3. WHAT IS TOPIC MODELING
IN NLP
In Natural Language Processing, the
term ˇ±topicˇ± means a set of words that ˇ°go togetherˇ±.
Topic modelling in natural language processing is a
technique which assigns topic to a given corpus based
on the relevant group of words present in it.
Feature reduction allows us to focus on the relevant
material rather than wasting time sifting through all of the
data's text.
4. WHY IS TOPIC MODELING
IMPORTANT
Topic modelling is important, because in this world full
of data it has become increasingly important to
ˇ°categories the documentsˇ±.
For Example, a company receives hundred of reviews,
then it is important for the company to know what
categories of reviews are more important and vice versa.
5. SUPPOSE:-
There are 1000 documents and each document has 500 words, So to process
this it requires 500*1000 = 500000 threads. So when you divide the document
containing certain topics then if there are 5 topics present in it, the
processing is just 5*500 words = 2500 threads.
? Data will be processed through the following steps:
? Tokenization: Split the text into sentences and the sentences into
words. Lowercase the words and remove punctuation.
? Words that have fewer than 3 characters are removed.
? All stopwords are removed.
? Words are stemmed ˇŞ words are reduced to their base/root form.
? Words are lemmatized ˇŞ reducing words to their base form having
some actual meaning.
6. TOPIC MODELING IS UNSUPERVISED
MACHINE LEARNING ALGORITHMˇ!
Topic modeling is a machine learning technique that
automatically analyzes text data to determine cluster
words for a set of documents.
This is known as 'unsupervised' machine learning
because it doesn't require a predefined list of tags or
training data that's been previously classified by humans
7. TOPIC MODELING
TECHNIQUES
Some of the well known topic modelling
techniques are:
1. Latent Semantic Analysis (LSA)
2. Probabilistic Latent Semantic Analysis (PLSA)
3. Latent Dirichlet Allocation (LDA)
4. Correlated Topic Model (CTM)
8. LATENT DIRICHLET
ALLOCATION (LDA)
LDA, short for Latent Dirichlet Allocation is a technique
used for topic modelling.
? Latent means hidden, something that exists but is
yet to be found.
? Dirichlet indicates that the model ˇ±assumesˇ± that the
topics in the documents and the words in those
topics are relevant to each other.
? Allocation means to giving something, which in this
case are topics.
9. TOPIC EXTRACTION
? The algorithm was first introduced in 2003
and treats topics as probability
distributions for the occurrence of
different words.
? The topics are extracted from the corpus of
words on the basis of probability that a
document may contain a certain word and
there is a probability that such word may
be relevant to some specific topic.
10. TOPIC EXTRACTION
STEPS
Text pre-processing, removing lemmatization,
stop words, and punctuations.
Removing contextually less relevant words.
Perform batch-wise LDA which will provide
topics in batches.
11. MAIN LIBRARIES
? GENSIM: ˇ°Generate Similarˇ± is a popular open source
natural language processing (NLP) library used for
unsupervised topic modeling
? NLTK is a toolkit build for working with NLP in
Python, works with human language data. It provides
us various text processing libraries with a lot of test
datasets.
? ( tokenization, lemmatization, parsing, etc)
? pyLDAvis is an open-source python library that
helps in analyzing and creating highly interactive
visualization of the clusters created by LDA.
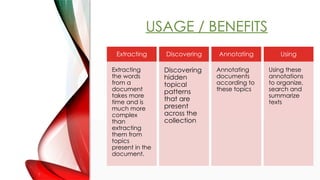
12. USAGE / BENEFITS
Extracting
Extracting
the words
from a
document
takes more
time and is
much more
complex
than
extracting
them from
topics
present in the
document.
Discovering
Discovering
hidden
topical
patterns
that are
present
across the
collection
Annotating
Annotating
documents
according to
these topics
Using
Using these
annotations
to organize,
search and
summarize
texts
13. APPLICATIONS
? Chat Bot
? Questioning/Answering,
? Health Care,
? Recommendation system,
? Similarity detection,
? Sentiment Analysis,
? Text Categorization,
? SEO
14. WHAT IS OCR?
? OCR stands for OPTICAL CHARACTER
RECOGNITION.
? OCR is a technology that analyzes the text of a
page and turns the letters into code that may be
used to process information.
? OCR systems are hardware and software systems
that turn physical documents into machine-
readable text.
15. HOW DOES OCR WORK?
? Image Pre-Processing
? AI Character Recognition
? Post-Processing
16. PRE-PROCESSING
Conversion of the document to digital
form like a picture from its physical form.
The purpose of this stage is for the machine's
representation to be precise while also
removing any undesired aberrations.
17. AI CHARACTER RECOGNITION
AI analyzes the image's dark portions to recognize characters and
numerals. Typically, AI uses one of the following approaches to target one
letter, phrase, or paragraph at a time:
? Pattern Recognition: Technologies use a range of language, text formats,
and handwriting to train the AI system. The program compares the
letters on the detected letter picture to the notes it has already learned
to find matches.
? Feature Recognition: The algorithm uses rules based on specific
character properties to recognize new characters. The amount of angled,
crossing, or curved lines in a letter is one example of a feature.
