


























ŪÖźžĄúŪĒĆŽ°úžöį 2.0 ŪäúŪ܆Ž¶¨žĖľ - CNN
- 2. Ž™©žį® ‚ÄĘ CNN žÜĆÍįú ‚ÄĘ Tensorflow 2.0 - CNN ‚ÄĘ Tensorflow 2.0 Sample code - CNN
- 3. CNN žÜĆÍįú
- 4. CNN ‚ÄĘ State of The Art ‚Äď ImageNet ‚ÄĘ 1,400 ŽßĆ žě•žĚė žĚīŽĮłžßÄŽ•ľ žė¨ŽįĒŽ•ł žĻīŪÖĆÍ≥†Ž¶¨Ž°ú Ž∂ĄŽ•ėŪēėŽäĒ ŽĆÄŪöĆ ‚ÄĘ 2015 ŽÖĄžóź ResNet žĚī žĚłÍįĄžĚė ŪćľŪŹ¨Ž®ľžä§Ž•ľ ŽõįžĖīŽĄėžĚĆ ‚ÄĘ 2017 ŽÖĄ žĚīŪõĄŽ°ú ŽćĒ žĚīžÉĀ ŽĆÄŪöĆÍįÄ žóīŽ¶¨žßÄ žēäžĚĆ http://blog.a-stack.com/2018/07/06/ImageNet-DataSet/ https://alexisbcook.github.io/2017/using-transfer-learning-to-classify-images-with-keras/ žóźŽü¨žú® (%)
- 5. CNN ‚ÄĘ Convolutional Neural Network https://terms.naver.com/entry.nhn?docId=864931&cid=42346&categoryId=42346
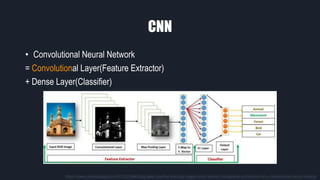
- 6. CNN ‚ÄĘ Convolutional Neural Network = Convolutional Layer(Feature Extractor) + Dense Layer(Classifier) https://www.completegate.com/2017022864/blog/deep-machine-learning-images-lenet-alexnet-cnn/general-architecture-of-a-convolutional-neural-network
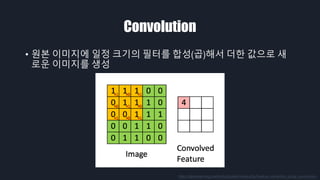
- 7. Convolution ‚ÄĘ žõźŽ≥ł žĚīŽĮłžßÄžóź žĚľž†ē ŪĀ¨ÍłįžĚė ŪēĄŪĄįŽ•ľ Ūē©žĄĪ(Í≥Ī)ŪēīžĄú ŽćĒŪēú ÍįížúľŽ°ú žÉą Ž°úžöī žĚīŽĮłžßÄŽ•ľ žÉĚžĄĪ http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
- 8. Convolution ‚ÄĘ ÍįĄŽč®Ūēú Convolution ŪēĄŪĄįžôÄ Í≤įÍ≥ľ žĚīŽĮłžßÄ https://en.wikipedia.org/wiki/Kernel_(image_processing) žąėžßĀžĄ† Í≤Äž∂ú žąėŪŹČžĄ† Í≤Äž∂ú Box blur Sharpen
- 9. ž†ĄŪÜĶž†Ā Convolution ‚ÄĘ Í≤įÍ≥ľ žĚīŽĮłžßĞ󟞥ú Feature Ž•ľ žĖĽžĚĄ žąė žěąžĚĆ ‚ÄĘ Žč§žĖĎŪēú Ž¨łž†ú ‚Äď object detection, object recognition, denoising ‚Äď Ž•ľ ŪíÄ žąė žěąžĚĆ https://kr.mathworks.com/help/vision/ug/local-feature-detection-and-extraction.html https://www.researchgate.net/figure/Sobel-operator-applied-to-the-image-Fig-22-Prewitt-operator-applied-to-image_fig15_221581664 BRISK - blob FAST - corner Sobel Filter - edge
- 10. Convolution ‚ÄĘ ŪēúÍ≥Ąž†ź : Feature žĚė žā¨ž†Ą ž†ēžĚė ŪēĄžöĒ ‚ÄĘ ž†ĄŽ¨łž†Ā žßÄžčĚ ŪēĄžöĒ ‚ÄĘ žąėŪĖČžóź žčúÍįĄžĚī žė§Žěė ÍĪłŽ¶ľ ‚ÄĘ Žč§Ž•ł ŽŹĄŽ©ĒžĚłžóź žĚľŽįėŪôĒŪēėÍłį ŪěėŽď¶ /zukun/eccv2010-feature-learning-for-image-classification-part-0
- 11. CNN ‚ÄĘ Feature Extraction ‚ÄĘ ŪēôžäĶ Í≥ľž†ēžóźžĄú ŽĄ§ŪäłžõĆŪĀ¨ÍįÄ Feature Ž•ľ žěźŽŹô žÉĚžĄĪ https://opensource.googleblog.com/2018/03/the-building-blocks-of-interpretability.html
- 12. Feature Extraction ‚ÄĘ Low-level : Ž™®žĄúŽ¶¨, Ž©ī ‚ÄĘ Mid-level : ŽįĒŪÄī, ŪĀį Ž∂ÄŪíą ‚ÄĘ High-level : Ūó§ŽďúŽĚľžĚīŪäł Žě®ŪĒĄ, žěĎžĚÄ Ž∂ÄŪíą https://technodocbox.com/3D_Graphics/72864833-Deep-learning-in-radiology-recent-advances-challenges-and-future-trends.html
