[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data
3 likes503 views
The document appears to be incomplete or consists primarily of repetitive characters and symbols. It does not provide coherent information or context. As a result, a meaningful summary cannot be derived.
1 of 28
Downloaded 58 times
![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://image.slidesharecdn.com/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754/85/Webinar-GraphDB-Fundamentals-Adding-Meaning-to-Your-Data-1-320.jpg)



![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://image.slidesharecdn.com/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754/85/Webinar-GraphDB-Fundamentals-Adding-Meaning-to-Your-Data-5-320.jpg)

![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://image.slidesharecdn.com/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754/85/Webinar-GraphDB-Fundamentals-Adding-Meaning-to-Your-Data-7-320.jpg)


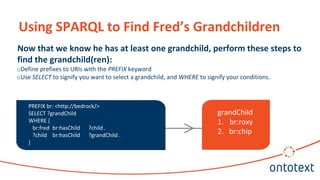




![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://image.slidesharecdn.com/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754/85/Webinar-GraphDB-Fundamentals-Adding-Meaning-to-Your-Data-19-320.jpg)




![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://image.slidesharecdn.com/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754/85/Webinar-GraphDB-Fundamentals-Adding-Meaning-to-Your-Data-24-320.jpg)


![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://image.slidesharecdn.com/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754/85/Webinar-GraphDB-Fundamentals-Adding-Meaning-to-Your-Data-27-320.jpg)
![[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data](https://image.slidesharecdn.com/webinar-graphdbfundamentalsaddingmeaningtoyourdata-180420104754/85/Webinar-GraphDB-Fundamentals-Adding-Meaning-to-Your-Data-28-320.jpg)
Ad
Recommended
Illegal Marriage Presentation
Illegal Marriage Presentationselia0202
Ěý
This short document discusses a topic that will be both easy and complicated. In one sentence, it introduces that the talk will focus on a problem that has both simple and complex aspects.Rekha khurana
Rekha khuranaLuvditya Khurana
Ěý
The document lists different animals and objects starting with each letter of the alphabet. It describes ants bouncing on apples, cats bouncing in cars, dogs dancing, eggs on elephants, five fat fish, grass being green, hands on heads, someone itching, jumping in jelly, kitties kissing, lions liking lemons, monkeys in McDonald's, the number nine, an old orange octopus, a pink pig's pool, queens being quiet, rabbits running, snakes in the sun, tigers on tiptoes, umbrellas up, Vincent's violin, washing the window, a fox in a box, yolks being yummy, and a zebra in the zoo.Romania - Delta Dunarii & Marea Neagra
Romania - Delta Dunarii & Marea NeagraElena M.
Ěý
This document repeats the phrase "Here we go" multiple times without providing any other context or information. It ends by mentioning "Fotografii/ Photos by: Sorin Toma" but does not include any photos or further details.Creating a Customized Email Experience with Marketing Automation
Creating a Customized Email Experience with Marketing AutomationInformz
Ěý
The document primarily contains the text '#informz' repeated multiple times, indicating a focus or emphasis on a specific topic or theme without providing additional context or information.FOUNDATIONS OF PHILIPPINE POLITICS AND GOVERNMENT: POLITICAL HISTORY
FOUNDATIONS OF PHILIPPINE POLITICS AND GOVERNMENT: POLITICAL HISTORYjundumaug1
Ěý
The document is comprised of the repeated text "JUN DUMAUG" on multiple lines without any other context or information provided. It is difficult to summarize as there is no clear topic, details, or meaning across the short repetitive text.Graph RAG Varieties and Their Enterprise Applications
Graph RAG Varieties and Their Enterprise ApplicationsOntotext
Ěý
The document presents an overview of knowledge graphs and their integration with generative AI technologies, highlighting their role in transforming complex business data into competitive advantages. It discusses the capabilities of various graph data management systems, their use cases in entity linking, and the benefits of fine-tuning large language models with knowledge graphs. Additionally, it addresses challenges faced in applying retrieval-augmented generation (RAG) and proposes solutions for enhancing data discoverability and effectiveness in managing and utilizing organizational data.EligibilityDesignAssistant_demo_slideshare.pptx.pdf
EligibilityDesignAssistant_demo_slideshare.pptx.pdfOntotext
Ěý
Ontotext's eligibility design assistant integrates knowledge graphs with large language models to streamline the selection of clinical trial eligibility criteria. Researchers can filter, explore, refine, and receive recommendations on criteria based on their study's phase, condition, and interventions, including the ability to input free-text measures. The tool enhances the identification of relevant inclusion and exclusion criteria, facilitating more effective patient population selection in clinical trials.Property graph vs. RDF Triplestore comparison in 2020
Property graph vs. RDF Triplestore comparison in 2020Ontotext
Ěý
The document compares RDF and property graph models in terms of their expressivity, semantics, query languages, and use cases, emphasizing that no single database management system can meet all needs. It outlines strengths and weaknesses of both models, highlighting RDF's interoperability and formal semantics versus property graph's graph traversal capabilities. The document also discusses the current market landscape for graph databases, mentioning leading vendors like Neo4j and Ontotext.Reasoning with Big Knowledge Graphs: Choices, Pitfalls and Proven Recipes
Reasoning with Big Knowledge Graphs: Choices, Pitfalls and Proven RecipesOntotext
Ěý
