VMUG Moscow 2014 –ü—Ä–ĺ–Ī–Ľ–Ķ–ľ—č —Ā –ī–ł—Ā–ļ–į–ľ–ł?
‚ÄĘDownload as PPTX, PDF‚ÄĘ
0 likes‚ÄĘ7,183 views








































VMUG Moscow 2014 –ü—Ä–ĺ–Ī–Ľ–Ķ–ľ—č —Ā –ī–ł—Ā–ļ–į–ľ–ł?
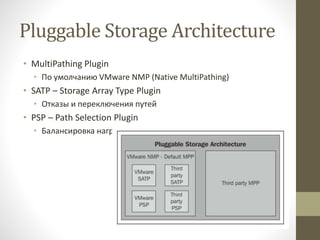
- 2. Pluggable Storage Architecture ‚ÄĘ MultiPathing Plugin ‚ÄĘ –ü–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é VMware NMP (Native MultiPathing) ‚ÄĘ SATP ‚Äď Storage Array Type Plugin ‚ÄĘ –ě—ā–ļ–į–∑—č –ł –Ņ–Ķ—Ä–Ķ–ļ–Ľ—é—á–Ķ–Ĺ–ł—Ź –Ņ—É—ā–Ķ–Ļ ‚ÄĘ PSP ‚Äď Path Selection Plugin ‚ÄĘ –Ď–į–Ľ–į–Ĺ—Ā–ł—Ä–ĺ–≤–ļ–į –Ĺ–į–≥—Ä—É–∑–ļ–ł –ł –≤—č–Ī–ĺ—Ä –Ņ—É—ā–ł –ī–Ľ—Ź IO
- 3. –†–ĺ–Ľ–ł –ł –ļ–ĺ–ľ–į–Ĺ–ī—č PSA ‚ÄĘ PSA –ĺ–Ī–Ĺ–į—Ä—É–∂–ł–≤–į–Ķ—ā –ī–ĺ—Ā—ā—É–Ņ–Ĺ—č–Ķ —Ö–ĺ—Ā—ā—É —Ä–Ķ—Ā—É—Ä—Ā—č —Ö—Ä–į–Ĺ–Ķ–Ĺ–ł—Ź ‚ÄĘ –ü—Ä–ł—Ā–≤–į–ł–≤–į–Ķ—ā –Ņ—Ä–į–≤–ł–Ľ–į MPP –ī–Ľ—Ź —É–Ņ—Ä–į–≤–Ľ–Ķ–Ĺ–ł—Ź —Ä–Ķ—Ā—É—Ä—Ā–ĺ–ľ ‚ÄĘ –Ē–Ľ—Ź –Ņ—Ä–ĺ—Ā–ľ–ĺ—ā—Ä–į –≤—Ā–Ķ—Ö –Ņ–Ľ–į–≥–ł–Ĺ–ĺ–≤ PSA ‚ÄĘ esxcli storage core plugin list
- 4. PSA - MPP ‚ÄĘ NMP/MPP –ł—Ā–Ņ–ĺ–Ľ–Ĺ—Ź–Ķ—ā —Ą—É–Ĺ–ļ—Ü–ł–ł ‚ÄĘ MPP –ĺ–Ņ—Ä–Ķ–ī–Ķ–Ľ—Ź–Ķ—ā —Ą–ł–∑–ł—á–Ķ—Ā–ļ–ł–Ļ –Ņ—É—ā—Ć –ī–ĺ —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–į –ī–Ľ—Ź SATP ‚ÄĘ NMP –ł–ľ–Ķ–Ķ—ā —Ā–ĺ–Ī—Ā—ā–≤–Ķ–Ĺ–Ĺ—č–Ļ –Ĺ–į–Ī–ĺ—Ä –Ņ—Ä–į–≤–ł–Ľ –ī–Ľ—Ź –į—Ā—Ā–ĺ—Ü–ł–į—Ü–ł–ł SATP —Ā PSP ‚ÄĘ –≠–ļ—Ā–Ņ–ĺ—Ä—ā–ł—Ä—É–Ķ—ā –Ľ–ĺ–≥–ł—á–Ķ—Ā–ļ–ĺ–Ķ —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–ĺ –Ņ–ĺ —Ą–ł–∑–ł—á–Ķ—Ā–ļ–ĺ–ľ—É –Ņ—É—ā–ł –ī–Ľ—Ź PSP ‚ÄĘ –Ē–Ľ—Ź –Ņ—Ä–ĺ—Ā–ľ–ĺ—ā—Ä–į –≤—Ā–Ķ—Ö —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤ —Ā —Ā–ĺ–ĺ—ā–≤. PSP/SATP ‚ÄĘ esxcli storage nmp device list
- 5. PSA - SATP ‚ÄĘ –Ě–į–Ī–Ľ—é–ī–į–Ķ—ā –∑–į —Ā–ĺ—Ā—ā–ĺ—Ź–Ĺ–ł–Ķ–ľ –Ņ—É—ā–Ķ–Ļ –ī–ĺ —Ą–ł–∑. —Ā–ł—Ā—ā–Ķ–ľ—č ‚ÄĘ –ě–Ī—ä—Ź–≤–Ľ—Ź–Ķ—ā –Ņ—É—ā–ł –≤ —Ā–ĺ—Ā—ā–ĺ—Ź–Ĺ–ł–Ķ failed/down ‚ÄĘ –£–Ņ—Ä–į–≤–Ľ—Ź–Ķ—ā –Ņ–Ķ—Ä–Ķ–ļ–Ľ—é—á–Ķ–Ĺ–ł–Ķ–ľ —Ą–ł–∑. –Ņ—É—ā–Ķ–Ļ –Ņ–ĺ—Ā–Ľ–Ķ —Ā–Ī–ĺ—Ź ‚ÄĘ vSphere –≤–ļ–Ľ—é—á–į–Ķ—ā –≤ —Ā–Ķ–Ī–Ķ SATP –Ņ–ĺ–ī –Ĺ–Ķ–ļ–ĺ—ā–ĺ—Ä–ĺ–Ķ –ļ–ĺ–Ľ–ł—á–Ķ—Ā—ā–≤–ĺ —Ä–į—Ā–Ņ—Ä–ĺ—Ā—ā—Ä–į–Ĺ–Ķ–Ĺ–Ĺ—č—Ö –°–•–Ē, –ł –Ĺ–Ķ—Ā–ļ–ĺ–Ľ—Ć–ļ–ĺ —É–Ĺ–ł–≤–Ķ—Ä—Ā–į–Ľ—Ć–Ĺ—č—Ö –≤–į—Ä–ł–į–Ĺ—ā–ĺ–≤ active-active/active-passive
- 6. PSA - SATP ‚ÄĘ –Ē–Ľ—Ź –Ņ—Ä–ĺ—Ā–ľ–ĺ—ā—Ä–į –≤—Ā–Ķ—Ö –∑–į–≥—Ä—É–∂–Ķ–Ĺ–Ĺ—č—Ö SATP –ł –į—Ā—Ā–ĺ—Ü–ł–ł—Ä–ĺ–≤–į–Ĺ–Ĺ—č—Ö PSP ‚ÄĘ esxcli storage nmp satp list ‚ÄĘ –Ē–Ľ—Ź –ł–∑–ľ–Ķ–Ĺ–Ķ–Ĺ–ł—Ź PSP –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é –ī–Ľ—Ź –ĺ–Ņ—Ä–Ķ–ī–Ķ–Ľ–Ķ–Ĺ–Ĺ–ĺ–≥–ĺ SATP ‚ÄĘ esxcli storage nmp satp set ‚Äďb <boottime> -P <Default PSP> -s <SATP>
