Web scraping in python
19 likes17,563 views

It is a getting started guide to web scraping with Python and was presented at Dev Fest Google Developers Group Pune.
1 of 21
Downloaded 671 times



















Recommended
Tutorial on Web Scraping in Python
Tutorial on Web Scraping in PythonNithish Raghunandanan
Ã˝
Tutorial on Scraping Data from the Web with Python using Scrapy and BeautifulSoup at PyData Munich held at Burda Bootcamp.What is web scraping?
What is web scraping?Brijesh Prajapati
Ã˝
What is Web Scraping and What is it Used For? | Definition and Examples EXPLAINED
For More details Visit - https://hirinfotech.com
About Web scraping for Beginners - Introduction, Definition, Application and Best Practice in Deep Explained
What is Web Scraping or Crawling? and What it is used for? Complete introduction video.
Web Scraping is widely used today from small organizations to Fortune 500 companies. A wide range of applications of web scraping a few of them are listed here.
1. Lead Generation and Marketing Purpose
2. Product and Brand Monitoring
3. Brand or Product Market Reputation Analysis
4. Opening Mining and Sentimental Analysis
5. Gathering data for machine learning
6. Competitor Analysis
7. Finance and Stock Market Data analysis
8. Price Comparison for Product or Service
9. Building a product catalog
10. Fueling Job boards with Job listings
11. MAP compliance monitoring
12. Social media Monitor and Analysis
13. Content and News monitoring
14. Scrape search engine results for SEO monitoring
15. Business-specific application
------------
Basics of web scraping using python
Python Scraping LibraryIntroduction to Web Scraping using Python and Beautiful Soup
Introduction to Web Scraping using Python and Beautiful SoupTushar Mittal
Ã˝
These are the slides on the topic Introduction to Web Scraping using the Python 3 programming language. Topics covered are-
What is Web Scraping?
Need of Web Scraping
Real Life used cases .
Workflow and Libraries used.Web Scraping using Python | Web Screen Scraping
Web Scraping using Python | Web Screen ScrapingCynthiaCruz55
Ã˝
Web scraping is the process of collecting and parsing raw data from the Web, and the Python community has come up with some pretty powerful web scraping tools.
Imagine you have to pull a large amount of data from websites and you want to do it as quickly as possible. How would you do it without manually going to each website and getting the data? Well, “Web Scraping” is the answer. Web Scraping just makes this job easier and faster.
https://www.webscreenscraping.com/hire-python-developers.phpWhat is Web-scraping?
What is Web-scraping?Yu-Chang Ho
Ã˝
The slides for my presentation on BIG DATA EN LAS ESTADÍSTICAS OFICIALES - ECONOMÍA DIGITAL Y EL DESARROLLO, 2019 in Colombia. I was invited to give a talk about the technical aspect of web-scraping and data collection for online resources.Intro to web scraping with Python
Intro to web scraping with PythonMaris Lemba
Ã˝
Introduction to web scraping from static and Ajax generated web pages with Python, using urllib, BeautifulSoup, and Selenium. The slides are from a talk given at Vancouver PyLadies meetup on March 7, 2016.Web scraping
Web scrapingSelecto
Ã˝
Web scraping involves extracting data from human-readable web pages and converting it into structured data. There are several types of scraping including screen scraping, report mining, and web scraping. The process of web scraping typically involves using techniques like text pattern matching, HTML parsing, and DOM parsing to extract the desired data from web pages in an automated way. Common tools used for web scraping include Selenium, Import.io, Phantom.js, and Scrapy.Web Scraping
Web ScrapingCarlos Rodriguez
Ã˝
Web scraping involves extracting data from websites in an automated manner, typically using bots and crawlers. It involves fetching web pages and then parsing and extracting the desired data, which can then be stored in a local database or spreadsheet for later analysis. Common uses of web scraping include extracting contact information, product details, or other structured data from websites to use for purposes like monitoring prices, reviewing competition, or data mining. Newer forms of scraping may also listen to data feeds from servers using formats like JSON.Web Scraping and Data Extraction Service
Web Scraping and Data Extraction ServicePromptCloud
Ã˝
Learn more about Web Scraping and data extraction services. We have covered various points about scraping, extraction and converting un-structured data to structured format. For more info visit http://promptcloud.com/WEB Scraping.pptx
WEB Scraping.pptxShubham Jaybhaye
Ã˝
Shubham Pralhad presented on the topic of web scraping. The presentation covered what web scraping is, the workflow of a web scraper, useful libraries for scraping including BeautifulSoup, lxml, and re, and advantages of scraping over using an API. Web scraping involves getting a website using HTTP requests, parsing the HTML document using a parsing library, and storing the results. BeautifulSoup is easy to use but slow, lxml is very fast but not purely Python, and re is part of the standard library but requires learning regular expressions.Web Scraping Basics
Web Scraping BasicsKyle Banerjee
Ã˝
Web scraping is mostly about parsing and normalization. This presentation introduces people to harvesting methods and tools as well as handy utilities for extracting and normalizing dataPPT on Data Science Using Python
PPT on Data Science Using PythonNishantKumar1179
Ã˝
Best Data Science Ppt using Python
Data science is an inter-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data. Data science is related to data mining, machine learning and big data.Scraping data from the web and documents
Scraping data from the web and documentsTommy Tavenner
Ã˝
This document discusses web scraping and data extraction. It defines scraping as converting unstructured data like HTML or PDFs into machine-readable formats by separating data from formatting. Scraping legality depends on the purpose and terms of service - most public data is copyrighted but fair use may apply. The document outlines the anatomy of a scraper including loading documents, parsing, extracting data, and transforming it. It also reviews several scraping tools and libraries for different programming languages.CS8651 Internet Programming - Basics of HTML, HTML5, CSS
CS8651 Internet Programming - Basics of HTML, HTML5, CSSVigneshkumar Ponnusamy
Ã˝
Internet Programming Unit 1 Power Point Presentation:
Vigneshkumar. P
Assistant Professor
Karpagam Institute of Technology, AP/CSE
CoimbatoreMachine Learning
Machine LearningDarshan Ambhaikar
Ã˝
Machine learning, a branch of artificial intelligence, concerns the construction and study of systems that can learn from data.Web content mining
Web content miningDaminda Herath
Ã˝
Web content mining mines content from websites like text, images, audio, video and metadata to extract useful information. It examines both the content of websites as well as search results. Web content mining helps understand customer behavior, evaluate website performance, and boost business through research. It can classify content into categories like web page content mining and search result mining.Machine Learning and Real-World Applications
Machine Learning and Real-World ApplicationsMachinePulse
Ã˝
This presentation was created by Ajay, Machine Learning Scientist at MachinePulse, to present at a Meetup on Jan. 30, 2015. These slides provide an overview of widely used machine learning algorithms. The slides conclude with examples of real world applications.
