ل„€ل…،ل†¼ل„’ل…ھل„’ل…،ل†¨ل„‰ل…³ل†¸ & Unity ML Agents
•Download as PPTX, PDF•
0 likes•128 views

대ى¶©ëŒ€ى¶© 공부ي•œ ë‚´ىڑ©ى„ ى •ë¦¬ي•کى—¬ ىک¬ë¦¼. Unity ML Agentsëٹ” ي•„ىڑ”ي•œ 분 ىˆى„ ى‹œ ى•Œë ¤ى£¼ى‹œë©´ ى‚¬ىڑ©ي•œ ê³¼ى •ى„ ى¢€ ëچ” ى •ë¦¬ي•´ë³´ê² ىŒ. A2Cى™€ PPO를 ى´ي•´ي•ک기 ىœ„ي•´ ى°¸ ë§ژى€ ë‚´ىڑ©ى„ ى´ي•´ي•´ى•¼ ي•¨ى„ ى•Œê²Œ ëگکى—ˆىŒ


















ل„€ل…،ل†¼ل„’ل…ھل„’ل…،ل†¨ل„‰ل…³ل†¸ & Unity ML Agents
- 1. ê°•ي™”ي•™ىٹµ & Unity ML Agents
- 2. https://youtu.be/KjWF8VIMGiY ى´ ë°œي‘œ ى£¼ى œىک ى‹œى‘ى€ ى¶”ى²œ ىکپىƒپ 때문ى´ى—ˆë‹¤ê³ ي•œë‹¤.
- 3. TROPى™€ PPOىک ê°œë…گى´ 무ى—‡ى¸ى§€ ى–´ë ´ي’‹ي•ک게 ى ‘ي•œ ى²« ى¸ىƒپى€?
- 4. ى™„ë²½يˆ ى´ي•´ي•œ ë°œي‘œىگى—گ게 ىگىœ ë،게 ى§ˆë¬¸
- 5. ى´ë²ˆ ë°œي‘œëٹ” 마ى¹ک ى—¬ي–‰ى„ ë– ë‚ ë•Œ ë°–ىک ê²½ى¹ک를 보듯ى´ Reinforcement Learning ىک ê°œë…گ들ى„ ي›‘ى–´ë³¸ë‹¤ëٹ” ëٹگë‚Œىœ¼ë،œ ë´گى£¼ى‹œë©´ ê°گى‚¬ي•کê² ىٹµë‹ˆë‹¤. ىک¤ëٹک ىڑ°ë¦¬ê°€ ى—¬ي–‰ي• ëھ…ى†Œë“¤ Policy Value Model-based On-Policy vs Off-Policy … Proximal Policy Optimization Algorithm (PPO)
- 6. ê°•ي™”ي•™ىٹµ • ىˆœى°¨ى پى¸ ىکى‚¬ê²°ى • 문ى œë¥¼ ي•´ê²°ي•کëٹ” 방법
- 7. Unity ML Agents ىکˆى œë¶€ي„° • Python 3.9.16 • Unity 2020.3.25f1 • Unity ml-agents repoىک release_19 branch • https://github.com/Unity-Technologies/ml-agents.git
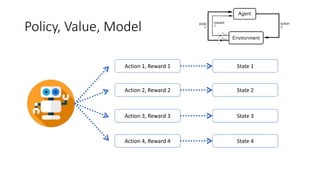
- 9. Policy, Value, Model Action 1, Reward 1 Action 2, Reward 2 Action 3, Reward 3 Action 4, Reward 4 State 1 State 2 State 3 State 4
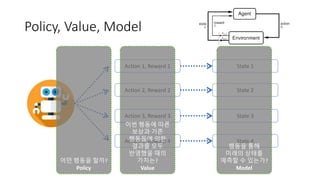