- 7. PSA - PSP ‚ÄĘ –ě—Ā–ĺ–Ī–Ķ–Ĺ–Ĺ–ĺ—Ā—ā–ł –ł –ĺ—ā–≤–Ķ—ā—Ā—ā–≤–Ķ–Ĺ–Ĺ–ĺ—Ā—ā—Ć PSP ‚ÄĘ –í—č–Ī–ĺ—Ä –Ņ—É—ā–ł –ī–Ľ—Ź –ĺ—ā–Ņ—Ä–į–≤–ļ–ł IO –∑–į–Ņ—Ä–ĺ—Ā–į (–ī–į–Ľ–Ķ–Ķ –Ņ—Ä–ĺ—Ā—ā–ĺ IO) ‚ÄĘ –ě—ā–Ľ–ł—á–į–Ķ—ā—Ā—Ź –ĺ—ā SATP —ā–Ķ–ľ, —á—ā–ĺ —Ź–≤–Ľ—Ź–Ķ—ā—Ā—Ź –ľ–Ķ—Ö–į–Ĺ–ł–∑–ľ–ĺ–ľ –Ī–į–Ľ–į–Ĺ—Ā–ł—Ä–ĺ–≤–ļ–ł –Ĺ–į–≥—Ä—É–∑–ļ–ł –ł —Ä–į–Ī–ĺ—ā–į–Ķ—ā —ā–ĺ–Ľ—Ć–ļ–ĺ —Ā –į–ļ—ā–ł–≤–Ĺ—č–ľ–ł –Ņ—É—ā—Ź–ľ–ł ‚ÄĘ vSphere –ł—Ā–Ņ–ĺ–Ľ—Ć–∑—É–Ķ—ā —ā—Ä–ł –Ņ–Ľ–į–≥–ł–Ĺ–į –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é: ‚ÄĘ Fixed ‚ÄĘ Most Recently Used (MRU) ‚ÄĘ Round Robin ‚ÄĘ VMware NMP –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é –≤—č–Ī–ł—Ä–į–Ķ—ā PSP, –į—Ā—Ā–ĺ—Ü–ł–ł—Ä–ĺ–≤–į–Ĺ–Ĺ—č–Ļ —Ā SATP, –∑–į–≥—Ä—É–∂–Ķ–Ĺ–Ĺ—č–ľ –ī–Ľ—Ź –ī–į–Ĺ–Ĺ–ĺ–Ļ –°–•–Ē
- 8. PSA - PSP ‚ÄĘ –Ē–Ľ—Ź –Ņ—Ä–ĺ—Ā–ľ–ĺ—ā—Ä–į –∑–į–≥—Ä—É–∂–Ķ–Ĺ–Ĺ—č—Ö PSP —Ā —ā–Ķ–ļ—É—Č–Ķ–Ļ –ļ–ĺ–Ĺ—Ą–ł–≥—É—Ä–į—Ü–ł–Ķ–Ļ ‚ÄĘ esxcli storage nmp psp <PSP Namespace> deviceconfig get ‚Äďd <device identifier>
- 9. IO –ĺ—ā –Ĺ–į—á–į–Ľ–į –ī–ĺ –ļ–ĺ–Ĺ—Ü–į ‚ÄĘ –í–ú –≤—č–ī–į–Ķ—ā SCSI –ļ–ĺ–ľ–į–Ĺ–ī—É –Ĺ–į —Ā–ĺ–ĺ—ā–≤. –≤–ł—Ä—ā—É–į–Ľ—Ć–Ĺ—č–Ļ –ī–ł—Ā–ļ ‚ÄĘ –Ē—Ä–į–Ļ–≤–Ķ—Ä—č –≥–ĺ—Ā—ā–Ķ–≤–ĺ–Ļ –ě–° –≤–∑–į–ł–ľ–ĺ–ī–Ķ–Ļ—Ā—ā–≤—É—é—ā —Ā –ī—Ä–į–Ļ–≤–Ķ—Ä–į–ľ–ł –≤–ł—Ä—ā—É–į–Ľ—Ć–Ĺ–ĺ–≥–ĺ —Ö—Ä–į–Ĺ–Ķ–Ĺ–ł—Ź ‚ÄĘ –ö–ĺ–ľ–į–Ĺ–ī–į –Ņ–Ķ—Ä–Ķ–Ī—Ä–į—Ā—č–≤–į–Ķ—ā—Ā—Ź –≤ Vmkernel, –≥–ī–Ķ –≤—Ā—ā—É–Ņ–į–Ķ—ā PSA ‚ÄĘ PSA –∑–į–≥—Ä—É–∂–į–Ķ—ā —Ā–ĺ–ĺ—ā–≤. MPP (NMP –≤ –Ĺ–į—ą–Ķ–ľ —Ā–Ľ—É—á–į–Ķ) ‚ÄĘ NMP –≤—č–∑—č–≤–į–Ķ—ā —Ā–ĺ–ĺ—ā–≤. PSP ‚ÄĘ PSP —Ā–ĺ–≥–Ľ–į—Ā–Ĺ–ĺ —Ā –Ņ—Ä–į–≤–ł–Ľ–į–ľ–ł –Ī–į–Ľ–į–Ĺ—Ā–ł—Ä–ĺ–≤–ļ–ł –≤—č–Ī–ł—Ä–į–Ķ—ā –Ņ—É—ā—Ć. –ö–ĺ–ľ–į–Ĺ–ī–į –ĺ—ā—Ā—č–Ľ–į–Ķ—ā—Ā—Ź –į–Ņ–Ņ–į—Ä–į—ā–Ĺ–ĺ–ľ—É/–Ņ—Ä–ĺ–≥—Ä–į–ľ–ľ–Ĺ–ĺ–ľ—É –ł–Ĺ–ł—Ü–ł–į—ā–ĺ—Ä—É, CNA –ł–Ľ–ł HBA ‚ÄĘ –ē—Ā–Ľ–ł –Ĺ–Ķ—É–ī–į—á–Ĺ–ĺ, —ā–ĺ PSP –≤—č–∑—č–≤–į–Ķ—ā SATP –ī–Ľ—Ź –ĺ–Ī—Ä–į–Ī–ĺ—ā–ļ–ł –ĺ—ą–ł–Ī–ļ–ł. –°—ā–į—ā—É—Ā –Ņ—É—ā–ł –ľ–Ķ–Ĺ—Ź–Ķ—ā—Ā—Ź –Ĺ–į –Ĺ–Ķ–į–ļ—ā–ł–≤–Ĺ—č–Ļ –ł –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā –Ņ–ĺ–≤—ā–ĺ—Ä—Ź–Ķ—ā—Ā—Ź ‚ÄĘ –ė–Ĺ–ł—Ü–ł–į—ā–ĺ—Ä, CNA –ł–Ľ–ł HBA —ā—Ä–į–Ĺ—Ā—Ą–ĺ—Ä–ľ–ł—Ä—É–Ķ—ā –ļ–ĺ–ľ–į–Ĺ–ī—É —Ā–ĺ–ĺ—ā–≤. —ā—Ä–į–Ĺ—Ā–Ņ–ĺ—Ä—ā—É –ł –Ņ–ĺ—Ā—č–Ľ–į–Ķ—ā –∑–į–Ņ—Ä–ĺ—Ā
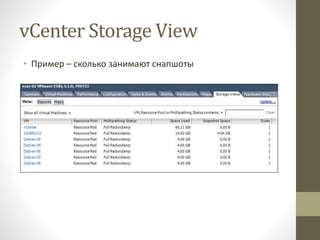
