Thanatos - Parallel & Distributed Computing
0 likes50 views

Il documento descrive l'implementazione di un attacco a forza bruta sul crittosistema DES utilizzando un'infrastruttura di calcolo distribuito con CPU e GPU. Si analizzano i vari strumenti e approcci, tra cui CUDA-C e OpenMPI, per confrontare l'efficacia delle prestazioni nella decrittazione delle chiavi. Inoltre, vengono presentati i risultati e le metriche di performance ottenute dalle diverse implementazioni testate.

































Thanatos - Parallel & Distributed Computing
- 1. Thanatos Implementazione di un attacco a Forza Bruta sul Crittosistema D.E.S. tramite unŌĆÖinfrastruttura di calcolo distribuito e parallelo In ordine Alfabetico: Francesco Pietralunga Idriss Riouak Renato Garavaglia Tommaso Campari Corso di Laurea in Informatica
- 2. SOMMARIO ŌĆó Strumenti utilizzati ŌĆó Scopo del progetto ŌĆó DES - Implementazione in C ŌĆó Introduzione CUDAŌĆōC ŌĆó Architettura CUDA ŌĆó Implementazione DES su CUDA -C
- 7. Strumenti Utilizzati EŌĆÖ uno package di tools per la verifica, il profiling e il debugging di programmi. Valgrind ├© in grado di rilevare automaticamente la presenza di memory leak.
- 8. Strumenti Utilizzati API multipiattaforma per la creazione di applicazioni parallele su sistemi a memoria condivisa
- 11. Scopo del Progetto Lo scopo del nostro lavoro ├© quello non tanto di mettere in evidenza le gi├Ā note vulnerabilit├Ā del crittosistema DES, ma piuttosto quello di fare un confronto tra due approcci distinti di attacco al crittosistema che utilizzano la medesima modalit├Ā ma con strumenti differenti, in particolare verranno utilizzate nella prima parte dei test le CPU presenti sui nodi della rete, mentre nella seconda parte verranno utilizzate le GPU. Il DES (Data Encryption standard ) ├© un Crittosistema scelto come standard dal Federal Information Processing Standard (FIPS) per il governo degli Stati Uniti dŌĆÖAmerica nel 1976. Si basa su chiavi a 64 bit (di cui 8 sono di controllo, quindi lo spazio dei valori si riduce a 56 bit) e per questo si presta a un attacco a Forza Bruta. Seppur 256 chiavi siano poche, un singolo processore impiegherebbe anni a testarle tutte, per questo gi├Ā nel 1998 gli EFFŌĆÖs DES cracker (Deep Crack) ruppero il DES in appena 56 ore grazie a un supercomputer equipaggiato con 1856 chip.
- 12. DES -Implementazione in C DEMO PRATICA Il C ├© un linguaggio di programmazione di basso livello, per questo ├© spesso visto come uno dei linguaggi pi├╣ ╠ü performanti in circolazione. Inoltre ha svariate librerie che permettono di svolgere funzioni altrimenti complicate come il trasferimento delle chiavi dal master ai vari Worker con OpenMPI o lŌĆÖesecuzione con multithreading grazie a OpenMP.
- 13. Introduzione CUDA-C Perch├® CUDA-C ? Noi abbiamo scelto CUDA-C in quanto si prestava particolarmente ai nostri fini: fornisce infatti supporto a OpenMPI e OpenMP e le parti CPU si presentano comunque efficienti in quanto C ├© tra i linguaggi pi├╣ performanti. CosŌĆÖ├© CUDA-C ? Le schede grafiche con supporto a CUDA (Compute Unified Device Architecture) sono un tipo di Hardware creato da NVIDIA per permettere lŌĆÖesecuzione di calcolo parallelo su GPU. I linguaggi di programmazione disponibili nellŌĆÖambiente di sviluppo per CUDA, sono estensioni dei linguaggi pi├╣ diffusi per scrivere programmi. Il principale ├© CUDA-C (C con estensioni NVIDIA), altri sono estensioni di Python, Fortran, Java e MATLAB.
