Topic models
âĒDownload as PPTX, PDFâĒ
0 likesâĒ1,397 views

[Topic models, LDA, LSA, HDP, Coherence] This is for topic modeling in NLP.



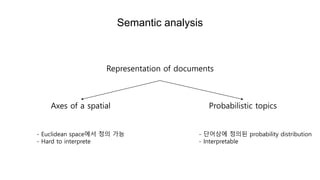




































![CRP using HDP
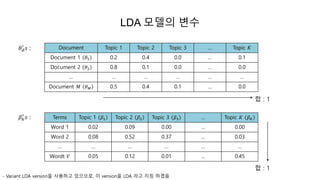
[ðš0~ð·ð ðū, ðŧ ]
ïŽ ė§ėė ė ėė ėļęļ°ëëĨž ęģ ë Īíīė ėīë ė ėėė ėėė íė§ ęē°ė
ïŽ ė ėė ėīëĪ ėėėī ėŽë Īė§ė§ë ė ėėė ėēŦ ė§ėėī ėėė í ë, ëŠĻëķíŽ ðŧėė ėėė íë ë―ėėžëĄ ęē°ė
ïŽ ė ėė ėļęļ°ëë ėėė íļë ė§ėė ėė ëđëĄíęģ , ė§ėėī ëđėīėë ė ėëĨž ęģ ëĨž ėë ėëĪ. ė ėė ėļęļ°ëë
ė§ėĪ íëžëŊļí° ðūė ėęīėëĪ.
[ðšð~ð·ð(ðž, ðš0)]
ïŽ ėëė ėíė ėļęļ°ëëĨž ęģ ë Īíīė ėīë ėíė ėėė§ëĨž ęģ ëĨļëĪ.
ïŽ ėíė ėīëĪ ėėėī ėŽë Īė§ė§ë ėíė ėēŦ ėëėī ėėžëĐī ė§ėė ëģļėŽëĄ ëģīëīė ęē°ė íęģ , ę·ļ ėėė ëķíŽ ėė
ė§ėëĪėī ė ėėė ėėė íļë ëķíŽ ðš0ëĨž ë°ëĨļëĪ. (ėíėë 1ę°ė ėėë§ ėŽëžę°ëĪ)
ïŽ ėíė ėļęļ°ëë ėė ėë ėŽëė ėė ëđëĄíęģ , ė§ėĪ íëžëŊļí° ðžė ë°ëžė ëđėīėë ėíė ęģ ëĨžėë ėëĪ.](https://image.slidesharecdn.com/topicmodels-190812083121/85/Topic-models-55-320.jpg)


Topic models
- 1. Jeonghun Yoon Probabilistic Topic Models
- 2. Natural Language Processing Natural language(ėė°ėī) : ėžė ėíėė ėŽėĐíë ėļėī Natural language processing(ėė°ėī ėēëĶŽ) : ėė°ėīė ėëŊļëĨž ëķėíėŽ ėŧīíĻí°ę° ėŽëŽę°ė§ ėžëĪė(tasks) ėē ëĶŽí ė ėëëĄ íë ęē Easy ïŽ Spell checking, Keyword search, Finding synonyms Medium ïŽ Parsing information from websites, documents, etc Hard ïŽ Machine translation ïŽ Semantic analysis ïŽ Coherence ïŽ Question answering CS 224D : Deep Learning for NLP
- 3. Semantic analysis ėļėīíėėė ėëŊļ ëķė ïŽ ėė°ėīëĨž ėīíīíë ęļ°ëē ėĪ íëëĄ, ëŽļėĨė ėëŊļ(meaning, semantic)ė ę·žęą°íėŽ ëŽļėĨė íīėíë ęēė ėëŊļ ïŽ Syntax analysisė ë°ë(lexicon, syntax analysis) ëĻļė ëŽëėėė ėëŊļ ëķė ïŽ Corpusė ėë ë§ė documents ė§íĐė ëīė ëėī ėë(latent) meanings, concepts, subjects, topics ëąė ėķė í ė ėë ęĩŽėĄ°ëĨž ėėąíë ęēė ėëŊļ ïŽ ëíė ėļ ėëŊļ ëķė ęļ°ëē ïŽ Latent Semantic Analysis(LSA or LSI) ïŽ PLSI ïŽ Latent Dirichlet Allocation(LDA) ïŽ Hieararchical Dirichlet Processing(HDP)
- 4. Semantic analysis Representation of documents Axes of a spatial Probabilistic topics - Euclidean spaceėė ė ė ę°ëĨ - Hard to interprete - ëĻėīėė ė ėë probability distribution - Interpretable
- 5. 1. Axes of a spatial - LSA 2. Probabilistic topics - LDA 3. Bayesian Nonparametric - HDP
- 6. LSA (Latent Semantic Analysis) ïŽ LSA(LSI)ë document dataė ėĻęēĻė§ ėëŊļ(hidden concept)ëĨž ė°ūėëīë ęļ°ëēėīëĪ. ïŽ LSAë ę°ę°ė ëŽļė(document)ė ëĻėī(word)ëĨž ëēĄí°ëĄ íííëĪ. ëēĄí°ëīėė ę°ę°ė elementë ėĻęēĻė§ ėëŊļę° ë ęēėīëĪ.