Ajay Ramaseshan, is a Machine Learning Scientist at MachinePulse. He holds a Bachelors degree in Computer Science from NITK, Suratkhal and a Master in Machine Learning and Data Mining from Aalto University School of Science, Finland. He has extensive experience in the machine learning domain and has dealt with various real world problems.Introduction to Machine Learning
Introduction to Machine LearningLior Rokach
Ã˝
Here are the key calculations:
1) Probability that persons p and q will be at the same hotel on a given day d is 1/100 √ó 1/100 √ó 10-5 = 10-9, since there are 100 hotels and each person stays in a hotel with probability 10-5 on any given day.
2) Probability that p and q will be at the same hotel on given days d1 and d2 is (10-9) √ó (10-9) = 10-18, since the events are independent.The Full Stack Web Development
The Full Stack Web DevelopmentSam Dias
Ã˝
Become a complete developer by learning front-end and back-end technologies in this Full Stack Web Developer Course. These are just a few of the 40 different apps that are part of this brilliant course. With this course, you will not only learn a whole lot of different technologies, but also become a complete developer.
So, what are you waiting for? Let’s become a Master Developer with this Full Stack Web Development Bundle Course.
For More Info : https://www.eduonix.com/courses/Web-Development/the-full-stack-web-development?coupon_code=kedu15Machine Learning presentation.
Machine Learning presentation.butest
Ã˝
Machine learning involves developing systems that can learn from data and experience. The document discusses several machine learning techniques including decision tree learning, rule induction, case-based reasoning, supervised and unsupervised learning. It also covers representations, learners, critics and applications of machine learning such as improving search engines and developing intelligent tutoring systems.Lecture-1: Introduction to web engineering - course overview and grading scheme
Lecture-1: Introduction to web engineering - course overview and grading schemeMubashir Ali
Ã˝
This document provides an introduction to the course "Introduction to Web Engineering". It discusses the need for applying systematic engineering principles to web application development to avoid common issues like cost overruns and missed objectives. The document defines web engineering and outlines categories of web applications of varying complexity, from document-centric to ubiquitous applications. Grading policies are also covered.Information retrieval introduction
Information retrieval introductionnimmyjans4
Ã˝
This document provides an overview of information retrieval models. It begins with definitions of information retrieval and how it differs from data retrieval. It then discusses the retrieval process and logical representations of documents. A taxonomy of IR models is presented including classic, structured, and browsing models. Boolean, vector, and probabilistic models are explained as examples of classic models. The document concludes with descriptions of ad-hoc retrieval and filtering tasks and formal characteristics of IR models.Data science life cycle
Data science life cycleManoj Mishra
Ã˝
Data Science Life Cycle - With Examples. These slides were used for Data Science Meetup - Dubai (November 25, 2017)An introduction to Machine Learning
An introduction to Machine Learningbutest
Ã˝
This document provides an introduction to machine learning. It discusses how machine learning allows computers to learn from experience to improve their performance on tasks. Supervised learning is described, where the goal is to learn a function that maps inputs to outputs from a labeled dataset. Cross-validation techniques like the test set method, leave-one-out cross-validation, and k-fold cross-validation are introduced to evaluate model performance without overfitting. Applications of machine learning like medical diagnosis, recommendation systems, and autonomous driving are briefly outlined.Java Servlets
Java ServletsBG Java EE Course
Ã˝
This document provides an overview of Java servlets technology, including:
1. What Java servlets are and their main purposes and advantages such as portability, power, and integration with server APIs.
2. Key aspects of servlet architecture like the servlet lifecycle, the HttpServletRequest and HttpServletResponse objects, and how different HTTP methods map to servlet methods.
3. Examples of simple servlets that process parameters, maintain a session counter, and examples of deploying servlets in Eclipse IDE.Introduction to Python
Introduction to PythonNowell Strite
Ã˝
This document provides an introduction and overview of the Python programming language. It covers Python's history and key features such as being object-oriented, dynamically typed, batteries included, and focusing on readability. It also discusses Python's syntax, types, operators, control flow, functions, classes, imports, error handling, documentation tools, and popular frameworks/IDEs. The document is intended to give readers a high-level understanding of Python.Ajax ppt
Ajax pptOECLIB Odisha Electronics Control Library
Ã˝
This document discusses AJAX (Asynchronous JavaScript and XML). It defines AJAX as a group of interrelated web development techniques used on the client-side to create interactive web applications. AJAX allows web pages to be updated asynchronously by exchanging small amounts of data with the server without reloading the entire page. The document outlines the technologies that power AJAX like HTML, CSS, XML, JavaScript, and XMLHttpRequest and how they work together to enable asynchronous updates on web pages.Artificial Intelligence with Python | Edureka
Artificial Intelligence with Python | EdurekaEdureka!
Ã˝
YouTube Link: https://youtu.be/7O60HOZRLng
* Machine Learning Engineer Masters Program: https://www.edureka.co/masters-program/machine-learning-engineer-training *
This Edureka PPT on "Artificial Intelligence With Python" will provide you with a comprehensive and detailed knowledge of Artificial Intelligence concepts with hands-on examples.
Follow us to never miss an update in the future.
