Web Speech API で2時間で作れる?ブラウザロボット
?
5 likes?4,934 views

第62回 HTML5とか勉強会スペシャル ー ブラウザ、次世代Web標準の最新動向とか































![Speech Recognition API
SpeechRecognitionError?音声認識のエラー
error attribute?(エラー属性)
message attribute?(メッセージ属性:デバッグ用のエラーメッセージ)
SpeechRecognitionAlternative?
transcript ?
con?dence
音声が検出されない
なんらかの動作による音声入力の中断
オーディオキャプチャの失敗
ネットワーク通信の失敗
ユーザーエージェントによる不許可
音声サービスの不許可
文法の誤り
言語がサポートされていない
no-speech
aborted ?
audio-capture
network
not-allowed
service-not-allowed
bad-grammar
language-not-supported
認識した言葉の書き出し
認識度合い(信頼度)。0~1で表す [議論中]
音声認識エラーのイベントで利用するインターフェース
音声認識の表す方法](https://image.slidesharecdn.com/201602205jbrowserrobot-160226183704/85/Web-Speech-API-2-37-320.jpg)


![Speech Recognition API?実装例
<script type="text/javascript">
var recognition = new webkitSpeechRecognition();
recognition.onresult = function(event) {
if (event.results.length > 0) {
q.value = event.results[0][0].transcript;
q.form.submit();
}
}
</script>
<form action="http://www.example.com/search">
<input type="search" id="q" name="q" size=60>
<input type="button" value="Click to Speak" onclick="recognition.start()">
</form>
【注意】Speech Recognition APIはWebサーバに載せないと動作しない](https://image.slidesharecdn.com/201602205jbrowserrobot-160226183704/85/Web-Speech-API-2-40-320.jpg)
















Web Speech API で2時間で作れる?ブラウザロボット
- 1. Web Speech APIを使って 2時間でつくれるブラウザロボット? 2016/ 02 /20 @eegozilla
- 2. 自己紹介 eegozilla html5j ロボット部 部長 html5j 運営スタッフ html5j Webプラットフォーム部?運営スタッフ html5j エンタープライズ部 LeapMotion Developers JP?共同主催 日本Androidの会 運営委員 Facebook Hirokazu Egashira Twitter? @ega1979 (eegozilla)
- 4. 2015/02/24 第1回勉強会 2015/03/03 第1回勉強会(再演版) 2015/03/14 第1回Pepperハッカソン 2015/04/21 AITCオープンラボ 第4回 IoT勉強会(第2回勉強会) 2015/05/21 AITCオープンラボ 第4回 IoT勉強会(再演版)(第2回勉強会) 2015/06/22 第3回勉強会(ROBOT × ビジネス?DMM .make ROBOTS)? 2015/07/20 Android Bazaar Conference 2015 Summerで登壇しました 2015/08/01 - 02 Makers Faire Tokyo 2015 出展 2015/08/22 AITC IoTx総まとめ & IoT! 夏のデバイスだらけのLT大会! 2015/09/07 第4回勉強会(ROS) 2015/09/17 DMM.make ROBOTS Palmi開発環境発表会展示 2015/09/30 JAWS IoT勉強会 2015/10/07 第5回勉強会(Pepper × スマートフォン) 2015/10/13 第6回勉強会(Pepper × COCOROBO) 2015/11/03 Happy Birthday HTML5 2015/12/06 Google HackFair @Tokyo 展示 html5j ロボット部 活動実績
- 9. Google HackFair @Tokyo 2015/12/6(sun) 13:00 - 18:00 photo by Robot Start .Inc
- 10. Google HackFair @Tokyo 2015/12/6(sun) 13:00 - 18:00 photo by Robot Start .Inc
- 11. 登場人物 Rasberry Pi 2 B type タミヤ音センサー 歩行ロボット製作セット(音センサーは使わない) NEXUS 5x ダイソーで買ったゴミ箱 (150円もした。。。)
- 12. 登場人物 Rasberry Pi 2 B type タミヤ音センサー 歩行ロボット製作セット(音センサーは使わない) NEXUS 5x ダイソーで買ったゴミ箱 (150円もした。。。)
- 13. 登場人物 Rasberry Pi 2 B type タミヤ音センサー 歩行ロボット製作セット(音センサーは使わない) NEXUS 5x ダイソーで買ったゴミ箱 (150円もした。。。) すみません 本日忘れてしまいました。。。
- 14. 登場人物 Rasberry Pi 2 B type タミヤ音センサー 歩行ロボット製作セット(音センサーは使わない) Macbook Pro ダイソーで買ったゴミ箱 (150円もした。。。)
- 17. 制作スケジュール 展示準備 展示開始13:00 ~ 12/5 21:00 別のブースの展示物をピックアップ 自宅到着22:00 自宅出発12/6 9:00 ~ 11:00 ~ 食事?お風呂22:00 ~ 23:30
- 18. 作業できるのはココのみ! (しかも眠い、、、) 制作スケジュール 展示準備 展示開始13:00 ~ 12/5 21:00 別のブースの展示物をピックアップ 自宅到着22:00 自宅出発12/6 9:00 ~ 11:00 ~ 食事?お風呂22:00 ~ 23:30
- 19. 制作スケジュール 展示開始13:00 ~ 12/5 21:00 別のブースの展示物をピックアップ 自宅到着22:00 自宅出発12/6 9:00 ~ 11:00 ~ 食事?お風呂22:00 ~ 23:30 作業できるのはココのみ! (しかも眠い、、、) 実装2時間で終了! (筐体は丸1日)
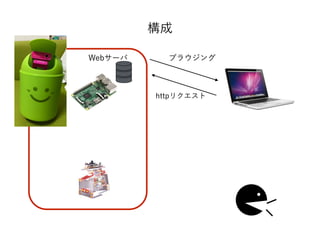
- 20. Web Speech API
- 22. Webページに、音声認識や音声合成を組み込むためJavaScriptのAPI。 W3CのSpeech APIコミュニティグループによって策定。 2012/10/19の段階でCommunity Group Final Reortが出ている。 (Googleのメンバー中心に編集されている) W3C標準でもなければW3Cの標準トラックに則ったものでもない。 It is not a W3C Standard nor is it on the W3C Standards Track. Web Speech API