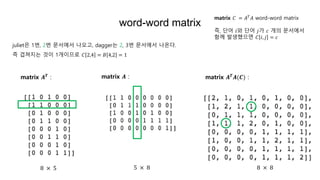
- 7. LSA (Latent Semantic Analysis) ïŽ 3ëē ëŽļėë ėŋžëĶŽė ëíīė 1ëąėī ë ęēėīëĪ. ïŽ 2ëē, 4ëē ëŽļėë ę·ļ ëĪėėī ë ęēėīëĪ. ïŽ 1ëē, 5ëē ëŽļėë? ïž ėŽëëĪėī ėļėíęļ°ëĄë ëŽļė 1ëēėī ëŽļė 5ëē ëģīëĪ ėĢžėīė§ ėŋžëĶŽė ë ë§ë ëŽļėėīëĪ. ėŧīíĻí°ë ėīëŽí ėķëĄ ęģžė ė í ė ėėęđ? ėĶ ėĻęēĻė§ ėëŊļëĨž ė°ūė ė ėėęđ? ð1 : Romeo and Juliet. ð2 : Juliet: O happy dagger! ð3 : Romeo died by dagger. ð4 : "Live free or die", that's the motto of New-Hampshire ð5 : Did you know, New-Hampshire is in New-England ððĒðððĶ : dies and dagger
- 8. LSA (Latent Semantic Analysis) matrix ðĻ : romeo juliet happy dagger live die free new-hampshire ð1 ð2 ð3 ð4 ð5
- 9. LSA (Latent Semantic Analysis) matrix ðĻ : romeo juliet happy dagger live die free new-hampshire ð1 ð2 ð3 ð4 ð5
- 10. doc-doc matrix matrix ðĻ : matrix ðĻ ðŧ: matrix ðĻðĻ ðŧ(ðĐ): 5 à 8 8 à 5 5 à 5 1ëē ëŽļėėë romeo, juliet, 2ëē ëŽļėėë juliet, happy, dagger ėĶ ęēđėģė§ë ęēėī 1ę°ėīëŊëĄ ðĩ 1,2 = ðĩ 2,1 = 1 matrix ðĐ = ðīðī ð doc-doc matrix ëŽļė ðė ëŽļė ðę° ðę° ė ęģĩíĩ ëĻėīëĨž ę°ė§ęģ ėėžëĐī ðĩ ð, ð = ð
- 11. word-word matrix 8 à 5 5 à 8 8 à 8 matrix ðĻ :matrix ðĻ ðŧ : matrix ðĻ ðŧ ðĻ(ðŠ) : julietė 1ëē, 2ëē ëŽļėėė ëėĪęģ , daggerë 2, 3ëē ëŽļėėė ëėĻëĪ. ėĶ ęēđėģė§ë ęēėī 1ę°ėīëŊëĄ ðķ 2,4 = ðĩ 4,2 = 1 matrix ðķ = ðī ð ðī word-word matrix ėĶ, ëĻėī ðė ëĻėī ðę° ð ę°ė ëŽļėėė íĻęŧ ë°ėíėžëĐī ðķ ð, ð = ð
- 12. LSA (Latent Semantic Analysis) SVD ėŽėĐ! ðī = ðÎĢð ð, ðë ðĩė eigenvectorsėīęģ , ðë ðķė eigenvectorsėīëĪ. singular value
- 13. LSA (Latent Semantic Analysis) Reduced SVD ėŽėĐ! ðī ð = ð ðÎĢk ð ð ð , ëŠĻë singular valueëĨž ėŽėĐí ė ėęģ , ėė ęēëĪė ė ėļíëĪ. ðę°ė íđėīę°ë§ ëĻęļ°ë ęēėīëĪ. ėĶ ðę°ė "hidden concepts"ë§ ëĻęļīëĪ.
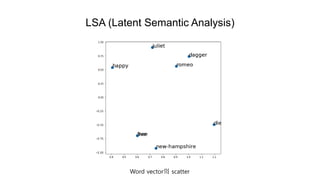
- 14. LSA (Latent Semantic Analysis) ÎĢ2 ð2 ð = ð2 ð = Word vector
- 15. LSA (Latent Semantic Analysis) Word vectorė scatter
- 16. LSA (Latent Semantic Analysis) ð2ÎĢ2 = ð2 = Document vector ð1 ð2 ð3 ð4 ð5 ð1 ð2 ð3 ð4 ð5
- 17. LSA (Latent Semantic Analysis) Document vectorė scatter
- 18. LSA (Latent Semantic Analysis) Word / Document vectorė scatter
- 19. LSA (Latent Semantic Analysis) cosine similarity = ð ðâð ð ð ðð = ð1 + ð2 2 query : dagger, die result :
- 20. LSA (Latent Semantic Analysis) Word / Document / Query vectorė scatter
- 21. 1. Axes of a spatial - LSA 2. Probabilistic topics - LDA 3. Bayesian Nonparametric - HDP
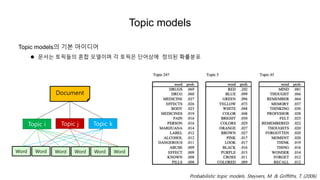
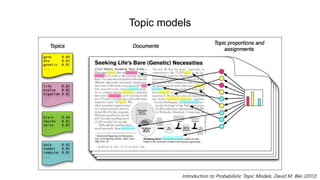
- 22. Topic models Topic modelsė ęļ°ëģļ ėėīëėī ïŽ ëŽļėë í í―ëĪė ížíĐ ëŠĻëļėīëĐ° ę° í í―ė ëĻėīėė ė ėë íëĨ ëķíŽ Document Topic i Topic j Topic k Word Word Word Word Word Word Probabilistic topic models. Steyvers, M. & Griffiths, T. (2006)
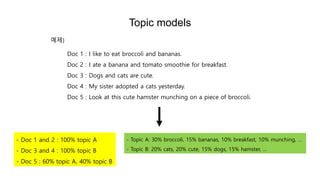