The document summarizes a webinar on reasoning with knowledge graphs, highlighting benefits, pitfalls, and implementation choices. It discusses Ontotext's GraphDB, a leading semantic technology vendor, and its capabilities in managing and reasoning over complex data sets. Various use cases, benchmarks, and technical insights are also shared, emphasizing the importance of semantic technologies in deriving meaningful insights from interconnected data.Building Knowledge Graphs in 10 steps
Building Knowledge Graphs in 10 stepsOntotext
Ěý
The document outlines a 10-step process for building knowledge graphs, starting from defining the goal and gathering relevant data to crafting a semantic data model and integrating it. It emphasizes data quality, harmonization, and the use of ETL tools, as well as the importance of creating usable and maintainable knowledge graphs. The final steps involve leveraging analytics and ensuring the data is fair, ultimately leading to the effective use and evolution of the knowledge graph.Analytics on Big Knowledge Graphs Deliver Entity Awareness and Help Data Linking
Analytics on Big Knowledge Graphs Deliver Entity Awareness and Help Data LinkingOntotext
Ěý
Ontotext, a semantic web pioneer, leverages big knowledge graphs and cognitive analytics to enhance entity awareness and data integration for businesses. The company emphasizes the need for global data to inform better business decisions and assists organizations with entity matching and information extraction. With a robust technology mix, Ontotext aims to facilitate advanced analytics and support enterprises in navigating complex data landscapes.It Don’t Mean a Thing If It Ain’t Got Semantics
It Don’t Mean a Thing If It Ain’t Got SemanticsOntotext
Ěý
The document discusses the challenges of managing large volumes of diverse data and emphasizes the need for systems like RDF graph databases to convert data into understanding and actionable insights. RDF graph databases are highlighted for their ability to manage both structured and unstructured data, aiding in intelligent data management and integration across information systems. It concludes by encouraging users to consider an RDF database to enhance their data's meaning and utility.The Bounties of Semantic Data Integration for the Enterprise
The Bounties of Semantic Data Integration for the Enterprise Ontotext
Ěý
Semantic data integration allows enterprises to connect heterogeneous data sources through a common language. This creates a unified 360-degree view of enterprise data and facilitates knowledge management and use. Semantic integration aims to enrich existing data with external knowledge and provide a single access point for enterprise assets. It addresses challenges of accessing and storing data from various internal resources by building a well-structured integrated whole to enhance business processes.[Conference] Cognitive Graph Analytics on Company Data and News
[Conference] Cognitive Graph Analytics on Company Data and NewsOntotext
Ěý
Ontotext introduced their cognitive analytics platform that performs cognitive graph analytics on company data and news. The platform builds large knowledge graphs by integrating data from multiple sources and uses text mining to link news articles to entities in the knowledge graph. It provides functionality for node ranking, similarity analysis and data cleaning to consolidate and reconcile company records across datasets. The platform was demonstrated through a knowledge graph containing over 2 billion facts built by integrating datasets like DBpedia, Geonames, and news article metadata.Transforming Your Data with GraphDB: GraphDB Fundamentals, Jan 2018
Transforming Your Data with GraphDB: GraphDB Fundamentals, Jan 2018Ontotext
Ěý
The document outlines a live webinar on GraphDB fundamentals held in January 2018, covering topics such as RDF, RDFS, SPARQL, and ontology. It discusses RDF as a data model for representing information and metadata using triples, introduces SPARQL as a query language for querying RDF data, and explains the significance of ontologies for knowledge representation. Additionally, it provides a brief overview of GraphDB and its capabilities, as well as links to additional resources and support.Hercule: Journalist Platform to Find Breaking News and Fight Fake Ones
Hercule: Journalist Platform to Find Breaking News and Fight Fake OnesOntotext
Ěý
The Hercule AI platform utilizes artificial intelligence to analyze and understand events, people, organizations, and other entities within various big data sources, particularly social media and news outlets. It features tools for journalists to define topics, classify stories based on popularity, trustworthiness, and verifiability, and offers a dashboard for summarizing content. The platform targets fact-checking journalists and those engaged in combating fake news, providing them with the capability to swiftly monitor and summarize important narratives.How to migrate to GraphDB in 10 easy to follow steps
How to migrate to GraphDB in 10 easy to follow steps Ontotext
Ěý
The document outlines a 10-step process for migrating to GraphDB, emphasizing the importance of integrating enterprise data for informed decision-making. It provides a comprehensive service that includes data validation, query optimization, and performance monitoring to ensure a smooth transition to the new database technology. The migration aims to enhance data management capabilities while addressing the unique needs of organizations.GraphDB Cloud: Enterprise Ready RDF Database on Demand
GraphDB Cloud: Enterprise Ready RDF Database on DemandOntotext
Ěý
The document outlines the features and offerings of the Ontotext GraphDB Cloud, an enterprise-ready RDF database available as a service. It includes details on training sessions, architecture, pricing tiers, support, and use cases for various users, such as developers and information architects. Additionally, it provides information on the cloud's capabilities like automated backups, performance monitoring, and access to knowledge graphs.[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...
