











![MPI_Init
It is used initializes the parallel code segment.
Always use to declare the start of
the parallel code segment.
ŌĆó int MPI_Init( int* argc ptr /* in/out */ ,char** argv ptr[ ] /* in/out */)
OR Simply](https://image.slidesharecdn.com/lect5-250130190008-4c83c253-250323072056-a4821757-250405180847-d231916c/85/Wondershare-Filmora-Crack-2025-For-Windows-Free-15-320.jpg)













Wondershare Filmora Crack 2025 For Windows Free
- 2. Shared Memory Model ŌĆó In the shared-memory programming model, tasks share a common address space, which they read and write asynchronously. ŌĆó Various mechanisms such as locks / semaphores may be used to control access to the shared memory. ŌĆó An advantage of this model from the programmer's point of view is that the notion of data "ownership" is lacking, so there is no need to specify explicitly the communication of data between tasks. Program development can often be simplified. ŌĆó An important disadvantage in terms of performance is that it becomes more difficult to understand and manage data locality.
- 3. Shared Memory Model: Implementations ŌĆó On shared memory platforms, the native compilers translate user program variables into actual memory addresses, which are global.
- 5. The Message-Passing Model ŌĆó A process is (traditionally) contain program counter and address space ŌĆó Processes may have multiple threads ŌĆō program counters and associated stacks ŌĆō sharing a single address space. ŌĆó MPI is for communication among processes ’āśseparate address spaces ŌĆó Interprocess communication consists of ŌĆō Synchronization ŌĆō Movement of data from one processŌĆÖs address space to anotherŌĆÖs.
- 6. Message Passing Model Implementations: MPI ŌĆó From a programming perspective, message passing implementations commonly comprise a library of subroutines that are imbedded in source code. The programmer is responsible for determining all parallelism. ŌĆó Historically, a variety of message passing libraries have been available since the 1980s. These implementations differed substantially from each other making it difficult for programmers to develop portable applications. ŌĆó In 1992, the MPI Forum was formed with the primary goal of establishing a standard interface for message passing implementations. ŌĆó Part 1 of the Message Passing Interface (MPI) was released in 1994. Part 2 (MPI-2) was released in 1996. Both MPI specifications are available on the web at www.mcs.anl.gov/Projects/mpi/standard.html.
- 7. Types of Parallel Computing Models ŌĆó Data Parallel ŌĆō the same instructions are carried out simultaneously on multiple data items (SIMD) ŌĆó Task Parallel ŌĆō different instructions on different data (MIMD) ŌĆó SPMD (single program, multiple data) ŌĆō not synchronized at individual operation level ŌĆó SPMD is equivalent to MIMD since each MIMD program can be made SPMD (similarly for SIMD, but not in practical sense) Message passing (and MPI) is for MIMD/SPMD parallelism. HPF is an example of a SIMD interface
- 8. Message Passing ŌĆó Basic Message Passing: ŌĆō Send: Analogous to mailing a letter ŌĆō Receive: Analogous to picking up a letter from the mailbox ŌĆō Scatter-gather: Ability to ŌĆ£scatterŌĆØ data items in a message into multiple memory locations and ŌĆ£gatherŌĆØ data items from multiple memory locations into one message ŌĆó Network performance: ŌĆō Latency: The time from when a Send is initiated until the first byte is received by a Receive. ŌĆō Bandwidth: The rate at which a sender is able to send data to a receiver.
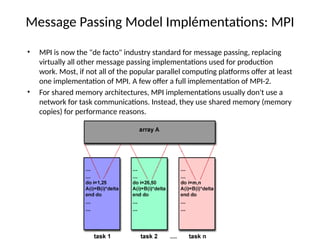
- 9. Message Passing Model Impl├®mentations: MPI ŌĆó MPI is now the "de facto" industry standard for message passing, replacing virtually all other message passing implementations used for production work. Most, if not all of the popular parallel computing platforms offer at least one implementation of MPI. A few offer a full implementation of MPI-2. ŌĆó For shared memory architectures, MPI implementations usually don't use a network for task communications. Instead, they use shared memory (memory copies) for performance reasons.