- 23. Topic models - Topic A: 30% broccoli, 15% bananas, 10% breakfast, 10% munching, âĶ - Topic B: 20% cats, 20% cute, 15% dogs, 15% hamster, âĶ Doc 1 : I like to eat broccoli and bananas. Doc 2 : I ate a banana and tomato smoothie for breakfast. Doc 3 : Dogs and cats are cute. Doc 4 : My sister adopted a cats yesterday. Doc 5 : Look at this cute hamster munching on a piece of broccoli. ėė ) - Doc 1 and 2 : 100% topic A - Doc 3 and 4 : 100% topic B - Doc 5 : 60% topic A, 40% topic B
- 24. Topic models Introduction to Probabilistic Topic Models. David M. Blei (2012)
- 25. Topic models Introduction to Probabilistic Topic Models. David M. Blei (2012) (Left) ëŽļėėėė topic proportion (Right) ëŽļėėė ëđėĪėī ëėë í í―ė ëíėŽ, í í―ëģ ëŽļėëī ëđëėę° ę°ėĨ ëė ëĻėī
- 26. Probabilistic Topic Modelsė ęĩŽėĄ° ëŠĻëļė ė ėė ėė, íėí ëĻėīëĪė ėíė íęļ° ïŽ Word : 1, âĶ , ð ëĨž ėļëąėĪëĄ ę°ė§ë vocaburary ėė items ïŽ Document : ð wordė sequence ïŽ ðĻ = ðĪ1, ðĪ2, âĶ , ðĪ ð , ðĪ ð : wordė sequenceëīėė ðëēė§ļė ėë word ïŽ Corpus : ð· documentsė collection ïŽ ðķ = ðĻ1, ðĻ2, âĶ , ðĻ ð·
- 27. Probabilistic Topic Modelsė ęĩŽėĄ° ëŽļė ðė ëĻėī ðĪð ëí ëķíŽ : ð ðĪð = ð=1 ðū ð ðĪð|ð§ð = ð ð ð§ð = ð ïŽ ð ðĪð|ð§ð = ð : í í― ðėė, ëĻėī ðĪðė probability ïŽ ę° í í―ėė ėīëĪ ëĻėīëĪėī ėĪėí ęđ? ïŽ ð ð§ð = ð : ðëēė§ļ ëĻėīė í í― ðę° í ëđëë probability (ėĶ, í í― ðę° ðëēė§ļ ëĻėīëĨž ėíī ėíë§ ë íëĨ ) ð― ð = ð ðĪ|ð§ = ð : í í― ðėė, ëĻėīëĪė multinomial distribution ð ð = ð ð§ : ëŽļė ðėė, í í―ëĪė multinomial distribution
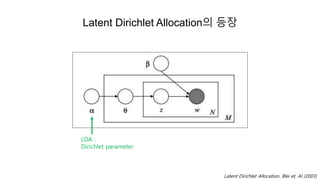
- 28. Latent Dirichlet Allocationė ëąėĨ ëŽļė ðė ëĻėī ðĪð ëí ëķíŽ : ð ðĪð = ð=1 ðū ð ðĪð|ð§ð = ð ð ð§ð = ð ëëĶŽíīë ëķíŽ(Dirichlet distribution)ė multinomial distributionė ėžĪë ėŽė ëķíŽëĄ(conjugate prior) ėŽėĐ ëĪí ëķíŽ(Multinomial distribution) ð = ð1, âĶ , ð ðū ė ëí Dirichlet distribution : ð·ðð ðž1, âĶ , ðž ðū = Î ð ðž ð ð Î ðž ð ð=1 ðū ð ð ðž ðâ1 ïŽ Hyperparameter ðžð : ëŽļė ðėė í í― ðę° ėíë§ ë íėė ëí ėŽė ęīė°° count (ëŽļėëĄëķí° ëĻėīę° ėĪė ëĄ ęī ė°°ëęļ° ėīė ė ę°) LDAë Dirichlet distributionė ðė priorëĄ ėŽėĐ (Blei et. Al, 2003)
- 29. Latent Dirichlet Allocationė ëąėĨ Latent Dirichlet Allocation. Blei et. Al (2003) LDA : Dirichlet parameter
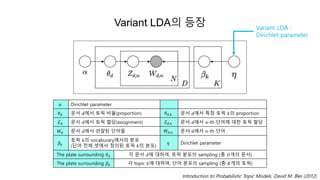
- 30. Variant LDAė ëąėĨ ëŽļė ðė ëĻėī ðĪð ëí ëķíŽ : ð ðĪð = ð=1 ðū ð ðĪð|ð§ð = ð ð ð§ð = ð Hyperparameter ð : Corpusė ëĻėīę° ęīė°°ëęļ° ėīė ė, í í―ėė ëĻėīę° ėíë§ ë íėė ëí ėŽė ęīė°° count Varian LDAë symmetric Dirichlet distribution(ðž)ė ð·ė priorëĄ ėŽėĐ (Griffiths and Steyvers, 2004)