[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...Ontotext
Ěý
Factforge introduces a knowledge graph platform for analyzing and linking diverse datasets, particularly focusing on news and social media content related to companies. It offers tools for relationship discovery, semantic media monitoring, and data transformation to RDF, all aimed at non-technical users. Users can explore rankings and trends, leveraging a vast collection of open data including company registries and news metadata.Smarter content with a Dynamic Semantic Publishing Platform
Smarter content with a Dynamic Semantic Publishing PlatformOntotext
Ěý
Dynamic Semantic Publishing (DSP) automates the aggregation, publishing, and re-purposing of interrelated content using linked data technology, enhancing user experience and engagement. The document details the architecture of DSP, including its use of knowledge graphs and semantic analytics, and discusses its applications in various business domains. It also highlights the importance of contextual and behavioral recommendations to serve relevant content to users.How is smart data cooked?
How is smart data cooked?Ontotext
Ěý
GraphDB is a tool that simplifies the process of managing and utilizing data, likened to a pasta maker that prepares ingredients for cooking. It enables automated discovery of patterns, trend detection, and the creation of new facts from various data sources. With GraphDB, businesses can develop tailored, smart data-driven solutions for diverse applications such as data integration and knowledge base building.Efficient Practices for Large Scale Text Mining Process
Efficient Practices for Large Scale Text Mining ProcessOntotext
Ěý
The document discusses best practices for large-scale text mining processes, focusing on the importance of clearly defining business and text analysis problems. It outlines essential steps including data preparation, annotation types, and evaluation metrics while emphasizing the collaborative effort needed from domain experts and technical staff. The document concludes with key takeaways and common pitfalls to avoid in text mining implementations.The Power of Semantic Technologies to Explore Linked Open Data
The Power of Semantic Technologies to Explore Linked Open DataOntotext
Ěý
The document discusses the use of semantic technologies for exploring linked open data within various contexts, such as combining local and remote data, media monitoring, and detecting relationships in business data. It outlines various tools and use cases, particularly focusing on Real-Time FactForge and OntoRefine for converting tabular data into RDF and integrating it for enhanced insights. Additionally, it presents examples of relational discovery, specific queries for media monitoring, and the application of the Panama Papers data as an example of linked open data exploration.First Steps in Semantic Data Modelling and Search & Analytics in the Cloud
First Steps in Semantic Data Modelling and Search & Analytics in the CloudOntotext
Ěý
The document announces a training course on designing a semantic technology proof of concept with GraphDB, scheduled for December 13, 2016. The course consists of tailored video materials, live interactive sessions, and SPARQL exercises, covering topics such as modeling data with RDF, applying flexible schemas, querying with SPARQL, and data visualization. Additionally, it explores the benefits of RDF databases and includes real-world use cases from organizations leveraging semantic technologies.The Knowledge Discovery Quest
The Knowledge Discovery Quest Ontotext
Ěý
The document discusses the importance of semantic search in overcoming inefficiencies in content management and information retrieval, noting that traditional keyword-based approaches limit knowledge discovery. Semantic search enhances the ability to explore complex relationships between data entities and their meanings, providing a more intuitive and context-aware search experience. It leverages semantic web technologies to transform information retrieval from simple result lists to a network of relevant connections, maximizing the potential for turning data into insights.Best Practices for Large Scale Text Mining Processing
Best Practices for Large Scale Text Mining ProcessingOntotext
Ěý
The webinar covers best practices for large-scale text mining processes, focusing on defining problems, selecting techniques, and planning successful workflows. Key topics include applications of NLP, annotation guidelines, and the importance of domain expertise in enhancing results. Participants are guided on implementing a structured approach to achieve effective information extraction and continuous adaptation through iterative evaluation and curation.Build Narratives, Connect Artifacts: Linked Open Data for Cultural Heritage
Build Narratives, Connect Artifacts: Linked Open Data for Cultural HeritageOntotext
Ěý