- 10. vCenter Storage View ‚ÄĘ –ü—Ä–ł–ľ–Ķ—Ä ‚Äď —Ā–ļ–ĺ–Ľ—Ć–ļ–ĺ –∑–į–Ĺ–ł–ľ–į—é—ā —Ā–Ĺ–į–Ņ—ą–ĺ—ā—č
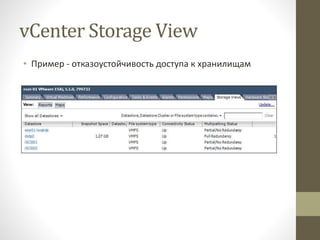
- 11. vCenter Storage View ‚ÄĘ –ü—Ä–ł–ľ–Ķ—Ä - –ĺ—ā–ļ–į–∑–ĺ—É—Ā—ā–ĺ–Ļ—á–ł–≤–ĺ—Ā—ā—Ć –ī–ĺ—Ā—ā—É–Ņ–į –ļ —Ö—Ä–į–Ĺ–ł–Ľ–ł—Č–į–ľ
- 12. vCenter Storage View ‚ÄĘ –ü—Ä–ł–ľ–Ķ—Ä ‚Äď –ī–Ķ—ā–į–Ľ—Ć–Ĺ—č–Ļ —Ā—ā–į—ā—É—Ā –Ņ–ĺ –Ņ—É—ā—Ź–ľ –ī–ĺ –ī–į—ā–į—Ā—ā–ĺ—Ä–į
- 13. vCenter Maps
- 14. esxtop/resxtop
- 15. Log ‚ÄĘ –ě—Ā–Ĺ–ĺ–≤–Ĺ—č–Ķ –∂—É—Ä–Ĺ–į–Ľ—č –ī–Ľ—Ź —Ä–Ķ—ą–Ķ–Ĺ–ł—Ź –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ —Ā –ī–ł—Ā–ļ–ĺ–≤–ĺ–Ļ —Ā–ł—Ā—ā–Ķ–ľ–ĺ–Ļ ‚ÄĘ /var/log/hostd.log –ě—Ā–Ĺ–ĺ–≤–Ĺ–ĺ–Ļ –∂—É—Ä–Ĺ–į–Ľ —Ā –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł–Ķ–Ļ –ĺ –∑–į–ī–į—á–į—Ö, —Ā–ĺ–Ī—č—ā–ł—Ź—Ö –ł –≤–∑–į–ł–ľ–ĺ–ī–Ķ–Ļ—Ā—ā–≤–ł–ł —Ö–ĺ—Ā—ā–į —Ā –ļ–Ľ–ł–Ķ–Ĺ—ā–ĺ–ľ, vCenter –į–≥–Ķ–Ĺ—ā–ĺ–ľ (vpxa) –ł —ā.–ī. ‚ÄĘ /var/log/vmkernel.log –ě—Ā–Ĺ–ĺ–≤–Ĺ–ĺ–Ļ –∂—É—Ä–Ĺ–į–Ľ VMkernel, –≤–ļ–Ľ—é—á–į—é—Č–ł–Ķ –ĺ–Ī–Ĺ–į—Ä—É–∂–Ķ–Ĺ–ł–Ķ —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤, —Ā–Ķ—ā–Ķ–≤—č—Ö –ł –ī–ł—Ā–ļ–ĺ–≤—č—Ö —Ā–ĺ–Ī—č—ā–ł—Ź—Ö –ł –≤–ļ–Ľ—é—á–Ķ–Ĺ–ł–ł –í–ú ‚ÄĘ /var/log/sysboot.log –Ė—É—Ä–Ĺ–į–Ľ VMkernel —Ā —Ā–ĺ–ĺ–Ī—Č–Ķ–Ĺ–ł—Ź–ľ–ł –ĺ —Ā—ā–į—Ä—ā–Ķ —Ö–ĺ—Ā—ā–į –ł –∑–į–≥—Ä—É–∑–ļ–Ķ –ľ–ĺ–ī—É–Ľ–Ķ–Ļ
- 16. Log ‚ÄĘ –Ē–Ľ—Ź –Ņ—Ä–ĺ—Ā—ā–ĺ–≥–ĺ –Ņ–ĺ–ł—Ā–ļ–į –≤ –∂—É—Ä–Ĺ–į–Ľ–Ķ ‚ÄĘ grep ‚Äďr search_term /var/log/vmkernel.log ‚ÄĘ –Ē–Ľ—Ź —Ä–Ķ–ļ—É—Ä—Ā–ł–≤–Ĺ–ĺ–≥–ĺ –Ņ–ĺ–ł—Ā–ļ–į –≤–ĺ –≤—Ā–Ķ—Ö –∂—É—Ä–Ĺ–į–Ľ–į—Ö ‚ÄĘ grep ‚Äďr search_term /var/log/* ‚ÄĘ –Ē–į–Ĺ–Ĺ—č–Ļ –Ņ–ĺ–ł—Ā–ļ –≤—č–ī–į—Ā—ā —ā–ĺ–Ľ—Ć–ļ–ĺ —Ā—ā—Ä–ĺ–ļ–ł, —Ā–ĺ–ī–Ķ—Ä–∂–į—Č–ł–Ķ –ł—Ā–ļ–ĺ–ľ–ĺ–Ķ ‚ÄĘ –ē—Ā–Ľ–ł –Ĺ—É–∂–Ĺ–ĺ –Ĺ–Ķ —ā–ĺ–Ľ—Ć–ļ–ĺ —ć—ā–ł —Ā—ā—Ä–ĺ–ļ–ł, —ā–ĺ ‚ÄĘ grep ‚Äďr ‚ÄďA3 ‚ÄďB2 search_term /var/log/* ‚ÄĘ –≠—ā–ĺ—ā –∑–į–Ņ—Ä–ĺ—Ā –≤—č–ī–į—Ā—ā —ā–į–ļ–∂–Ķ 3 —Ā—ā—Ä–ĺ–ļ–ł –Ņ–Ķ—Ä–Ķ–ī –ł 2 –Ņ–ĺ—Ā–Ľ–Ķ ‚ÄĘ –ü–ĺ–ł—Ā–ļ –≤—Ā–Ķ—Ö —Ā–ĺ–Ī—č—ā–ł–Ļ, –≤ –ļ–ĺ—ā–ĺ—Ä—č—Ö –ĺ–ī–Ĺ–ĺ–≤—Ä–Ķ–ľ–Ķ–Ĺ–Ĺ–ĺ SCSI –ł Failed ‚ÄĘ cat /var/log/vmkernel.log | grep SCSI | grep ‚Äďi Failed
- 17. Log ‚ÄĘ –≠–ļ—Ä–į–Ĺ –Ņ–Ķ—Ä–Ķ–Ņ–ĺ–Ľ–Ĺ–ł–Ľ—Ā—Ź? ‚ÄĘ cat /var/log/vmkernel.log | grep ‚Äďi SCSI | less ‚ÄĘ –ü–ĺ—Ā–Ľ–Ķ–ī–Ĺ–ł–Ķ 10 —Ā–ĺ–ĺ–Ī—Č–Ķ–Ĺ–ł–Ļ –≤ hostd.log ‚ÄĘ tail ‚Äďn10 /var/log/hostd.log ‚ÄĘ –ü–Ķ—Ä–≤—č–Ķ 10 —Ā–ĺ–ĺ–Ī—Č–Ķ–Ĺ–ł–Ļ –≤ hostd.log ‚ÄĘ head ‚Äďn10 /var/log/hostd.log ‚ÄĘ –Ě–į–Ī–Ľ—é–ī–Ķ–Ĺ–ł–Ķ –∑–į –∂—É—Ä–Ĺ–į–Ľ–ĺ–ľ vmkwarning.log ‚ÄĘ tail ‚Äďf /var/log/vmkwarning.log