- 31. Variant LDAė ëąėĨ Variant LDA : Dirichlet parameter Introduction to Probabilistic Topic Models. David M. Blei (2012) ðž Dirichlet parameter ð ð ëŽļė ðėė í í― ëđėĻ(proportion) ð ð,ð ëŽļė ðėė íđė í í― ðė proportion ð ð ëŽļė ðėė í í― í ëđ(assignment) ð ð,ð ëŽļė ðėė ð-th ëĻėīė ëí í í― í ëđ ðð ëŽļė ðėė ęīė°°ë ëĻėīëĪ ðð,ð ëŽļė ðėė ð-th ëĻėī ð― ð í í― ðė vocaburaryėėė ëķíŽ (ëĻėī ė ėēī ė ėė ė ėë í í― ðė ëķíŽ) ð Dirichlet parameter The plate surrounding ð ð ę° ëŽļė ðė ëíėŽ, í í― ëķíŽė sampling (ėī ð·ę°ė ëŽļė) The plate surrounding ð― ð ę° topic ðė ëíėŽ, ëĻėī ëķíŽė sampling (ėī ðūę°ė í í―)
- 32. LDA ëŠĻëļė ëģė ð ð âē ð : ð― ð âē ð : Document Topic 1 Topic 2 Topic 3 âĶ Topic ðū Document 1 ð1 0.2 0.4 0.0 âĶ 0.1 Document 2 ð2 0.8 0.1 0.0 âĶ 0.0 âĶ âĶ âĶ âĶ âĶ âĶ Document ð ð ð 0.5 0.4 0.1 âĶ 0.0 Terms Topic 1 ð―1 Topic 2 ð―2 Topic 3 ð―3 âĶ Topic ðū ð― ðū Word 1 0.02 0.09 0.00 âĶ 0.00 Word 2 0.08 0.52 0.37 âĶ 0.03 âĶ âĶ âĶ âĶ âĶ âĶ Wordt ð 0.05 0.12 0.01 âĶ 0.45 íĐ : 1 íĐ : 1 - Variant LDA versionė ėŽėĐíęģ ėėžëŊëĄ, ėī versionė LDA ëžęģ ė§ėđ íęē ė
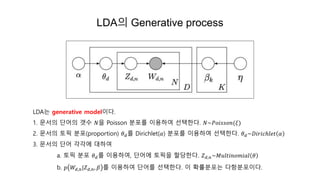
- 33. LDAė Generative process LDAë generative modelėīëĪ. 1. ëŽļėė ëĻėīė ę°Ŋė ðė Poisson ëķíŽëĨž ėīėĐíėŽ ė ííëĪ. ð~ðððð ð ðð(ð) 2. ëŽļėė í í― ëķíŽ(proportion) ð ðëĨž Dirichlet(ðž) ëķíŽëĨž ėīėĐíėŽ ė ííëĪ. ð ð~ð·ððððâðððĄ ðž 3. ëŽļėė ëĻėī ę°ę°ė ëíėŽ a. í í― ëķíŽ ð ðëĨž ėīėĐíėŽ, ëĻėīė í í―ė í ëđíëĪ. ð ð,ð~ððĒððĄððððððð ð b. ð ðð,ð|ð ð,ð, ð― ëĨž ėīėĐíėŽ ëĻėīëĨž ė ííëĪ. ėī íëĨ ëķíŽë ëĪíëķíŽėīëĪ.
- 34. LDAė Generative process ėė ) 1. ėëĄėī ëŽļė ð·ė ęļļėīëĨž 5ëĄ ė ííëĪ. ėĶ, ð· = ðĪ1, ðĪ2, ðĪ3, ðĪ4, ðĪ5 2. ëŽļė ð·ė í í― ëķíŽëĨž 50%ë ėė(food), 50%ë ë뎞(animal)ëĄ ė ííëĪ. 3. ę° ëĻėīė ëíėŽ, 1. ėēŦëēė§ļ ëĻėī ðĪ1ė food topicė í ëđíëĪ. Food topicėė broccoliëĨž ðĪ1ėžëĄ ė ííëĪ. 2. ëëēė§ļ ëĻėī ðĪ2ė animal topicė í ëđíëĪ. Animal topicėė pandaëĨž ðĪ2ėžëĄ ė ííëĪ. 3. ėļëēė§ļ ëĻėī ðĪ3ė animal topicė í ëđíëĪ. Animal topicėė adorable ëĨž ðĪ3ėžëĄ ė ííëĪ. 4. ëĪëēė§ļ ëĻėī ðĪ4ė food topicė í ëđíëĪ. Food topicėė cherries ëĨž ðĪ4ėžëĄ ė ííëĪ. 5. ëĪėŊëēė§ļ ëĻėī ðĪ5ė food topicė í ëđíëĪ. Food topicėė eating ëĨž ðĪ5ėžëĄ ė ííëĪ. ð· : broccoli panda adorable cherries eating
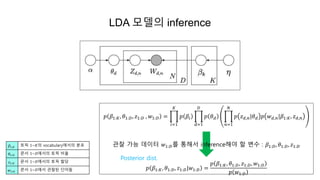
- 35. LDA ëŠĻëļė inference ęīė°° ę°ëĨí ëŽļė ëī ëĻėī ðð,ðëĨž ėīėĐíėŽ, LDA ëŠĻëļė ė ėŽ ëģė(hidden variable)ėļ ëŽļėė í í―ëķíŽ ð ð ė í í―ė ëĻėīëķíŽ ð― ðëĨž ėķė íë ęģžė ėī inferenceėīëĪ. Generative probabilistic modelingėėë, dataë ė ėŽ ëģė(hidden variable)ëĨž íŽíĻíë generative processėėëķí° ë°ėíëęēėžëĄ ëĪëĢŽëĪ. ë°ëžė, generative processë observed random variableęģž hidden random variableė ęē°íĐ íëĨ ë°ë(joint probability distribution)ëĨž ė ėíëĪ. ïŽ Observed variables : ëŽļėëīė ëĻėīëĪ ïŽ Hidden variables : ëŽļėė í í― ëķíŽ, í í―ė ëĻėī ëķíŽ (topic structure) ęē°íĐ íëĨ ë°ëíĻėëĨž ėīėĐíėŽ observed variableėī ėĢžėīėĄė ë hidden variableė ėĄ°ęąīëķ ëķíŽëĨž ęĩŽíëĪ. ėī ëķíŽë ėŽí íëĨ ëķíŽ(posterior distribution)ėīëĪ.
