Tutorial on EM algorithm - Poster

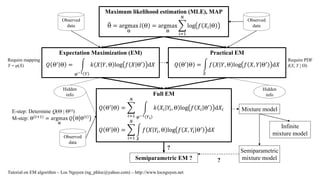
Maximum likelihood estimation (MLE) is a popular method for parameter estimation in both applied probability and statistics but MLE cannot solve the problem of incomplete data or hidden data because it is impossible to maximize likelihood function from hidden data. Expectation maximum (EM) algorithm is a powerful mathematical tool for solving this problem if there is a relationship between hidden data and observed data. Such hinting relationship is specified by a mapping from hidden data to observed data or by a joint probability between hidden data and observed data (showing MLE, EM, and practical EM, hidden info implies the hinting relationship). The essential ideology of EM is to maximize the expectation of likelihood function over observed data based on the hinting relationship instead of maximizing directly the likelihood function of hidden data (showing the full EM with proof along with two steps). An important application of EM is (finite) mixture model which in turn is developed towards two trends such as infinite mixture model and semiparametric mixture model. Especially, in semiparametric mixture model, component probabilistic density functions are not parameterized. Semiparametric mixture model is interesting and potential for other applications where probabilistic components are not easy to be specified (showing mixture models). I raise a question that whether it is possible to backward discover semiparametric EM from semiparametric mixture model. I hope that this question will open a new trend or new extension for EM algorithm (showing the question).


Tutorial on EM algorithm - Poster
- 1. Presentation ŌĆó Maximum likelihood estimation (MLE) is a popular method for parameter estimation in both applied probability and statistics but MLE cannot solve the problem of incomplete data or hidden data because it is impossible to maximize likelihood function from hidden data. Expectation maximum (EM) algorithm is a powerful mathematical tool for solving this problem if there is a relationship between hidden data and observed data. Such hinting relationship is specified by a mapping from hidden data to observed data or by a joint probability between hidden data and observed data (showing MLE, EM, and practical EM, hidden info implies the hinting relationship). ŌĆó The essential ideology of EM is to maximize the expectation of likelihood function over observed data based on the hinting relationship instead of maximizing directly the likelihood function of hidden data (showing the full EM with proof along with two steps). ŌĆó An important application of EM is (finite) mixture model which in turn is developed towards two trends such as infinite mixture model and semiparametric mixture model. Especially, in semiparametric mixture model, component probabilistic density functions are not parameterized. Semiparametric mixture model is interesting and potential for other applications where probabilistic components are not easy to be specified (showing mixture models). ŌĆó I raise a question that whether it is possible to backward discover semiparametric EM from semiparametric mixture model. I hope that this question will open a new trend or new extension for EM algorithm (showing the question).
- 2. Maximum likelihood estimation (MLE), MAP ╬ś = argmax ╬ś ØæÖ ╬ś = argmax ╬ś Øæ¢=1 Øæü log Øæō ØæŗØæ¢ ╬ś Expectation Maximization (EM) Øæä ╬śŌĆ▓ ╬ś = Ø£æŌłÆ1 Øæī Øæś Øæŗ Øæī, ╬ś log Øæō Øæŗ ╬śŌĆ▓ dØæŗ Practical EM Øæä ╬śŌĆ▓ ╬ś = Øæŗ Øæō Øæŗ Øæī, ╬ś log Øæō Øæŗ, Øæī ╬śŌĆ▓ dØæŗ Full EM Øæä ╬śŌĆ▓ ╬ś = Øæ¢=1 Øæü Ø£æŌłÆ1 ØæīØæ¢ Øæś ØæŗØæ¢ ØæīØæ¢, ╬ś log Øæō ØæŗØæ¢ ╬śŌĆ▓ dØæŗØæ¢ Øæä ╬śŌĆ▓ ╬ś = Øæ¢=1 Øæü Øæŗ Øæō Øæŗ ØæīØæ¢, ╬ś log Øæō Øæŗ, ØæīØæ¢ ╬śŌĆ▓ dØæŗ Observed data Observed data Observed data Mixture model Semiparametric EM ? ? E-step: Determine Q(╬ś | ╬ś(t)) M-step: ╬ś ØæĪ+1 = argmax ╬ś Øæä ╬ś ╬ś ØæĪ Require mapping Y = Žå(X) Require PDF f(X, Y | Ž┤) ? Tutorial on EM algorithm ŌĆō Loc Nguyen (ng_phloc@yahoo.com) ŌĆō http://www.locnguyen.net Semiparametric mixture model Infinite mixture model Hidden info Hidden info
- 3. Thank you for attention 3 Conditional mixture model for modeling attributed dyadic data 16/09/2021
Editor's Notes
- #3: Maximum likelihood estimation (MLE) is a popular method for parameter estimation in both applied probability and statistics but MLE cannot solve the problem of incomplete data or hidden data because it is impossible to maximize likelihood function from hidden data. Expectation maximization (EM) algorithm is a powerful mathematical tool for solving this problem if there is a relationship between hidden data and observed data. Such hinting relationship is specified by a mapping from hidden data to observed data or by a joint probability between hidden data and observed data (showing MLE, EM, and practical EM, hidden info implies the hinting relationship). The essential ideology of EM is to maximize the expectation of likelihood function over observed data based on the hinting relationship instead of maximizing directly the likelihood function of hidden data (showing the full EM with proof along with two steps). An important application of EM is (finite) mixture model which in turn is developed towards two trends such as infinite mixture model and semiparametric mixture model. Especially, in semiparametric mixture model, component probabilistic density functions are not parameterized. Semiparametric mixture model is interesting and potential for other applications where probabilistic components are not easy to be specified (showing mixture models). I raise a question that whether it is possible to backward discover semiparametric EM from semiparametric mixture model. I hope that this question will open a new trend or new extension for EM algorithm (showing the question).