The document discusses the importance of Linked Open Data (LOD) for cultural heritage institutions (GLAM) and their adaptation to digital changes. It highlights various GLAM content standards, metadata schemas, and ontologies that aid in the management and sharing of cultural artifacts. The presentation also emphasizes challenges and opportunities for GLAM organizations in the internet age, advocating for a shift towards data linking and semantic web principles.Semantic Data Normalization For Efficient Clinical Trial Research
Semantic Data Normalization For Efficient Clinical Trial ResearchOntotext
Ěý
This document discusses semantic data normalization of clinical trial data to make it more structured and amenable to analysis. It describes converting unstructured clinical data like conditions, interventions, adverse events and eligibility criteria into RDF triples. The goal is to extract key phrases and concepts, identify qualifiers and relationships to formally represent the data. Examples show how condition texts, drug annotations and criteria can be modeled. Current work has normalized over 215,000 clinical studies from ClinicalTrials.gov into over 80 million RDF triples. The normalized data is pre-loaded in GraphDB and Ontotext S4 Cloud and can be explored and analyzed more easily.Who will create the languages of the future?
Who will create the languages of the future?Jordi Cabot
Ěý
Will future languages be created by language engineers?
Can you "vibe" a DSL?
In this talk, we will explore the changing landscape of language engineering and discuss how Artificial Intelligence and low-code/no-code techniques can play a role in this future by helping in the definition, use, execution, and testing of new languages. Even empowering non-tech users to create their own language infrastructure. Maybe without them even realizing. Step by step guide to install Flutter and Dart
Step by step guide to install Flutter and DartS Pranav (Deepu)
Ěý
Flutter is basically Google’s portable user
interface (UI) toolkit, used to build and
develop eye-catching, natively-built
applications for mobile, desktop, and web,
from a single codebase. Flutter is free, open-
sourced, and compatible with existing code. It
is utilized by companies and developers
around the world, due to its user-friendly
interface and fairly simple, yet to-the-point
commands.More Related Content
More from Ontotext (20)
Reasoning with Big Knowledge Graphs: Choices, Pitfalls and Proven Recipes
Reasoning with Big Knowledge Graphs: Choices, Pitfalls and Proven RecipesOntotext
Ěý
The document summarizes a webinar on reasoning with knowledge graphs, highlighting benefits, pitfalls, and implementation choices. It discusses Ontotext's GraphDB, a leading semantic technology vendor, and its capabilities in managing and reasoning over complex data sets. Various use cases, benchmarks, and technical insights are also shared, emphasizing the importance of semantic technologies in deriving meaningful insights from interconnected data.Building Knowledge Graphs in 10 steps
Building Knowledge Graphs in 10 stepsOntotext
Ěý
The document outlines a 10-step process for building knowledge graphs, starting from defining the goal and gathering relevant data to crafting a semantic data model and integrating it. It emphasizes data quality, harmonization, and the use of ETL tools, as well as the importance of creating usable and maintainable knowledge graphs. The final steps involve leveraging analytics and ensuring the data is fair, ultimately leading to the effective use and evolution of the knowledge graph.Analytics on Big Knowledge Graphs Deliver Entity Awareness and Help Data Linking
Analytics on Big Knowledge Graphs Deliver Entity Awareness and Help Data LinkingOntotext
Ěý
Ontotext, a semantic web pioneer, leverages big knowledge graphs and cognitive analytics to enhance entity awareness and data integration for businesses. The company emphasizes the need for global data to inform better business decisions and assists organizations with entity matching and information extraction. With a robust technology mix, Ontotext aims to facilitate advanced analytics and support enterprises in navigating complex data landscapes.It Don’t Mean a Thing If It Ain’t Got Semantics
It Don’t Mean a Thing If It Ain’t Got SemanticsOntotext
Ěý
The document discusses the challenges of managing large volumes of diverse data and emphasizes the need for systems like RDF graph databases to convert data into understanding and actionable insights. RDF graph databases are highlighted for their ability to manage both structured and unstructured data, aiding in intelligent data management and integration across information systems. It concludes by encouraging users to consider an RDF database to enhance their data's meaning and utility.The Bounties of Semantic Data Integration for the Enterprise
The Bounties of Semantic Data Integration for the Enterprise Ontotext