- 19. –ö–Ľ–Ķ–Ļ–ľ–ł–Ĺ–≥ (claim) ‚ÄĘ –ö–Ľ–Ķ–Ļ–ľ–ł–Ĺ–≥ ‚Äď –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā —É—Ā—ā–į–Ĺ–ĺ–≤–ļ–ł –≤–∑–į–ł–ľ–ĺ—Ā–≤—Ź–∑–ł –ľ–Ķ–∂–ī—É —Ą–ł–∑–ł—á–Ķ—Ā–ļ–ł–ľ–ł —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–į–ľ–ł –ł –Ņ–Ľ–į–≥–ł–Ĺ–į–ľ–ł –≤ PSA ‚ÄĘ –í—Ā–Ķ –ļ–Ľ–Ķ–Ļ–ľ-–Ņ—Ä–į–≤–ł–Ľ–į –ľ–ĺ–≥—É—ā –Ī—č—ā—Ć –∑–į–≥—Ä—É–∂–Ķ–Ĺ—č —ā–ĺ–Ľ—Ć–ļ–ĺ —á–Ķ—Ä–Ķ–∑ –ļ–ĺ–ľ–į–Ĺ–ī–Ĺ—É—é —Ā—ā—Ä–ĺ–ļ—É –ł –Ĺ–Ķ –ī–ĺ—Ā—ā—É–Ņ–Ĺ—č —á–Ķ—Ä–Ķ–∑ GUI
- 20. –ö–Ľ–Ķ–Ļ–ľ–ł–Ĺ–≥ (claim) ‚ÄĘ –ü—Ä–ĺ—Ā–ľ–ĺ—ā—Ä –∑–į–≥—Ä—É–∂–Ķ–Ĺ–Ĺ—č—Ö –ļ–Ľ–Ķ–Ļ–ľ-–Ņ—Ä–į–≤–ł–Ľ ‚ÄĘ esxcli storage core claimrule list ‚ÄĘ –ö–Ľ–Ķ–Ļ–ľ –Ņ—Ä–į–≤–ł–Ľ–ĺ –ľ–ĺ–∂–Ķ—ā –Ī—č—ā—Ć —Ä–į–∑–Ĺ—č—Ö —ā–ł–Ņ–ĺ–≤ ‚ÄĘ vendor, location, transport –ł driver ‚ÄĘ –£ –ļ–į–∂–ī–ĺ–≥–ĺ –Ņ—Ä–į–≤–ł–Ľ–į –Ķ—Ā—ā—Ć –ł–ī–Ķ–Ĺ—ā–ł—Ą–ł–ļ–į—ā–ĺ—Ä –ĺ—ā 0 –ī–ĺ 65535 ‚ÄĘ ID 0-100, 65436-65535 –∑–į—Ä–Ķ–∑–Ķ—Ä–≤–ł—Ä–ĺ–≤–į–Ĺ—č
- 21. –ö–Ľ–Ķ–Ļ–ľ–ł–Ĺ–≥ (claim) ‚ÄĘ –ė–ī–Ķ–Ĺ—ā–ł—Ą–ł–ļ–į—ā–ĺ—Ä 65535 –∑–į—Ä–Ķ–∑–Ķ—Ä–≤–ł—Ä–ĺ–≤–į–Ĺ ‚ÄĘ –ü—Ä–į–≤–ł–Ľ–į –Ņ—Ä–ł–ľ–Ķ–Ĺ—Ź—é—ā—Ā—Ź –≤ –Ņ–ĺ—Ä—Ź–ī–ļ–Ķ –ĺ—ā 0 –Ņ–ĺ –≤–ĺ–∑—Ä–į—Ā—ā–į—é—Č–Ķ–Ļ ‚ÄĘ –ē—Ā–Ľ–ł —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–ĺ –Ĺ–Ķ –Ņ–ĺ–Ņ–į–Ľ–ĺ –Ĺ–ł –Ņ–ĺ–ī –ĺ–ī–Ĺ–ĺ –Ņ—Ä–Ķ–ī—č–ī—É—Č–Ķ–Ķ –Ņ—Ä–į–≤–ł–Ľ–ĺ, —ā–ĺ –Ķ–≥–ĺ –∑–į–Ī–ł—Ä–į–Ķ—ā –Ņ–ĺ–ī —Ā–Ķ–Ī—Ź NMP ‚ÄĘ MASK_PATH ‚Äď –Ņ–Ľ–į–≥–ł–Ĺ, —Ä–Ķ–į–Ľ–ł–∑—É—é—Č–ł–Ļ –Ĺ–į —É—Ä–ĺ–≤–Ĺ–Ķ PSA —Ą—É–Ĺ–ļ—Ü–ł–ĺ–Ĺ–į–Ľ, –į–Ĺ–į–Ľ–ĺ–≥–ł—á–Ĺ—č–Ļ –∑–ĺ–Ĺ–ł—Ä–ĺ–≤–į–Ĺ–ł—é –ł –ľ–į—Ā–ļ–ł—Ä–ĺ–≤–į–Ĺ–ł—é –≤ FC ‚ÄĘ –ē—Ā–Ľ–ł –Ķ—Ā—ā—Ć –Ņ—Ä–į–≤–ł–Ľ–ĺ 134 –ī–Ľ—Ź MASK_PATH –ł –Ņ—Ä–į–≤–ł–Ľ–ĺ 150 –ī–Ľ—Ź MPP, —ā–ĺ –Ņ—É—ā—Ć –Ī—É–ī–Ķ—ā —Ā–ļ—Ä—č—ā –ł —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–ĺ –Ĺ–Ķ –Ī—É–ī–Ķ—ā –Ņ–ĺ–ī–ļ–Ľ—é—á–Ķ–Ĺ–ĺ ‚ÄĘ –£ –ļ–į–∂–ī–ĺ–≥–ĺ –Ņ—Ä–į–≤–ł–Ľ–į –Ķ—Ā—ā—Ć –ļ–Ľ–į—Ā—Ā ‚ÄĘ File ‚Äď –Ņ—Ä–į–≤–ł–Ľ–ĺ –∑–į–≥—Ä—É–∂–Ķ–Ĺ–ĺ –≤ —Ā–ł—Ā—ā–Ķ–ľ–Ķ ‚ÄĘ Runtime ‚Äď –Ņ—Ä–į–≤–ł–Ľ–ĺ –≤–ļ–Ľ—é—á–Ķ–Ĺ–ĺ –ł –į–ļ—ā–ł–≤–Ĺ–ĺ (—Ā–≤—Ź–∑–į–Ĺ–ĺ —Ā —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–ĺ–ľ)
- 22. –ö–Ľ–Ķ–Ļ–ľ–ł–Ĺ–≥ (claim) ‚ÄĘ –£–ī–į–Ľ–ł—ā—Ć –ļ–Ľ–Ķ–Ļ–ľ-–Ņ—Ä–į–≤–ł–Ľ–ĺ ‚ÄĘ esxcli storage core claimrule remove ‚Äďrule 400 ‚ÄĘ !!! –í—Ā–Ķ–≥–ī–į –ł—Ā–Ņ–ĺ–Ľ—Ć–∑—É–Ļ—ā–Ķ –ļ–ĺ–ľ–į–Ĺ–ī—É vm-support –ī–Ľ—Ź —Ā–ĺ—Ö—Ä–į–Ĺ–Ķ–Ĺ–ł—Ź —ā–Ķ–ļ—É—Č–Ķ–Ļ –ļ–ĺ–Ĺ—Ą–ł–≥—É—Ä–į—Ü–ł–ł !!!
