

















WaveNet
- 1. WaveNet: A Generative Model for Raw Audio TIS + Albert √„è䪷 2017/01/24 ◊Ó…œÀ√…˙ tsuguo_mogami@albert2005.co.jp
- 2. Why? ? Autoregressive model (e.g. PixelCNN)§¨¡º§Ø≥…π¶§∑§∆§§§Î°£ ? ? °˙ “Ù…˘§œ§…§¶§«§¢§Ì§¶§´°£ ? §Ω§Ï§ÚRNN§Ë§ÍÑø¬ µƒ§ CNN§«––§§§ø§§°£
- 3. Contributions ? §≥§Ï§fi§«§À§ §§∆∑Ÿ|§Œ“Ù…˘∫œ≥…°£ ? Dilated convolution§Ú 𧧰¢¥Û§≠§ ‹»›“∞§Ú≥÷§ƒ§À§‚Èv§Ô§È§∫ Ñø¬ µƒ§ •¢©`•≠•∆•Ø•¡•„ ? £®“Ù…˘’J◊R§‚£©
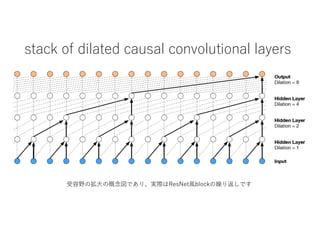
- 5. stack of dilated causal convolutional layers ‹»›“∞§Œíà¥Û§Œ∏≈ƒÓá̧«§¢§Í°¢ågÎH§œResNetÔLblock§Œ¿R§Í∑µ§∑§«§π
- 6. Repetition Structure 1,2,4,°≠,512, 1,2,4,°≠,512, 1,2,4,°≠,512. Suspected to be repeating the 1°≠512 blocks 16 times
- 8. residual block and the entire architecture §¡§Á§√§»§Ô§´§Í§À§Ø§§§Œ§«∆’Õ®§Œ±Ì”õ§À√˧≠§ §™§∑§fi§π
- 9. ???
- 10. Gated activation units ? ? K: layerindex, f for filter, g for gate ? : elementwise multipulication ? h: condition (person, text, etc.) ? Why? ? PixelCNN (1606.05328)§«å߻Π? §Ω§Ï“‘«∞§ŒCNN…˙≥…•‚•«•Î§¨PixelRNN§À¡”§√§ø§Œ§œ LSTM§Œ•≤©`•»òã‘ϧŒ§ª§§§¿§»øº§®§∆LSTMÀ∆§Œ•≤©` •»§Úå߻Χ∑§ø
- 12. Things not described and Guesses ? Kernel size of the dilation filters 2 ? Number of the layers (ResNet-blocks) 4*10~ 6*10 ? Number of the channels in hidden layers hundreds? 256? ? the other activation function in a Res-block? may be no ? Batch normalization no reason not to use ? Sampling frequency °Æat least 16kHz°Ø ? Where to let the skip connection out? Every 10? ? Skip connections have weights yes?
- 13. Experiments
- 14. Text-to-Speech (TTS) ? Single-speaker speech dataset ? North American English dataset: 24.6hr ? Mandarin Chinese dataset: 34.8hr ? Receptive field 240ms ? Ad hoc architecture as °˙ WaveNet Audio(t) Yet another model Liguistic feature h_i (possibly phoneme) Another model Fundamental frequency F0(t) duration(t) Liguistic feature h(t) °˘’쌃§»§œfl`§√§ø”õ∫≈§Ú π§√§∆§§§fi§π°£
- 15. TTS: Mean Opinion Score https://deepmind.com/blog/wavenet-generative-model-raw-audio/
- 16. Speech Recoginition ? TIMIT dataset (possibly ~4hrs) ? Add pooling layer after dilated convolution ? of 160x down sampling (Does it mean 7th layer?) ? Then a few non-causal convolutions. ? Loss to predict the next sample (same as ordinary WaveNet) ? And a loss to classify the frame ? 18.8PER, which is best score among raw-audio models.
- 17. End
- 18. (Multi-speaker) Speech Generation ? Conditioned on the speaker ? 44 hours of data (from 109 speakers)
- 19. TTS: Mean opinion score
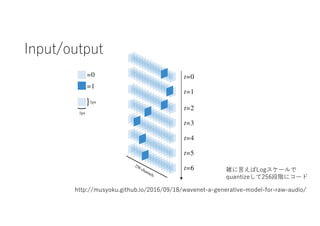
- 20. ¶Ã-law transformation (ITU-T, 1988) ? ? §«-1,1§ŒÈg§Ú256∑÷∏Ó§∑§∆§§§Î°£ ? ¥ÛÎj∞—§À§œ log §«•≥©`•…§∑§∆§§§Î§¿§±°£