°æ¬€Œƒ…ÐΩÈ°ø±´-≥“¥°∞’-±ı∞’
?
1 like?3,869 views

•¢•´•¶•Û•»üopdf DL: https://speakerdeck.com/meow_noisy/u-gat-it selfie2anime§Œ’쌃§«§π°£ LPIXEL§µ§Û§Œ’쌃LTª·§À§œ°¢“ª∂»§œ∞k±Ì’þ§»§∑§∆≤Œº”§∑§ø§´§√§ø§Œ§«°¢¥Ûâ‰π‚ñ—§«§∑§ø°£ 2019ƒÍ11‘¬13»’(ÀÆ)§ÀLPIXEL§µ§Û§Œ’쌃LTª·#8§«∞k±Ì§∑§øŸY¡œ§«§π°£ https://lpixel.connpass.com/event/154432/






















![[ljøº] •‚•«•Î—ß¡ï
? $ python main.py [opt] -®Cdataset <dataset_name>
? ∂ý∑÷°¢GPU•·•‚•Í§¨◊„§Í§ §§§œ§∫
? Õ®≥£•‚•«•Î§ŒœÎ∂®GPU•π•⁄•√•Ø§œV100 32GB
? light∞Ê•‚•«•Î§ÿâ‰∏¸
? --light•™•◊•∑•Á•Û§Ú◊∑º”
? •‚•«•Î§ŒœÎ∂®GPU•π•⁄•√•Ø§œ1080Ti 11GB
? §Ω§Ï§Ë§Í§™ ÷≥÷§¡§ŒGPU•·•‚•Í§¨…Ÿ§ §§àˆ∫œ§œ°¢1唧¢§ø
§Í§Œ•¡•„•Õ•Î§Úœ˜úp§π§Î
? ---ch <int>•™•◊•∑•Á•Û§Ú◊∑º”
? <int>§À§œ64“‘œ¬§Ú‘O∂®](https://image.slidesharecdn.com/20191121safe-191120215223/85/U-GAT-IT-24-320.jpg)
°æ¬€Œƒ…ÐΩÈ°ø±´-≥“¥°∞’-±ı∞’
- 1. U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation °æª≠œÒÑI¿Ì & ôC–µ—ß¡ï°ø’쌃LTª·£° #8@LPIXEL meow (id: meow_noisy) 2019/11/21(ƒæ)
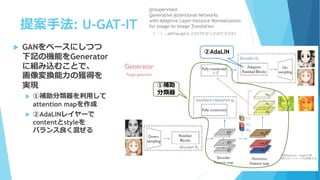
- 2. ’쌃∏≈“™ ? ª≠œÒâ‰ìQ•ø•π•Ø§À§™§§§∆°¢ðÜπ˘§¨¥Û§≠§Ø≧ԧΕø©`•≤•√•» §ÿ§Œâ‰ìQ§ÚΩÃéü§ §∑§«´@µ√§π§Î ÷∑®§ŒÃ·∞∏ ? ÷∑®§ŒÃÿè’ 1. CAM•È•§•Ø§ —a÷˙∑÷Óê∆˜§Œå߻ΧÀ§Ë§Íattention map§Ú◊˜≥… 2. AdaLIN§À§Ë§Ícontent§»style§Ú§¡§Á§¶§…¡º§ØªÏ§º§∆’˝“éªØ ? ÷¯’þ ? Junho Kim ?, Minjae Kim ?, Hyeonwoo Kang ?, Kwanghee Lee? ? ? NCSOFT, ? Boeing Korea Engineering and Technology Center ? —ߪ·«ÈàÛ: § §∑ ? URL: https://arxiv.org/abs/1907.10830