- 23. Use Cases ? Voice Web Search? ? Speech Command Interface? ? Domain Specific Grammars Contingent on Earlier Inputs ? Continuous Recognition of Open Dialog? ? Domain Specific Grammars Filling Multiple Input Fields ? Speech UI present when no visible UI need be present? ? Voice Activity Detection? ? Temporal Structure of Synthesis to Provide Visual Feedback? ? Hello World ? Speech Translation? ? Speech Enabled Email Client? ? Dialog Systems? ? Multimodal Interaction? ? Speech Driving Directions? ? Multimodal Video Game ? Multimodal Search?
- 24. ? Voice Web Search? ? Speech Command Interface? ? Domain Specific Grammars Contingent on Earlier Inputs ? Continuous Recognition of Open Dialog? ? Domain Specific Grammars Filling Multiple Input Fields ? Speech UI present when no visible UI need be present? ? Voice Activity Detection? ? Temporal Structure of Synthesis to Provide Visual Feedback? ? Hello World ? Speech Translation? ? Speech Enabled Email Client? ? Dialog Systems? ? Multimodal Interaction? ? Speech Driving Directions? ? Multimodal Video Game ? Multimodal Search? ? ? Use Cases
- 25. ? Voice Web Search? ? Speech Command Interface? ? Domain Specific Grammars Contingent on Earlier Inputs ? Continuous Recognition of Open Dialog? ? Domain Specific Grammars Filling Multiple Input Fields ? Speech UI present when no visible UI need be present? ? Voice Activity Detection? ? Temporal Structure of Synthesis to Provide Visual Feedback? ? Hello World ? Speech Translation? ? Speech Enabled Email Client? ? Dialog Systems? ? Multimodal Interaction? ? Speech Driving Directions? ? Multimodal Video Game ? Multimodal Search? つまり コミュニケーションロボットを つくるためのAPIでしょ!? Use Cases
- 26. 1. User agents must only start speech input sessions with explicit, informed user consent. User consent can include, for example: - User click on a visible speech input element which has an obvious graphical representation showing that it ? will start speech input. - Accepting a permission prompt shown as the result of a call to SpeechRecognition.start. - Consent previously granted to always allow speech input for this web page. 2.User agents must give the user an obvious indication when audio is being recorded. - In a graphical user agent, this could be a mandatory notification displayed by the user agent as part of its ? chrome and not accessible by the web page. This could for example be a pulsating/blinking record icon as ? part of the browser chrome/address bar, an indication in the status bar, an audible notification, or anything ? else relevant and accessible to the user. This UI element must also allow the user to stop recording. - In a speech-only user agent, the indication may for example take the form of the system speaking the label ? of the speech input element, followed by a short beep. 3. The user agent may also give the user a longer explanation the first time speech input is used, to let the user now what it is and how they can tune their privacy settings to disable speech recording if required. 4. To minimize the chance of users unwittingly allowing web pages to record speech without their knowledge, implementations must abort an active speech input session if the web page lost input focus to another window or to another tab within the same user agent. Security and privacy considerations
- 27. Web Speech API Speech Synthesis API 音声合成API Speech Recognition API 音声認識API A web API for controlling a text-to-speech output. Method to provide speech input in a web browser.