- 14. Architettura CUDA CUDA basa il suo funzionamento sul concetto di esecuzione parallela, questo ├© possibile grazie a particolari funzioni marcate con la keyword global che sono anche definite come funzioni kernel. Una funzione kernel si presenta esattamente come una funzione C nella sua definizione, le differenze si mostrano infatti al momento della chiamata che ├© strutturata come: kernel <<< NumBlocks, NumThreads >>> (Arguments);
- 15. Implementazioni DES su CUDA-C 1┬░ Implementazione CUDA-C 2┬░ Implementazione CUDA-C
- 16. PROFILING ŌĆó Profiling DES su CUDA-C ŌĆó ZeroCopyMemory ŌĆó Profiling Jetson TX1
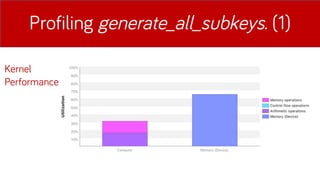
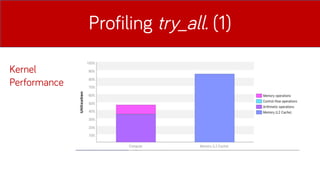
- 18. Profiling DES su CUDA-C Profiling dei tempi dŌĆÖesecuzione con nvprof.
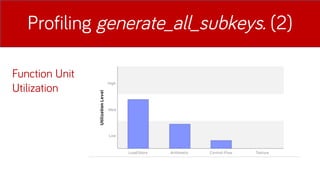
- 20. Profiling generate_all_subkeys. (2) Function Unit Utilization
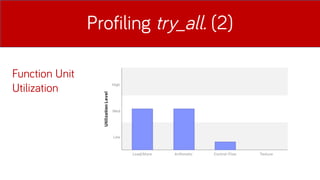
- 22. Profiling try_all. (2) Function Unit Utilization
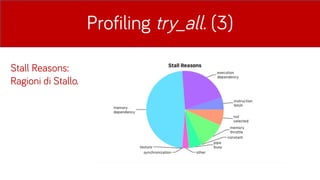
- 23. Profiling try_all. (3) Stall Reasons: Ragioni di Stallo.
- 24. Jetson TX1 Scheda Jetson TX1 con CPU 64-bit ARM┬« A57 CPUs e GPU 1 TFLOP/s 256-core with NVIDIA MaxwellŌäó Architecture
- 25. Jetson TX1 LŌĆÖuniversit├Ā ci ha fornito lŌĆÖaccesso ad una scheda Jetson TX1 sulla quale effettuare dei test. Questa scheda, ha unŌĆÖunica memoria centrale, condivisa tra CPU e GPU. Infatti per utilizzare questa scheda, per allocare la memoria, bisogna utilizzare il metodo dŌĆÖallocazione ZeroCopy.
- 26. ZeroCopyMemory Per lŌĆÖimplementazione ├© stato modificata la seconda implementazione in CUDA-C cfr(║▌║▌▀Ż 7) Sostituendo le classiche cudaMalloc con le chiamate cudaHostAlloc fornite dalla libreria CUDA e le cudaMemcpy con cudaGetHostDevicePointer con le seguenti Sintassi. cudaError_t cudaHostAlloc(void** pHost, size_t size, unsigned int flags). cudaError_t cudaHostGetDevicePointer(void ** pDevice, void * pHost, unsigned int flags).
- 27. Profiling Jetson TX1 Analisi dei tempi dŌĆÖesecuzione sulla macchina Jetson TX1
- 28. Comunicazione & Distribuzione Chiavi ŌĆó Entit├Ā Server e Client ŌĆó Scatter ŌĆó Coda ŌĆó Opzioni dŌĆÖesecuzione ŌĆó Gestione delle richieste
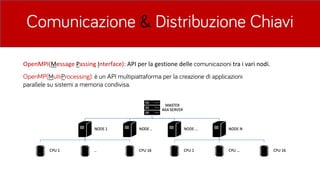
- 29. Comunicazione & Distribuzione Chiavi OpenMPI(Message Passing Interface): API per la gestione delle comunicazioni tra i vari nodi. OpenMP(MultiProcessing): ├© un API multipiattaforma per la creazione di applicazioni parallele su sistemi a memoria condivisa.
- 30. Comunicazione & Distribuzione Chiavi ŌĆó LŌĆÖentit├Ā Server: che distribuisce blocchi di chiavi ai singoli Client e ne testa il risultato. ŌĆó LŌĆÖentit├Ā Client: che per ogni chiave del blocco passatogli prova a decifrare il messaggio e se ha successo informa il Server che la chiave ├© stata trovata e dunque il messaggio messaggio viene ridecifrato dal Server e mostra allŌĆÖutente la chiave trovata.