- 3. ±≥æ∞ ? ª≠œÒâ‰ìQ•ø•π•Ø§À§™§§§∆§œ°¢æ÷À˘µƒ§ •∆•Ø•π•¡•„§Œâ‰ìQ§œ ƒø“ô§Þ§∑§§≥…π¶§ÚÖߧ·§ø ? –¥’Ê?•¥•√•€§ŒΩ}ª≠ ? ÒR?•∑•Þ•¶•Þ ? §∑§´§∑°¢–Œ§¨§Ω§‚§Ω§‚≧ԧ√§∆§§§Î§‚§Œ§ÿâ‰ìQ§π§Î§≥§»§œÎy§∑§§ ? √®?»Æ ? ÓÜ–¥’Ê?•¢•À•·
- 4. ÷∞∏ ÷∑®: U-GAT-IT ? GAN§Ú•Ÿ©`•π§À§∑§ƒ§ƒ œ¬”õ§ŒôCƒÐ§ÚGenerator §ÀΩM§þÞz§ý§≥§»§«°¢ ª≠œÒâ‰ìQƒÐ¡¶§Œ´@µ√§Ú åg¨F ? ¢Ÿ—a÷˙∑÷Óê∆˜§Ú¿˚”√§∑§∆ attention map§Ú◊˜≥… ? ¢⁄AdaLIN•Ï•§•‰©`§« content§»style§Ú •–•È•Û•π¡º§ØªÏ§º§Î ¢Ÿ—a÷˙ ∑÷Óê∆˜ ¢⁄AdaLIN °˘á̧œsource°˙target§Œ¿˝ (ƒÊ§Œ•Õ•√•»•Ô©`•Ø§‚”√“‚§π§Î) Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation £®?-`£©.?oO(You got it.§»§´§±§ø§´§√§ø§Œ§¿§Ì§¶§´)
- 5. CAM•È•§•Ø§ —a÷˙∑÷Óê∆˜ ? CAM(Class Activation Map) ? CNN§Œ≈–∂œ∏˘í᧌ø…“ïªØ ÷∑®§Œ§“§»§ƒ ? Ãÿè’•Þ•√•◊§»softmax§ÿ§Œ÷ÿ§þ§ÚæÄ–ŒΩY∫œ§∑Activation Map§Ú◊˜≥… auxiliary classifier á̧œ‘™’쌃§Ë§Í: https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Zhou_Learning_Deep_Features_CVPR_2016_paper.pdf
- 6. CAM•È•§•Ø§ —a÷˙∑÷Óê∆˜(p.3) auxiliary classifier ? —a÷˙∑÷Óê∆˜? ? ? »Î¡¶§µ§Ï§øª≠œÒ§¨source§´§È¿¥§ø¥_¬ §Ú≥ˆ¡¶ §π§Î∂˛Çé∑÷Óê∆˜ ? Ãÿè’•Þ•√•◊§ŒGlobal Avg Pooling, Global Max Pooling§ÚΩY∫œ§∑§ø§‚§Œ»Î¡¶ ? Encoder§´§È≥ˆ¡¶§µ§Ï§øÃÿè’•Þ•√•◊§Œ÷ÿ§þ§« CAM§Ú◊˜≥… °˘á̧œsource°˙target§Œ¿˝ (ƒÊ§Œ•Õ•√•»•Ô©`•Ø§‚”√“‚§π§Î) ?