Ěý
Semantic data integration allows enterprises to connect heterogeneous data sources through a common language. This creates a unified 360-degree view of enterprise data and facilitates knowledge management and use. Semantic integration aims to enrich existing data with external knowledge and provide a single access point for enterprise assets. It addresses challenges of accessing and storing data from various internal resources by building a well-structured integrated whole to enhance business processes.[Conference] Cognitive Graph Analytics on Company Data and News
[Conference] Cognitive Graph Analytics on Company Data and NewsOntotext
Ěý
Ontotext introduced their cognitive analytics platform that performs cognitive graph analytics on company data and news. The platform builds large knowledge graphs by integrating data from multiple sources and uses text mining to link news articles to entities in the knowledge graph. It provides functionality for node ranking, similarity analysis and data cleaning to consolidate and reconcile company records across datasets. The platform was demonstrated through a knowledge graph containing over 2 billion facts built by integrating datasets like DBpedia, Geonames, and news article metadata.Transforming Your Data with GraphDB: GraphDB Fundamentals, Jan 2018
Transforming Your Data with GraphDB: GraphDB Fundamentals, Jan 2018Ontotext
Ěý
The document outlines a live webinar on GraphDB fundamentals held in January 2018, covering topics such as RDF, RDFS, SPARQL, and ontology. It discusses RDF as a data model for representing information and metadata using triples, introduces SPARQL as a query language for querying RDF data, and explains the significance of ontologies for knowledge representation. Additionally, it provides a brief overview of GraphDB and its capabilities, as well as links to additional resources and support.Hercule: Journalist Platform to Find Breaking News and Fight Fake Ones
Hercule: Journalist Platform to Find Breaking News and Fight Fake OnesOntotext
Ěý
The Hercule AI platform utilizes artificial intelligence to analyze and understand events, people, organizations, and other entities within various big data sources, particularly social media and news outlets. It features tools for journalists to define topics, classify stories based on popularity, trustworthiness, and verifiability, and offers a dashboard for summarizing content. The platform targets fact-checking journalists and those engaged in combating fake news, providing them with the capability to swiftly monitor and summarize important narratives.How to migrate to GraphDB in 10 easy to follow steps
How to migrate to GraphDB in 10 easy to follow steps Ontotext
Ěý
The document outlines a 10-step process for migrating to GraphDB, emphasizing the importance of integrating enterprise data for informed decision-making. It provides a comprehensive service that includes data validation, query optimization, and performance monitoring to ensure a smooth transition to the new database technology. The migration aims to enhance data management capabilities while addressing the unique needs of organizations.GraphDB Cloud: Enterprise Ready RDF Database on Demand
GraphDB Cloud: Enterprise Ready RDF Database on DemandOntotext
Ěý
The document outlines the features and offerings of the Ontotext GraphDB Cloud, an enterprise-ready RDF database available as a service. It includes details on training sessions, architecture, pricing tiers, support, and use cases for various users, such as developers and information architects. Additionally, it provides information on the cloud's capabilities like automated backups, performance monitoring, and access to knowledge graphs.[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...
[Webinar] FactForge Debuts: Trump World Data and Instant Ranking of Industry ...Ontotext
Ěý
Factforge introduces a knowledge graph platform for analyzing and linking diverse datasets, particularly focusing on news and social media content related to companies. It offers tools for relationship discovery, semantic media monitoring, and data transformation to RDF, all aimed at non-technical users. Users can explore rankings and trends, leveraging a vast collection of open data including company registries and news metadata.Smarter content with a Dynamic Semantic Publishing Platform
Smarter content with a Dynamic Semantic Publishing PlatformOntotext
Ěý
Dynamic Semantic Publishing (DSP) automates the aggregation, publishing, and re-purposing of interrelated content using linked data technology, enhancing user experience and engagement. The document details the architecture of DSP, including its use of knowledge graphs and semantic analytics, and discusses its applications in various business domains. It also highlights the importance of contextual and behavioral recommendations to serve relevant content to users.How is smart data cooked?
