What is OLAP -Data Warehouse Concepts - IT Online Training @ Newyorksys
7 likes2,314 views

NEWYORKSYSTRAINING are destined to offer quality IT online training and comprehensive IT consulting services with complete business service delivery orientation.



























































More Related Content
What's hot (20)
Similar to What is OLAP -Data Warehouse Concepts - IT Online Training @ Newyorksys (20)


















Recently uploaded (20)




















What is OLAP -Data Warehouse Concepts - IT Online Training @ Newyorksys
- 1. What Is OLAP? Online Analytical Processing - coined by EF Codd in 1994 paper contracted by Arbor Software * Generally synonymous with earlier terms such as Decisions Support, Business Intelligence, Executive Information System OLAP = Multidimensional Database MOLAP: Multidimensional OLAP (Arbor Essbase, Oracle Express) ROLAP: Relational OLAP (Informix MetaCube, Microstrategy DSS Agent)
- 2. IT ONLINE TRAINING & PLACEMENTS Visit us at http://www.newyorksys.com
- 3. The OLAP Market Rapid growth in the enterprise market 1995: $700 Million 1997: $2.1 Billion Significant consolidation activity among major DBMS vendors 10/94: Sybase acquires ExpressWay 7/95: Oracle acquires Express 11/95: Informix acquires Metacube 1/97: Arbor partners up with IBM 10/96: Microsoft acquires Panorama Result: OLAP shifted from small vertical niche to mainstream DBMS category
- 4. Strengths of OLAP It is a powerful visualization paradigm It provides fast, interactive response times It is good for analyzing time series It can be useful to find some clusters and outliers Many vendors offer OLAP tools
- 5. OLAP Is FASMI Fast Analysis Shared Multidimensional Information
- 6. Multi-dimensional Data “ Hey…I sold $100M worth of goods” Dimensions: Product, Region, Time Hierarchical summarization paths Product Region Time Industry Country Year Category Region Quarter Product City Month Week Office Day Month 1 2 3 4 7 6 5 Product Toothpaste Juice Cola Milk Cream Soap Region W S N
- 7. Data Cube Lattice Cube lattice ABC AB AC BC A B C none Can materialize some groupbys, compute others on demand Question: which groupbys to materialze? Question: what indices to create Question: how to organize data (chunks, etc)
- 8. A Visual Operation: Pivot (Rotate) 10 47 30 12 Juice Cola Milk Cream NY LA SF 3/1 3/2 3/3 3/4 Date Month Region Product
- 9. “ Slicing and Dicing” Product Sales Channel Regions Retail Direct Special Household Telecomm Video Audio India Far East Europe The Telecomm Slice
- 10. Roll-up and Drill Down Sales Channel Region Country State Location Address Sales Representative Roll Up Higher Level of Aggregation Low-level Details Drill-Down
- 11. Nature of OLAP Analysis Aggregation -- (total sales, percent-to-total) Comparison -- Budget vs. Expenses Ranking -- Top 10, quartile analysis Access to detailed and aggregate data Complex criteria specification Visualization
- 12. Organizationally Structured Data Different Departments look at the same detailed data in different ways. Without the detailed, organizationally structured data as a foundation, there is no reconcilability of data marketing manufacturing sales finance
- 13. Multidimensional Spreadsheets Analysts need spreadsheets that support pivot tables (cross-tabs) drill-down and roll-up slice and dice sort selections derived attributes Popular in retail domain
- 14. OLAP - Data Cube Idea: analysts need to group data in many different ways eg. Sales(region, product, prodtype, prodstyle, date, saleamount) saleamount is a measure attribute, rest are dimension attributes groupby every subset of the other attributes materialize (precompute and store) groupbys to give online response Also: hierarchies on attributes: date -> weekday, date -> month -> quarter -> year
- 15. SQL Extensions Front-end tools require Extended Family of Aggregate Functions rank, median, mode Reporting Features running totals, cumulative totals Results of multiple group by total sales by month and total sales by product Data Cube
- 16. Relational OLAP: 3 Tier DSS Store atomic data in industry standard RDBMS. Generate SQL execution plans in the ROLAP engine to obtain OLAP functionality. Obtain multi-dimensional reports from the DSS Client. Data Warehouse ROLAP Engine Decision Support Client Database Layer Application Logic Layer Presentation Layer
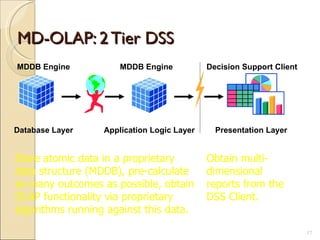