- 23. –ö–Ľ–Ķ–Ļ–ľ–ł–Ĺ–≥ (claim) ‚ÄĘ –£–ī–į–Ľ–ł—ā—Ć –ľ–ĺ–∂–Ĺ–ĺ —ā–ĺ–Ľ—Ć–ļ–ĺ –Ņ—Ä–į–≤–ł–Ľ–ĺ –≤ —Ā–ĺ—Ā—ā–ĺ—Ź–Ĺ–ł–ł File ‚ÄĘ –Ē–Ľ—Ź —É–ī–į–Ľ–Ķ–Ĺ–ł—Ź –Ņ—Ä–į–≤–ł–Ľ–į –≤ —Ā–ĺ—Ā—ā–ĺ—Ź–Ĺ–ł–ł Runtime ‚ÄĘ –°–Ĺ–į—á–į–Ľ–į –∑–į–≥—Ä—É–∑–ł–ľ –Ĺ–į–Ī–ĺ—Ä –Ņ—Ä–į–≤–ł–Ľ esxcli storage core claimrule load ‚ÄĘ –ó–į—ā–Ķ–ľ —Ā–Ĺ–ł–ľ–Ķ–ľ –ļ–Ľ–Ķ–Ļ–ľ —Ā —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–į esxcli storage core claiming unclaim -t location -A vmhba32 -T 1 -L 0 ‚ÄĘ –ü—Ä–ĺ—Ā—ā–ĺ–Ļ —Ä–Ķ—Ā–ļ–į–Ĺ —ā–Ķ–Ņ–Ķ—Ä—Ć –Ņ–ĺ–∑–≤–ĺ–Ľ–ł—ā —É–≤–ł–ī–Ķ—ā—Ć –ī–į—ā–į—Ā—ā–ĺ—Ä
- 24. –ü—Ä–ĺ–Ī–Ľ–Ķ–ľ—č —Ā –Ņ—É—ā—Ź–ľ–ł ‚ÄĘ –í–Ĺ–ł–ľ–į—ā–Ķ–Ľ—Ć–Ĺ–ĺ —á–ł—ā–į–Ļ—ā–Ķ –ī–ĺ–ļ—É–ľ–Ķ–Ĺ—ā–į—Ü–ł—é –ļ –°–•–Ē ‚ÄĘ vSphere –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é –∑–į–≥—Ä—É–∂–į–Ķ—ā ‚ÄĘ Fixed –ī–Ľ—Ź active-active –°–•–Ē ‚ÄĘ MRU –ī–Ľ—Ź active-passive –°–•–Ē ‚ÄĘ –í–Ķ–Ĺ–ī–ĺ—Ä –°–•–Ē –∑–Ĺ–į–Ķ—ā –Ľ—É—á—ą–Ķ ‚ÄĘ –Ě–į–Ņ—Ä–ł–ľ–Ķ—Ä, HP MSA1500 –ł–ľ–Ķ–Ķ—ā active-active ‚ÄĘ –Ě–ĺ –≤ —Ā–ł–Ľ—É –≤–Ĺ—É—ā—Ä–Ķ–Ĺ–Ĺ–Ķ–Ļ –Ľ–ĺ–≥–ł–ļ–ł MSA —Ä–Ķ–ļ–ĺ–ľ–Ķ–Ĺ–ī—É–Ķ—ā—Ā—Ź MRU
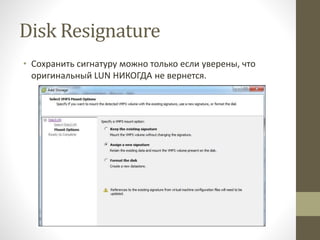
- 25. Disk Resignature ‚ÄĘ VMFS —ā–ĺ–ľ —Ā–ĺ–ī–Ķ—Ä–∂–ł—ā –≤ —Ā–ł–≥–Ĺ–į—ā—É—Ä–Ķ –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—é –ĺ –∂–Ķ–Ľ–Ķ–∑–Ķ ‚ÄĘ –í —ā–ĺ–ľ —á–ł—Ā–Ľ–Ķ –ł–ī–Ķ–Ĺ—ā–ł—Ą–ł–ļ–į—ā–ĺ—Ä –ľ–į—Ā—Ā–ł–≤–į, LUN ID –ł UUID ‚ÄĘ –ē—Ā–Ľ–ł —ā–ĺ–ľ –Ņ–Ķ—Ä–Ķ–Ĺ–Ķ—Ā–Ķ–Ĺ –ł–Ľ–ł —Ā–ľ–Ķ–Ĺ–ł–Ľ ID ‚Äď vSphere –ł–≥–Ĺ–ĺ—Ä–ł—Ä—É–Ķ—ā ‚ÄĘ –Ē–Ľ—Ź –Ņ—Ä–Ķ–ī–ĺ—ā–≤—Ä–į—Č–Ķ–Ĺ–ł—Ź –ľ–ĺ–Ĺ—ā–ł—Ä–ĺ–≤–į–Ĺ–ł—Ź –ļ–ĺ–Ņ–ł–Ļ –ł —Ā–Ĺ–į–Ņ—ą–ĺ—ā–ĺ–≤ ‚ÄĘ –ü–Ķ—Ä–Ķ–Ņ–ĺ–ī–Ņ–ł—Ā—č–≤–į–Ĺ–ł–Ķ (resignature) ‚Äď —Ā–ĺ–∑–ī–į–Ĺ–ł–Ķ –Ĺ–ĺ–≤–ĺ–Ļ —Ā–ł–≥–Ĺ–į—ā—É—Ä—č (–ł UUID) –ī–Ľ—Ź –Ņ–Ķ—Ä–Ķ–ľ–Ķ—Č–Ķ–Ĺ–Ĺ–ĺ–≥–ĺ LUN –Ņ—Ä–ł –ľ–ĺ–Ĺ—ā–ł—Ä–ĺ–≤–į–Ĺ–ł–ł ‚ÄĘ http://kb.vmware.com/selfservice/microsites/search.do?langu age=en_US&cmd=displayKC&externalId=1011387
- 26. Disk Resignature ‚ÄĘ –°–ĺ—Ö—Ä–į–Ĺ–ł—ā—Ć —Ā–ł–≥–Ĺ–į—ā—É—Ä—É –ľ–ĺ–∂–Ĺ–ĺ —ā–ĺ–Ľ—Ć–ļ–ĺ –Ķ—Ā–Ľ–ł —É–≤–Ķ—Ä–Ķ–Ĺ—č, —á—ā–ĺ –ĺ—Ä–ł–≥–ł–Ĺ–į–Ľ—Ć–Ĺ—č–Ļ LUN –Ě–ė–ö–ě–ď–Ē–ź –Ĺ–Ķ –≤–Ķ—Ä–Ĺ–Ķ—ā—Ā—Ź.