- 15. žĚľŽįėž†ĀžĚł CNN žĚė ÍĶ¨ž°į ‚ÄĘ Conv žôÄ Pool žĚī ÍĶźžį®ŽźėŽ©į ŽįįžĻėŽź® ‚ÄĘ žė§Ž≤ĄŪĒľŪĆ̥֞ ŽßČÍłį žúĄŪēī Dense Ží§žóź Dropout žā¨žö© Conv Layer Pool Layer Conv Layer Pool Layer Flat Layer Dense Layer Dropout Layer Dense Layer Cat : 0.99 Dog : 0.1 Input Output Feature Extractor Classifier
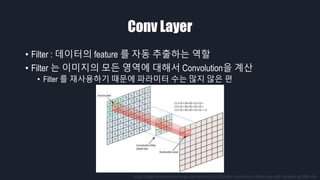
- 16. Conv Layer ‚ÄĘ Filter : ŽćįžĚīŪĄįžĚė feature Ž•ľ žěźŽŹô ž∂Ēž∂úŪēėŽäĒ žó≠Ūē† ‚ÄĘ Filter ŽäĒ žĚīŽĮłžßÄžĚė Ž™®Žď† žėĀžó≠žóź ŽĆÄŪēīžĄú ConvolutionžĚĄ Í≥Ąžāį ‚ÄĘ Filter Ž•ľ žě¨žā¨žö©ŪēėÍłį ŽēĆŽ¨łžóź ŪĆĆŽĚľŽĮłŪĄį žąėŽäĒ ŽßéžßÄ žēäžĚÄ Ūéł https://datascience.stackexchange.com/questions/23183/why-convolutions-always-use-odd-numbers-as-filter-size
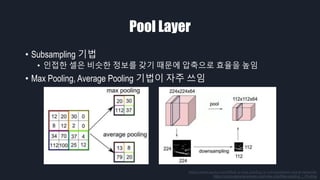
- 17. Pool Layer ‚ÄĘ Subsampling ÍłįŽ≤ē ‚ÄĘ žĚłž†ĎŪēú žÖÄžĚÄ ŽĻĄžä∑Ūēú ž†ēŽ≥īŽ•ľ ÍįĖÍłį ŽēĆŽ¨łžóź žēēž∂ēžúľŽ°ú Ūö®žú®žĚĄ ŽÜížěĄ ‚ÄĘ Max Pooling, Average Pooling ÍłįŽ≤ēžĚī žěźž£ľ žďįžěĄ https://www.quora.com/What-is-max-pooling-in-convolutional-neural-networks https://computersciencewiki.org/index.php/Max-pooling_/_Pooling
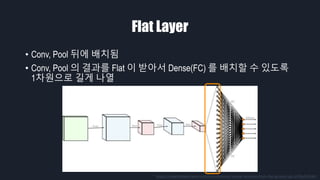
- 18. Flat Layer ‚ÄĘ Conv, Pool Ží§žóź ŽįįžĻėŽź® ‚ÄĘ Conv, Pool žĚė Í≤įÍ≥ľŽ•ľ Flat žĚī ŽįõžēĄžĄú Dense(FC) Ž•ľ ŽįįžĻėŪē† žąė žěąŽŹĄŽ°Ě 1žį®žõźžúľŽ°ú ÍłłÍ≤Ć Žāėžóī https://towardsdatascience.com/convolutional-neural-networks-from-the-ground-up-c67bb41454e1
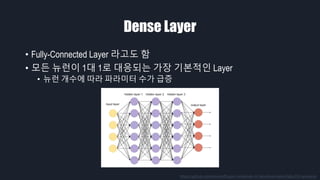
- 19. Dense Layer ‚ÄĘ Fully-Connected Layer ŽĚľÍ≥†ŽŹĄ Ūē® ‚ÄĘ Ž™®Žď† ŽČīŽüįžĚī 1ŽĆÄ 1Ž°ú ŽĆÄžĚĎŽźėŽäĒ ÍįÄžě• ÍłįŽ≥łž†ĀžĚł Layer ‚ÄĘ ŽČīŽüį Íįúžąėžóź ŽĒįŽĚľ ŪĆĆŽĚľŽĮłŪĄį žąėÍįÄ ÍłČž¶Ě https://github.com/drewnoff/spark-notebook-ml-labs/tree/master/labs/DLFramework
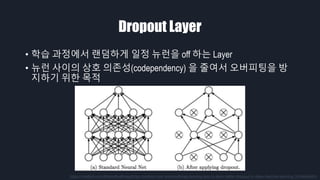
- 20. Dropout Layer ‚ÄĘ ŪēôžäĶ Í≥ľž†ēžóźžĄú ŽěúŽć§ŪēėÍ≤Ć žĚľž†ē ŽČīŽüįžĚĄ off ŪēėŽäĒ Layer ‚ÄĘ ŽČīŽüį žā¨žĚīžĚė žÉĀŪėł žĚėž°īžĄĪ(codependency) žĚĄ ž§Ąžó¨žĄú žė§Ž≤ĄŪĒľŪĆ̥֞ Žį© žßÄŪēėÍłį žúĄŪēú Ž™©ž†Ā https://medium.com/@amarbudhiraja/https-medium-com-amarbudhiraja-learning-less-to-learn-better-dropout-in-deep-machine-learning-74334da4bfc5
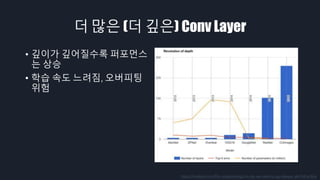
- 21. ŪćľŪŹ¨Ž®ľžä§Ž•ľ ŽÜížĚīÍłį žúĄŪēú ŽÖłŽ†• ‚ÄĘ ŽćĒ ŽßéžĚÄ (ŽćĒ ÍĻäžĚÄ) Conv Layer ‚ÄĘ Image Augmentation
- 22. ŽćĒ ŽßéžĚÄ (ŽćĒ ÍĻäžĚÄ) Conv Layer ‚ÄĘ ŽĒ•Žü¨Žč̞󟞥ú ŽĄ§ŪäłžõĆŪĀ¨ ÍĶ¨ž°įŽ•ľ ÍĻäÍ≤Ć žĆď ŽäĒ Í≤ÉžĚī ÍįÄŽä•ŪēīžßĄ žĚīŪõĄ, Conv Layer ÍįÄ ž§Ďž≤©Žźú ŽćĒ ÍĻäžĚÄ ÍĶ¨ž°įÍįÄ Í≥ĄžÜć ŽāėŪÉÄŽā® https://arxiv.org/abs/1709.01921
- 23. ŽćĒ ŽßéžĚÄ (ŽćĒ ÍĻäžĚÄ) Conv Layer ‚ÄĘ ÍĻäžĚīÍįÄ ÍĻäžĖīžßąžąėŽ°Ě ŪćľŪŹ¨Ž®ľžä§ ŽäĒ žÉĀžäĻ ‚ÄĘ ŪēôžäĶ žÜ掏Ą ŽäźŽ†§žßź, žė§Ž≤ĄŪĒľŪĆÖ žúĄŪóė https://medium.com/finc-engineering/cnn-do-we-need-to-go-deeper-afe1041e263e
- 24. Image Augmentation ‚ÄĘ Train data žĚė ŪéłŪĖ•žĚĄ Ž≥īžôĄŪēėÍłį žúĄŪēú ÍłįŽ≤ē ‚ÄĘ žĚīŽĮłžßÄ ÍłįžöłžĚīÍłį, flip, zoom in/out, crop ŽďĪžúľŽ°ú train data žąėŽ•ľ ŽäėŽ†§ ŽĄ§ ŪäłžõĆŪĀ¨žĚė ŽĆÄžĚĎžĄĪžĚĄ ŽÜížěĄ ‚ÄĘ ŪēôžäĶ žÜ掏Ą ŽäźŽ†§žßź https://becominghuman.ai/data-augmentation-using-fastai-aefa88ca03f1