YouTube: https://www.youtube.com/user/edurekaIN
Instagram: https://www.instagram.com/edureka_learning/
Facebook: https://www.facebook.com/edurekaIN/
Twitter: https://twitter.com/edurekain
LinkedIn: https://www.linkedin.com/company/edureka
Castbox: https://castbox.fm/networks/505?country=in
Getting started with Scrapy in Python
Getting started with Scrapy in PythonViren Rajput
Ã˝
This document summarizes web scraping and introduces the Scrapy framework. It defines web scraping as extracting information from websites when APIs are not available or data needs periodic extraction. The speaker then discusses experiments with scraping in Python using libraries like BeautifulSoup and lxml. Scrapy is introduced as a fast, high-level scraping framework that allows defining spiders to extract needed data from websites and run scraping jobs. Key benefits of Scrapy like simplicity, speed, extensibility and documentation are highlighted.Guide for web scraping with Python libraries_ Beautiful Soup, Scrapy, and mor...
Guide for web scraping with Python libraries_ Beautiful Soup, Scrapy, and mor...ThinkODC
Ã˝
Choosing a Python library for web scraping largely depends on your specific objectives and the complexity of the task. Beautiful Soup or Requests can handle simpler projects. For more complex use cases, especially with dynamic content, Scrapy or Selenium are better options. Moreover, MechanicalSoup offers a straightforward way to work with HTTP requests for simpler tasks.
More Related Content
What's hot (20)
Web Scraping and Data Extraction Service
Web Scraping and Data Extraction ServicePromptCloud
Ã˝
Learn more about Web Scraping and data extraction services. We have covered various points about scraping, extraction and converting un-structured data to structured format. For more info visit http://promptcloud.com/WEB Scraping.pptx
WEB Scraping.pptxShubham Jaybhaye
Ã˝
Shubham Pralhad presented on the topic of web scraping. The presentation covered what web scraping is, the workflow of a web scraper, useful libraries for scraping including BeautifulSoup, lxml, and re, and advantages of scraping over using an API. Web scraping involves getting a website using HTTP requests, parsing the HTML document using a parsing library, and storing the results. BeautifulSoup is easy to use but slow, lxml is very fast but not purely Python, and re is part of the standard library but requires learning regular expressions.Web Scraping Basics
Web Scraping BasicsKyle Banerjee
Ã˝
Web scraping is mostly about parsing and normalization. This presentation introduces people to harvesting methods and tools as well as handy utilities for extracting and normalizing dataPPT on Data Science Using Python
PPT on Data Science Using PythonNishantKumar1179
Ã˝
Best Data Science Ppt using Python
Data science is an inter-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data. Data science is related to data mining, machine learning and big data.Scraping data from the web and documents
Scraping data from the web and documentsTommy Tavenner
Ã˝
This document discusses web scraping and data extraction. It defines scraping as converting unstructured data like HTML or PDFs into machine-readable formats by separating data from formatting. Scraping legality depends on the purpose and terms of service - most public data is copyrighted but fair use may apply. The document outlines the anatomy of a scraper including loading documents, parsing, extracting data, and transforming it. It also reviews several scraping tools and libraries for different programming languages.CS8651 Internet Programming - Basics of HTML, HTML5, CSS
CS8651 Internet Programming - Basics of HTML, HTML5, CSSVigneshkumar Ponnusamy
Ã˝
Internet Programming Unit 1 Power Point Presentation:
Vigneshkumar. P
Assistant Professor
Karpagam Institute of Technology, AP/CSE
CoimbatoreMachine Learning
Machine LearningDarshan Ambhaikar
Ã˝
Machine learning, a branch of artificial intelligence, concerns the construction and study of systems that can learn from data.Web content mining
Web content miningDaminda Herath
Ã˝
Web content mining mines content from websites like text, images, audio, video and metadata to extract useful information. It examines both the content of websites as well as search results. Web content mining helps understand customer behavior, evaluate website performance, and boost business through research. It can classify content into categories like web page content mining and search result mining.Machine Learning and Real-World Applications
Machine Learning and Real-World ApplicationsMachinePulse
Ã˝
This presentation was created by Ajay, Machine Learning Scientist at MachinePulse, to present at a Meetup on Jan. 30, 2015. These slides provide an overview of widely used machine learning algorithms. The slides conclude with examples of real world applications.
Ajay Ramaseshan, is a Machine Learning Scientist at MachinePulse. He holds a Bachelors degree in Computer Science from NITK, Suratkhal and a Master in Machine Learning and Data Mining from Aalto University School of Science, Finland. He has extensive experience in the machine learning domain and has dealt with various real world problems.Introduction to Machine Learning
Introduction to Machine LearningLior Rokach
Ã˝
Here are the key calculations:
1) Probability that persons p and q will be at the same hotel on a given day d is 1/100 √ó 1/100 √ó 10-5 = 10-9, since there are 100 hotels and each person stays in a hotel with probability 10-5 on any given day.
2) Probability that p and q will be at the same hotel on given days d1 and d2 is (10-9) √ó (10-9) = 10-18, since the events are independent.The Full Stack Web Development
The Full Stack Web DevelopmentSam Dias
Ã˝
Become a complete developer by learning front-end and back-end technologies in this Full Stack Web Developer Course. These are just a few of the 40 different apps that are part of this brilliant course. With this course, you will not only learn a whole lot of different technologies, but also become a complete developer.
So, what are you waiting for? Let’s become a Master Developer with this Full Stack Web Development Bundle Course.
For More Info : https://www.eduonix.com/courses/Web-Development/the-full-stack-web-development?coupon_code=kedu15Machine Learning presentation.