- 10. Policy, Value, Model Action 1, Reward 1 Action 2, Reward 2 Action 3, Reward 3 Action 4, Reward 4 State 1 State 2 State 3 State 4 ى–´ë–¤ ي–‰ëڈ™ى„ ي• 까? Policy ى´ë²ˆ ي–‰ëڈ™ى—گ 따른 ë³´ىƒپê³¼ 기ى،´ ي–‰ëڈ™ë“¤ى—گ ىکي•œ 결과를 ëھ¨ë‘گ ë°کىکپي–ˆى„ ë•Œىک ê°€ى¹کëٹ”? Value ي–‰ëڈ™ى„ ي†µي•´ 미ëکىک ىƒپيƒœë¥¼ ىکˆى¸،ي• ىˆک ىˆëٹ”ê°€? Model
- 11. 1. Policy 기ë°ک 방법ë، • REINFORCE • Neural Network 기ë°ک • ى…ë ¥: يک„ى¬ ىƒپيƒœ (State) • ى¶œë ¥: ي–‰ëڈ™ (Action) 1. Policy 기ë°ک 방법ë،
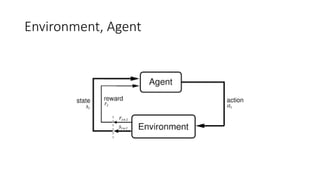
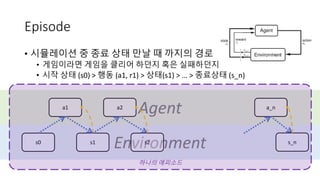
- 12. Environment Agent Episode • ى‹œë®¬ë ˆى´ى…ک ى¤‘ ى¢…료 ىƒپيƒœ ë§Œë‚ ë•Œ 까ى§€ىک ê²½ë،œ • 게ى„ى´ë¼ë©´ 게ى„ى„ يپ´ë¦¬ى–´ ي•کëچکى§€ يک¹ى€ ى‹¤يŒ¨ي•کëچکى§€ • ى‹œى‘ ىƒپيƒœ (s0) > ي–‰ëڈ™ (a1, r1) > ىƒپيƒœ(s1) > … > ى¢…료ىƒپيƒœ (s_n) s0 a1 s1 s2 a2 a_n s_n ي•کë‚کىک ى—گي”¼ى†Œë“œ
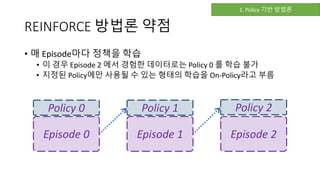
- 13. REINFORCE 방법ë، ى•½ى گ • 매 Episode마다 ى •ى±…ى„ ي•™ىٹµ • ى´ ê²½ىڑ° Episode 2 ى—گى„œ ê²½ي—کي•œ ëچ°ى´ي„°ë،œëٹ” Policy 0 를 ي•™ىٹµ 불가 • ى§€ى •ëگœ Policyى—گ만 ى‚¬ىڑ©ëگ ىˆک ىˆëٹ” يک•يƒœىک ي•™ىٹµى„ On-Policyë¼ê³ 부름 Episode 0 Policy 0 Policy 1 Episode 1 Policy 2 Episode 2 1. Policy 기ë°ک 방법ë،
- 14. 2. Value 기ë°ک 방법ë، • Q-Learning • (State, Action) ى،°ي•©ى—گ 대ي•œ ê°€ى¹کىک 기대 ê°’ى„ 계ى‚°ي•´ë‘گىگ. • يک„금يگ름ي• ى¸ë²•(DCF)ى™€ ىœ ى‚¬ي•œ ê°œë…گ • 미ëکى—گ ىˆى„ ë³´ىƒپ(reward)ى—گ ي• ى¸ىœ¨ى„ ى پىڑ© • ى—¬ëں¬ 방법ى´ ىˆىŒ • يک„대ىک Classic: Markov Decision Process (MDP) • يک„대ىک Modern: Deep Q-Learning (DQL) • Value 기ë°کىک يٹ¹ى§• • Rewardê°€ ë°œىƒي•œ Stateê°€ ىˆى„ ê²½ىڑ° ى¸ى ‘ي•œ Stateى—گ ي•´ë‹¹ ê°’ى´ ى „يŒŒ • ي•™ىٹµ ى‹œ يک„ى¬ ىƒپيƒœىک Q-Valueëٹ” 다ىŒى—گ ëڈ„달ي•œ ىƒپيƒœىک Value를 ê°€ى ¸ى™€ discount ي›„ ë°کىکپي•ک기ى—گ ë°”ë،œ ى¸ى ‘ي•œ ىƒپيƒœى—گ 대ي•´ى„œë§Œ ê°€ى¹ک ى „달 ê°€ëٹ¥ • ى´ë¥¼ temporal difference ي•™ىٹµى´ë¼ 부름 • ىگى„¸ي•œ ى„¤ëھ…ى€ 다ىŒ ىٹ¬ë¼ى´ë“œىک ë‚´ىڑ© ى°¸ى،° 2. Value 기ë°ک 방법ë،
- 15. Q-Learning (MDP) /hyunjonglees/qlearning-257058513 2. Value 기ë°ک 방법ë،
- 16. 2. Value 기ë°ک 방법ë، • Deep Q-Learning (DQN) • Deep Neural Network 기ë°ک • ى…ë ¥: يک„ى¬ ىƒپيƒœ ë°ڈ ي–‰ëڈ™ (State, Action) • ى¶œë ¥: ê·¸ ىƒپيƒœى™€ ي–‰ëڈ™ى—گى„œىک ê°€ى¹ک (Value) • ê·¸ëکى„œ ي•™ىٹµى´ ى™„료ëگکë©´ يٹ¹ى • Stateى—گى„œ ي–‰ي• ىˆک ىˆëٹ” ëھ¨ë“ Action ى¤‘ ê°€ى¹ک를 ىµœëŒ€ي™” ي• ىˆک ىˆëٹ” ي–‰ëڈ™ ى„ يƒ • يٹ¹ى§• • Off-Policy • ë”°ë¼ى„œ ëھ¨ë“ Episodeىک ëچ°ى´ي„°ë¥¼ ي•™ىٹµى—گ ي™œىڑ© ê°€ëٹ¥ • DQNى—گى„œ Episodeىک ëچ°ى´ي„°ê°€ On-Policyىک ى œى•½ى´ 걸리ى§€ ى•ٹëڈ„ë، ى„¤ê³„ • Experience Replay memory • Off-Policy를 ىœ„ي•´ Episode ëچ°ى´ي„°ë¥¼ ى €ى¥ي•کëٹ” ë©”ëھ¨ë¦¬ë¥¼ ىœ„ى™€ ê°™ى´ 부름 2. Value 기ë°ک 방법ë،
- 17. 3. Model 기ë°ک 방법ë، • Monte Carlo Tree Search (MCTS) ê°€ ê·¸ ى¤‘ ي•کë‚ک • AlphaGoى—گى„œëڈ„ ى‚¬ىڑ©ëگœ 방법ë، • 마ى¹ک 바둑ى—گى„œ ëھ‡ ىˆک ى•ى„ 내다보듯ى´ يک„ى¬ ىƒپيƒœى—گى„œ ى•ىœ¼ë،œ ى–´ë–¤ ى¼ى´ ى¼ى–´ë‚ ى§€ ى¶”ى •ي•´ë³´ëٹ” 것 • ى‹¤ى œ ىƒپيƒœë¥¼ 변경ي•کى§„ ى•ٹىŒ • ى¦‰, Environment를 변경ي•کى§€ ى•ٹىœ¼ë©° ى•Œê³ ىˆëٹ” ى •ë³´ë‚´ى—گى„œ ي–‰ëڈ™ى—گ 따른 결과를 미리 ى§گى‘ • ى´ê²ƒى„ ى‚¬ىڑ©ي•کëٹ” ê²½ىڑ°ëٹ” ى²´ىٹ¤ë‚ک 바둑ى²کëں¼ ى¤‘ê°„ ê³¼ى •ى—گ ë³´ىƒپى„ ى£¼ê¸° ى–´ë ¤ىڑ´ ê²½ىڑ° • ي–‰ëڈ™ى„ ى„ يƒي•´ëڈ„ ë³´ىƒپى´ ë°”ë،œ ى£¼ى–´ى§€ى§€ ى•ٹê³ ي•œى°¸ى„ ى§„ي–‰ي•´ى•¼ ىٹ¹ë¦¬ يک¹ى€ يŒ¨ë°°ë¥¼ ى•Œ ىˆک ىˆىŒ • ى¦‰, ي™کê²½ى—گى„œ reward를 ى£¼ê¸° ى–´ë ¤ىڑ¸ ë•Œ ى´ë¥¼ ë³´ى™„ي•ک기 ىœ„ي•¨ى´ë¼ê³ ى´ي•´ 3. Model 기ë°ک 방법ë،
- 18. ي–¥ىƒپëگœ DQN • ëھ©ي‘œ ى‹ ê²½ë§ ëڈ„ى… • 매 Episode마다 ëھ©ي‘œê°€ ëگکëٹ” Q ê°’ى´ 바뀌니 ي•™ىٹµى´ ى œëŒ€ë،œ ëگکى§€ ى•ٹىŒ • 매 Episode마다 ëھ©ي‘œ Q를 변경ي•کى§€ ë§گê³ ى¼ى • Batch 단ىœ„마다 변경ي•کىگ • > ëھ©ي‘œê°€ ى•ˆى •ي™”ëگکى–´ ى¼ى •ي•œ ي•™ىٹµ ê°€ëٹ¥ • ى´ى¤‘ DQN • Qê°’ى€ ىگى‹ ى´ ي–‰ي• ىˆک ىˆëٹ” ي–‰ىœ„ ى¤‘ max ê°’ى„ ى·¨ي•ک게 ëگ¨ • ى´ë،œ ى¸ي•´ 과대 ى¶”ى • 문ى œ ë°œىƒ • ى´ë¥¼ ë°©ى§€ي•ک기 ىœ„ي•´ ë‘گê°œىک DQNى„ ي•™ىٹµي•کىگ • 누ë پى†Œëٹ” ى¼ى„ ىکي•کê³ ê²€ى€ى†Œëٹ” 놀기를 ىکي•کê³ â€¦ • ي•œ DQNى€ ي–‰ëڈ™ى„ ى„ يƒي•کëٹ”ëچ° ى‚¬ىڑ©ي•کê³ , 다른 ë…€ى„ى€ ê·¸ ي–‰ëڈ™ى—گ 대ي•œ ê°€ى¹ک를 يŒگ단ي•کëٹ”ëچ° ى‚¬ىڑ©ي•کىگ • ë‘گ개를 분리ي•ک니 과대 ى¶”ى • 문ى œê°€ ى™„ي™”ëگکى—ˆë‹¤ • ىڑ°ى„ ىˆœىœ„ê°€ ىˆëٹ” Experience Replay memory • DQNى—گى„œ Experience Replay memory ëڈ„ى…ىœ¼ë،œ ي•™ىٹµ ى‹œ ى¬ë¯¸ê°€ ىˆى—ˆëٹ”ëچ° ى´ë¥¼ ى¢€ ëچ” ىک ى“¸ ىˆک ى—†ى„까? • 답) ىˆë‹¤. يک„ى¬ Episodeى™€ ى°¨ى´ê°€ يپ° (ى •ë³´ëں‰ى´ ë§ژى€) ê²½ي—کى„ ىڑ°ى„ ى پىœ¼ë،œ ىƒکي”Œë§پ ي•´ë³´ىگ (ى´ë¥¼ Importance Samplingى´ë¼ 부름) 2. Value 기ë°ک 방법ë،
- 19. ي–¥ىƒپëگœ DQN • ê²°ë، : ى¢‹ë‹¤. 2. Value 기ë°ک 방법ë،
- 20. 다른 방법ى€ ى—†ëٹ”ê°€? • 답) ىˆë‹¤. ê°پ 방법ë، 들ىک ى¥ى گى„ ى„ىœ¼ë©´ ëگœë‹¤. • Advantage Actor-Critic (A2C) ê°€ ى—…계 ي‘œى¤€ى´ ëگœ 것 같긴ي•œëچ°â€¦ ى´ê²ƒëڈ„ ى¢€ ى‹œê°„ى´ ى§€ë‚کى„œ يک„ى¬ëٹ” ëھ¨ë¥´ê² ىŒ • ى—¬ê¸°ى„œ ى¢€ ë©‹ى§„ Generalized Advantage Estimation (GAE)ë¼ëٹ” ىڑ©ى–´ë¥¼ ى”€ • ê·¸ëں°ëچ° ى•ىک 방법들 ى •ë¦¬ي•ک다 보니 ى§€ى³گى„œ ى´ê±´ 다ىŒ 기يڑŒى—گ ê³µىœ ي•کê² ىŒ 4. ê·¸ ى™¸ىک 방법들
