Ź do not use thresholding inside the rules, make your component responsible for that â—Ź be careful with machine learning models that can have a different output distribution after model updates â—Ź same for rules, be aware what concept they represent â—Ź allow running simulations of how system would behave with various settings, including past and potential future simulations
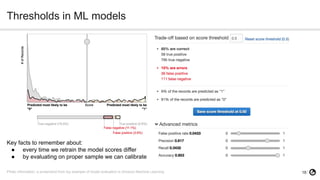
- 18. 18 Thresholds in ML models Photo information: a screenshot from toy example of model evaluation in Amazon Machine Learning Key facts to remember about: â—Ź every time we retrain the model scores differ â—Ź by evaluating on proper sample we can calibrate
- 19. 19 Easier. Safer. Faster. Jaroslaw Szymczak Senior Data Scientist OLX Group Berlin jaroslaw.szymczak@olx.com www.joinolx.com Terminology taken from: Hidden Technical Debt in Machine Learning Systems, D. Sculley et al., NIPS 2015 while most of examples come from professional experience