Machine Learning presentation.butest
Ã˝
Machine learning involves developing systems that can learn from data and experience. The document discusses several machine learning techniques including decision tree learning, rule induction, case-based reasoning, supervised and unsupervised learning. It also covers representations, learners, critics and applications of machine learning such as improving search engines and developing intelligent tutoring systems.Lecture-1: Introduction to web engineering - course overview and grading scheme
Lecture-1: Introduction to web engineering - course overview and grading schemeMubashir Ali
Ã˝
This document provides an introduction to the course "Introduction to Web Engineering". It discusses the need for applying systematic engineering principles to web application development to avoid common issues like cost overruns and missed objectives. The document defines web engineering and outlines categories of web applications of varying complexity, from document-centric to ubiquitous applications. Grading policies are also covered.Information retrieval introduction
Information retrieval introductionnimmyjans4
Ã˝
This document provides an overview of information retrieval models. It begins with definitions of information retrieval and how it differs from data retrieval. It then discusses the retrieval process and logical representations of documents. A taxonomy of IR models is presented including classic, structured, and browsing models. Boolean, vector, and probabilistic models are explained as examples of classic models. The document concludes with descriptions of ad-hoc retrieval and filtering tasks and formal characteristics of IR models.Data science life cycle
Data science life cycleManoj Mishra
Ã˝
Data Science Life Cycle - With Examples. These slides were used for Data Science Meetup - Dubai (November 25, 2017)An introduction to Machine Learning
An introduction to Machine Learningbutest
Ã˝
This document provides an introduction to machine learning. It discusses how machine learning allows computers to learn from experience to improve their performance on tasks. Supervised learning is described, where the goal is to learn a function that maps inputs to outputs from a labeled dataset. Cross-validation techniques like the test set method, leave-one-out cross-validation, and k-fold cross-validation are introduced to evaluate model performance without overfitting. Applications of machine learning like medical diagnosis, recommendation systems, and autonomous driving are briefly outlined.Java Servlets
Java ServletsBG Java EE Course
Ã˝
This document provides an overview of Java servlets technology, including:
1. What Java servlets are and their main purposes and advantages such as portability, power, and integration with server APIs.
2. Key aspects of servlet architecture like the servlet lifecycle, the HttpServletRequest and HttpServletResponse objects, and how different HTTP methods map to servlet methods.
3. Examples of simple servlets that process parameters, maintain a session counter, and examples of deploying servlets in Eclipse IDE.Introduction to Python
Introduction to PythonNowell Strite
Ã˝
This document provides an introduction and overview of the Python programming language. It covers Python's history and key features such as being object-oriented, dynamically typed, batteries included, and focusing on readability. It also discusses Python's syntax, types, operators, control flow, functions, classes, imports, error handling, documentation tools, and popular frameworks/IDEs. The document is intended to give readers a high-level understanding of Python.Ajax ppt
Ajax pptOECLIB Odisha Electronics Control Library
Ã˝
This document discusses AJAX (Asynchronous JavaScript and XML). It defines AJAX as a group of interrelated web development techniques used on the client-side to create interactive web applications. AJAX allows web pages to be updated asynchronously by exchanging small amounts of data with the server without reloading the entire page. The document outlines the technologies that power AJAX like HTML, CSS, XML, JavaScript, and XMLHttpRequest and how they work together to enable asynchronous updates on web pages.Artificial Intelligence with Python | Edureka
Artificial Intelligence with Python | EdurekaEdureka!
Ã˝
YouTube Link: https://youtu.be/7O60HOZRLng
* Machine Learning Engineer Masters Program: https://www.edureka.co/masters-program/machine-learning-engineer-training *
This Edureka PPT on "Artificial Intelligence With Python" will provide you with a comprehensive and detailed knowledge of Artificial Intelligence concepts with hands-on examples.
Follow us to never miss an update in the future.
YouTube: https://www.youtube.com/user/edurekaIN
Instagram: https://www.instagram.com/edureka_learning/
Facebook: https://www.facebook.com/edurekaIN/
Twitter: https://twitter.com/edurekain
LinkedIn: https://www.linkedin.com/company/edureka
Castbox: https://castbox.fm/networks/505?country=in
Similar to Web scraping in python (20)
Getting started with Scrapy in Python
Getting started with Scrapy in PythonViren Rajput
Ã˝
This document summarizes web scraping and introduces the Scrapy framework. It defines web scraping as extracting information from websites when APIs are not available or data needs periodic extraction. The speaker then discusses experiments with scraping in Python using libraries like BeautifulSoup and lxml. Scrapy is introduced as a fast, high-level scraping framework that allows defining spiders to extract needed data from websites and run scraping jobs. Key benefits of Scrapy like simplicity, speed, extensibility and documentation are highlighted.Guide for web scraping with Python libraries_ Beautiful Soup, Scrapy, and mor...
Guide for web scraping with Python libraries_ Beautiful Soup, Scrapy, and mor...ThinkODC
Ã˝
Choosing a Python library for web scraping largely depends on your specific objectives and the complexity of the task. Beautiful Soup or Requests can handle simpler projects. For more complex use cases, especially with dynamic content, Scrapy or Selenium are better options. Moreover, MechanicalSoup offers a straightforward way to work with HTTP requests for simpler tasks.
Scrappy
ScrappyVishwas N
Ã˝
The document discusses web scraping and provides an overview of the topic. It introduces the author and their experience before providing a brief history of web scraping, noting it involves extracting data from websites using automated processes. The document then mentions HTML, CSS, and frameworks like Beautiful Soup and Scrapy that can be used for web scraping. It emphasizes choosing the right tools and experimenting to get started with web scraping.Web scraping
Web scrapingAshley Davis
Ã˝
∫›∫›fl£s from my talk on web scraping to BrisJS the Brisbane JavaScript meetup.
You can find the code on GitHub: https://github.com/ashleydavis/brisjs-web-scraping-talkScraping the web with Laravel, Dusk, Docker, and PHP
Scraping the web with Laravel, Dusk, Docker, and PHPPaul Redmond
Ã˝
Jumpstart your web scraping automation in the cloud with Laravel Dusk, Docker, and friends. We will discuss the types of web scraping tools, the best tools for the job, and how to deal with running selenium in Docker.
Code examples @ https://github.com/paulredmond/scraping-with-laravel-duskCommon SEO Mistakes During Site Relaunches, Redesigns, Migrations (2018) 
Common SEO Mistakes During Site Relaunches, Redesigns, Migrations (2018) Melanie Phung
Ã˝
Nine (mostly technical) ways to ruin your search engine rankings and kill your traffic with a site redesign, relaunch or migration … and how to avoid them. This talk was originally presented at WordPress DC.