- 25. Tensorflow 2.0 - CNN
- 26. Conv2D ‚ÄĘ žĽ¨Žü¨ žĪĄŽĄźžĚī žěąŽäĒ 2D žĚīŽĮłžßÄ(3D ŽćįžĚīŪĄį)Ž•ľ input žúľŽ°ú ŽįõžĚĆ ‚ÄĘ ŽÜížĚī x ŽĄąŽĻĄ x žĽ¨Žü¨ žĪĄŽĄź ‚ÄĘ Output ŽŹĄ 3D ŽćįžĚīŪĄįÍįÄ Žź® ‚ÄĘ ŽÜížĚī x ŽĄąŽĻĄ x ŪēĄŪĄį Íįúžąė https://medium.com/@udemeudofia01/basic-overview-of-convolutional-neural-network-cnn-4fcc7dbb4f17
- 27. Conv2D ‚ÄĘ tf.keras.layers žóźžĄú import Ūē† žąė žěąžĚĆ
- 28. kernel_size ‚ÄĘ Filter ÍįÄ Ūēú step ŽßąŽč§ Í≥ĄžāįŪēėŽäĒ žėĀžó≠žĚė ŪĀ¨Íłį ‚ÄĘ Receptive field ŽĚľÍ≥†ŽŹĄ Ūē® https://github.com/vdumoulin/conv_arithmetic kernel_size = (3, 3) kernel_size = (4, 4)
- 29. strides ‚ÄĘ Filter ÍįÄ Ūēú step ŽßąŽč§ žĚīŽŹôŪēėŽäĒ ŪĀ¨Íłį ‚ÄĘ Strides ÍįÄ žĽ§žßÄŽ©ī ž∂úŽ†• žĚīŽĮłžßÄÍįÄ žěĎžēĄžßź strides = (1, 1) strides = (2, 2) https://github.com/vdumoulin/conv_arithmetic
- 30. padding ‚ÄĘ valid : filter window ÍįÄ input žēąžóźŽßĆ žúĄžĻėŪēėŽŹĄŽ°Ě Ūē® ‚ÄĘ same : output žĚė size ÍįÄ input Í≥ľ ÍįôžēĄžßÄŽŹĄŽ°Ě Ūē® ‚ÄĘ zero padding : Žā®ŽäĒ Í≥ĶÍįĄžĚĄ 0 žúľŽ°ú žĪĄžõĆžĄú Í≥Ąžāį https://github.com/vdumoulin/conv_arithmetic padding = ‚Äėvalid‚Äô padding = ‚Äėsame‚Äô
- 31. filters ‚ÄĘ Conv Layer Ž•ľ ÍĶ¨žĄĪŪēėŽäĒ filter žĚė žąė ‚ÄĘ Filter žĚė žąėŽäĒ ŽĄ§ŪäłžõĆŪĀ¨ÍįÄ žĖľŽßąŽāė ŽßéžĚÄ feature Ž•ľ ž∂Ēž∂úŪē† žąė žěąŽäĒžßÄ Ž•ľ Í≤įž†ē
- 33. Tensorflow 2.0 sample code - CNN
- 34. Hello World ‚Äď MNIST ‚ÄĘ 0~9Ž°ú ŽĚľŽ≤®ŽßĀŽźú 28x28 pixelžĚė žÜźÍłÄžĒ® žĚīŽĮłžßÄ 70,000žě•žĚĄ Ž∂ĄŽ•ė ‚ÄĘ 1998ŽÖĄŽ∂ÄŪĄį Ž®łžč†Žü¨ŽčĚžĚė benchmark ž§Ď ŪēėŽāėŽ°ú Ūôúžö©Žź® https://theanets.readthedocs.io/en/stable/examples/mnist-classifier.html
- 35. Hello World ‚Äď MNIST ‚ÄĘ Performance : Error rate ‚ÄĘ CNN žĚī ÍįÄžě• žĘčžĚÄ ŪćľŪŹ¨Ž®ľžä§Ž•ľ Ž≥īžěĄ https://en.wikipedia.org/wiki/MNIST_database
- 36. Hello World ‚Äď MNIST ‚ÄĘ Tensorflow ŪôąŪéėžĚīžßÄžĚė <Get started with TensorFlow 2.0 for beginners> Ž•ľ ÍłįŽįėžúľŽ°ú žąėž†ē
- 37. CNN with MNIST Dataset ‚ÄĘ Google Colab žĹĒŽďú ŽßĀŪĀ¨
- 38. Thank you!
Editor's Notes
- žēąŽÖēŪēėžĄłžöĒ. ž†ÄŽäĒ žė§Žäė Tensorflow 2.0 Tutorial, CNN žĚīŽĚľŽäĒ ž£ľž†úŽ°ú ŽįúŪĎúŽ•ľ Žß°žĚÄ žóĒžĒ®žÜĆŪĒĄŪäłžĚė ÍĻÄŪôėŲ̄ŽĚľÍ≥† Ūē©ŽčąŽč§.
- Ž™©žį®ŽäĒ Žč§žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. Ž®ľž†Ä CNN žóź ŽĆÄŪēī žēĄžčúŽäĒ Ž∂ĄŽŹĄ ŽßéÍ≤†žßÄŽßĆ Ž≥ĶžäĶ žį®žõźžóźžĄú ž§ĎžöĒŪēú ž†źŽď§žĚĄ ÍįôžĚī žāīŪéīŽ≥īÍ≥†, Tensorflow 2.0 žóźžĄú CNN žĚĄ žā¨žö©ŪēėŽäĒ ÍįĄŽč®Ūēú Žį©Ž≤ēžĚĄ žēĄž£ľ žßßÍ≤Ć žāīŪéīŽ≥ł Žč§žĚĆžóź, Google Colab žúľŽ°ú ž§ÄŽĻĄŪēú žÉėŪĒĆ žĹĒŽďúžôÄ Ūē®ÍĽė MNIST ŽćįžĚīŪĄį žÖčžĚĄ classification ŪēėŽäĒ žėąž†úŽ•ľ Žč§žĖĎŪēėÍ≤Ć žāīŪéīŽ≥īŽŹĄŽ°Ě ŪēėÍ≤†žäĶŽčąŽč§.
- Ž®ľž†Ä CNN žÜĆÍįúžě֎蹎č§.