- 27. –Ě–ĺ–ľ–Ķ—Ä–į LUN ‚ÄĘ –ú–į–ļ—Ā–ł–ľ–į–Ľ—Ć–Ĺ–ĺ–Ķ –ļ–ĺ–Ľ–ł—á–Ķ—Ā—ā–≤–ĺ LUN‚Äô–ĺ–≤, —Ā –ļ–ĺ—ā–ĺ—Ä—č–ľ–ł –ľ–ĺ–∂–Ķ—ā —Ä–į–Ī–ĺ—ā–į—ā—Ć ESXi = 256 ‚ÄĘ –ü—Ä–ł —Ä–Ķ—Ā–ļ–į–Ĺ–Ķ ESXi –Ĺ–į—á–ł–Ĺ–į–Ķ—ā —Ā 0 –ł –ĺ—Ā—ā–į–Ĺ–į–≤–Ľ–ł–≤–į–Ķ—ā—Ā—Ź –Ĺ–į 255 ‚ÄĘ LUN 268 –Ě–ė–ö–ě–ď–Ē–ź –Ĺ–Ķ –Ī—É–ī–Ķ—ā –≤–ł–ī–Ķ–Ĺ ESXi ‚ÄĘ –ü–ĺ–ļ–į –Ĺ–Ķ—ā –ĺ—Ā—ā—Ä–ĺ–Ļ –Ĺ–Ķ–ĺ–Ī—Ö–ĺ–ī–ł–ľ–ĺ—Ā—ā–ł ‚Äď –Ĺ–Ķ –ľ–Ķ–Ĺ—Ź–Ļ—ā–Ķ LUN ID –ī–Ľ—Ź —Ä–į–∑–Ĺ—č—Ö —Ö–ĺ—Ā—ā–ĺ–≤ ‚ÄĘ Disk.MaxLun –ľ–ĺ–∂–Ķ—ā —Ā–ĺ–ļ—Ä–į—ā–ł—ā—Ć –≤—Ä–Ķ–ľ—Ź —Ä–Ķ—Ā–ļ–į–Ĺ–į –ł –∑–į–≥—Ä—É–∑–ļ–ł ‚ÄĘ –Ě–ĺ –≤—Ā–Ķ–≥–ī–į –Ķ—Ā—ā—Ć –ĺ–Ņ–į—Ā–Ĺ–ĺ—Ā—ā—Ć, —á—ā–ĺ –Ĺ–ĺ–≤—č–Ļ –≤—č–ī–Ķ–Ľ–Ķ–Ĺ–Ĺ—č–Ļ LUN –Ī—É–ī–Ķ—ā —Ā ID > Disk.MaxLun –ł —Ā–ĺ–ĺ—ā–≤. —Ö–ĺ—Ā—ā –Ķ–≥–ĺ –Ĺ–Ķ —É–≤–ł–ī–ł—ā
- 28. IP –≤–ł–ī–ł–ľ–ĺ—Ā—ā—Ć ‚ÄĘ –Ě–į—Ā—ā–ĺ—Ź—ā–Ķ–Ľ—Ć–Ĺ–ĺ —Ä–Ķ–ļ–ĺ–ľ–Ķ–Ĺ–ī—É–Ķ—ā—Ā—Ź –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł–Ķ —Ä–į–∑–Ľ–ł—á–Ĺ—č—Ö –Ņ–ĺ–ī—Ā–Ķ—ā–Ķ–Ļ –ł –ī–į–∂–Ķ —Ą–ł–∑–ł—á–Ķ—Ā–ļ–ł—Ö —Ā–Ķ—ā–Ķ–Ļ –ī–Ľ—Ź —Ā–Ķ—ā–ł –í–ú –ł IP —Ö—Ä–į–Ĺ–Ķ–Ĺ–ł—Ź ‚ÄĘ –ě—ā–ī–Ķ–Ľ—Ć–Ĺ–į—Ź —Ā–Ķ—ā—Ć ‚Äď –ĺ—ā–ī–Ķ–Ľ—Ć–Ĺ—č–Ķ –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ—č ‚ÄĘ –ü—Ä–ĺ–Ņ–į–Ľ–ł –ī–ł—Ā–ļ–ł ‚Äď –Ņ—Ä–ĺ–≤–Ķ—Ä—Ć—ā–Ķ –Ņ–ĺ–ī–ļ–Ľ—é—á–Ķ–Ĺ–ł–Ķ ‚ÄĘ ping –ł vmkping –ī–Ľ—Ź ESXi ‚Äď –ĺ–ī–Ĺ–ĺ –ł —ā–ĺ –∂–Ķ
- 29. –ü—Ä–ĺ–Ī–Ľ–Ķ–ľ—č iSCSI ‚ÄĘ –ü—Ä–į–ļ—ā–ł—á–Ķ—Ā–ļ–ł –≤—Ā–Ķ –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ—č —Ā iSCSI –ľ–ĺ–∂–Ĺ–ĺ –Ĺ–į–Ļ—ā–ł –≤ –∂—É—Ä–Ĺ–į–Ľ–į—Ö ‚ÄĘ grep ‚Äďr iscsid/var/log/* | less ‚ÄĘ –ē—Ā–Ľ–ł –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł–ł –Ĺ–Ķ–ī–ĺ—Ā—ā–į—ā–ĺ—á–Ĺ–ĺ, —ā–ĺ‚Ķ ‚ÄĘ vmkiscsid -x "insert into internal (key, value) VALUES ('option.LogLevel',' 999');" ‚ÄĘ –Ę–ĺ–Ľ—Ć–ļ–ĺ –Ĺ–Ķ –∑–į–Ī—É–ī—Ć—ā–Ķ –≤—č–ļ–Ľ—é—á–ł—ā—Ć –Ņ–ĺ—Ā–Ľ–Ķ ‚ÄĘ vmkiscsid -x "delete from internal where key ='option.LogLevel';"
- 30. –ü—Ä–ĺ–Ī–Ľ–Ķ–ľ—č NFS ‚ÄĘ NFS –Ņ–ĺ–ī–ļ–Ľ—é—á–Ķ–Ĺ–ł—Ź –Ľ–ł—ą–Ķ–Ĺ—č –ľ–Ĺ–ĺ–≥–ł—Ö –Ī–Ľ–ĺ—á–Ĺ—č—Ö –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ, –Ĺ–ĺ‚Ķ ‚ÄĘ –ó–į–≤–ł—Ā—Ź—ā –Ķ—Č–Ķ –ł –ĺ—ā DNS ‚ÄĘ –Ě–Ķ–ļ–ĺ—ā–ĺ—Ä—č–Ķ NFS —Ā–ł—Ā—ā–Ķ–ľ—č —ā—Ä–Ķ–Ī—É—é—ā –ĺ–Ī—Ä–į—ā–Ĺ–ĺ–≥–ĺ —Ä–į–∑—Ä–Ķ—ą–Ķ–Ĺ–ł—Ź –ł–ľ–Ķ–Ĺ. –ē—Ā–Ľ–ł NFS –°–•–Ē –Ĺ–Ķ –ľ–ĺ–∂–Ķ—ā —Ä–į–∑—Ä–Ķ—ą–ł—ā—Ć –ł–ľ—Ź ESXi, —ā–ĺ –Ĺ–Ķ –ĺ—ā–ī–į—Ā—ā —Ä–Ķ—Ā—É—Ä—Ā ‚ÄĘ –Ě–Ķ –Ņ–ĺ–ī–ļ–Ľ—é—á–į–Ķ—ā—Ā—Ź NFS –ī–į—ā–į—Ā—ā–ĺ—Ä ‚Äď –Ņ—Ä–ĺ–≤–Ķ—Ä—Ć ACL ‚ÄĘ –ü—Ä–ĺ–≤–Ķ—Ä—Ć ACL –Ķ—Č–Ķ —Ä–į–∑ ‚ÄĘ –ė –Ķ—Č–Ķ —Ä–į–∑ ‚ÄĘ –ė –Ĺ–Ķ –∑–į–Ī—É–ī—Ć, —á—ā–ĺ NFS —á—É–≤—Ā—ā–≤–ł—ā–Ķ–Ľ–Ķ–Ĺ –ļ —Ä–ē–≥–ł—Ā–Ę—Ä–£ ‚ÄĘ –ė —á—ā–ĺ –Ĺ–į –í–°–ē–• —Ö–ĺ—Ā—ā–į—Ö –ł–ľ—Ź –ī–į—ā–į—Ā—ā–ĺ—Ä–į –ī–ĺ–Ľ–∂–Ĺ–ĺ –Ī—č—ā—Ć –ĺ–ī–ł–Ĺ–į–ļ–ĺ–≤—č–ľ
