tesi
0 likes806 views

Il documento analizza e confronta diverse architetture di database management systems (DBMS) utilizzando un benchmark standard (TPC-H) per testare prestazioni e capacit├Ā di gestione di dati. I risultati mostrano che, nonostante ci siano poche differenze significative tra i database relazionali e NoSQL, MySQL si ├© comportato particolarmente bene sotto carico. Inoltre, il documento evidenzia che molti DBMS relazionali non rispettano pienamente lo standard SQL:2008, e che i database NoSQL mancano completamente di uno standard definito.









![Generazione dei dati
Sperimentazione
Analisi dei risultati
Query 1 - SQL
select
l returnflag ,
l linestatus ,
sum ( l q u a n t i t y ) a s sum qty ,
sum ( l e x t e n d e d p r i c e ) a s s u m b a s e p r i c e ,
sum ( l e x t e n d e d p r i c e ŌłŚ(1ŌłÆ l d i s c o u n t ) ) a s s u m d i s c p r i c e ,
sum ( l e x t e n d e d p r i c e ŌłŚ(1ŌłÆ l d i s c o u n t )ŌłŚ(1+ l t a x ) ) a s s u m c h a r g e ,
avg ( l q u a n t i t y ) a s a v g q t y ,
avg ( l e x t e n d e d p r i c e ) a s a v g p r i c e ,
avg ( l d i s c o u n t ) a s a v g d i s c ,
count (ŌłŚ) as c o u n t o r d e r
from
lineitem
where
l s h i p d a t e <= d a t e ŌĆÖ 1998ŌłÆ12ŌłÆ01 ŌĆÖ ŌłÆ i n t e r v a l ŌĆÖ [ DELTA ] ŌĆÖ day ( 3 )
group by
l returnflag ,
l linestatus
o r d e r by
l returnflag ,
l linestatus ;
Mauro Fagnoni Analisi e comparazione architetture per DBMS](https://image.slidesharecdn.com/fagnoni608514-120215135622-phpapp02/85/tesi-15-320.jpg)
![Generazione dei dati
Sperimentazione
Analisi dei risultati
Query 1 - map/reduce
query: { shipdate: {ŌĆÖ$lteŌĆÖ: ŌĆÖ1998-11-28ŌĆÖ} },
map:function() { emit(
{returnflag: this.returnflag, linestatus: this.linestatus},
{count_order: 1, sum_qty: this.quantity, sum_base_price: this.extendedprice,
sum_disc_price:this.extendedprice*(1-this.discount),
sum_charge:this.extendedprice*(1-this.discount)*(1 + this.tax) });};
reduce: function(key, vals){
var ret = { count_order: 0, sum_qty: 0, sum_disc_price: 0, sum_base_price: 0,
sum_charge: 0 };
for (var i=0; i<vals.length; i++){
ret.sum_qty += vals[i].sum_qty;
ret.count_order += vals[i].count_order;
ret.sum_base_price += vals[i].sum_base_price;
ret.sum_disc_price += vals[i].sum_disc_price;
ret.sum_charge += vals[i].sum_charge;}
return ret;};
finalize: function(key,val) {
val.avg_qty = val.sum_qty/val.count_order;
val.avg_price = val.sum_base_price / val.count_order;
val.avg_disc = val.sum_disc_price / val.count_order;
return val;};
Mauro Fagnoni Analisi e comparazione architetture per DBMS](https://image.slidesharecdn.com/fagnoni608514-120215135622-phpapp02/85/tesi-16-320.jpg)



tesi
- 1. Analisi e comparazione empirica di architetture per DBMS Mauro Fagnoni Universit` degli Studi dellŌĆÖInsubria a Dipartimento di Informatica e Comunicazione Relatore: Prof. Alberto Trombetta 14 Ottobre 2011 Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 2. Obiettivo Benchmark Obiettivo Analizzare e comparare nuove tecnologie di gestione di basi di dati Procedura di analisi: benchmark standard Database analizzati: database relazionali Row oriented (MySQL e FirebirdSQL) Column oriented (MonetDB e LucidDB) database non relazionali NoSQL (CouchDB e MongoDB) Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 3. Obiettivo Benchmark Il benchmark Il benchmark TPC-H appartenente allo standard del Transaction Processing Performance Council ` composto da query di tipo commerciale e simula un reale caso di database aziendale ` composto da query con un alto grado di complessit` e a elevato numero di operatori e vincoli di selezione vincoli di integrit` sullo schema del database a genera unŌĆÖintensa attivit` del server ponendolo sotto stress a Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 4. Generazione dei dati Sperimentazione Analisi dei risultati