- CNN žĚÄ ŪėĄžě¨ ŽĒ•Žü¨ŽčĚžĚī ÍįÄžě• žěėŪēėÍ≥† žěąŽäĒ Ž∂Ąžēľ ž§Ď ŪēėŽāėžě֎蹎č§. CNN žĚė Žįúž†ĄžĚĄ žĚīŽĀą Í≥ĄÍłį ž§Ď ŪēėŽāėŽ°ú 1400 ŽßĆ žě•žĚė žĚīŽĮłžßÄŽ•ľ žė¨ŽįĒŽ•ł žĻīŪÖĆÍ≥†Ž¶¨Ž°ú Ž∂ĄŽ•ėŪēėŽäĒ ImageNet ŽĆÄŪöĆÍįÄ žěąžäĶŽčąŽč§. žĚī ŽĆÄŪöƞ󟞥ú 2012 ŽÖĄ AlexNet, 2014 ŽÖĄ GoogLeNet, 2015 ŽÖĄ ResNet ŽďĪ CNNžĚė ŽßéžĚÄ ŪėĀžč†žĚī žěąžóąžäĶŽčąŽč§. 2015 ŽÖĄžóź žĚłÍįĄŽ≥īŽč§ žĘčžĚÄ ŪćľŪŹ¨Ž®ľžä§Ž•ľ Ž≥īžėÄÍ≥†, 2017 ŽÖĄ žĚīŪõĄŽ°úŽäĒ žĚī Ž¨łž†úŽ•ľ ŪĎłŽäĒ Žćįžóź žĖīŽäź ž†ēŽŹĄ ŪēúÍ≥Ąžóź ŽŹĄŽč¨ŪĖąŽč§Í≥† ŪĆźŽč®ŪĖąŽäĒžßÄ ŽĆÄŪöĆÍįÄ ŽćĒ žĚīžÉĀ žóīŽ¶¨žßÄ žēäÍ≥† žěąžäĶŽčąŽč§.
- CNN žĚÄ Convolutional Neural Network žĚė ž§ÄŽßźžě֎蹎č§. ŽĄ§žĚīŽ≤ĄžĚė IT žö©žĖī žā¨ž†ĄžóźŽäĒ ÍįĀÍįĀžĚė ŪĒĹžÖĞ̥ Ž≥łŽěė ŪĒĹžÖÄÍ≥ľ Í∑ł ž£ľŽ≥Ä ŪĒĹžÖÄžĚė ž°įŪē©žúľŽ°ú ŽĆÄž≤īŪēėŽäĒ ŽŹôžěĎžĚīŽĚľÍ≥† ŽāėžôÄ žěąžäĶŽčąŽč§.
- ÍįĄŽč®Ūěą žÉĚÍįĀŪēėŽ©ī ŪŹ¨Ū܆žÉĶžĚė ŪēĄŪĄį ÍįôžĚÄ Í≤ÉžĚīŽĚľÍ≥† Ūē† žąė žěąžäĶŽčąŽč§. Í∑łŽ¶ľžĚė Convolutional Layer Ž•ľ Ž≥īžčúŽ©ī Íłįž°ī žĚīŽĮłžßÄÍįÄ Žč§Ž•ł žÉČÍ≥ľ Ž™ÖŽŹĄŽ°ú Ž≥ÄŪôėŽźú Í≤ɞ̥ Ž≥īžč§ žąė žěąžäĶŽčąŽč§. Convolutional Neural Network ŽäĒ ŪĀ¨Í≤Ć Convolutional Layer žôÄ Dense Layer Ž°ú ÍĶ¨Ž∂ĄŪē† žąė žěąŽäĒŽćį, žĚī ŽĎėžĚÄ ÍįĀÍįĀ Feature Extractor žôÄ Classifier žĚė žó≠Ūē†žĚĄ Ūē©ŽčąŽč§. Classifier ŽäĒ Žßź Í∑łŽĆÄŽ°ú žĖīŽĖ§ ž†ēŽ≥īŽ•ľ ŪäĻž†ē žĻīŪÖĆÍ≥†Ž¶¨Ž°ú Ž∂ĄŽ•ėŪēėŽäĒ žó≠Ūē†žĚĄ Ūē©ŽčąŽč§. žā¨žßĄžĚĄ Ž≥īÍ≥† žĚīÍ≤ÉžĚī ŽŹôŽ¨ľžĚłžßÄ ÍĪīž∂ēŽ¨ľžĚłžßÄ Ž∂ĄŽ•ėŪēėŽäĒ Í≤Éžě֎蹎č§. Í∑łŽüľ Feature Extractor ŽäĒ Ž¨īžóážĚłžßÄžóź ŽĆÄŪēīžĄú žĘÄ ŽćĒ žěźžĄłŪěą žĄ§Ž™ÖŽďúŽ¶¨Í≤†žäĶŽčąŽč§.
- Ž®ľž†Ä Convolution žóįžāįžĚÄ žõźŽ≥ł žĚīŽĮłžßÄžóź žĚľž†ē ŪĀ¨ÍłįžĚė ŪēĄŪĄįŽ•ľ Ūē©žĄĪŪēīžĄú ŽćĒŪēú ÍįížúľŽ°ú žÉąŽ°úžöī žĚīŽĮłžßÄŽ•ľ žÉĚžĄĪŪēėŽäĒ Í≤Éžě֎蹎č§.
- žĚīŽĮłžßÄŽ°ú žėąžčúŽ•ľ Žď§žĖīŽ≥īŽ©ī ÍįÄžöīŽćįžóź žěąŽäĒ 4ÍįúžĚė ŪēĄŪĄįŽ•ľ žôľž™Ĺ žĚīŽĮłžßÄžóź žĒĆžöįŽ©ī žė§Ž•łž™ĹÍ≥ľ ÍįôžĚī Ž≥ÄŪôėžĚī Žź©ŽčąŽč§.
- žĚīŽ†áÍ≤Ć Ž≥ÄŪôėŽźú Í≤įÍ≥ľ žĚīŽĮłžßĞ󟞥ú Feature ŽĚľÍ≥† Ž∂ąŽ¶¨ŽäĒ Í≤ɞ̥ žĖĽžĚĄ žąė žěąžäĶŽčąŽč§. Feature ŽäĒ žĚīŽĮłžßÄžĚė žôłÍ≥ĹžĄ†žĚīŽāė žĹĒŽĄą ÍįôžĚÄ žĚīŽĮłžßÄžĚė ŪäĻžßēžĚĄ ŽßźŪē©ŽčąŽč§. žĚīŽüį ŪäĻžßēžĚĄ Í≤Äž∂úŪēėŽ©ī ž†ĄŪÜĶž†ĀžĚł vision žóįÍĶ¨žĚė ž£ľž†úžĚł žā¨Ž¨ľ ÍįźžßÄ, žā¨Ž¨ľ žĚłžčĚ, ŽÖłžĚīž¶ą ž†úÍĪį ŽďĪžĚė Ž¨łž†úŽ•ľ ŪíÄ žąė žěąžäĶŽčąŽč§.