- 21. يک¹ى‹œ Neural Network ى‚¬ىڑ©ى‹œ 근본ى پى¸ 문ى œëٹ” ى—†ëٹ”ê°€? • 답) ىˆë‹¤. • ىڑ°ë¦¬ê°€ يک„ى¬ ي•™ىٹµي•کëٹ” 것ى€ Neural Networkىک Embedding Spaceى´ë‹¤. • ê·¸ëں°ëچ° ë§گى…니다, NNى´ ىµœى پي™” ëگکëٹ” ë°©ي–¥ىœ¼ë،œ ê°„ë‹¤ê³ ê·¸ê²Œ ê°•ي™”ي•™ىٹµى—گ ëڈ„ى›€ى´ ëگکى§„ ى•ٹëٹ”다. • NNىک Embedding Spaceى™€ ê°•ي™”ي•™ىٹµى´ ë°°ى›Œى•¼ ي•کëٹ” Value يک¹ى€ Policyëٹ” NNê³¼ 다른 공간ى—گ 놓ى—¬ىˆê¸°ى—گ NNى´ ى¢€ ى›€ى§پى´ë©´ Value يک¹ى€ Policyê°€ 깨ى§€ëٹ” ê²½ىڑ°ê°€ ىˆىŒ • ى´ë¥¼ Performance Collapseë¼ê³ ي•¨ • ê°•ي™”ي•™ىٹµ ëھ¨ëچ¸ى„ ي•™ىٹµي•ک다 ë³´ë©´ ê°•ي™”ëگکى§€ ى•ٹê³ ê¹¨ى§€ëٹ” ê²½ىڑ°ê°€ ىگى£¼ ىˆë‹¤. • 마ى¹ک MMORPGى—گى„œ ى¥ë¹„ ê°•ي™”ي•ک다 깨ى§€ëٹ” ëٹگë‚Œ? 근본ى پى¸ 문ى œ
- 22. ê·¸ëں¼ ى´ë¥¼ ي•´ê²°ي• 방법ى€ ى—†ëٹ”ê°€? • 답) ىˆë‹¤. • Proximal Policy Optimization (PPO)ê°€ ى´ëں° ى—°ىœ ë،œ ىƒê²¨ë‚¬ë‹¤. • ىڑ”ى¦ک ى´ê±° ى•ˆ ى“°ë©´ يٹ¸ë Œë“œى—گ ë’¤ى³گى§گ • ê·¸ë ‡ë‹¤ë©´ PPOëٹ” 무ى—‡ى¸ê°€? • PPO ê°œë…گى„ 구يک„ي•ک기 ىœ„ي•œ ى—¬ëں¬ê°€ى§€ 방법들ى´ ى¶œيک„ي–ˆëٹ”ëچ° 간단ي•ک게 ى„¤ëھ…ي•کë©´ ي•™ىٹµ ى‹œ ىƒˆ ى •ى±…ىک ë³€ي™”를 ى¼ى • ë²”ىœ„ë‚´ë،œ ى œي•œي•کëٹ” 것ى´ë‹¤. • “간단ي•ک게â€ë¼ê³ ي–ˆëٹ”ëچ° ى´ê²Œ ى „부ى´ë‹¤. • ى•„ëک ىˆکى‹ىک clip 부분ى´ PPOê°€ ى پىڑ©ëگœ ë‚´ىڑ© 근본ى پى¸ 문ى œ
- 23. Unity ML Agents ىکˆى œ 다ى‹œ ي•œë²ˆ?
- 24. ى™„ë²½يˆ ى´ي•´ي•œ ë°œي‘œىگى—گ게 ىگىœ ë،게 ى§ˆë¬¸ ي•کى§€ ë§گى•„ى£¼ى„¸ىڑ”. 너무 ى‰¬ى›Œى„œ 답변ي•ک기 ى–´ë µىٹµë‹ˆë‹¤.