Fasi di lavoro 1 Generazione dei dati 2 Sperimentazione 3 Analisi dei risultati Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 5. Generazione dei dati Sperimentazione Analisi dei risultati La generazione dei dati, secondo gli standard proposti dal TPC, ` e stata realizzata attraverso il programma DbGen che ha prodotto un dataset in formato CSV di 1.1 Gigabyte Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 6. Generazione dei dati Sperimentazione Analisi dei risultati Fasi di lavoro 1 Generazione dei dati 2 Sperimentazione 3 Analisi dei risultati Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 7. Generazione dei dati Sperimentazione Analisi dei risultati Nella fase di sperimentazione per ogni database sono stati eseguiti: Popolamento del database attraverso bulk loading (nei casi in cui ` stato possibile) e Test per mezzo di un programma Java che, attraverso una serie di iterazioni, memorizza sia i risultati che le prestazioni Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 8. Generazione dei dati Sperimentazione Analisi dei risultati Nella fase di sperimentazione per ogni database sono stati eseguiti: Popolamento del database attraverso bulk loading (nei casi in cui ` stato possibile) e Test per mezzo di un programma Java che, attraverso una serie di iterazioni, memorizza sia i risultati che le prestazioni Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 9. Generazione dei dati Sperimentazione Analisi dei risultati Problemi riscontrati Database relazionali Scarso supporto allo standard SQL Database non relazionali Supporto allo standard SQL assente Necessit` di destrutturazione dei dati del modello TPC-H a Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 10. Generazione dei dati Sperimentazione Analisi dei risultati Destrutturazione dati NoSQL Di’¼Ćerenti caratteristiche architetturali I database NoSQL non supportano il modello relazionale Le operazioni di join sono eliminate Dati semi strutturati organizzati a documenti Impossibilit` di utilizzo del modello standard a Supporto al paradigma map/reduce Mauro Fagnoni Analisi e comparazione architetture per DBMS
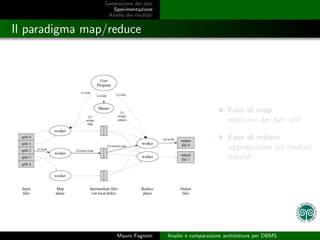
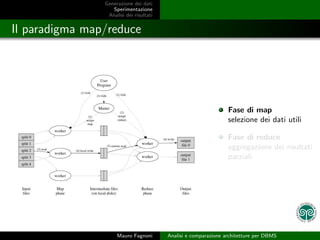
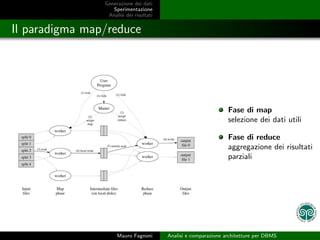
- 11. Generazione dei dati Sperimentazione Analisi dei risultati Il paradigma map/reduce Fase di map selezione dei dati utili Fase di reduce aggregazione dei risultati parziali Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 12. Generazione dei dati Sperimentazione Analisi dei risultati Il paradigma map/reduce Fase di map selezione dei dati utili Fase di reduce aggregazione dei risultati parziali Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 13. Generazione dei dati Sperimentazione Analisi dei risultati Il paradigma map/reduce Fase di map selezione dei dati utili Fase di reduce aggregazione dei risultati parziali Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 14. Generazione dei dati Sperimentazione Analisi dei risultati Destrutturazione dati NoSQL Soluzioni Analisi del modello Query che coinvolgessero una sola tabella Aggregazione dei dati delle tabelle coinvolte nelle query 1 e 19 Riscrittura delle query 1 e 19 del modello Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 15. Generazione dei dati Sperimentazione Analisi dei risultati Query 1 - SQL select l returnflag , l linestatus , sum ( l q u a n t i t y ) a s sum qty , sum ( l e x t e n d e d p r i c e ) a s s u m b a s e p r i c e , sum ( l e x t e n d e d p r i c e ŌłŚ(1ŌłÆ l d i s c o u n t ) ) a s s u m d i s c p r i c e , sum ( l e x t e n d e d p r i c e ŌłŚ(1ŌłÆ l d i s c o u n t )ŌłŚ(1+ l t a x ) ) a s s u m c h a r g e , avg ( l q u a n t i t y ) a s a v g q t y , avg ( l e x t e n d e d p r i c e ) a s a v g p r i c e , avg ( l d i s c o u n t ) a s a v g d i s c , count (ŌłŚ) as c o u n t o r d e r from lineitem where l s h i p d a t e <= d a t e ŌĆÖ 1998ŌłÆ12ŌłÆ01 ŌĆÖ ŌłÆ i n t e r v a l ŌĆÖ [ DELTA ] ŌĆÖ day ( 3 ) group by l returnflag , l linestatus o r d e r by l returnflag , l linestatus ; Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 16. Generazione dei dati Sperimentazione Analisi dei risultati Query 1 - map/reduce query: { shipdate: {ŌĆÖ$lteŌĆÖ: ŌĆÖ1998-11-28ŌĆÖ} }, map:function() { emit( {returnflag: this.returnflag, linestatus: this.linestatus}, {count_order: 1, sum_qty: this.quantity, sum_base_price: this.extendedprice, sum_disc_price:this.extendedprice*(1-this.discount), sum_charge:this.extendedprice*(1-this.discount)*(1 + this.tax) });}; reduce: function(key, vals){ var ret = { count_order: 0, sum_qty: 0, sum_disc_price: 0, sum_base_price: 0, sum_charge: 0 }; for (var i=0; i<vals.length; i++){ ret.sum_qty += vals[i].sum_qty; ret.count_order += vals[i].count_order; ret.sum_base_price += vals[i].sum_base_price; ret.sum_disc_price += vals[i].sum_disc_price; ret.sum_charge += vals[i].sum_charge;} return ret;}; finalize: function(key,val) { val.avg_qty = val.sum_qty/val.count_order; val.avg_price = val.sum_base_price / val.count_order; val.avg_disc = val.sum_disc_price / val.count_order; return val;}; Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 17. Generazione dei dati Sperimentazione Analisi dei risultati Fasi di lavoro 1 Generazione dei dati 2 Sperimentazione 3 Analisi dei risultati Mauro Fagnoni Analisi e comparazione architetture per DBMS
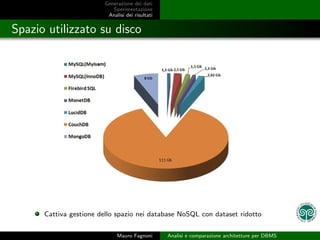
- 18. Generazione dei dati Sperimentazione Analisi dei risultati Spazio utilizzato su disco Cattiva gestione dello spazio nei database NoSQL con dataset ridotto Mauro Fagnoni Analisi e comparazione architetture per DBMS
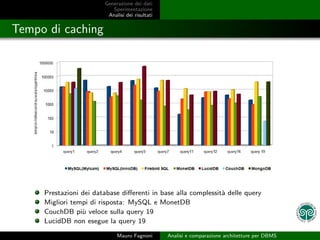
- 19. Generazione dei dati Sperimentazione Analisi dei risultati Tempo di caching Prestazioni dei database di’¼Ćerenti in base alla complessit` delle query a Migliori tempi di risposta: MySQL e MonetDB CouchDB pi` veloce sulla query 19 u LucidDB non esegue la query 19 Mauro Fagnoni Analisi e comparazione architetture per DBMS
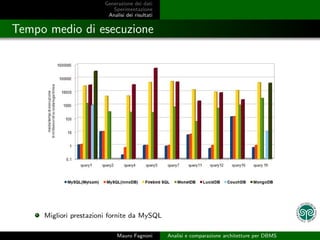
- 20. Generazione dei dati Sperimentazione Analisi dei risultati Tempo medio di esecuzione Migliori prestazioni fornite da MySQL Mauro Fagnoni Analisi e comparazione architetture per DBMS
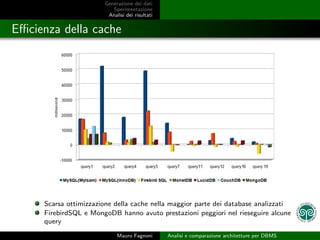
- 21. Generazione dei dati Sperimentazione Analisi dei risultati E’¼ācienza della cache Scarsa ottimizzazione della cache nella maggior parte dei database analizzati FirebirdSQL e MongoDB hanno avuto prestazioni peggiori nel rieseguire alcune query Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 22. Conclusioni Considerazioni riguardo al benchmark Senza usare repliche e avendo destrutturato i dati non sono emerse grosse di’¼Ćerenze prestazionali tra i database SQL e NoSQL MySQL ha fornito migliori prestazioni sia con MyISAM che con InnoDB CouchDB ha fornito prestazioni simili a MySQL Considerazioni generali Molti database relazionali non rispettano ancora completamente lo standard SQL:2008 Totale mancanza di uno standard nei database NoSQL Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 23. Conclusioni Considerazioni riguardo al benchmark Senza usare repliche e avendo destrutturato i dati non sono emerse grosse di’¼Ćerenze prestazionali tra i database SQL e NoSQL MySQL ha fornito migliori prestazioni sia con MyISAM che con InnoDB CouchDB ha fornito prestazioni simili a MySQL Considerazioni generali Molti database relazionali non rispettano ancora completamente lo standard SQL:2008 Totale mancanza di uno standard nei database NoSQL Mauro Fagnoni Analisi e comparazione architetture per DBMS
- 24. GRAZIE PER LŌĆÖATTENZIONE Mauro Fagnoni Analisi e comparazione architetture per DBMS