- 36. ð ð―1:ðū, ð1:ð·, ð§1:ð· , ðĪ1:ð· = ð=1 ðū ð ð―ð ð=1 ð· ð ð ð ð=1 ð ð ð§ ð,ð|ð ð ð ðĪ ð,ð|ð―1:ðū, ð§ ð,ð ęīė°° ę°ëĨ ë°ėīí° ðĪ1:ð·ëĨž íĩíīė inferenceíīėž í ëģė : ð―1:ð·, ð1:ð·, ð§1:ð· ð ð―1:ðū, ð1:ð·, ð§1:ð·|ðĪ1:ð· = ð ð―1:ðū, ð1:ð·, ð§1:ð·, ðĪ1:ð· ð ðĪ1:ð· LDA ëŠĻëļė inference ð―1:ðū í í― 1~ðūė vocabularyėėė ëķíŽ ð1:ð· ëŽļė 1~ð·ėėė í í― ëđėĻ ð§1:ð· ëŽļė 1~ð·ėėė í í― í ëđ ðĪ1:ð· ëŽļė 1~ð·ėė ęīė°°ë ëĻėīëĪ Posterior dist.
- 37. LDA ëŠĻëļė inference Posterior distributionė ęĩŽíë ęēė ėŽėīęēėļę°? ëķėė ęē―ė°ëĨž ëĻžė ėīíīëģīė. ð ð―1:ðū, ð1:ð·, ð§1:ð·|ðĪ1:ð· = ð ð―1:ðū, ð1:ð·, ð§1:ð·, ðĪ1:ð· ð ðĪ1:ð· ëŠĻë random variableė ęē°íĐ íëĨ ë°ë íĻėë, hidden variableėī ėėëĄ ė í ëëĪëĐī ė―ęē ęģė° ę°ëĨ
- 38. LDA ëŠĻëļė inference ëķëŠĻė ęē―ė°ëĨž ėīíīëģīė. ð ð―1:ðū, ð1:ð·, ð§1:ð·|ðĪ1:ð· = ð ð―1:ðū, ð1:ð·, ð§1:ð·, ðĪ1:ð· ð ðĪ1:ð· Observed variableė ėĢžëģ ë°ëíĻė(marginal probability) - ėėė topic modelėė, observed corpusëĨž ëģž ė ėė íëĨ ė ęĩŽíë ęē - ëŠĻë hidden topic structureė ę°ëĨí ęē―ė°(instantiation)ëĨž ęĩŽíęģ , ęē°íĐ íëĨ ë°ë íĻėëĨž summation ę°ëĨí hidden topic sturctureë ė§ėė ėžëĄ ë§ëĪ. ë°ëžė íīëđ ë°ëíĻėëĨž ęĩŽíë ęēė ë§Īė° ėīë ĩëĪ. Modern probabilistic models, Bayesian statisticsėėë ëķëŠĻė ëķíŽ ëëŽļė posteriorëĨž ęģė°íë ęēėī ėīë ĩëĪ. ë°ëžė posteriorëĨž íĻęģžė ėžëĄ ėķė íë ęļ°ëēė ëí ė°ęĩŽę° ë§ėī ėīëĢĻėīė§ęģ ėëĪ. ë°ëžė, topic modeling algorithmsėėë posterior distributionė ėķė íęļ° ėí ęļ°ëēė íėĐíëĪ. - sampling based method - variational method
- 39. Difficulty of deriving marginal probability ð ðĪ1:ð· ïŽ Topic mixture ðė joint distribution (parameter : ðž, ð―) ð ð, ðŦ, ðĻ ðž, ð― = ð ð|ðž ð=1 ð ð ð§ ð|ð ð ðĪ ð|ð§ ð, ð― ïŽ Documentė marginal distribution ð ðĻ|ðž, ð― = ð ð|ðž ð=1 ð ð§ ð ð ð§ ð|ð ð ðĪ ð|ð§ ð, ð― ðð ïŽ Corpusė probability ð ð·|ðž, ð― = ð=1 ð ð ð ð|ðž ð=1 ð ð ð§ ðð ð ð§ ðð|ð ð ð ðĪ ðð|ð§ ðð, ð― ðð ð ėŽęļ°ėė notationė Latent Dirichlet Allocation. Blei et. Al (2003)ė ė°ļęģ