- 7. —a÷˙∑÷Óê∆˜§ŒÑøπ˚(p.5 Fig 2) ? §¢§Í/§ §∑§«Óá÷¯§ Ñøπ˚§¨§¢§Î (‘™ª≠œÒ) §¢§Í § §∑
- 8. CAM•È•§•Ø§ —a÷˙∑÷Óê∆˜(p.3) auxiliary classifier ? CAM§Úattention map§»§π§Î ? ¿˝§®§–°¢? ? = ? ? ? ? ? ? attention§Ú»´ΩY∫œå”§À¡˜§∑°¢··∂Œ§ŒAdaLIN§« 𧶠•¢•’•£•Û•—•È•·©`•ø¶√°¢¶¬§ÚÕ∆∂® °˘á̧œsource°˙target§Œ¿˝ (ƒÊ§Œ•Õ•√•»•Ô©`•Ø§‚”√“‚§π§Î)
- 10. AdaLIN: Adaptive Layer-Instance Normalization ? Decoder§ŒRes Block§À§™§§§∆AdaLIN•Ï•§•‰©`§Ú–Ƨý ? ÑI¿Ìƒ⁄»ð: attention map§Àåù§∑§∆°¢Instance Normalization(IN) §»Layer Normalization(LN)§ŒªÏ∫œ∫Õ§Ú”ãÀ„ ? IN: •¡•„•Õ•ÎÖgŒª§«’˝“éªØ ? LN: •Ï•§•‰©`(§π§Ÿ§∆§ŒÃÿè’•Þ•√•◊)ÖgŒª§«’˝“éªØ (p.3)
- 11. AdaLIN§ŒÑøπ˚(p.6; Fig.4) ? •π•ø•§•Îâ‰ìQ•ø•π•Ø§«Ã·∞∏§µ§Ï§øNormalize ÷∑®§Ú±»ð^ ? IN§œ•ø©`•≤•√•»•…•·•§•Û(anime)§Œ«ÈàÛ§¨…Ÿ§ §Ø°¢LN§œ•Ω©`•π•…•·•§•Û (selfie)§Œ«ÈàÛ§¨…Ÿ§ §§°£§∑§ø§¨§√§∆°¢’€÷‘§π§Î§»…œ ÷§Ø§§§Ø ? AdaIN§œcontent(selfie?)§Œ•—•ø©`•Û§¨…Ÿ§ §§§È§∑§§(p.3,col.2,l.16) (‘™ª≠œÒ) AdaLIN IN LN AdaIN GN p.7 Tab.1 ∂®¡ø‘uÅ˝(–°§µ§§§€§…¡º§§)§«§‚◊Ó¡º
- 12. ågÚY(p.5) ? ±»ð^ ÷∑® ? U-GAT-IT§Ú∫¨§ý5§ƒ§Œª≠œÒâ‰ìQ ÷∑® ? •«©`•ø•ª•√•» ? selfie?anime§Ú∫¨§ý5§ƒ§Œ•«©`•ø•ª•√•» ? ‘uÅ˝≥þ∂» ? ∂®–‘‘uÅ˝: •Ê©`•∂©`•∆•π•»(n=135) ? â‰ìQ«∞··§Œª≠œÒ§»°¢â‰ìQœ»§Œ•…•·•§•Û§Œ§þ§ÚΩç®°¢ •Ÿ•π•»§¿§»Àº§¶ª≠œÒ§Úþx§Û§«§‚§È§¶ ? ∂®¡ø‘uÅ˝: KID(Kernel Inception Distance) ? FID§Ë§Í–≈Óm§«§≠§Î§È§∑§§(p.7; 5.3.4Ìó)
- 13. ∂®–‘‘uÅ˝§ŒΩYπ˚(p.8 Tab.2) ? 4§ƒ§Œ•«©`•ø•ª•√•»§«Ã·∞∏ ÷∑®§¨◊Ó¡º ‘™ª≠œÒ ÷∞∏ CycleGAN UNIT MUNIT DRIT photo2portrait dataset
- 14. ∂®¡ø‘uÅ˝§ŒΩYπ˚(p.8 Tab.3) ? KID§«úy§Î°£–°§µ§§§€§…¡º§§°£ ? 3§ƒ§Œ•«©`•ø•ª•√•»§«Ã·∞∏ ÷∑®§¨◊Ó¡º ? À˚2§ƒ§«¡”§Î§¨°¢•»•√•◊§»§Œ≤Ó§œŒ¢°©§ø§Î§‚§Œ§»÷˜èà
- 16. ÇÄ»Àµƒ§ “…Üñ ? ’˝“éªØ§«ª≠œÒ§ŒŸ|§¨§ §º•≥•Û•»•Ì©`•Î§«§≠§Î§Œ§´§Ô§´§√§∆§§ § §§ ? ’˝“éªØ§π§ÎÖgŒª§Œþ`§§§«§Ω§Û§ §Àcontent§»style§Œ«ÈàÛ§¨â‰ªØ§π§Î? (‘™ª≠œÒ) AdaLIN IN LN AdaIN GN