- 17. MD-OLAP: 2 Tier DSS MDDB Engine MDDB Engine Decision Support Client Database Layer Application Logic Layer Presentation Layer Store atomic data in a proprietary data structure (MDDB), pre-calculate as many outcomes as possible, obtain OLAP functionality via proprietary algorithms running against this data. Obtain multi-dimensional reports from the DSS Client.
- 18. Typical OLAP Problems Data Explosion Data Explosion Syndrome Number of Dimensions Number of Aggregations (4 levels in each dimension) Microsoft TechEd’98
- 19. Metadata Repository Administrative metadata source databases and their contents gateway descriptions warehouse schema, view & derived data definitions dimensions, hierarchies pre-defined queries and reports data mart locations and contents data partitions data extraction, cleansing, transformation rules, defaults data refresh and purging rules user profiles, user groups security: user authorization, access control
- 20. Metdata Repository .. 2 Business data business terms and definitions ownership of data charging policies operational metadata data lineage: history of migrated data and sequence of transformations applied currency of data: active, archived, purged monitoring information: warehouse usage statistics, error reports, audit trails.
- 21. Recipe for a Successful Warehouse
- 22. For a Successful Warehouse From day one establish that warehousing is a joint user/builder project Establish that maintaining data quality will be an ONGOING joint user/builder responsibility Train the users one step at a time Consider doing a high level corporate data model in no more than three weeks
- 23. For a Successful Warehouse Look closely at the data extracting, cleaning, and loading tools Implement a user accessible automated directory to information stored in the warehouse Determine a plan to test the integrity of the data in the warehouse From the start get warehouse users in the habit of 'testing' complex queries
- 24. For a Successful Warehouse Coordinate system roll-out with network administration personnel When in a bind, ask others who have done the same thing for advice Be on the lookout for small, but strategic, projects Market and sell your data warehousing systems
- 25. Data Warehouse Pitfalls You are going to spend much time extracting, cleaning, and loading data Despite best efforts at project management, data warehousing project scope will increase You are going to find problems with systems feeding the data warehouse You will find the need to store data not being captured by any existing system You will need to validate data not being validated by transaction processing systems
- 26. Data Warehouse Pitfalls Some transaction processing systems feeding the warehousing system will not contain detail Many warehouse end users will be trained and never or seldom apply their training After end users receive query and report tools, requests for IS written reports may increase Your warehouse users will develop conflicting business rules Large scale data warehousing can become an exercise in data homogenizing
- 27. Data Warehouse Pitfalls 'Overhead' can eat up great amounts of disk space The time it takes to load the warehouse will expand to the amount of the time in the available window... and then some Assigning security cannot be done with a transaction processing system mindset You are building a HIGH maintenance system You will fail if you concentrate on resource optimization to the neglect of project, data, and customer management issues and an understanding of what adds value to the customer
- 28. DW and OLAP Research Issues Data cleaning focus on data inconsistencies, not schema differences data mining techniques Physical Design design of summary tables, partitions, indexes tradeoffs in use of different indexes Query processing selecting appropriate summary tables dynamic optimization with feedback acid test for query optimization: cost estimation, use of transformations, search strategies partitioning query processing between OLAP server and backend server.
- 29. DW and OLAP Research Issues .. 2 Warehouse Management detecting runaway queries resource management incremental refresh techniques computing summary tables during load failure recovery during load and refresh process management: scheduling queries, load and refresh Query processing, caching use of workflow technology for process management
- 30. DATA WAREHOUSING TECHNOLOGIES: InformaticaĚý Hyperion EssbaseĚý Hyperion Interactive ReportsĚý CognosĚý Ab Initio MSBIĚý Data stage 8Ěý MicroStrategyĚý Cognos Planning and BudgetingĚý Cognos TM1Ěý Business ObjectsĚý BODI
- 31. IT ONLINE TRAINING & PLACEMENTS Visit us at http://www.newyorksys.com