- 28. SpeechSynthesis Attributes?音声合成の属性 Speech Synthesis API pending speaking paused SpeechSynthesis Methods?音声合成のメソッド speak cancel pause resume getVoices SpeechSynthesisUtterance Attributes?音声合成発話の属性 text lang voiceURI volume rate pitch
- 29. SpeechSynthesisUtterance Events?音声合成発話のイベント start end error pause resume mark boundary SpeechSynthesisEvent Attributes?音声合成イベントとの属性 charIndex elapsedTime name Speech Synthesis API 話始めたときに発火 話し終えたときに発火(このときはerrorイベントは発火しない) エラーが起きたとき発火(このときはendイベントは発火しない) 発話が途中で止まったとき(停止したとき)に発火 pause後、再開したときに発火 SSMLのタグに来たとき発火 発話が文の境目にきたとき発火
- 30. SpeechSynthesisVoice?音声について voiceURI name lang localService default SpeechSynthesisVoiceList?音声のリスト length attribute item getter Speech Synthesis API 音声合成の声のURI (ローカルファイルやリモートファイルを使う場合) 合成音声の名前 言語設定 ローカルにある音声合成を使うときはtrue、リモートにある音声合成を使うときはfalse デフォルト音声が使われているときはtrue。各UAがデフォルトのときの音声が何か調べると きに使う
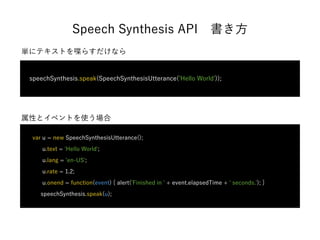
- 31. 単にテキストを喋らすだけなら Speech Synthesis API?書き方 speechSynthesis.speak(SpeechSynthesisUtterance('Hello World')); var u = new SpeechSynthesisUtterance(); u.text = 'Hello World'; u.lang = 'en-US'; u.rate = 1.2; u.onend = function(event) { alert('Finished in ' + event.elapsedTime + ' seconds.'); } speechSynthesis.speak(u); 属性とイベントを使う場合
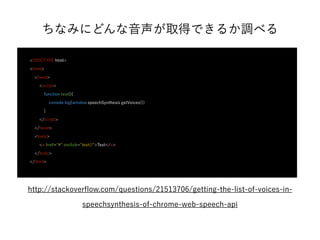
- 32. ちなみにどんな音声が取得できるか調べる <!DOCTYPE html> <html> <head> <script> function test(){ console.log(window.speechSynthesis.getVoices()) } </script> </head> <body> <a href="#" onclick="test()">Test</a> </body> </html> http://stackoverflow.com/questions/21513706/getting-the-list-of-voices-in-speechsynthesis-of- chrome-web-speech-api
- 35. Speech Recognition API SpeechRecognition Attributes 音声認識属性 grammars lang continuous interimResults maxAlternatives serviceURI SpeechRecognition Methods?音声認識メソッド start stop abort ※グループは現在WebRTCがオーディオのソースの選択とリモートの認識機能を? 特定するために使用される可能性があるかどうか議論していると。 文法属性 言語属性 連続属性?falseは1つの認識で1つだけ結果を返す, trueは連続して返す。 デフォルトはfalse 中間結果の設定?trueで中間結果を返し、falseで返さない。デフォルトはfalse SpeechRecognitionAlternativesの最大数の設定。デフォルト値は1 使用したい音声認識サービスのURIを指定 音声認識開始のメソッド 音声認識停止のメソッド 音声認識中断のメソッド