- 31. –ü—Ä–ĺ–Ī–Ľ–Ķ–ľ—č NFS ‚ÄĘ NFS –ł –ļ–ĺ–ľ–į–Ĺ–ī–Ĺ–į—Ź —Ā—ā—Ä–ĺ–ļ–į ‚ÄĘ grep ‚Äďr nfs /var/log/* | less ‚ÄĘ –Ē–ĺ–Ī–į–≤–ł–ľ –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł–ł ‚ÄĘ esxcfg-advcfg ‚Äďs 1 /NFS/LogNfsStat3 ‚ÄĘ –ó–į–ļ–ĺ–Ĺ—á–ł–Ľ–ł ‚Äď —É–Ī–į–≤–ł–Ľ–ł ‚ÄĘ esxcfg-advcfg ‚Äďs 0 /NFS/LogNfsStat3
- 33. IO Latency ‚ÄĘ –ö–Ľ—é—á–Ķ–≤–į—Ź –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ–į –ī–ł—Ā–ļ–ĺ–≤—č—Ö —Ā–ł—Ā—ā–Ķ–ľ ‚Äď –∑–į–ī–Ķ—Ä–∂–ļ–ł ‚ÄĘ esxtop –Ĺ–į–ľ –ł—Ö –Ņ–ĺ–ļ–į–∂–Ķ—ā ‚ÄĘ DAVG/cmd ‚Äď —Ā—Ä–Ķ–ī–Ĺ–Ķ–Ķ –≤—Ä–Ķ–ľ—Ź –Ĺ–į –ļ–ĺ–ľ–į–Ĺ–ī—É, –Ņ–ĺ—Ā–Ľ–į–Ĺ–Ĺ—É—é VMkernel –Ĺ–į —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–ĺ. –Ě–ĺ—Ä–ľ–į–Ľ—Ć–Ĺ—č–Ļ –Ņ–ĺ–ļ–į–∑–į—ā–Ķ–Ľ—Ć <25ms ‚ÄĘ KAVG/cmd ‚Äď —Ā—Ä–Ķ–ī–Ĺ–Ķ–Ķ –≤—Ä–Ķ–ľ—Ź –≤–Ĺ—É—ā—Ä–ł VMkernel. 1-2ms ‚ÄĘ GAVG/cmd ‚Äď —Ā—Ä–Ķ–ī–Ĺ–Ķ–Ķ –≤—Ä–Ķ–ľ—Ź –ī–Ľ—Ź –≥–ĺ—Ā—ā–Ķ–≤–ĺ–Ļ –ě–°. <25ms
- 34. IO Latency ‚Äď –≥–ī–Ķ –∑–į—Ä—č—ā–į? ‚ÄĘ –ö–į–ļ —É–∑–Ĺ–į—ā—Ć, –≥–ī–Ķ –ł–ľ–Ķ–Ĺ–Ĺ–ĺ –∑–į—Ä—č—ā–į —Ā–ĺ–Ī–į–ļ–į? ‚ÄĘ –Ě–į –ĺ–ī–Ĺ–ĺ–ľ HBA? –Ě–į –ľ–į—Ā—Ā–ł–≤–Ķ? –Ě–į –ĺ–ī–Ĺ–ĺ–ľ –Ņ—É—ā–ł? ‚ÄĘ esxtop: d f a b g
- 35. IO Latency ‚Äď –≥–ī–Ķ –∑–į—Ä—č—ā–į? ‚ÄĘ –ó–į–ī–Ķ—Ä–∂–ļ–ł –Ņ–ĺ —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤–į–ľ ‚ÄĘ esxtop: u f a i
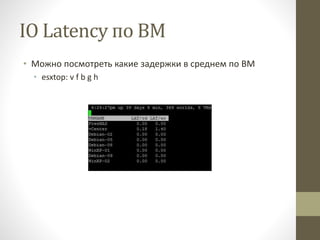
- 36. IO Latency –Ņ–ĺ –í–ú ‚ÄĘ –ú–ĺ–∂–Ĺ–ĺ –Ņ–ĺ—Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć –ļ–į–ļ–ł–Ķ –∑–į–ī–Ķ—Ä–∂–ļ–ł –≤ —Ā—Ä–Ķ–ī–Ĺ–Ķ–ľ –Ņ–ĺ –í–ú ‚ÄĘ esxtop: v f b g h
- 37. SCSI Reservation ‚ÄĘ VMFS ‚Äď —Ā–ł–ľ–ľ–Ķ—ā—Ä–ł—á–Ĺ–į—Ź –ļ–Ľ–į—Ā—ā–Ķ—Ä–Ĺ–į—Ź —Ą–į–Ļ–Ľ–ĺ–≤–į—Ź —Ā–ł—Ā—ā–Ķ–ľ–į ‚ÄĘ –Ě–Ķ—ā –≤—č–ī–Ķ–Ľ–Ķ–Ĺ–Ĺ—č—Ö —Ö–ĺ—Ā—ā–ĺ–≤-–į—Ä–Ī–ł—ā—Ä–ĺ–≤ ‚ÄĘ –Ē–Ľ—Ź –Ņ—Ä–Ķ–ī–ĺ—ā–≤—Ä–į—Č–Ķ–Ĺ–ł—Ź –Ņ–ĺ—Ä—á–ł –ī–į–Ĺ–Ĺ—č—Ö –Ņ—Ä–ł –ĺ–Ī–Ĺ–ĺ–≤–Ľ–Ķ–Ĺ–ł–ł –ľ–Ķ—ā–į–ī–į–Ĺ–Ĺ—č—Ö –ł–ī–Ķ—ā –Ī–Ľ–ĺ–ļ–ł—Ä–ĺ–≤–ļ–į –≤—Ā–Ķ–≥–ĺ LUN ‚ÄĘ –ú–Ķ—ā–į–ī–į–Ĺ–Ĺ—č–Ķ –ĺ–Ī–Ĺ–ĺ–≤–Ľ—Ź—é—ā—Ā—Ź –≤ –ľ–ĺ–Ĺ–ĺ–Ņ–ĺ–Ľ—Ć–Ĺ–ĺ–ľ —Ä–Ķ–∂–ł–ľ–Ķ ‚ÄĘ –ě–Ņ–Ķ—Ä–į—Ü–ł–ł, —ā—Ä–Ķ–Ī—É—Č–ł–Ķ –ĺ–Ī–Ĺ–ĺ–≤–Ľ–Ķ–Ĺ–ł—Ź –ľ–Ķ—ā–į–ī–į–Ĺ–Ĺ—č—Ö ‚ÄĘ –í–ļ–Ľ—é—á–Ķ–Ĺ–ł–Ķ/–≤—č–ļ–Ľ—é—á–Ķ–Ĺ–ł–Ķ –í–ú ‚ÄĘ –°–ĺ–∑–ī–į–Ĺ–ł–Ķ –Ĺ–ĺ–≤–ĺ–Ļ –í–ú/—Ä–į–∑–≤–Ķ—Ä—ā—č–≤–į–Ĺ–ł–Ķ –ł–∑ —ą–į–Ī–Ľ–ĺ–Ĺ–į ‚ÄĘ –ú–ł–≥—Ä–į—Ü–ł—Ź –í–ú –Ĺ–į –ī—Ä—É–≥–ĺ–Ļ —Ö–ĺ—Ā—ā ‚ÄĘ –ė–∑–ľ–Ķ–Ĺ–Ķ–Ĺ–ł–Ķ –ī–į—ā–į—Ā—ā–ĺ—Ä–ĺ–≤ ‚ÄĘ –ė–∑–ľ–Ķ–Ĺ–Ķ–Ĺ–ł–Ķ —Ä–į–∑–ľ–Ķ—Ä–į —Ą–į–Ļ–Ľ–į
- 38. SCSI Reservation ‚ÄĘ vmkernel.log ‚ÄĘ reservation conflict ‚ÄĘ esxtop: d u f F H