- Í∑łŽ¶¨Í≥† žĚīŽĮłžßÄ ŽŅźŽßĆ žēĄŽčąŽĚľ žė§ŽĒĒžė§ ŽďĪ Žč§Ž•ł Ž∂ĄžēľžóźžĄúŽŹĄ feature Ž•ľ ž∂Ēž∂úŪēėŽäĒ Žč§žĖĎŪēú Žį©Ž≤ēžĚī ÍįúŽįúŽźėžĖī žôĒžäĶŽčąŽč§. ŪēėžßÄŽßĆ žĚī Žį©Ž≤ēŽď§žĚĄ ž†Āžö©ŪēėÍłį žúĄŪēīžĄúŽäĒ ž†ĄŽ¨łž†ĀžĚł žßÄžčĚžĚī ŪēĄžöĒŪēėÍ≥†, žąėŪĖČžóź žčúÍįĄžĚī žė§Žěė ÍĪłŽ¶¨Ž©į Žč§Ž•ł ŽŹĄŽ©ĒžĚłžóź žĚľŽįėŪôĒŪēėÍłį ŪěėŽď§Žč§ŽäĒ Žč®ž†źžĚī žěąžóąžäĶŽčąŽč§.
- Í∑łŽüįŽćį CNN žĚĄ ŽĻĄŽ°ĮŪēú žč†Í≤ĹŽßĚžĚÄ Feature Ž•ľ žěźŽŹôžúľŽ°ú ž∂Ēž∂úŪē©ŽčąŽč§. žĚī žĚīŽĮłžßÄŽäĒ ÍĶ¨ÍłÄŽĄ∑žóźžĄú ÍįĀ ŽČīŽüįžĚė ŪôúžĄĪŪôĒŽźú ž†ēŽŹĄŽ•ľ Ž≥īžó¨ž§ćŽčąŽč§. ŪēôžäĶ Í≥ľž†ēžĚī žßÄžÜ掟ėŽ©ī ÍįĀ ŽČīŽüįžĚÄ ŪäĻž†ē ŪĆ®ŪĄīžĚĄ žěė Í≤Äž∂úŪē† žąė žěąŽŹĄŽ°Ě ŽįĒŽÄĆÍ≤Ć Žź©ŽčąŽč§.
- Feature Extraction žĚÄ CNN žĚĄ ŪŹ¨Ūē®Ūēú žč†Í≤ĹŽßĚ ŽĄ§ŪäłžõĆŪĀ¨žĚė ŪäĻžßēžě֎蹎č§. CNN žĚÄ Ž≥īŪÜĶ žó¨Žü¨ žłĶžĚĄ žĆďžēĄžė¨Ž¶¨ŽäĒŽćį žĚīŽēĆ ÍįĀ žłĶŽ≥ĄŽ°ú ž∂Ēž∂úŽźėŽäĒ feature žĚė ŪäĻžßēžĚī Žč¨ŽĚľžßώ蹎č§. žĚīŽĮłžßÄžóź ÍįÄÍĻĆžöī low-level layer ŽäĒ žĚīŽĮłžßÄžĚė ŪĀį Ž∂ÄŽ∂ĄžĚĄ ž∂Ēž∂úŪēėŽäĒ Í≤ĹŪĖ•žĚī žěąÍ≥†, high-level layer ŽäĒ žĄłŽįÄŪēú Ž∂ÄŽ∂Ąžóź žßĎž§ĎŪēėŽäĒ Í≤ĹŪĖ•žĚī žěąžäĶŽčąŽč§.
- žĚī Í∑łŽ¶ľžóźžĄúŽäĒ ÍįĀ Ž†ąžĚīžĖīžôÄ Í∑ł Ž†ąžĚīžĖīžóź ÍįÄžě• žěė ŪôúžĄĪŪôĒŽźėŽäĒ žĚīŽĮłžßÄžĚė Ž∂ÄŽ∂ĄžĚĄ ŪĎúžčúŪēú Í≤Éžě֎蹎č§. Layer 1Í≥ľ Layer 2 žóźžĄúŽäĒ Ž™®žĄúŽ¶¨, žõźŪėē ÍįôžĚÄ žĚīŽĮłžßÄžĚė ž∂ĒžÉĀž†ĀžĚł ŪäĻžßēžĚĄ žě°žēĄŽÉ֎蹎č§.
- Layer 5 žóźžĄúŽäĒ žā¨ŽěĆžĚė žĖľÍĶī, ÍįúžôÄ Ž∂ÄžóČžĚīžĚė žĖľÍĶī, žěźž†ĄÍĪįžĚė ŽįĒŪÄī ŽďĪžĚĄ žě°žēĄŽÉ֎蹎č§. Layer 1 žóźžĄú Layer 5 Ž°ú ÍįąžąėŽ°Ě ž†źž†ź žā¨ŽěĆžĚī žēĆžēĄŽ≥īÍłį žČ¨žöī žĄłŽįÄŪēú Ž∂ÄŽ∂ĄžĚĄ žěė žě°žēĄŽāīŽäĒ Í≤ɞ̥ ŪôēžĚłŪē† žąė žěąžäĶŽčąŽč§.
- žĚľŽįėž†ĀžĚł CNN žĚė ÍĶ¨ž°įŽäĒ Convolution Layer žôÄ Pooling Layer ÍįÄ žīąŽįėžóź ŽįįžĻėŽźėžĖī Feature Extraction žĚĄ Ūēú Žč§žĚĆ, ŽßąžßÄŽßČ Žč®žĚė Dense Layer žóźžĄú žė¨ŽįĒŽ•ł ŽĚľŽ≤®žóź ŽĆÄŪēú Classification žĚĄ ŪēėŽäĒ ÍĶ¨ž°įžě֎蹎č§.
- Í∑łŽüľ ÍįĀ Ž†ąžĚīžĖīŽ•ľ ŪēėŽāėžĒ© žāīŪéīŽ≥īÍ≤†žäĶŽčąŽč§. Ž®ľž†Ä Convolution Layer, ž§Ąžó¨žĄú Conv Layer ŽäĒ Ž≥īŪÜĶ 2D žĚīŽĮłžßÄŽ•ľ ŽįõžēĄžĄú ž∂úŽ†• žĚīŽĮłžßÄŽ•ľ ŽįėŪôėŪēėŽäĒ žó≠Ūē†žĚĄ Ūē©ŽčąŽč§. Í∑ł Í≥ľž†ēžóźžĄú ŽćįžĚīŪĄįžĚė feature Ž•ľ žěźŽŹô ž∂Ēž∂úŪēėŽäĒŽćį, žĚī filter ŽäĒ žĚīŽĮłžßÄžĚė Ž™®Žď† žėĀžó≠žóź ŽĆÄŪēīžĄú convolution žĚĄ Í≥ĄžāįŪēėÍłį ŽēĆŽ¨łžóź ŪĆĆŽĚľŽĮłŪĄį žąėŽäĒ ŽßéžßÄ žēäžĚÄ Ūéłžě֎蹎č§.