How is smart data cooked?Ontotext
Ěý
GraphDB is a tool that simplifies the process of managing and utilizing data, likened to a pasta maker that prepares ingredients for cooking. It enables automated discovery of patterns, trend detection, and the creation of new facts from various data sources. With GraphDB, businesses can develop tailored, smart data-driven solutions for diverse applications such as data integration and knowledge base building.Efficient Practices for Large Scale Text Mining Process
Efficient Practices for Large Scale Text Mining ProcessOntotext
Ěý
The document discusses best practices for large-scale text mining processes, focusing on the importance of clearly defining business and text analysis problems. It outlines essential steps including data preparation, annotation types, and evaluation metrics while emphasizing the collaborative effort needed from domain experts and technical staff. The document concludes with key takeaways and common pitfalls to avoid in text mining implementations.The Power of Semantic Technologies to Explore Linked Open Data
The Power of Semantic Technologies to Explore Linked Open DataOntotext
Ěý
The document discusses the use of semantic technologies for exploring linked open data within various contexts, such as combining local and remote data, media monitoring, and detecting relationships in business data. It outlines various tools and use cases, particularly focusing on Real-Time FactForge and OntoRefine for converting tabular data into RDF and integrating it for enhanced insights. Additionally, it presents examples of relational discovery, specific queries for media monitoring, and the application of the Panama Papers data as an example of linked open data exploration.First Steps in Semantic Data Modelling and Search & Analytics in the Cloud
First Steps in Semantic Data Modelling and Search & Analytics in the CloudOntotext
Ěý
The document announces a training course on designing a semantic technology proof of concept with GraphDB, scheduled for December 13, 2016. The course consists of tailored video materials, live interactive sessions, and SPARQL exercises, covering topics such as modeling data with RDF, applying flexible schemas, querying with SPARQL, and data visualization. Additionally, it explores the benefits of RDF databases and includes real-world use cases from organizations leveraging semantic technologies.The Knowledge Discovery Quest
The Knowledge Discovery Quest Ontotext
Ěý
The document discusses the importance of semantic search in overcoming inefficiencies in content management and information retrieval, noting that traditional keyword-based approaches limit knowledge discovery. Semantic search enhances the ability to explore complex relationships between data entities and their meanings, providing a more intuitive and context-aware search experience. It leverages semantic web technologies to transform information retrieval from simple result lists to a network of relevant connections, maximizing the potential for turning data into insights.Best Practices for Large Scale Text Mining Processing
Best Practices for Large Scale Text Mining ProcessingOntotext
Ěý
The webinar covers best practices for large-scale text mining processes, focusing on defining problems, selecting techniques, and planning successful workflows. Key topics include applications of NLP, annotation guidelines, and the importance of domain expertise in enhancing results. Participants are guided on implementing a structured approach to achieve effective information extraction and continuous adaptation through iterative evaluation and curation.Build Narratives, Connect Artifacts: Linked Open Data for Cultural Heritage
Build Narratives, Connect Artifacts: Linked Open Data for Cultural HeritageOntotext
Ěý
The document discusses the importance of Linked Open Data (LOD) for cultural heritage institutions (GLAM) and their adaptation to digital changes. It highlights various GLAM content standards, metadata schemas, and ontologies that aid in the management and sharing of cultural artifacts. The presentation also emphasizes challenges and opportunities for GLAM organizations in the internet age, advocating for a shift towards data linking and semantic web principles.Semantic Data Normalization For Efficient Clinical Trial Research
Semantic Data Normalization For Efficient Clinical Trial ResearchOntotext
Ěý
This document discusses semantic data normalization of clinical trial data to make it more structured and amenable to analysis. It describes converting unstructured clinical data like conditions, interventions, adverse events and eligibility criteria into RDF triples. The goal is to extract key phrases and concepts, identify qualifiers and relationships to formally represent the data. Examples show how condition texts, drug annotations and criteria can be modeled. Current work has normalized over 215,000 clinical studies from ClinicalTrials.gov into over 80 million RDF triples. The normalized data is pre-loaded in GraphDB and Ontotext S4 Cloud and can be explored and analyzed more easily.Recently uploaded (20)
Who will create the languages of the future?
Who will create the languages of the future?Jordi Cabot
Ěý
Will future languages be created by language engineers?
Can you "vibe" a DSL?