- 39. SCSI Reservation - —Ä–Ķ—ą–Ķ–Ĺ–ł–Ķ ‚ÄĘ –í–ļ–Ľ—é—á–ł—ā–Ķ VAAI ‚ÄĘ –ö–ĺ–Ĺ–ļ—Ä–Ķ—ā–Ĺ–ĺ ATS ‚ÄĘ –†–į–∑–ľ–Ķ—Ā—ā–ł—ā–Ķ –í–ú, —ā—Ä–Ķ–Ī—É—é—Č–ł–Ķ SCSI Reservation –Ņ–ĺ —Ä–į–∑–Ĺ—č–ľ LUN ‚ÄĘ –í–ļ–Ľ—é—á–Ķ–Ĺ–ł–Ķ-–≤—č–ļ–Ľ—é—á–Ķ–Ĺ–ł–Ķ, —Ā–Ĺ–į–Ņ—ą–ĺ—ā—č ‚ÄĘ –£–≤–Ķ–Ľ–ł—á—Ć—ā–Ķ –ļ–ĺ–Ľ–ł—á–Ķ—Ā—ā–≤–ĺ LUN ‚ÄĘ –£–ľ–Ķ–Ĺ—Ć—ą–ł—ā–Ķ –ļ–ĺ–Ľ–ł—á–Ķ—Ā—ā–≤–ĺ —Ö–ĺ—Ā—ā–ĺ–≤ –Ĺ–į LUN ‚ÄĘ –£–ľ–Ķ–Ĺ—Ć—ą–ł—ā–Ķ –ļ–ĺ–Ľ–ł—á–Ķ—Ā—ā–≤–ĺ —Ā–Ĺ–į–Ņ—ą–ĺ—ā–ĺ–≤ ‚ÄĘ –£–ľ–Ķ–Ĺ—Ć—ą–ł—ā–Ķ –ļ–ĺ–Ľ–ł—á–Ķ—Ā—ā–≤–ĺ –í–ú –Ĺ–į LUN ‚ÄĘ http://kb.vmware.com/selfservice/microsites/search.do?langu age=en_US&cmd=displayKC&externalId=1005009
- 40. –ě—á–Ķ—Ä–Ķ–ī–ł IO ‚ÄĘ IO –Ĺ–Ķ —Ā—Ä–į–∑—É —É—Ö–ĺ–ī–ł—ā –Ĺ–į –ī–ł—Ā–ļ, –į —Ā–Ĺ–į—á–į–Ľ–į –Ņ–ĺ–Ņ–į–ī–į–Ķ—ā –≤ –ĺ—á–Ķ—Ä–Ķ–ī—Ć ‚ÄĘ OS queue ‚ÄĘ 32 –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é ‚ÄĘ 64 –ī–Ľ—Ź PVSCSI ‚ÄĘ –ė–∑–ľ–Ķ–Ĺ—Ź–Ķ—ā—Ā—Ź –≤ —Ä–Ķ–Ķ—Ā—ā—Ä–Ķ Windows ‚ÄĘ Adapter Queue ‚ÄĘ –ě–Ī—č—á–Ĺ–ĺ 1024+ –Ĺ–į –Ņ–ĺ—Ä—ā –ł –ļ—Ä–į–Ļ–Ĺ–Ķ —Ä–Ķ–ī–ļ–ĺ —ā—Ä–Ķ–Ī—É–Ķ—ā –≤–Ĺ–ł–ľ–į–Ĺ–ł—Ź ‚ÄĘ Per-LUN queue ‚ÄĘ –ě–Ī—č—á–Ĺ–ĺ 32 –ł–Ľ–ł 64 ‚ÄĘ Disk.SchedNumReqOutstanding
- 41. –ě—á–Ķ—Ä–Ķ–ī–ł IO ‚ÄĘ –ú–ĺ–Ĺ–ł—ā–ĺ—Ä–ł–Ĺ–≥ –ĺ—á–Ķ—Ä–Ķ–ī–Ķ–Ļ ‚ÄĘ DQLEN ‚Äď per-LUN queue ‚ÄĘ ACTV ‚Äď –į–ļ—ā–ł–≤–Ĺ—č–Ķ –ļ–ĺ–ľ–į–Ĺ–ī—č –≤ –ĺ–Ī—Ä–į–Ī–ĺ—ā–ļ–Ķ VMkernel ‚ÄĘ QUED ‚Äď –ļ–ĺ–ľ–į–Ĺ–ī—č, –∂–ī—É—Č–ł–Ķ –ĺ–Ī—Ä–į–Ī–ĺ—ā–ļ–ł –ł–Ľ–ł –Ņ–ĺ—Ā—ā–į–Ĺ–ĺ–≤–ļ–ł –≤ –ĺ—á–Ķ—Ä–Ķ–ī—Ć ‚ÄĘ %USED ‚Äď –Ņ—Ä–ĺ—Ü–Ķ–Ĺ—ā –ļ–ĺ–ľ–į–Ĺ–ī –≤ –ĺ—á–Ķ—Ä–Ķ–ī–ł –≤ –į–ļ—ā–ł–≤–Ĺ–ĺ–Ļ –ĺ–Ī—Ä–į–Ī–ĺ—ā–ļ–Ķ ‚ÄĘ LOAD ‚Äď –ĺ—ā–Ĺ–ĺ—ą–Ķ–Ĺ–ł–Ķ –Ĺ–į–≥—Ä—É–∂–Ķ–Ĺ–Ĺ–ĺ—Ā—ā–ł –ĺ—á–Ķ—Ä–Ķ–ī–ł –ļ –Ķ–Ķ —Ä–į–∑–ľ–Ķ—Ä—É ‚ÄĘ –ö–į–ļ –Ņ–ĺ—Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć ‚ÄĘ esxtop: u f F
- 42. –ě—á–Ķ—Ä–Ķ–ī–ł IO ‚ÄĘ –ě—á–Ķ–≤–ł–ī–Ĺ—č –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ—č —Ā LUN‚Äô–ĺ–ľ ‚ÄĘ QUED>0 –ĺ–∑–Ĺ–į—á–į–Ķ—ā, —á—ā–ĺ –ĺ—á–Ķ—Ä–Ķ–ī—Ć –ļ–ĺ–Ĺ—á–ł–Ľ–į—Ā—Ć ‚ÄĘ DAVG, KAVG, GAVG –≤—č—ą–Ķ –Ņ–ĺ—Ä–ĺ–≥–ĺ–≤ ‚ÄĘ DQLEN = 32, –į –Ĺ–Ķ —Ā—ā–į–Ĺ–ī–į—Ä—ā–Ĺ—č–Ķ 128. –†–Ķ–∑—É–Ľ—Ć—ā–į—ā —Ä–į–Ī–ĺ—ā—č Disk.SchedNumReqOutstanding
- 43. –õ–ł—ā–Ķ—Ä–į—ā—É—Ä–į ‚ÄĘ Troubleshooting vSphere Storage. Preston, Mike. ‚ÄĘ Information Storage and Management: Storing, Managing, and Protecting Digital Information in Classic, Virtualized, and Cloud Environments. EMC Education Services ‚ÄĘ Storage Implementation in vSphere 5.0 Technology Deep Dive. Mostafa Khalil
- 44. –í–ĺ–Ņ—Ä–ĺ—Ā—č? ‚ÄĘ –ź–Ĺ—ā–ĺ–Ĺ –Ė–Ī–į–Ĺ–ļ–ĺ–≤ ‚ÄĘ VCP 3/4/5 ‚ÄĘ VMware vExpert 2009-2014 ‚ÄĘ MCITP: SA + VA ‚ÄĘ EMC Cloud Architect Expert ‚ÄĘ anton@vadmin.ru ‚ÄĘ http://blog.vadmin.ru ‚ÄĘ https://communities.vmware.com/community/vmtn/vmug/fo rums/emea/russia