- 10. Methods of Creating Process ŌĆó Two method of creating Process 1. Static Process Communication ŌĆó Numbers specified before execution starts ŌĆó programmer explicitly mention in code ŌĆó Difficult programming but easy implementation 2. Dynamic Process Communication ŌĆó Process creates during execution of other processes ŌĆó System calls are used to create processes ŌĆó Process number vary during execution
- 11. Methods of Creating Process ŌĆó In reality Process number are defined prior to execution ŌĆó One master Processes ŌĆó Many slave Processes which are identical in functionality but have different id
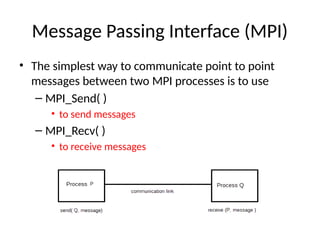
- 12. Message Passing Interface (MPI) ŌĆó The simplest way to communicate point to point messages between two MPI processes is to use ŌĆō MPI_Send( ) ŌĆó to send messages ŌĆō MPI_Recv( ) ŌĆó to receive messages
- 13. Message Passing Interface (MPI) Requirement ŌĆó The data type being sent/received ŌĆó The receiver's process ID when sending ŌĆó The senderŌĆÖs process ID (or MPI_ANY_SOURCE) when receiving ŌĆó The senderŌĆÖs tag ID (or MPI_ANY_TAG) when receiving
- 14. Message Passing Interface (MPI) ŌĆó In order to receive a message, MPI requires the type, processid and the tag match if they donŌĆÖt match, the receive call will wait forever-hanging your program
- 15. MPI_Init It is used initializes the parallel code segment. Always use to declare the start of the parallel code segment. ŌĆó int MPI_Init( int* argc ptr /* in/out */ ,char** argv ptr[ ] /* in/out */) OR Simply
- 16. MPI_Finalize ŌĆó It is used to declare the end of the parallel code segment. It is important to note ŌĆó that it takes no arguments. ŌĆó int MPI Finalize(void) or simply MPI_Finalize()
- 17. MPI_Comm_rank ŌĆó It provides you with your process identification or rank ŌĆó Which is an integer ranging from 0 to P ŌłÆ 1, where P is the number of processes on which are running), ŌĆó int MPI_Comm_rank(MPI Comm comm /* in */,int* result /* out */) or simply ŌĆó MPI_Comm_rank(MPI_COMM_WORLD,&myrank)
- 18. MPI_Comm_size ŌĆó It provides you with the total number of processes that have been allocated. ŌĆó int MPI_Comm_size( MPI Comm comm /* in */,int* size /* out */) or simply ŌĆó MPI_Comm_size(MPI_COMM_WORLD,&mysize)
- 19. MPI_COMM_WORLD ŌĆó comm is called the communicator, and it essentially is a designation for a collection of processes which can communicate with each other. ŌĆó MPI has functionality to allow you to specify varies communicators (differing collections of processes); ŌĆó however, generally MPI_COMM_WORLD, which is predefined within MPI and consists of all the processes initiated when a parallel program, is used.
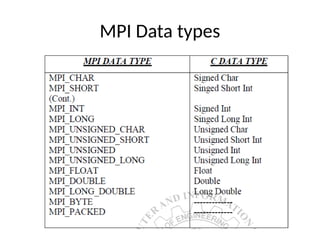
- 20. MPI Data types
- 21. MPI_Send ŌĆó int MPI_Send( void* message /* in */, int count /* in */, MPI Datatype datatype /* in */, int dest /* in */, int tag /* in*/, MPI Comm comm /* in */ )
- 22. MPI_Recv ŌĆó int MPI_Recv( void* message /* out */, int count /* in */, MPI Datatype datatype /* in */, int source /* in */, int tag /* in*/, MPI Comm comm /* in */, MPI Status* status /* out */)
- 23. #include <iostream.h> #include <mpi.h> int main(int argc, char * argv) { int mynode, totalnodes; int datasize; // number of data units to be sent/recv int sender=2; // process number of the sending process int receiver=4; // process number of the receiving process int tag; // integer message tag MPI_Status status; // variable to contain status information MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD, &totalnodes); MPI_Comm_rank(MPI_COMM_WORLD, &mynode); // Determine datasize databuffer=111 if(mynode==sender) MPI_Send(databuffer,datasize,MPI_DOUBLE,receiver, tag,MPI_COMM_WORLD); if(mynode==receiver) MPI_Recv(databuffer,datasize,MPI_DOUBLE,sender,tag, MPI_COMM_WORLD,&status); Print(ŌĆ£Processor %d got % /n,ŌĆØ myid, databuffer); // Send/Recv complete MPI_Finalize(); }
- 24. Argument List ŌĆó message - starting address of the send/recv buffer. ŌĆó count - number of elements in the send/recv buffer. ŌĆó datatype - data type of the elements in the send buffer. ŌĆó source - process rank to send the data. ŌĆó dest - process rank to receive the data. ŌĆó tag - message tag. ŌĆó comm - communicator. ŌĆó status - status object.
- 25. Example Code 1
- 26. Important Points ŌĆó In general, the message array for both the sender and receiver should be of the same type and both of same size at least datasize. ŌĆó In most cases the sendtype and recvtype are identical. ŌĆó The tag can be any integer between 0-32767. ŌĆó MPI Recv may use for the tag the wildcard MPI ANY TAG. This allows an MPI Recv to receive from a send using any tag. ŌĆó MPI Send cannot use the wildcard MPI ANY TAG. A special tag must be specified. ŌĆó MPI Recv may use for the source the wildcard MPI ANY SOURCE. This allows an MPI Recv to receive from a send from any source. ŌĆó MPI Send must specify the process rank of the destination. No wildcard exists.
- 27. Example Code 2
- 28. ŌĆó #include<iostream.h> ŌĆó #include<mpi.h> ŌĆó int main(int argc, char ** argv) ŌĆó { ŌĆó int mynode, totalnodes; ŌĆó int sum,startval,endval,accum; ŌĆó MPI_Status status; ŌĆó MPI_Init(argc,argv); ŌĆó MPI_Comm_size(MPI_COMM_WORLD, &totalnodes); ŌĆó MPI_Comm_rank(MPI_COMM_WORLD, &mynode); ŌĆó sum = 0; ŌĆó startval = 1000*mynode/totalnodes+1; ŌĆó endval = 1000*(mynode+1)/totalnodes; ŌĆó for(int i=startval;i<=endval;i=i+1) ŌĆó sum = sum + i; ŌĆó if(mynode!=0) ŌĆó MPI_Send(&sum,1,MPI_INT,0,1,MPI_COMM_WORLD); ŌĆó else ŌĆó for(int j=1;j<totalnodes;j=j+1) ŌĆó {
- 29. MPI_Recv(&accum,1,MPI_INT,j,1,MPI_COMM_WORLD,&status); sum = sum + accum; } if(mynode == 0) cout << "The sum from 1 to 1000 is: " << sum << endl; MPI_Finalize(); }