In this talk, we will explore the changing landscape of language engineering and discuss how Artificial Intelligence and low-code/no-code techniques can play a role in this future by helping in the definition, use, execution, and testing of new languages. Even empowering non-tech users to create their own language infrastructure. Maybe without them even realizing. Step by step guide to install Flutter and Dart
Step by step guide to install Flutter and DartS Pranav (Deepu)
Ěý
Flutter is basically Google’s portable user
interface (UI) toolkit, used to build and
develop eye-catching, natively-built
applications for mobile, desktop, and web,
from a single codebase. Flutter is free, open-
sourced, and compatible with existing code. It
is utilized by companies and developers
around the world, due to its user-friendly
interface and fairly simple, yet to-the-point
commands.Looking for a BIRT Report Alternative Here’s Why Helical Insight Stands Out.pdf
Looking for a BIRT Report Alternative Here’s Why Helical Insight Stands Out.pdfVarsha Nayak
Ěý
The search for an Alternative to BIRT Reports has intensified as companies face challenges with BIRT's steep learning curve, limited visualization capabilities, and complex deployment requirements. Organizations need reporting solutions that offer intuitive design interfaces, comprehensive analytics features, and seamless integration capabilities – all while maintaining the reliability and performance that enterprise environments demand.Women in Tech: Marketo Engage User Group - June 2025 - AJO with AWS
Women in Tech: Marketo Engage User Group - June 2025 - AJO with AWSBradBedford3
Ěý
Creating meaningful, real-time engagement across channels is essential to building lasting business relationships. Discover how AWS, in collaboration with Deloitte, set up one of Adobe's first instances of Journey Optimizer B2B Edition to revolutionize customer journeys for B2B audiences.
This session will share the use cases the AWS team has the implemented leveraging Adobe's Journey Optimizer B2B alongside Marketo Engage and Real-Time CDP B2B to deliver unified, personalized experiences and drive impactful engagement.
They will discuss how they are positioning AJO B2B in their marketing strategy and how AWS is imagining AJO B2B and Marketo will continue to work together in the future.
Whether you’re looking to enhance customer journeys or scale your B2B marketing efforts, you’ll leave with a clear view of what can be achieved to help transform your own approach.
Speakers:
Britney Young Senior Technical Product Manager, AWS
Erine de Leeuw Technical Product Manager, AWSMaking significant Software Architecture decisions
Making significant Software Architecture decisionsBert Jan Schrijver
Ěý
Presented at the iSAQB Software Architecture Community NL meetup on 12-6-2025Meet You in the Middle: 1000x Performance for Parquet Queries on PB-Scale Dat...
Meet You in the Middle: 1000x Performance for Parquet Queries on PB-Scale Dat...Alluxio, Inc.
Ěý
Alluxio Webinar
June 10, 2025
For more Alluxio Events: https://www.alluxio.io/events/
Speaker:
David Zhu (Engineering Manager @ Alluxio)
Storing data as Parquet files on cloud object storage, such as AWS S3, has become prevalent not only for large-scale data lakes but also as lightweight feature stores for training and inference, or as document stores for Retrieval-Augmented Generation (RAG). However, querying petabyte-to-exabyte-scale data lakes directly from S3 remains notoriously slow, with latencies typically ranging from hundreds of milliseconds to several seconds.
In this webinar, David Zhu, Software Engineering Manager at Alluxio, will present the results of a joint collaboration between Alluxio and a leading SaaS and data infrastructure enterprise that explored leveraging Alluxio as a high-performance caching and acceleration layer atop AWS S3 for ultra-fast querying of Parquet files at PB scale.
David will share:
- How Alluxio delivers sub-millisecond Time-to-First-Byte (TTFB) for Parquet queries, comparable to S3 Express One Zone, without requiring specialized hardware, data format changes, or data migration from your existing data lake.
- The architecture that enables Alluxio’s throughput to scale linearly with cluster size, achieving one million queries per second on a modest 50-node deployment, surpassing S3 Express single-account throughput by 50x without latency degradation.
- Specifics on how Alluxio offloads partial Parquet read operations and reduces overhead, enabling direct, ultra-low-latency point queries in hundreds of microseconds and achieving a 1,000x performance gain over traditional S3 querying methods.Advanced Token Development - Decentralized Innovation
Advanced Token Development - Decentralized Innovationarohisinghas720
Ěý
The world of blockchain is evolving at a fast pace, and at the heart of this transformation lies advanced token development. No longer limited to simple digital assets, today’s tokens are programmable, dynamic, and play a crucial role in driving decentralized applications across finance, governance, gaming, and beyond.
Generative Artificial Intelligence and its Applications
Generative Artificial Intelligence and its ApplicationsSandeepKS52
Ěý
The exploration of generative AI begins with an overview of its fundamental concepts, highlighting how these technologies create new content and ideas by learning from existing data. Following this, the focus shifts to the processes involved in training and fine-tuning models, which are essential for enhancing their performance and ensuring they meet specific needs. Finally, the importance of responsible AI practices is emphasized, addressing ethical considerations and the impact of AI on society, which are crucial for developing systems that are not only effective but also beneficial and fair.Application Modernization with Choreo - The AI-Native Internal Developer Plat...