Python in Industry
Python in IndustryDharmit Shah
Ã˝
∫›∫›fl£s from the talk given at Nirma University. Audience comprised of fifth semester Electronics & Communications (EC) Engineering students.Web stats
Web statsAndrew Stevens
Ã˝
Web analytics tools like access logs, JavaScript-based solutions, and web bugs can provide information about web activity, but all have limitations. Access logs record actual interactions but are impacted by bots and caching. JavaScript-based solutions rely on browser capabilities and settings and may not record all interactions. Both are affected by differing user behaviors. It's important to understand the limitations of the analytic method used and maintain skepticism of results, as the metrics may not precisely measure activity due to various issues like one-directional links and bot traffic.Web mining
Web miningRenusoni8
Ã˝
This document discusses web mining and its various types and applications. It defines web mining as the extraction of useful information from web documents and services. There are three main types of web mining: web content mining analyzes the content of web pages, web structure mining examines the link structure between pages, and web usage mining studies user access patterns by analyzing server logs. The challenges and pros of web mining are also covered, along with its applications in areas like e-commerce, business intelligence, and knowledge management.Search engine and web crawler
Search engine and web crawlervinay arora
Ã˝
This document discusses search engines and web crawling. It begins by defining a search engine as a searchable database that collects information from web pages on the internet by indexing them and storing the results. It then discusses the need for search engines and provides examples. The document outlines how search engines work using spiders to crawl websites, index pages, and power search functionality. It defines web crawlers and their role in crawling websites. Key factors that affect web crawling like robots.txt, sitemaps, and manual submission are covered. Related areas like indexing, searching algorithms, and data mining are summarized. The document demonstrates how crawlers can download full websites and provides examples of open source crawlers.An EyeWitness View into your Network
An EyeWitness View into your NetworkCTruncer
Ã˝
This document summarizes the EyeWitness tool for automated network discovery and host identification. It discusses the typical assessment lifecycle, initial discovery and recon steps using Nmap and Nessus, and the need to automate analysis of large lists of web servers. The development of EyeWitness is described, from an initial proof of concept to version 2.0, which improved modularity, added protocol support, signature-based categorization and the ability to resume incomplete scans. Future work may include additional modules, protocols, and optical character recognition.Integrating Structured Data (to an SEO Plan) for the Win _ WTSWorkshop '23.pptx
Integrating Structured Data (to an SEO Plan) for the Win _ WTSWorkshop '23.pptxBegum Kaya
Ã˝
This document provides an overview of structured data and how to plan and implement it effectively. It discusses the giant global graph and semantic web concepts. Schema.org is introduced as a way to add structured data tags to pages. The benefits of structured data like improved rankings and user experience are outlined. The document then covers how to plan structured data by auditing pages, identifying appropriate schema types and properties. Implementation tips around templating, testing and monitoring structured data are provided. Common pitfalls to avoid are also highlighted.Web Scraping With Python
Web Scraping With PythonRobert Dempsey
Ã˝
This document discusses web scraping using Python. It provides an overview of scraping tools and techniques, including checking terms of service, using libraries like BeautifulSoup and Scrapy, dealing with anti-scraping measures, and exporting data. General steps for scraping are outlined, and specific examples are provided for scraping a website using a browser extension and scraping LinkedIn company pages using Python.What You Need to Know About Technical SEO
What You Need to Know About Technical SEONiki Mosier
Ã˝
This document provides an overview and agenda for a technical SEO workshop. It discusses various technical SEO topics like crawling and indexing websites, redirects, structured data, page speed, and tools for auditing sites. The agenda includes sections on technical SEO basics, a technical audit walkthrough, and a technical SEO scorecard. Attendees will learn about making their sites easy to crawl, reducing crawl errors, optimizing page speed, and using tools to improve their technical SEO.Presentation 10all
Presentation 10allguestaa4c059
Ã˝
Crawlers and spiders automatically retrieve web pages and send them to indexing software. The indexing software extracts and analyzes information from pages to build an index of keywords. Meta search engines transmit search terms to multiple search engines and integrate the results into a single page. Search engines present results differently than databases, which contain URLs and keywords but not full documents.Data Studio for SEOs: Reporting Automation Tips - Weekly SEO with Lazarina Stoy
Data Studio for SEOs: Reporting Automation Tips - Weekly SEO with Lazarina StoyLazarinaStoyanova
Ã˝
In this webinar, I will go through the benefits and limitations of Data Studio, tips and tricks for turning spreadsheets into cool reports, and share some hot dashboard templatesBig data at scrapinghub
Big data at scrapinghubDana Brophy
Ã˝
Presentation from Shane Evans, co-founder of Scrapinghub, Cork Big Data & Analytics Group, 4th April 2016Destination Documentation: How Not to Get Lost in Your Org
Destination Documentation: How Not to Get Lost in Your Orgcsupilowski
Ã˝
We hope you walk away with some tips and tools to make sure you don't get lost in your org, and more importantly, can lead the way for others!SEO for Large/Enterprise Websites - Data & Tech Side
SEO for Large/Enterprise Websites - Data & Tech SideDominic Woodman
Ã˝
There is a lot to cover about SEO for large websites/enterprise.
In this talk we'll cover primarily the data analysis and the technical SEO side of things. In future presentations we'll look at more.Week 1 - Interactive News Editing and Producing
Week 1 - Interactive News Editing and Producingkurtgessler
Ã˝
This document provides an overview and introduction to an interactive news editing and production class. It includes an agenda for the first class covering introductions, class logistics, how the web works, HTML basics, narrative storytelling, and assigning homework. The class will focus on hands-on workshops and assignments with no final project. Grading will be based on homework, workshops, and engagement. Students are expected to have certain software and accounts. The core concepts that will be covered include the fundamentals of how the web works, HTML, CSS, digital storytelling, data visualization, social media, and analytics.Recently uploaded (20)
Field Device Management Market Report 2030 - TechSci Research
Field Device Management Market Report 2030 - TechSci ResearchVipin Mishra
Ã˝
The Global Field Device Management (FDM) Market is expected to experience significant growth in the forecast period from 2026 to 2030, driven by the integration of advanced technologies aimed at improving industrial operations.