- Pooling Layer ŽäĒ žĚīŽĮłžßÄžĚė ŪĀ¨ÍłįŽ•ľ ž§ĄžĚīŽ©īžĄú ž§ĎžöĒŪēú ž†ēŽ≥īŽßĆ Žā®ÍłįŽäĒ žó≠Ūē†žĚĄ Ūē©ŽčąŽč§. Max Pooling žĚÄ žā¨ÍįĀŪėēžĚė žėĀžó≠ ž§Ďžóź Max ÍįíŽßĆ Žā®ÍłįÍ≤Ć ŽźėÍ≥†, Average Pooling žĚÄ ŪŹČÍ∑†ÍįížĚĄ Žā®ÍłįÍ≤Ć Žź©ŽčąŽč§.
- Flat Layer ŽäĒ Conv Žāė Pool žĚė ž∂úŽ†•žĚĄ 1žį®žõźžúľŽ°ú ÍłłÍ≤Ć ŽāėžóīŪēīž£ľŽäĒ žó≠Ūē†žĚĄ Ūē©ŽčąŽč§. žěÖŽį©ž≤īŽ°ú ŪĎúžčúŽźú Í≤Éž≤ėŽüľ ŽćįžĚīŪĄįžĚė žį®žõźžĚī 3žį®žõźžĚīÍłį ŽēĆŽ¨łžóź žĚīÍ≤ɞ̥ 1žį®žõźžúľŽ°ú ŽįĒÍŅĒž§ćŽčąŽč§.
- Dense Layer ŽäĒ žĚľŽįėž†ĀžúľŽ°ú ÍįÄžě• ŽßéžĚī žďįžĚīŽäĒ ÍłįŽ≥łž†ĀžĚł Layer žě֎蹎č§. Ž™®Žď† ŽČīŽüįžóź 1ŽĆÄ 1Ž°ú ŽĆÄžĚĎŪēėÍłį ŽēĆŽ¨łžóź ŽČīŽüįžĚī ŽßéžēĄžßąžąėŽ°Ě ŪĆĆŽĚľŽĮłŪĄį žąėÍįÄ ÍłČž¶ĚŪē©ŽčąŽč§.
- Dropout Layer ŽäĒ ŪēôžäĶ Í≥ľž†ēžóźžĄú ŽěúŽć§ŪēėÍ≤Ć žĚľž†ē ŽČīŽüįžĚĄ off Ūēīž£ľŽäĒ žó≠Ūē†žĚĄ Ūē©ŽčąŽč§. Dense Layer ŽäĒ Ž™®Žď† ŽČīŽüįžĚī žĄúŽ°ú žóįÍ≤įŽźėžĖī žěąÍłį ŽēĆŽ¨łžóź ŽČīŽüį žā¨žĚīžóź žÉĀŪėł žĚėž°īžĄĪžĚī ŽÜížäĶŽčąŽč§. žÉĀŪėł žĚėž°īžĄĪžĚī ŽÜížúľŽ©ī žĄúŽ°úžĚė Íįížóź žėĀŪĖ•žĚī žĽ§žßÄÍłį ŽēĆŽ¨łžóź, žĄúŽ°ú ŽĻĄžä∑Ūēú Í≤įÍ≥ľÍįížĚĄ ÍįÄžßÄÍ≤Ć ŽźėžĖī žė§Ž≤ĄŪĒľŪĆÖžĚī ŽįúžÉĚŪē©ŽčąŽč§. žĚīŽ•ľ ŽßČÍłį žúĄŪēīžĄú ŪēôžäĶ Í≥ľž†ēžóźžĄúŽßĆ ŽěúŽć§ŪēėÍ≤Ć ŽČīŽüįžĚĄ Íļľž£ľÍ≥†, žč§ž†úŽ°ú Í≤įÍ≥ľŽ•ľ ŪÖĆžä§ŪäłŪē† ŽēĆžóźŽäĒ Ž™®Žď† ŽČīŽüįžĚĄ žľúž§ćŽčąŽč§.
- CNN žóźžĄú ŪćľŪŹ¨Ž®ľžä§Ž•ľ ŽÜížĚīÍłį žúĄŪēīžĄúŽäĒ žó¨Žü¨ ÍįÄžßÄ Žį©Ž≤ēžĚī žěąÍ≤†žäĶŽčąŽč§ŽßĆ, žė§ŽäėžĚÄ 2ÍįÄžßÄžóź žīąž†źžĚĄ Žßěž∂įŽ≥īŽ†§ Ūē©ŽčąŽč§.
- ž≤ęŽ≤ąžßłŽäĒ Convolution Layer Ž•ľ ŽćĒ ŽßéžĚī žĆďŽäĒ Í≤Éžě֎蹎č§. 1998 ŽÖĄžĚė LeNet žĚī 5Íįú Layer Ž•ľ žĆďžĚÄ žĚīŪõĄ, Layer žąėŽäĒ ž†źž†ź ŽßéžēĄž°ĆžäĶŽčąŽč§.
- Í∑łŽ¶¨Í≥† ÍĻäžĚīÍįÄ ÍĻäžĖīžßąžąėŽ°Ě ŪćľŪŹ¨Ž®ľžä§ŽäĒ žĘčžēĄž°ĆžäĶŽčąŽč§. žĚīž†úŽäĒ ŽěúŽć§Ūēú ŽĄ§ŪäłžõĆŪĀ¨ ÍĶ¨ž°į žÉĚžĄĪ ŽďĪ Žč§Ž•ł Žį©Ž≤ēŽď§ŽŹĄ ÍįúŽįúŽźėÍ≥† žěąžßÄŽßĆ, ŪėĄžě¨ÍĻĆžßÄ žĽ®Ž≥ľŽ£®žÖė Ž†ąžĚīžĖīŽ•ľ žĆďžĚĄžąėŽ°Ě žĄĪŽä•žĚī ž¶ĚÍįÄŪēúŽč§ŽäĒ ž†źžĚÄ Í≥ĄžÜć ž¶ĚŽ™ÖŽźėžĖī žôĒžäĶŽčąŽč§. ŪēėžßÄŽßĆ ŽĄąŽ¨ī ŽßéžĚÄ žĽ®Ž≥ľŽ£®žÖė Ž†ąžĚīžĖīŽ•ľ žā¨žö©ŪēėŽ©ī ŪēôžäĶ žÜ掏ĄÍįÄ ŽäźŽ†§žßą Í≤ÉžĚīÍ≥† žė§Ž≤Ą ŪĒľŪĆÖžĚī ŽįúžÉĚŪē† žúĄŪóėŽŹĄ žěąžäĶŽčąŽč§.