- 40. Algorithm for extracting topics Gibbs sampling ð· ðð = ð|ðâð, ðĪð, ðð,â â ðķ ðĪ ð ð ððū + ð ðĪ=1 ð ðķ ðĪð ððū + ðð ðķ ðð ð ð·ðū + ðž ðĄ=1 ðū ðķ ð ð ðĄ ð·ðū + ððž ëŽļėėė ðëēė§ļė ëėĪë ëĻėī ðĪė í í―ėī ðėž íëĨ ė ėíĨė ëŊļėđë ėė - ėė 1 : í í― ðė í ëđë ė ėēī ëĻėī ėĪėė íīëđ ëĻėīė ė ė ėĻėī ëėėëĄ ðėž íëĨ ėī íŽëĪ. - ėė 2 : wðę° ėí ëŽļė ëī ëĪëĨļ ëĻėīę° í í― ðė ë§ėī í ëđëėėėëĄ ðėž íëĨ ėī íŽëĪ. ð§ð = ð ëŽļėėė ðëēė§ļė ëėĪë ëĻėī ðĪė í í― ðę° í ëđ ðŦâð ðëēė§ļ ëĻėīëĨž ė ėļí ëĪëĨļ ëĻėīëĪė ëí í í― í ëđ ðĪð ëĻėī index ðð ëŽļė index â ëĪëĨļ ė ëģī ë° observed information ðķ ðĪð ððū ëĻėī ðĪę° í í― ðė í ëđë íė (íėŽ ðë ė ėļ) ðķ ðð ð·ðū ëŽļė ðė ëĻėīëĪ ėĪėė í í― ðė í ëđë íė (íėŽ ðë ė ėļ) ð í í―ė ëĻėī ëķíŽ ėėąė ėŽėĐëë Dirichlet parameter ðž ëŽļėė í í― ëķíŽ ėėąė ėŽėĐëë Dirichlet parameter Smoothing
- 41. Algorithm for extracting topics Doc 0 : ð§0,0, ð§0,1, ð§0,2, ð§0,3 Doc 1 : (ð§1,0, ð§1,1, ð§1,2) Doc 2 : (ð§2,0, ð§2,1, ð§2,2, ð§2,3) Doc 3 : (ð§3,0, ð§3,1, ð§3,2, ð§3,3, ð§5,4) Doc 4 : (ð§4,0, ð§4,1, ð§4,2, ð§4,3, ð§4,4) Doc 5 : (ð§5,0, ð§5,1, ð§5,2, ð§5,3, ð§5,4, ð§5,5) ėė ) ð§ð,ð : ðëēė§ļ ëŽļėė ð í í―ėī í ëđë ęēė ëíëīë íëĨ ëģė 1. íëĨ ëģėė ëëĪíęē í í―ė í ëđ 2. ð§0,0ė ė ėļí ę°ëĪė í ëëĄ ð§0,0ė ę°ė ė ë°ėīíļ 3. ð§0,1ė ė ėļí ę°ëĪė í ëëĄ ð§0,1ė ę°ė ė ë°ėīíļ âĶ. 4. ð§5,5ė ė ėļí ę°ëĪė í ëëĄ ð§5,5ė ę°ė ė ë°ėīíļ 5. íëĨ ëģėę° ėë īí ëęđė§ ë°ëģĩ
- 42. Algorithm for extracting topics ðķ ððū = ðķ11 ðķ12 âĶ ðķ21 ðķ22 âĶ âĶ âĶ âĶ ðķ1ð âĶ ðķ1ðū ðķ2ð âĶ ðķ2ðū âĶ âĶ âĶ ðķ ðĢ3 ðķ ðĢ3 âĶ âĶ âĶ âĶ ðķ ð1 ðķ ð2 âĶ ðķ ðĢð âĶ ðķ ðĢðū âĶ âĶ âĶ ðķ ðð âĶ ðķ ððū ðķ ð·ðū = ðķ11 ðķ12 âĶ ðķ21 ðķ22 âĶ âĶ âĶ âĶ ðķ1ð âĶ ðķ1ðū ðķ2ð âĶ ðķ2ðū âĶ âĶ âĶ ðķ ð3 ðķ ð3 âĶ âĶ âĶ âĶ ðķ ð·1 ðķ ð·2 âĶ ðķ ðð âĶ ðķ ððū âĶ âĶ âĶ ðķ ð·ð âĶ ðķ ð·ðū
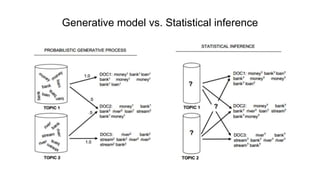
- 43. Generative model vs. Statistical inference
- 44. ėĩė ė í í― ė Perplexity ïŽ Language modelingėė ėĢžëĄ ėŧĻëēĪė ėžëĄ ėŽėĐíëĪ. ïŽ ėžë°ė ėžëĄ perplexityë exp ðŧ ð ëĄ ííëëĪ. ðŧ ð ë ðė ėíļëĄížëĨž ėëŊļíëĪ. ïŽ LDAėė ėķė ë í í― ė ëģīëĨž ėīėĐíėŽ ëĻėīė ë°ė íëĨ ė ęģė°íėė ë, íëĨ ę°ėī ëėėëĄ generative processëĨž ė ëëĄ ėĪëŠ íëĪęģ ëģļëĪ. ðððððððĨððĄðĶ ðķ = exp â ð=1 ð· log ð ðĻ ð ð=1 ð· ðð ïŽ ð ðĻ ð : í í―ė ëĻėīëķíŽ ė ëģīė ëŽļėëī í í―ė ëđėĪ ė ëģīė ęģąė ėīėĐíėŽ ęģė° ïŽ ð ðĻ ð ë íīėëĄ ėĒėžëŊëĄ, perplexityë ėėėëĄ ėĒëĪ.