üìä According to TechSci Research, the Global Field Device Management Market was valued at USD 1,506.34 million in 2023 and is anticipated to grow at a CAGR of 6.72% through 2030. FDM plays a vital role in the centralized oversight and optimization of industrial field devices, including sensors, actuators, and controllers.
Key tasks managed under FDM include:
Configuration
Monitoring
Diagnostics
Maintenance
Performance optimization
FDM solutions offer a comprehensive platform for real-time data collection, analysis, and decision-making, enabling:
Proactive maintenance
Predictive analytics
Remote monitoring
By streamlining operations and ensuring compliance, FDM enhances operational efficiency, reduces downtime, and improves asset reliability, ultimately leading to greater performance in industrial processes. FDM’s emphasis on predictive maintenance is particularly important in ensuring the long-term sustainability and success of industrial operations.
For more information, explore the full report: https://shorturl.at/EJnzR
Major companies operating in GlobalÃ˝Field Device Management Market are:
General Electric Co
Siemens AG
ABB Ltd
Emerson Electric Co
Aveva Group Ltd
Schneider Electric SE
STMicroelectronics Inc
Techno Systems Inc
Semiconductor Components Industries LLC
International Business Machines Corporation (IBM)
#FieldDeviceManagement #IndustrialAutomation #PredictiveMaintenance #TechInnovation #IndustrialEfficiency #RemoteMonitoring #TechAdvancements #MarketGrowth #OperationalExcellence #SensorsAndActuatorsBuild with AI on Google Cloud Session #4
Build with AI on Google Cloud Session #4Margaret Maynard-Reid
Ã˝
This is session #4 of the 5-session online study series with Google Cloud, where we take you onto the journey learning generative AI. You’ll explore the dynamic landscape of Generative AI, gaining both theoretical insights and practical know-how of Google Cloud GenAI tools such as Gemini, Vertex AI, AI agents and Imagen 3. L01 Introduction to Nanoindentation - What is hardness
L01 Introduction to Nanoindentation - What is hardnessRostislavDaniel
Ã˝
Introduction to NanoindentationHow Discord Indexes Trillions of Messages: Scaling Search Infrastructure by V...
How Discord Indexes Trillions of Messages: Scaling Search Infrastructure by V...ScyllaDB
Ã˝
This talk shares how Discord scaled their message search infrastructure using Rust, Kubernetes, and a multi-cluster Elasticsearch architecture to achieve better performance, operability, and reliability, while also enabling new search features for Discord users.Fl studio crack version 12.9 Free Download
Fl studio crack version 12.9 Free Downloadkherorpacca127
Ã˝
Google the copied link üëâüèªüëâüèª https://activationskey.com/download-latest-setup/
üëàüèªüëàüèª
The ultimate guide to FL Studio 12.9 Crack, the revolutionary digital audio workstation that empowers musicians and producers of all levels. This software has become a cornerstone in the music industry, offering unparalleled creative capabilities, cutting-edge features, and an intuitive workflow.
With FL Studio 12.9 Crack, you gain access to a vast arsenal of instruments, effects, and plugins, seamlessly integrated into a user-friendly interface. Its signature Piano Roll Editor provides an exceptional level of musical expression, while the advanced automation features empower you to create complex and dynamic compositions.Brave Browser Crack 1.45.133 Activated 2025
Brave Browser Crack 1.45.133 Activated 2025kherorpacca00126
Ã˝
https://ncracked.com/7961-2/
Note: >> Please copy the link and paste it into Google New Tab now Download link
Brave is a free Chromium browser developed for Win Downloads, macOS and Linux systems that allows users to browse the internet in a safer, faster and more secure way than its competition. Designed with security in mind, Brave automatically blocks ads and trackers which also makes it faster,
As Brave naturally blocks unwanted content from appearing in your browser, it prevents these trackers and pop-ups from slowing Download your user experience. It's also designed in a way that strips Downloaden which data is being loaded each time you use it. Without these components
Unlocking DevOps Secuirty :Vault & Keylock
Unlocking DevOps Secuirty :Vault & KeylockHusseinMalikMammadli
Ã˝
DevOps iş təhlükəsizliyi sizi maraqlandırır? İstər developer, istər təhlükəsizlik mühəndisi, istərsə də DevOps həvəskarı olun, bu tədbir şəbəkələşmək, biliklərinizi bölüşmək və DevSecOps sahəsində ən son təcrübələri öyrənmək üçün mükəmməl fürsətdir!
Bu workshopda DevOps infrastrukturlarının təhlükəsizliyini necə artırmaq barədə danışacayıq. DevOps sistemləri qurularkən avtomatlaşdırılmış, yüksək əlçatan və etibarlı olması ilə yanaşı, həm də təhlükəsizlik məsələləri nəzərə alınmalıdır. Bu səbəbdən, DevOps komandolarının təhlükəsizliyə yönəlmiş praktikalara riayət etməsi vacibdir.Replacing RocksDB with ScyllaDB in Kafka Streams by Almog Gavra
Replacing RocksDB with ScyllaDB in Kafka Streams by Almog GavraScyllaDB
Ã˝
Learn how Responsive replaced embedded RocksDB with ScyllaDB in Kafka Streams, simplifying the architecture and unlocking massive availability and scale. The talk covers unbundling stream processors, key ScyllaDB features tested, and lessons learned from the transition.Computational Photography: How Technology is Changing Way We Capture the World
Computational Photography: How Technology is Changing Way We Capture the WorldHusseinMalikMammadli
Ã˝
üì∏ Computational Photography (Computer Vision/Image): How Technology is Changing the Way We Capture the World
Heç düşünmüsünüzmü, müasir smartfonlar və kameralar necə bu qədər gözəl görüntülər yaradır? Bunun sirri Computational Fotoqrafiyasında(Computer Vision/Imaging) gizlidir—şəkilləri çəkmə və emal etmə üsulumuzu təkmilləşdirən, kompüter elmi ilə fotoqrafiyanın inqilabi birləşməsi.What Makes "Deep Research"? A Dive into AI Agents
What Makes "Deep Research"? A Dive into AI AgentsZilliz
Ã˝
About this webinar:
Unless you live under a rock, you will have heard about OpenAI’s release of Deep Research on Feb 2, 2025. This new product promises to revolutionize how we answer questions requiring the synthesis of large amounts of diverse information. But how does this technology work, and why is Deep Research a noticeable improvement over previous attempts? In this webinar, we will examine the concepts underpinning modern agents using our basic clone, Deep Searcher, as an example.