- 36. Speech Recognition API SpeechRecognition Events?音声認識のイベント speechstart speechend audiostart? audioend soundstart soundend result nomatch error start end 音声認識で使われる音声が始まった時に発火 音声認識で使われる音声が終了したときに(必ずspeechstart、speechend順で発火) オーディオをキャプチャーし始めたときに発火 オーディオをキャプチャーし終えたときに発火(必ずaudiostart、audioend順で発火) 何かの音(できる限り音声)を検知したときに発火 何の音も検知されなくなったら発火(必ずsoundstart、soundend順で発火) 音声認識が結果を返したときに発火。音声認識イベントのインターフェースに使われる。 音声認識したという閾値に達することがなかったという最終結果を返したときに発火。音声認識 イベントのインターフェースに使われる。result属性は音声認識の閾値に至らないもしくはnull。 音声認識がエラーを起こしたときに発火。音声認識エラーのインターフェースで使われる。 音声認識サービスが音を認識しはじめたときに発火。 音声認識サービスが切断時に発火。どんな理由でセッションが終了しても必ず生成。
- 37. Speech Recognition API SpeechRecognitionError?音声認識のエラー error attribute?(エラー属性) message attribute?(メッセージ属性:デバッグ用のエラーメッセージ) SpeechRecognitionAlternative? transcript ? con?dence 音声が検出されない なんらかの動作による音声入力の中断 オーディオキャプチャの失敗 ネットワーク通信の失敗 ユーザーエージェントによる不許可 音声サービスの不許可 文法の誤り 言語がサポートされていない no-speech aborted ? audio-capture network not-allowed service-not-allowed bad-grammar language-not-supported 認識した言葉の書き出し 認識度合い(信頼度)。0~1で表す [議論中] 音声認識エラーのイベントで利用するインターフェース 音声認識の表す方法
- 38. SpeechRecognitionResult?音声認識の結果 length attribute item getter ?nal attribute SpeechRecognitionList?音声認識のリスト length attribute item getter SpeechRecognitionEvent? resultIndex? results interpretation emma Speech Recognition API 音声認識結果に関する(中間結果の認識最終結果かどちらか)オブジェクト n-bestの認識の代替結果がアイテムの配列に入った長さ n-bestの値の配列にあるインデックスから音声認識の代替結果を返したもの インデックスの値がlengthの長さより大きいならnull 音声認識でインデックスされた値が最終結果か(true)、falseなら中間結果を表す 音声認識し続けた結果を一連の結果として保持するオブジェクト(連続して認識しないなら保持する値は1つだけ) 認識結果が変更した時に起きるイベント
- 39. Speech Recognition API SpeechGrammar src attribute weight attribute SpeechGrammarList length attribute item getter addFromURI method addFromString method SpeechGrammarオブジェクトの集合としてのオブジェクト 文法上のコンテナとしてのオブジェクト URIを求めるときのもの 音声認識でウェイトを利用する場合(デフォルト値は1)
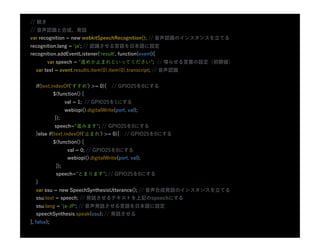
- 40. Speech Recognition API?実装例 <script type="text/javascript"> var recognition = new webkitSpeechRecognition(); recognition.onresult = function(event) { if (event.results.length > 0) { q.value = event.results[0][0].transcript; q.form.submit(); } } </script> <form action="http://www.example.com/search"> <input type="search" id="q" name="q" size=60> <input type="button" value="Click to Speak" onclick="recognition.start()"> </form> 【注意】Speech Recognition APIはWebサーバに載せないと動作しない
- 43. Web Speech API?Reference https://dvcs.w3.org/hg/speech-api/raw-file/tip/speechapi.html https://www.google.com/intl/ja/chrome/demos/speech.html https://developer.mozilla.org/ja/docs/Web/API/Web_Speech_API - Web Speech API Demonstration - W3C Community Group Final Reort “Web Speech API Specification” - MDN Web Speech API