18. POST PROCESSING
AI corrects flaws in the final file during Post-
Processing. One approach is to teach the AI a
glossary of terms that will appear in the paper.
Then, limit the AI's output to those words/formats
to verify that no interpretations are beyond the
vocabulary.
19. IMPEDIMENTS TO OCR
PERFORMANCE
The image
can be
skewed or
non-
oriented
Colored
and
varying
backgroun
d patterns
Text in
glared or
blurry
images
20. OCR USE CASES BY INDUSTRY
?Banking
?Insurance
?Legal
?Healthcare
?Tourism
?Retail
21. SOME COMPANIES PROVIDING
SERVICES OF OCR
COMPANY AREA OF FOCUS CUSTOMERS TYPES OF SOLUTION
Google Cloud Vision API
Document recognition,
data capture
Chevron, Texas A&M
University
Continuously trained ML
ABBYY FineReader Document recognition,
data capture, language
processing
Dell, Fujitsu, HP, Siemens Continuously trained ML
PDFelement
Document data
extraction
Hitachi, Deloitte Template based
Rossum
Document data
extraction Bloomberg, IBM, Nvidia Continuously trained ML
22. EASYOCR
? EasyOCR was founded by JaidedAI.
? Jaided (pronounce as jai-ded) means "courageous
mind" in Thai.
? Jaided AI was founded in 2020.
? The first project is an open source OCR library
called EasyOCR.
? EasyOCR detects text in 80+ different languages
including: Latin, Chinese, Arabic, Devanagari, Cyrillic, etc.
24. EASYOCR
? Reader class: Base class for EasyOCR
It is used to define what languages the model will
detect, will the model use gpu and many more
useful arguments while downloading.
? readtext method: Main method for reader object
It is used to define how the model will detect the
text like how and in what form the results will be
shown.
26. USING EASYOCR
Detecting Text in Image
import easyocr
reader = easyocr.Reader(['ch_tra', 'en'])
result = reader.readtext('chinese_tra.jpg')
[([[448, 111], [917, 111], [917, 243], [448, 243]],' ¸ß čF ×ó I
Őľ ',0.9247),
([[454, 214], [629, 214], [629, 290], [454, 290]], 'HSR', 0.9931)]
img = cv2.imread('chinese_tra.jpg')
result = reader.readtext(img)
27. USING EASYOCR
The standard output may look too complicated for
many, you can get simple output by passing
optional argument detail like this
reader.readtext('chinese_tra.jpg', detail = 0). And
this is what you will get.
[' ¸ßčF×ó IŐľ ', 'HSR', 'Station', ' Ćű܇ĹRÍŁ˝ÓËÍ
…^ ', 'Kiss', 'Car', 'and', 'Ride']
28. USING EASYOCR
PARAGRAPH PARAMETER
Another useful optional argument for readtext function is
paragraph. By setting paragraph=True, EasyOCR will try to
combine raw result into easy-to-read paragraph. Here is the
result with reader.readtext('chinese_tra.jpg', detail = 0,
paragraph=True).
[' ¸ßčF×ó IŐľ HSR Station Ćű܇ĹRÍŁ˝ÓËÍ…^ Car Kiss and
Ride']
























![USING EASYOCR
Detecting Text in Image
import easyocr
reader = easyocr.Reader(['ch_tra', 'en'])
result = reader.readtext('chinese_tra.jpg')
[([[448, 111], [917, 111], [917, 243], [448, 243]],' ¸ß čF ×ó I
Őľ ',0.9247),
([[454, 214], [629, 214], [629, 290], [454, 290]], 'HSR', 0.9931)]
img = cv2.imread('chinese_tra.jpg')
result = reader.readtext(img)](https://image.slidesharecdn.com/topicmodelinginnlpeasyocr-250313093153-277bca77/85/TOPIC__MODELING_IN_NLP__-__EasyOCR-pptx-26-320.jpg)
![USING EASYOCR
The standard output may look too complicated for
many, you can get simple output by passing
optional argument detail like this
reader.readtext('chinese_tra.jpg', detail = 0). And
this is what you will get.
[' ¸ßčF×ó IŐľ ', 'HSR', 'Station', ' Ćű܇ĹRÍŁ˝ÓËÍ
…^ ', 'Kiss', 'Car', 'and', 'Ride']](https://image.slidesharecdn.com/topicmodelinginnlpeasyocr-250313093153-277bca77/85/TOPIC__MODELING_IN_NLP__-__EasyOCR-pptx-27-320.jpg)
![USING EASYOCR
PARAGRAPH PARAMETER
Another useful optional argument for readtext function is
paragraph. By setting paragraph=True, EasyOCR will try to
combine raw result into easy-to-read paragraph. Here is the
result with reader.readtext('chinese_tra.jpg', detail = 0,
paragraph=True).
[' ¸ßčF×ó IŐľ HSR Station Ćű܇ĹRÍŁ˝ÓËÍ…^ Car Kiss and
Ride']](https://image.slidesharecdn.com/topicmodelinginnlpeasyocr-250313093153-277bca77/85/TOPIC__MODELING_IN_NLP__-__EasyOCR-pptx-28-320.jpg)