Topics covered:
Tool use
Structured output
Reflection
Reasoning models
Planning
Types of agentic memoryUiPath Agentic Automation Capabilities and Opportunities
UiPath Agentic Automation Capabilities and OpportunitiesDianaGray10
Ã˝
Learn what UiPath Agentic Automation capabilities are and how you can empower your agents with dynamic decision making. In this session we will cover these topics:
What do we mean by Agents
Components of Agents
Agentic Automation capabilities
What Agentic automation delivers and AI Tools
Identifying Agent opportunities
‚ùì If you have any questions or feedback, please refer to the "Women in Automation 2025" dedicated Forum thread. You can find there extra details and updates.Technology use over time and its impact on consumers and businesses.pptx
Technology use over time and its impact on consumers and businesses.pptxkaylagaze
Ã˝
In this presentation, I will discuss how technology has changed consumer behaviour and its impact on consumers and businesses. I will focus on internet access, digital devices, how customers search for information and what they buy online, video consumption, and lastly consumer trends.
Revolutionizing-Government-Communication-The-OSWAN-Success-Story
Revolutionizing-Government-Communication-The-OSWAN-Success-Storyssuser52ad5e
Ã˝
üåê ùó¢ùó¶ùó™ùóîùó° ùó¶ùòÇùó∞ùó∞ùó≤ùòÄùòÄ ùó¶ùòÅùóºùóøùòÜ üöÄ
ùó¢ùó∫ùóªùó∂ùóπùó∂ùóªùó∏ ùóßùó≤ùó∞ùóµùóªùóºùóπùóºùó¥ùòÜÃ˝ is proud to be a part of the ùó¢ùó±ùó∂ùòÄùóµùóÆ ùó¶ùòÅùóÆùòÅùó≤ ùó™ùó∂ùó±ùó≤ ùóîùóøùó≤ùóÆ ùó°ùó≤ùòÅùòÑùóºùóøùó∏ (ùó¢ùó¶ùó™ùóîùó°) success story! By delivering seamless, secure, and high-speed connectivity, OSWAN has revolutionized e-ùóöùóºùòÉùó≤ùóøùóªùóÆùóªùó∞ùó≤ ùó∂ùóª ùó¢ùó±ùó∂ùòÄùóµùóÆ, enabling efficient communication between government departments and enhancing citizen services.
Through our innovative solutions, ùó¢ùó∫ùóªùó∂ùóπùó∂ùóªùó∏ ùóßùó≤ùó∞ùóµùóªùóºùóπùóºùó¥ùòÜ has contributed to making governance smarter, faster, and more transparent. This milestone reflects our commitment to driving digital transformation and empowering communities.
üì° ùóñùóºùóªùóªùó≤ùó∞ùòÅùó∂ùóªùó¥ ùó¢ùó±ùó∂ùòÄùóµùóÆ, ùóòùó∫ùóΩùóºùòÑùó≤ùóøùó∂ùóªùó¥ ùóöùóºùòÉùó≤ùóøùóªùóÆùóªùó∞ùó≤!
DevNexus - Building 10x Development Organizations.pdf
DevNexus - Building 10x Development Organizations.pdfJustin Reock
Ã˝
Developer Experience is Dead! Long Live Developer Experience!
In this keynote-style session, we’ll take a detailed, granular look at the barriers to productivity developers face today and modern approaches for removing them. 10x developers may be a myth, but 10x organizations are very real, as proven by the influential study performed in the 1980s, ‘The Coding War Games.’
Right now, here in early 2025, we seem to be experiencing YAPP (Yet Another Productivity Philosophy), and that philosophy is converging on developer experience. It seems that with every new method, we invent to deliver products, whether physical or virtual, we reinvent productivity philosophies to go alongside them.
But which of these approaches works? DORA? SPACE? DevEx? What should we invest in and create urgency behind today so we don’t have the same discussion again in a decade?Understanding Traditional AI with Custom Vision & MuleSoft.pptx
Understanding Traditional AI with Custom Vision & MuleSoft.pptxshyamraj55
Ã˝
Understanding Traditional AI with Custom Vision & MuleSoft.pptx | ### ∫›∫›fl£ Deck Description:
This presentation features Atul, a Senior Solution Architect at NTT DATA, sharing his journey into traditional AI using Azure's Custom Vision tool. He discusses how AI mimics human thinking and reasoning, differentiates between predictive and generative AI, and demonstrates a real-world use case. The session covers the step-by-step process of creating and training an AI model for image classification and object detection—specifically, an ad display that adapts based on the viewer's gender. Atulavan highlights the ease of implementation without deep software or programming expertise. The presentation concludes with a Q&A session addressing technical and privacy concerns.Unlock AI Creativity: Image Generation with DALL·E
Unlock AI Creativity: Image Generation with DALL·EExpeed Software
Ã˝
Discover the power of AI image generation with DALL·E, an advanced AI model that transforms text prompts into stunning, high-quality visuals. This presentation explores how artificial intelligence is revolutionizing digital creativity, from graphic design to content creation and marketing. Learn about the technology behind DALL·E, its real-world applications, and how businesses can leverage AI-generated art for innovation. Whether you're a designer, developer, or marketer, this guide will help you unlock new creative possibilities with AI-driven image synthesis.TrustArc Webinar - Building your DPIA/PIA Program: Best Practices & Tips
TrustArc Webinar - Building your DPIA/PIA Program: Best Practices & TipsTrustArc
Ã˝
Understanding DPIA/PIAs and how to implement them can be the key to embedding privacy in the heart of your organization as well as achieving compliance with multiple data protection / privacy laws, such as GDPR and CCPA. Indeed, the GDPR mandates Privacy by Design and requires documented Data Protection Impact Assessments (DPIAs) for high risk processing and the EU AI Act requires an assessment of fundamental rights.