- Í∑łŽ¶¨Í≥† Train date žĚė ŪéłŪĖ•žĚĄ Ž≥īžôĄŪēėÍłį žúĄŪēīžĄú, ŽćįžĚīŪĄįžóź ŽěúŽć§Ūēú Ž≥ÄŪėēžĚĄ ÍįÄŪēėŽäĒ Žį©Ž≤ēžĚī žěąžäĶŽčąŽč§. žĚīŽĮłžßÄžóź žĚīŽüį Ž≥ÄŪėēžĚĄ ÍįÄŪēīžĄú žąęžěźŽ•ľ ŽäėŽ¶¨ŽäĒ Í≤ɞ̥ Image Augmentation žĚīŽĚľÍ≥† Ūē©ŽčąŽč§. žĚīŽ†áÍ≤Ć ŽźėŽ©ī Žč§žĖĎŪēú Train data Ž•ľ ŽßéžĚī ÍįÄžßÄÍ≥† žěąŽäĒ ŽďĮŪēú Ūö®Í≥ľŽ•ľ žĖĽžĚĄ žąė žěąžäĶŽčąŽč§. Žč§ŽßĆ žĚīŽ†áÍ≤Ć ŽźėŽ©ī ŽćįžĚīŪĄįžĚė žąė žěźž≤īÍįÄ ŽßéžēĄžßÄÍłį ŽēĆŽ¨łžóź žó≠žčú ŪēôžäĶ žÜ掏ĄÍįÄ ŽäźŽ†§žßÄŽäĒ Í≤įÍ≥ľŽ•ľ Žā≥žäĶŽčąŽč§.
- Í∑łŽüľ Tensorflow 2.0 žóźžĄú CNN žĚĄ žďįŽäĒ Žį©Ž≤ēžĚĄ ÍįĄŽěĶŪēėÍ≤Ć žēĆžēĄŽ≥īÍ≤†žäĶŽčąŽč§. žěźžĄłŪēú Žāīžö©žĚÄ Ží§žĚė Sample Code žóźžĄú Žč§Ž£į žėąž†ēžĚīÍłį ŽēĆŽ¨łžóź, žó¨ÍłįžĄúŽäĒ Convolution Layer API žóź ŽĆÄŪēú žĄ§Ž™ÖŽßĆ ÍįĄŽěĶŪěą ŽďúŽ¶¨Í≤†žäĶŽčąŽč§.
- Tensorflow 2.0 žóźžĄú API Ž•ľ ÍįĄŽěĶŪēėÍ≤Ć ŽßĆŽď§Í≥† ŪÜĶŪē©ŪĖąÍłį ŽēĆŽ¨łžóź, tf.keras.layers žóźžĄú Conv2D Layer Ž•ľ ÍįĄŽč®ŪēėÍ≤Ć Ž∂ąŽü¨žė¨ žąė žěąžäĶŽčąŽč§. Conv2D Ž†ąžĚīžĖīŽäĒ 2D žĚīŽĮłžßÄŽ•ľ Input žúľŽ°ú ŽįõŽäĒŽćį, žĚīŽĮłžßÄŽäĒ RGB ŽĚľŽäĒ 3ÍįúžĚė žĽ¨Žü¨ žĪĄŽĄźŽ°ú ÍĶ¨žĄĪŽźėžĖī žěąÍłį ŽēĆŽ¨łžóź žĚīŽĮłžßÄŽäĒ 3žį®žõź ŽćįžĚīŪĄįŽĚľÍ≥† ŽßźŪē† žąė žěąžäĶŽčąŽč§. Í∑łŽ¶¨Í≥† žč§ž†ú ŪēôžäĶžóźžĄú Ūēú žě•žĚė žĚīŽĮłžßÄŽßĆ ŪēôžäĶŪēėžßÄ žēäÍ≥† žó¨Žü¨ žě•žĚė žĚīŽĮłžßÄŽ•ľ ŪēôžäĶŪē† Í≤ÉžĚīÍłį ŽēĆŽ¨łžóź, žč§ž†ú input data ŽäĒ 4žį®žõźžĚī Žź©ŽčąŽč§.
- žó¨Íłįžóź Conv Layer Ž•ľ Ž∂ąŽü¨žė§ŽäĒ žėąž†ú žĹĒŽďúÍįÄ žěąžäĶŽčąŽč§. žó¨Íłįžóź žěąŽäĒ ž£ľžöĒ Žß§Íįú Ž≥Äžąėžóź ŽĆÄŪēīžĄú žĄ§Ž™ÖžĚĄ ŽďúŽ¶¨Í≤†žäĶŽčąŽč§.
- Ž®ľž†Ä kernel_size ŽäĒ Filter ÍįÄ Ūēú step ŽßąŽč§ Í≥ĄžāįŪēėŽäĒ žėĀžó≠žĚė ŪĀ¨Íłįžě֎蹎č§. žĚī Í∑łŽ¶ľžóźžĄú žēĄŽěėž™ĹžĚė ŪĆĆŽěÄžÉČžĚī žĚłŪíč žĚīŽĮłžßÄžĚīÍ≥† žīąŽ°ĚžÉČžĚī žēĄžõÉŪíč žĚīŽĮłžßĞ̾ ŽēĆ, žôľž™ĹžĚÄ kernel_size ÍįÄ 3 by 3 žėĀžó≠žĚīÍ≥†, žė§Ž•łž™ĹžĚÄ 4 by 4 žě֎蹎č§.
- strides ŽäĒ ŪēĄŪĄįÍįÄ Ūēú žä§ŪÖĚŽßąŽč§ žĚīŽŹôŪēėŽäĒ ŪĀ¨Íłįžě֎蹎č§. Stride ÍįÄ žĽ§žßÄŽ©ī ž∂úŽ†• žĚīŽĮłžßÄÍįÄ žěĎžēĄžßώ蹎č§. žė§Ž•łž™ĹžĚÄ strides ÍįÄ 1 by 1 žĚīžóąŽč§Ž©ī 3 by 3 žĚė ž∂úŽ†• žĚīŽĮłžßÄÍįÄ ŽźėžóąžĖīžēľ ŪēėÍ≤†žßÄŽßĆ, strides ÍįÄ 2 by 2 žĚīÍłį ŽēĆŽ¨łžóź Í≥Ąžāį Í≤įÍ≥ľ ž∂úŽ†•ŽŹĄ 2 by 2 žĚė žĚīŽĮłžßÄÍįÄ ŽźėžóąžäĶŽčąŽč§.