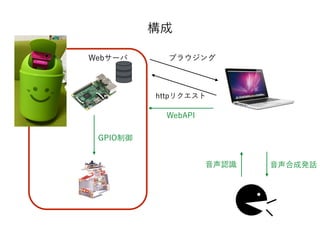
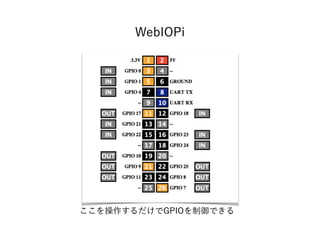
- 47. ? Webサーバ機能が標準で搭載されている ? プログラムを書かなくともデフォルトのURLにアクセスするだけで GPIOを制御できる ? REST APIに対応している ? 機能な豊富なJavaScriptライブラリ(webiopi.js)が用意されている WebIOPi
- 50. WebIOPi GPIO REST API http://webiopi.trouch.com/RESTAPI.html
- 51. WebIOPiの入れ方 $tar xvzf WebIOPi-0.7.1.tar.gz $sudo ./setup.sh $sudo /etc/init.d/webiopi start ② 解凍する $cd /home/pi/WebIOPi-0.7.1 ③ ディレクトリを移動 ④ インストール ⑤ 起動 ① サイトよりダウンロードしてscpとかでアップロード http://webiopi.trouch.com/DOWNLOADS.html
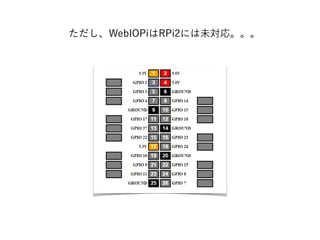
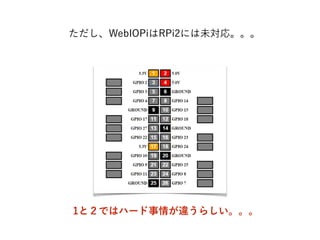
- 54. WebIOPiをRasberry Pi 2に対応させる if (strcmp(hardware, BCM2708 ) == 0) if (strcmp(hardware, BCM2709 ) == 0) python/native/cpuinfo.c ( L.40 ) #de?ne BCM2708_PERI_BASE 0x20000000 #de?ne BCM2709_PERI_BASE 0x3f000000 python/native/gpio.c ( L.32 ) $sudo ./setup.sh ③インストール ②ペリフェラルのベースアドレスを変更 ①SoCがBCM2708からBCM2709に変更したので修正
- 55. あとはWebIOPiのGPIOを制御するだけ <script type="text/javascript" src=/slideshow/web-speech-api-2-58770345/58770345/"jquery.js"></script> <script type="text/javascript" src="webiopi.js"></script> <script> // 初期設定 // Raspberry Piのターゲットのピンとその初期値の設定 var port = 25; // GPIO25 var val = 0; // 初期値 $(function() { // GPIO25をOUTモードにして初期設定内容を適用する webiopi().setFunction(port, "out", function(){ webiopi().digitalWrite(port, val); }); }); // 続く
- 56. // 続き // 音声認識と合成、発話 var recognition = new webkitSpeechRecognition(); // 音声認識のインスタンスを立てる recognition.lang = ja ; // 認識させる言語を日本語に設定 recognition.addEventListener('result', function(event){ var speech = 進めか止まれといってください"; // 喋らせる言葉の設定(初期値) var text = event.results.item(0).item(0).transcript; // 音声認識 if(text.indexOf( すすめ') >= 0){?// GPIO25を0にする $(function() { val = 1; // GPIO25を1にする webiopi().digitalWrite(port, val); }); speech= 進みます ; // GPIO25を0にする }else if(text.indexOf( 止まれ') >= 0){?// GPIO25を0にする $(function() { val = 0; // GPIO25を0にする webiopi().digitalWrite(port, val); }); speech= とまります ; // GPIO25を0にする } var ssu = new SpeechSynthesisUtterance(); // 音声合成発話のインスタンスを立てる ssu.text = speech; // 発話させるテキストを上記のspeechにする ssu.lang = ja-JP'; // 音声発話させる言語を日本語に設定 speechSynthesis.speak(ssu); // 発話させる }, false);
- 58. たった2時間で ドヤ顔!
- 60. ありがとうございました