Application Modernization with Choreo - The AI-Native Internal Developer Plat...WSO2
Ěý
In this slide deck, we explore the challenges and best practices of application modernization. We also deep dive how an internal developer platform as a service like Choreo can fast track your modernization journey with AI capabilities and end-to-end workflow automation.Porting Qt 5 QML Modules to Qt 6 Webinar
Porting Qt 5 QML Modules to Qt 6 WebinarICS
Ěý
Have you upgraded your application from Qt 5 to Qt 6? If so, your QML modules might still be stuck in the old Qt 5 style—technically compatible, but far from optimal. Qt 6 introduces a modernized approach to QML modules that offers better integration with CMake, enhanced maintainability, and significant productivity gains.
In this webinar, we’ll walk you through the benefits of adopting Qt 6 style QML modules and show you how to make the transition. You'll learn how to leverage the new module system to reduce boilerplate, simplify builds, and modernize your application architecture. Whether you're planning a full migration or just exploring what's new, this session will help you get the most out of your move to Qt 6.Automated Migration of ESRI Geodatabases Using XML Control Files and FME
Automated Migration of ESRI Geodatabases Using XML Control Files and FMESafe Software
Ěý
Efficient data migration is a critical challenge in geospatial data management, especially when working with complex data structures. This presentation explores an automated approach to migrating ESRI Geodatabases using FME and XML-based control files. A key advantage of this method is its adaptability: changes to the data model are seamlessly incorporated into the migration process without requiring modifications to the underlying FME workflow. By separating data model definitions from migration logic, this approach ensures flexibility, reduces maintenance effort, and enhances scalability.Shell Skill Tree - LabEx Certification (LabEx)
Shell Skill Tree - LabEx Certification (LabEx)VICTOR MAESTRE RAMIREZ
Ěý
Shell Skill Tree - LabEx Certification (LabEx)Async-ronizing Success at Wix - Patterns for Seamless Microservices - Devoxx ...
Async-ronizing Success at Wix - Patterns for Seamless Microservices - Devoxx ...Natan Silnitsky
Ěý
In a world where speed, resilience, and fault tolerance define success, Wix leverages Kafka to power asynchronous programming across 4,000 microservices. This talk explores four key patterns that boost developer velocity while solving common challenges with scalable, efficient, and reliable solutions:
1. Integration Events: Shift from synchronous calls to pre-fetching to reduce query latency and improve user experience.
2. Task Queue: Offload non-critical tasks like notifications to streamline request flows.
3. Task Scheduler: Enable precise, fault-tolerant delayed or recurring workflows with robust scheduling.
4. Iterator for Long-running Jobs: Process extensive workloads via chunked execution, optimizing scalability and resilience.
For each pattern, we’ll discuss benefits, challenges, and how we mitigate drawbacks to create practical solutions
This session offers actionable insights for developers and architects tackling distributed systems, helping refine microservices and adopting Kafka-driven async excellence.Zoneranker’s Digital marketing solutions
Zoneranker’s Digital marketing solutionsreenashriee
Ěý
Zoneranker offers expert digital marketing services tailored for businesses in Theni. From SEO and PPC to social media and content marketing, we help you grow online. Partner with us to boost visibility, leads, and sales.
Smadav Pro 2025 Rev 15.4 Crack Full Version With Registration Key
Smadav Pro 2025 Rev 15.4 Crack Full Version With Registration Keyjoybepari360
Ěý
➡️ 🌍📱👉COPY & PASTE LINK👉👉👉
https://crackpurely.site/smadav-pro-crack-full-version-registration-key/AI-Powered Compliance Solutions for Global Regulations | Certivo
AI-Powered Compliance Solutions for Global Regulations | Certivocertivoai
Ěý
Certivo offers AI-powered compliance solutions designed to help businesses in the USA, EU, and UK simplify complex regulatory demands. From environmental and product compliance to safety, quality, and sustainability, our platform automates supplier documentation, manages certifications, and integrates with ERP/PLM systems. Ensure seamless RoHS, REACH, PFAS, and Prop 65 compliance through predictive insights and multilingual support. Turn compliance into a competitive edge with Certivo’s intelligent, scalable, and audit-ready platform.Ad
[Webinar] GraphDB Fundamentals: Adding Meaning to Your Data
- 2. o o o o o o
- 3. o o o o o o
- 4. o o o o o
- 6. o o o o o o
- 8. o o o o o o
- 9. o o o o o o
- 10. o o o
- 11. o o o
- 12. o o
- 13. o o 1.
- 14. o o o o o o
- 15. o o o o o
- 16. o o o o
- 17. o o o o o o o o
- 18. o o o o o o
- 20. o o o o o o
- 22. o o o o o
- 23. o o o o o o
- 25. o o o o o
- 26. o o o o o o o o