How can you build this into a sustainable program across your business? What are the similarities and differences between PIAs and DPIAs? What are the best practices for integrating PIAs/DPIAs into your data privacy processes?
Whether you're refining your compliance framework or looking to enhance your PIA/DPIA execution, this session will provide actionable insights and strategies to ensure your organization meets the highest standards of data protection.
Join our panel of privacy experts as we explore:
- DPIA & PIA best practices
- Key regulatory requirements for conducting PIAs and DPIAs
- How to identify and mitigate data privacy risks through comprehensive assessments
- Strategies for ensuring documentation and compliance are robust and defensible
- Real-world case studies that highlight common pitfalls and practical solutionsFuture-Proof Your Career with AI Options
Future-Proof Your Career with AI OptionsDianaGray10
Ã˝
Learn about the difference between automation, AI and agentic and ways you can harness these to further your career. In this session you will learn:
Introduction to automation, AI, agentic
Trends in the marketplace
Take advantage of UiPath training and certification
In demand skills needed to strategically position yourself to stay ahead
‚ùì If you have any questions or feedback, please refer to the "Women in Automation 2025" dedicated Forum thread. You can find there extra details and updates.THE BIG TEN BIOPHARMACEUTICAL MNCs: GLOBAL CAPABILITY CENTERS IN INDIA
THE BIG TEN BIOPHARMACEUTICAL MNCs: GLOBAL CAPABILITY CENTERS IN INDIASrivaanchi Nathan
Ã˝
This business intelligence report, "The Big Ten Biopharmaceutical MNCs: Global Capability Centers in India", provides an in-depth analysis of the operations and contributions of the Global Capability Centers (GCCs) of ten leading biopharmaceutical multinational corporations in India. The report covers AstraZeneca, Bayer, Bristol Myers Squibb, GlaxoSmithKline (GSK), Novartis, Sanofi, Roche, Pfizer, Novo Nordisk, and Eli Lilly. In this report each company's GCC is profiled with details on location, workforce size, investment, and the strategic roles these centers play in global business operations, research and development, and information technology and digital innovation.A Framework for Model-Driven Digital Twin Engineering
A Framework for Model-Driven Digital Twin EngineeringDaniel Lehner
Ã˝
∫›∫›fl£s from my PhD Defense at Johannes Kepler University, held on Janurary 10, 2025.
The full thesis is available here: https://epub.jku.at/urn/urn:nbn:at:at-ubl:1-83896Computational Photography: How Technology is Changing Way We Capture the World
Computational Photography: How Technology is Changing Way We Capture the WorldHusseinMalikMammadli
Ã˝
Web scraping in python
- 1. Web Scraping with Python Virendra Rajput, Hacker @Markitty
- 2. Agenda ‚óè What is scraping ‚óè Why we scrape ‚óè My experiments with web scraping ‚óè How do we do it ‚óè Tools to use ‚óè Online demo ‚óè Some more tools ‚óè Ethics for scraping
- 3. converting unstructured documents into structured information scraping:
- 4. What is Web Scraping? ‚óè Web scraping (web harvesting) is a software technique of extracting information from websites ‚óè It focuses on transformation of unstructured data on the web (typically HTML), into structured data that can be stored and analyzed
- 5. RSS is meta data and not HTML replacement
- 6. Why we scrape? ● Web pages contain wealth of information (in text form), designed mostly for human consumption ● Static websites (legacy systems) ● Interfacing with 3rd party with no API access ● Websites are more important than API’s ● The data is already available (in the form of web pages) ● No rate limiting ● Anonymous access
- 7. How search engines use it
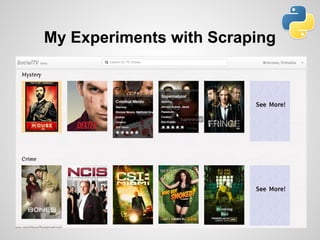
- 8. My Experiments with Scraping
- 9. and more..! IMDb API Did you mean! Facebook Bot for Brahma Kumaris
- 10. Getting started!
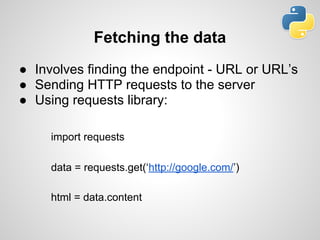
- 11. Fetching the data ● Involves finding the endpoint - URL or URL’s ● Sending HTTP requests to the server ● Using requests library: import requests data = requests.get(‘http://google.com/’) html = data.content
- 12. Processing (say no to Reg-ex) ‚óè use reg-ex ‚óè Avoid using reg-ex ‚óè Reasons why not to use it: 1. Its fragile 2. Really hard to maintain 3. Improper HTML & Encoding handling
- 13. Use BeautifulSoup for parsing ● Provides simple methods to- ○ search ○ navigate ○ select ● Deals with broken web-pages really well ● Auto-detects encoding Philosophy- “You didn't write that awful page. You're just trying to get some data out of it. Beautiful Soup is here to help.”
- 14. Export the data ‚óè Database (relational or non-relational) ‚óè CSV ‚óè JSON ‚óè File (XML, YAML, etc.) ‚óè API
- 16. Challenges ‚óè External sites can change without warning ‚óã Figuring out the frequency is difficult (TEST, and test) ‚óã Changes can break scrapers easily ‚óè Bad HTTP status codes ‚óã example: using 200 OK to signal an error ‚óã cannot always trust your HTTP libraries default behaviour ‚óè Messy HTML markup
- 17. Mechanize ● Stateful web-browsing with mechanize ○ Fill up forms ○ Follow links ○ Handle cookies ○ Browse history ● After Andy Lester’s WWW: Mechanize
- 18. Filling forms with Mechanize
- 19. Scrapy - a framework for web scraping ‚óè Uses XPath to select elements ‚óè Interactive shell scripting ‚óè Using Scrapy: ‚óã define a model to store items ‚óã create your spider to extract items ‚óã write a Pipeline to store them
- 20. Conclusion ‚óè Scrape wisely ‚óè Do not steal ‚óè Use cloud ‚óè Share your scrapers scraperwiki.com