- 31. Scatter & Coda (1) Int MPI_Scatter( const void* sendbuf, int sendCount, MPI_Datatype sendtype, void* recvbuff, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm);
- 32. Scatter & Coda (2) 256 chiavi 255 chiavi ŌĆó Supponiamo di avere K client con CPU a disposizione Numero di Blocchi = 255 # $%&'() LŌĆÖeventuale resto viene calcolato dallŌĆÖultimo client. Gestito tramite coda. ║▌║▌▀Ż successiva
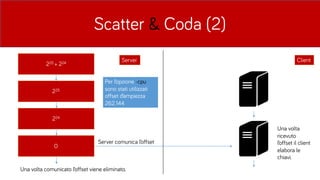
- 33. Scatter & Coda (2) 225 + 224 225 224 0 Server Client Server comunica lŌĆÖoffset Una volta comunicato lŌĆÖoffset viene eliminato. Una volta ricevuto lŌĆÖoffset il client elabora le chiavi. Per lŌĆÖopzione -cpu sono stati utilizzati offset dŌĆÖampiezza 262.144
- 34. Opzioni dŌĆÖesecuzione (1) typedef struct {long long possibileChiave; long long processID; double tempo; int tipo; } infoExec; static MPI_Datatype Info_Type;
- 35. Opzioni dŌĆÖesecuzione (2) -cpu: vengono utilizzate come unica unit├Ā dŌĆÖelaborazione le CPU. -gpu: vengono utilizzate come unica unit├Ā dŌĆÖelaborazione le GPU. -zcmem: deve essere preceduta da ŌĆōgpu o da -hybrid, e permette di eseguire i test utilizzando i costrutti CudaHostAlloc e CudaGetHostDevicePointer. -hybrid: permette di utilizzare contemporaneamente sia lŌĆÖunit├Ā dŌĆÖelaborazione CPU che GPU, sfruttando dunque al massimo tutta la potenza computazionale a disposizione.
- 36. Gestione delle richieste Per poter gestire i diversi messaggi che i client devono mandare al server, utilizziamo diversi tipi di TAG. cfr(OpenMPI) ŌĆó Key_found_tag (0): Utilizzando questo Tag, il client comunica al master che ha trovato la chiave per decifrare il messaggio di partenza. ŌĆó New_offset_request_tag (1): Utilizzando questo Tag, il master ├© in grado di capire che uno dei client ha bisogno di un nuovo blocco di chiavi da processare. ŌĆó Info_on_elaboration_tag(2): Utilizzando questo Tag, il client raccoglie il messaggio e lo elabora per ricavare lŌĆÖavanzamento totale dellŌĆÖattacco.
- 37. GREEN COMPUTING VS GRID COMPUTING ŌĆó TESLA VS XEON VS JETSON ŌĆó ARM VS XEON ŌĆó ZeroCopyMemory ŌĆó Hybrid Function: 4K40 VS TX1 ŌĆó 1998 VS 2016
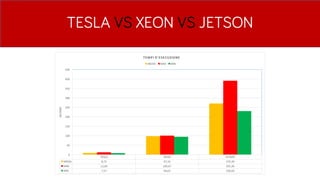
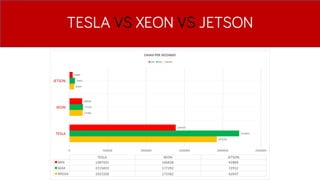
- 38. TESLA VS XEON VS JETSON
- 39. TESLA VS XEON VS JETSON
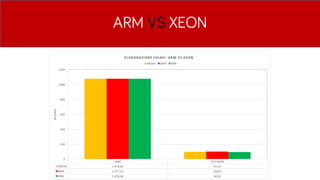
- 40. ARM VS XEON
- 43. HYBRID FUNCTION: 4K40 VS TX1
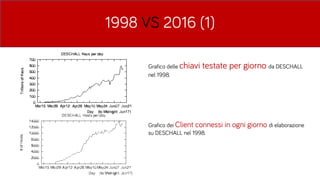
- 44. 1998 VS 2016 (1) Grafico delle chiavi testate per giorno da DESCHALL nel 1998. Grafico dei Client connessi in ogni giorno di elaborazione su DESCHALL nel 1998.
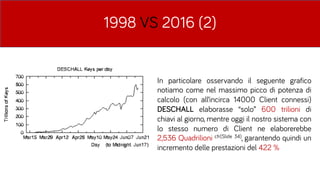
- 45. 1998 VS 2016 (2) In particolare osservando il seguente grafico notiamo come nel massimo picco di potenza di calcolo (con allŌĆÖincirca 14000 Client connessi) DESCHALL elaborasse ŌĆ£soloŌĆØ 600 trilioni di chiavi al giorno, mentre oggi il nostro sistema con lo stesso numero di Client ne elaborerebbe 2,536 Quadrilioni cfr(║▌║▌▀Ż 34), garantendo quindi un incremento delle prestazioni del 422 %