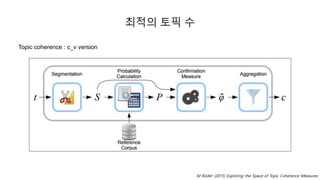
- 45. ėĩė ė í í― ė Topic coherence ïŽ ėĪė ëĄ ėŽëėī íīėíęļ°ė(interpretability) ė íĐí íę° ėēëëĨž ë§ëĪęļ° ėíī ė ėë ėŽëŽ ėēëëĪ ėĪ íë ïŽ Newmanė ëīėĪė ėą ë°ėīí°ëĨž ėė§íėŽ í í― ëŠĻëļë§ė ėĪė. ę·ļ ęē°ęģžëĄ ëėĻ í í―ëĪėī ė ėëŊļíė§ ėėė ėžëĄ ė ėí. ę·ļëĶŽęģ ėīë ęē ë§ĪęēĻė§ ė ėė ę°ėĨ ė ėŽí ęē°ęģžëĨž ëž ė ėë ėēëëĨž ė ė. ïŽ í í― ëŠĻëļë§ ęē°ęģžëĄ ëėĻ ę°ę°ė í í―ėė ėė ðę°ė ëĻėīëĨž ė íí í, ėė ëĻėī ę°ė ė ėŽëëĨž ęģė°íėŽ, ėĪ ė ëĄ íīëđ í í―ėī ėëŊļė ėžëĄ ėžėđíë ëĻėīëĪëžëĶŽ ëŠĻėŽėëė§ íëĻ ę°ëĨ ïŽ ëĪėí ëēė ïŽ NPMI ïŽ UMass ïŽ UCI ïŽ c_v Newman, D., Lau, J. H., Grieser, K., & Baldwin, T. (2010, June). Automatic evaluation of topic coherence. In Human Language Technologies
- 46. ėĩė ė í í― ė Topic coherence : c_v version M RÃķder (2015) Exploring the Space of Topic Coherence Measures
- 47. 1. Axes of a spatial - LSA 2. Probabilistic topics - LDA 3. Bayesian Nonparametric - HDP
- 48. Dirichlet Process LDAë í í―ė ė ðę° íėíëĪ. ë°ėīí°ė ëíėŽ, ėī ë°ėīí°ė ëŠ ę°ė í í―ėī ėĄīėŽíëė§ ëŊļëĶŽ ėë ęēė ėīë ĩëĪ. ėī ëķëķėī LDAė ė―ė ėĪ íëėīëĪ. íė§ë§ ė°ëĶŽë ë°ėīí°ė ë°ëž ė ė í í í― ę°ėëĨž ė°ūė ė ėėžëĐ° ėīęēė Dirichlet ProcessëĨž ėīėĐíėŽ ęĩŽí ė ėëĪ. Dirichlet distributionė ėĢžėīė§ íėīížíëžëŊļí°ė ë°ëž ëĪíëķíŽëĨž ėėąíīėĢžë ëķíŽëžęģ í ė ėëĪ. ë°ëžė ëëĶŽíīë ëķíŽëĨž ėŽė ëķíŽëĄ ëëĐī, ëĪíëķíŽëĨž ë°ëĨīë ėŽííëĨ ëķíŽëĨž ė―ęē ęĩŽí ė ėëĪ. (ëëĶŽíīë ëķíŽ ë ëĪíëķíŽė ėžĪë ëķíŽėīëĪ.)
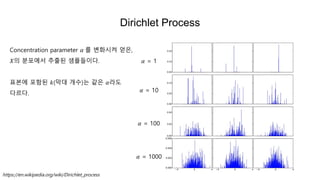
- 49. Dirichlet Process ðę° ëëĶŽíīë ëķíŽëĨž ë°ëĨļëĪęģ ę°ė íė. ėĶ ð~ð·ðð(1,2,1)ëžęģ íė. ėŽęļ°ė ð = 3ėīëĪ. ë°ëžė ėī ëķíŽėė íëģļė ėķėķíëĪëĐī 3ę°ė ėąëķėžëĄë§ ėīëĢĻėīė§, ę·ļëĶŽęģ ėėė íĐėī 1ėļ ėíëĪėī ėėąë ęēėīëĪ. ðĐ1 = 0.2,0.5,0.3 ðĐ2 = 0.1,0.6, 0.3 âĶ ëëĶŽíīë ëķíŽëĨž ėëĄ ëĪëĨļ ðę°ėī ëėŽ ė ėë ëķíŽëĄ íėĨė í ęēėī ëĪėė Dirichlet ProcessėīëĪ. ð~ð·ð ðž, ðŧ ðžë ė§ėĪ íëžëŊļí°(concentration parameter)ėīęģ ðŧë ëŠĻëķíŽėīëĪ. ðžę° 0ė ę°ęđėļėëĄ ðė ëķíŽë ëŠĻëķíŽ ė íę· ė ėĪėŽėžëĄ ëŠĻėīęģ , ðžę° ėŧĪė§ėëĄ ëŠĻëķíŽė íę· ėė ëĐėīė§ęē ëëĪ. YW The Et al.(2005) Hierarchical Dirichlet Processes
- 50. Dirichlet Process ðž = 1 ðž = 10 ðž = 100 ðž = 1000 https://en.wikipedia.org/wiki/Dirichlet_process Concentration parameter ðž ëĨž ëģíėėž ėŧė, ðė ëķíŽėė ėķėķë ėíëĪėīëĪ. íëģļė íŽíĻë ð(ë§ë ę°ė)ë ę°ė ðžëžë ëĪëĨīëĪ.
- 51. Chinese Restaurant Process í ėĪęĩė§ėī ėęģ , ę·ļ ėĪęĩė§ėë ëŽīėí ë§ė ėíėī ėëĪ. ėíėë ëŽīėí ë§ė ėëĶŽę° ėėīė ėëėī ėž ë§ë ė§ ėė ė ėëĪ. ëĻ, ėëėī ėíė ėė ë ėëė ę°ė ę·ėđėī ėëĪ. ïŽ ėëė ėíė ėļęļ°ëëĨž ęģ ë Īíīė ėīë ėíė ėėė§ ė ííëĪ. ïŽ ėíė ėīëĪ ėėėī ėŽë Īė§ė§ë ėíė ėēŦ ėëėī ėė ë ëŠĻëķíŽ ðŧėė ėė íëëĨž ë―ėėžëĄė ęē°ė íëĪ. ïŽ ėíė ėļęļ°ëë ėė ėë ėŽëė ėė ëđëĄíęģ , ėëė ëđėīėë ėíė ęģ ëĨž ė ėëĪ. ëđ ėíė ėļęļ°ëë ė§ ėĪ íëžëŊļí° ðžė ëđëĄíëĪ. ėēŦëēė§ļ ėëė ëđėīėë ėíė ėė ęēėīëĪ. ëëēė§ļ ėëė ėēŦëēė§ļ ėíė ėęą°ë, ëđėīėë ėëĄėī ėíė ėëëĪ. ë§ė― ðžę° íŽëĪëĐī ëđėīėë ėíė ęģ ëĨž íëĨ ėī ëėė§ëĪ. (ëë ėíė ėļęļ°ę° ëŪėë) ėīë ęē ėëėī ëŽīíí ęģė ëĪėīėĪëĪëģīëĐī ėíė ę°ėę° ė íīė§ęģ (countably infinite), ėíė ėļęļ°ë ëđėĻë ėžė ę°ė ėë īíęē ëëĪ. ėīë ęē ėŧė ėļęļ°ëė ëđë ëŠĻëķíŽę° ðŧ, ė§ėĪ íëžëŊļí°ę° ðžėļ ëëĶŽíīë íëĄėļėĪ ėė ë―ė ėíėī ëëĪ.