- Padding žĚÄ Ūó∑ÍįąŽ¶¨Íłį žČ¨žöī ÍįúŽÖźžě֎蹎č§. žĚľŽč® žó¨ÍłįžĄúŽäĒ ŽĎź ÍįÄžßÄžĚė žėĶžÖėžĚĄ ž†úÍ≥ĶŪēėŽäĒŽćį, valid ŽäĒ filter window ÍįÄ žĚłŪíč žĚīŽĮłžßÄ žēąžóźžĄúŽßĆ žõÄžßĀžĚīŽŹĄŽ°Ě ŪēėŽäĒ Í≤Éžě֎蹎č§. ŽĒįŽĚľžĄú Žā®ŽäĒ Í≥ĶÍįĄžĚÄ Ž≤ĄŽ†§žßÄÍ≤Ć Žź©ŽčąŽč§. Same žĚÄ žĚłŪíčÍ≥ľ žēĄžõÉŪíč žĚīŽĮłžßÄžĚė ŪĀ¨ÍłįÍįÄ ÍįôžēĄžßÄŽŹĄŽ°Ě žĚłŪíč žĚīŽĮłžßÄ ž£ľŽ≥Äžóź žěĄžĚėžĚė ÍįížĚĄ ŽĄ£žĖīžĄú ž°įž†ąŪēėŽäĒ Í≤Éžě֎蹎č§. žó¨ÍłįžĄú žěĄžĚėžĚė ÍįížĚĄ 0žúľŽ°ú ŽĄ£žúľŽ©ī zero padding žĚī Žź©ŽčąŽč§.
- Filters ŽäĒ Conv Layer Ž•ľ ÍĶ¨žĄĪŪēėŽäĒ filter žĚė žąėžě֎蹎č§. žĚī žąęžěźŽäĒ ŽĄ§ŪäłžõĆŪĀ¨ÍįÄ žĖľŽßąŽāė ŽßéžĚÄ feature Ž•ľ ž∂Ēž∂úŪē† žąė žěąŽäĒžßÄŽ•ľ Í≤įž†ēŪēėÍłį ŽēĆŽ¨łžóź ŽßéžĚĄžąėŽ°Ě žĘčžßÄŽßĆ, ŽĄąŽ¨ī ŽßéžĚĄ Í≤Ĺžöį ŪēôžäĶ žÜ掏ĄÍįÄ ŽäźŽ†§žßą žąė žěąÍ≥† žė§Ž≤Ą ŪĒľŪĆÖžĚī ŽįúžÉĚŪē† žąėŽŹĄ žěąžäĶŽčąŽč§.
- Ž≥īžčúŽäĒ Í≤Éž≤ėŽüľ ŽßéžĚÄ ŪēĄŪĄįŽ•ľ ÍįÄžßÄÍ≥† žěąŽč§ŽäĒ Í≤ÉžĚÄ Žč§žĖĎŪēú feature Ž•ľ ž∂Ēž∂úŪē† žąė žěąŽč§ŽäĒ ŽúĽžĚī Žź©ŽčąŽč§. ŪēėŽč®žĚė žĚīŽĮłžßĞ󟞥ú žė§Ž•łž™Ĺ ŪēĄŪĄįŽ•ľ ÍĪįžĻėŽ©ī žôľž™ĹÍ≥ľ ÍįôžĚÄ feature ÍįÄ ž∂Ēž∂úŽź©ŽčąŽč§.
- Í∑łŽüľ žĚīž†ú žč§ž†ú žÉėŪĒĆ žĹĒŽďúžôÄ Ūē®ÍĽė Tensorflow 2.0 žóźžĄú CNN žĚĄ žā¨žö©ŪēėŽäĒ Žį©Ž≤ēžĚĄ ÍįĄŽč®Ūěą ŪēôžäĶŪēīŽ≥īŽŹĄŽ°Ě ŪēėÍ≤†žäĶŽčąŽč§.
- ŽĒ•Žü¨Žč̞̥ Žįįžöł ŽēĆ ÍįÄžě• ž≤ėžĚĆ Žč§Ž£®Í≤Ć ŽźėŽäĒ ŽćįžĚīŪĄį ž§Ď ŪēėŽāėŽäĒ MNIST žě֎蹎č§. MNIST ŽäĒ žĖÄ Ž•īžŅ§žĚī 1998 ŽÖĄžóź ŽįúŪĎúŪēú ŽÖľŽ¨ł žĚīŪõĄ Ž®łžč†Žü¨ŽčĚžĚė Ž≤§žĻėŽßąŪĀ¨ ž§Ď ŪēėŽāėŽ°ú Ūôúžö©ŽźėžóąžäĶŽčąŽč§. 70,000 žě•žĚė ŽćįžĚīŪĄįŽ°ú ÍįĄŽč®ŪēėÍ≤Ć CNN žĚĄ ŪēīŽ≥ľ žąė žěąÍ≥†, ŽĄ§ŪäłžõĆŪĀ¨ ÍĶ¨ž°įŽāė ŪēėžĚīŪćľŪĆĆŽĚľŽĮłŪĄįŽ•ľ ŽįĒÍŅÄ ŽēĆ ŪćľŪŹ¨Ž®ľžä§ÍįÄ žĖīŽĖĽÍ≤Ć Ž≥ÄŪēėŽäĒžßÄ ŽĻ†Ž•īÍ≤Ć žēĆ žąė žěąžäĶŽčąŽč§.
- MNIST žĚė ž£ľžöĒ ŪćľŪŹ¨Ž®ľžä§ Ž¶¨žä§Ū䳎•ľ Ž≥īŽ©ī, Žč§Ž•ł Žį©Ž≤ēŽď§žĚĄ Ž¨ľŽ¶¨žĻėÍ≥† CNN žĚī žÉĀžúĄžóź žúĄžĻėŪēī žěąŽäĒ Í≤ɞ̥ Ž≥ľ žąė žěąžäĶŽčąŽč§. ž†ēŪôēŽŹĄ 99% žĚīžÉĀžúľŽ°ú 10 ÍįúžĚė ŽĚľŽ≤®žĚĄ žėąžł°Ūē©ŽčąŽč§.
- žĚī žėąž†úŽäĒ Tensorflow ŪôąŪéėžĚīžßÄžĚė žīąžč¨žěź ŽĆÄžÉĀ colab žĚĄ ÍłįŽįėžúľŽ°ú ŽßéžĚÄ Ž∂ÄŽ∂ĄžĚī žąėž†ēŽźėžóąžäĶŽčąŽč§.
- Í∑łŽüľ žėąž†úŽ•ľ žóīžĖīžĄú žč§ŪĖČŪēīŽ≥īŽŹĄŽ°Ě ŪēėÍ≤†žäĶŽčąŽč§.