- 17. ≤ŒøºŒƒœ◊ 1. •À•Â©`•È•Î•Õ•√•»•Ô©`•Ø§«Style Transfer§Ú––§¶’쌃§ŒΩB ΩÈ ? https://qiita.com/kidach1/items/0e7af5981e39955f33d6 2. Class activation mapping§Ú”√§§§øCNN§Œø…“ïªØ ? https://qiita.com/KDOG08/items/74ef0a342f100bf0c5d5
- 20. §π§∞§À‘á§∑§ø§§∑ΩœÚ§± ? ”–÷槌»À§¨•Í•Í©`•π§∑§øWebApp∞ʧ¨¥Ê‘⁄ ? https://selfie2anime.com/ ? •–•√•Ø•®•Û•…§À±´-≥“¥°∞’-±ı∞’§Ú π”√§∑§∆§§§Î
- 21. π´ Ω•Í•ð•∏•»•Í§Œclone ? π´ Ω§ŒTF∞Êrepo§Úclone ? https://github.com/taki0112/UGATIT ? readme.md§À”õðd§µ§Ï§∆§§§Îselfie2anime dataset§Ú•¿•¶•Û•Ì©`•… ? readme.md§À”õðd§µ§Ï§∆§§§Îpretrained model§Ú•¿•¶•Û•Ì©`•… ? °˘π´ Ω§ŒPyTorch∞Êrepo§‚§¢§Î§¨°¢pretrained model§¨Ã· 𩧵§Ï§∆§§§ §§ ? https://github.com/znxlwm/UGATIT-pytorch ? pytorch∞ʧŒissue§ÀTF§Œ•‚•«•Î§Úπ´È_§∑§∆§§§Î»À§‚§§§∆§‰§‰§≥§∑§§
- 22. •«©`•ø ? •«©`•ø•ª•√•» ? dataset•«•£•Ï•Ø•»•Í§À≈‰÷√ ? trainA,trainB,testA,testB§»§§§¶•«•£•Ï•Ø•»•Í√˚§œπÃ∂® ? testA§Àselfie§Ú»Î§Ï§Ï§–§§§§ ? ª≠œÒ•’•°•§•Î√˚§Œíàèà◊”§‰√˚«∞§œöð§À§∑§ §Ø§∆§§§§ ? °˘ selfie2anime dataset§œanimeÇ»(trainB, testB)§¨ jpg§¿§¨ågëB§œpng ? pretrained model ? repo§Œ•Î©`•»§À¬‰§»§∑§∆§≠§øzip•’•°•§•Î§Ú’πÈ_ ? checkpoint•«•£•Ï•Ø•»•Í§¨§«§≠§Î§œ§∫ ? §¢§»§œ∫Œ§‚§§§∏§È§ §Ø§∆§§§§
- 23. Õ∆’ì ? python main.py --dataset <dataset_name> --phase test ? repo•Î©`•»œ¬§Àresults•«•£•Ï•Ø•»•Í§¨§«§≠°¢§Ω§Œ÷–§Àâ‰ìQ ··§Œhtml•’•°•§•Î§»ª≠œÒ§¨§«§≠§∆§§§Î
- 24. [ljøº] •‚•«•Î—ß¡ï ? $ python main.py [opt] -®Cdataset <dataset_name> ? ∂ý∑÷°¢GPU•·•‚•Í§¨◊„§Í§ §§§œ§∫ ? Õ®≥£•‚•«•Î§ŒœÎ∂®GPU•π•⁄•√•Ø§œV100 32GB ? light∞Ê•‚•«•Î§ÿâ‰∏¸ ? --light•™•◊•∑•Á•Û§Ú◊∑º” ? •‚•«•Î§ŒœÎ∂®GPU•π•⁄•√•Ø§œ1080Ti 11GB ? §Ω§Ï§Ë§Í§™ ÷≥÷§¡§ŒGPU•·•‚•Í§¨…Ÿ§ §§àˆ∫œ§œ°¢1唧¢§ø §Í§Œ•¡•„•Õ•Î§Úœ˜úp§π§Î ? ---ch <int>•™•◊•∑•Á•Û§Ú◊∑º” ? <int>§À§œ64“‘œ¬§Ú‘O∂®