- 52. Hierarchical Dirichlet Process DPė ė ëĄėŽí : ë§ė― ėĪęĩė§ėī í ęģģėī ėëęģ ėŽëŽęģģėīëžęģ ėę°íė. ėīëĪ ėėėī ėŽë Īė§ ėíė ė°ūėė ę°ę°ė ėĪęĩė§ėė ę·ļ ėėėī ėžë§ë ėļęļ° ėëė§ íėļíęģ ėķëĪęģ íė. ëŽļė ë ėŽęļ°ė ë°ėíëĪ. ę° ėĪęĩ ė§ė ėíėī ëŠ ę° ėëė§ ëŠĻëĨīęģ , ę° ėíė ėīëĪ ėėėī ėëė§ ëŠĻëĨļëĪ. ėīëĪ ėėėī ėëĄ ëĪëĨļ ėëđėė ę°ėī ëąėĨíëĪë ëģīėĨë ėëĪ. ėëđ ę° ėė ëđęĩę° ëķę°ëĨíëĪ. ę·ļëė íėëĪė Hierarchical Dirichlet ProcessëĨž ė ėíëĪ. ðš0~ð·ð ðū, ðŧ ðšð~ð·ð(ðž, ðš0) ëŠĻëķíŽëĨž ë°ëĨīë ėė ëëĶŽíīë íëĄėļėĪëĨž ėėąíęģ , ėī ëëĶŽíīë íëĄėļėĪëĨž ëŠĻëķíŽëĄ íë íė ëëĶŽíī ë íëĄėļėĪëĨž ėŽëŽ ę° ėėąíëĪ. ėīë°ėėžëĄ íė ëëĶŽíīë íëĄėļėĪëĨž ėëĄ ė°ęē° ėėžėĪëĪ.
- 53. Hierarchical Dirichlet Process YW The Et al.(2005) Hierarchical Dirichlet Processes
- 54. CRP using HDP ėĪęĩė§ ėēīėļė ėī ėëĪ. ėēīėļė ėë ëŽīėí ë§ė ėíėī ėęģ , ę·ļ ėíėë ëŽīėí ë§ė ėëĶŽę° ėëĪ. ę° ėēīėļ ė ë§ëĪ ėëėī íëŠ ėĐ ęūļėĪí ëĪėīėė ėíė ęģĻëž ėëëĪ. ę°ę°ė ėēīėļė ė ėėė ë°°ëķíīėĢžë ėĪęĩė§ ëģļ ėŽę° ėëĪ. ę° ėēīėļė ė ėëėī ëđ ėíė ėęē ëëĐī, ė§ėėī ëģļėŽëĄ ę°ė ėíė ėŽëĶī ėėė ęģĻëžėĻëĪ. ëģļ ėŽėë ėėėī ëīęēĻėë ėėĢž í° ė ėę° ëŽīíí ėęģ , ę° ė ėë ėķĐëķí ėŧĪė ëŽīíí ėėė í ė ėëĪ.
- 55. CRP using HDP [ðš0~ð·ð ðū, ðŧ ] ïŽ ė§ėė ė ėė ėļęļ°ëëĨž ęģ ë Īíīė ėīë ė ėėė ėėė íė§ ęē°ė ïŽ ė ėė ėīëĪ ėėėī ėŽë Īė§ė§ë ė ėėė ėēŦ ė§ėėī ėėė í ë, ëŠĻëķíŽ ðŧėė ėėė íë ë―ėėžëĄ ęē°ė ïŽ ė ėė ėļęļ°ëë ėėė íļë ė§ėė ėė ëđëĄíęģ , ė§ėėī ëđėīėë ė ėëĨž ęģ ëĨž ėë ėëĪ. ė ėė ėļęļ°ëë ė§ėĪ íëžëŊļí° ðūė ėęīėëĪ. [ðšð~ð·ð(ðž, ðš0)] ïŽ ėëė ėíė ėļęļ°ëëĨž ęģ ë Īíīė ėīë ėíė ėėė§ëĨž ęģ ëĨļëĪ. ïŽ ėíė ėīëĪ ėėėī ėŽë Īė§ė§ë ėíė ėēŦ ėëėī ėėžëĐī ė§ėė ëģļėŽëĄ ëģīëīė ęē°ė íęģ , ę·ļ ėėė ëķíŽ ėė ė§ėëĪėī ė ėėė ėėė íļë ëķíŽ ðš0ëĨž ë°ëĨļëĪ. (ėíėë 1ę°ė ėėë§ ėŽëžę°ëĪ) ïŽ ėíė ėļęļ°ëë ėė ėë ėŽëė ėė ëđëĄíęģ , ė§ėĪ íëžëŊļí° ðžė ë°ëžė ëđėīėë ėíė ęģ ëĨžėë ėëĪ.
- 56. CRP using HDP YW The Et al.(2005) Hierarchical Dirichlet Processes
- 57. HDP for infinite topic models ïŽ ėĪęĩė§ ėēīėļė â Documents ïŽ ëģļėŽėė ęē°ė íīėĢžë ėė â Topic ïŽ ę°ę°ė ėëëĪ â Words in a document https://www.cs.cmu.edu/~epxing/Class/10708-14/scribe_notes/scribe_note_lecture20.pdf