









XGBoost (System Overview)
- 1. XGBOOST: A SCALABLE TREE BOOSTING SYSTEM (T. CHEN, C. GUESTRIN, 2016) NATALLIE BAIKEVICH HARDWARE ACCELERATION FOR DATA PROCESSING SEMINAR ETH ZÃRICH
- 2. MOTIVATION ïž Effective statistical models ïž Scalable system ïž Successful real-world applications XGBoost eXtreme Gradient Boosting
- 3. BIAS-VARIANCE TRADEOFF Random Forest Variance â Boosting Bias â Voting + +
- 4. A BIT OF HISTORY AdaBoost, 1996 Random Forests, 1999 Gradient Boosting Machine, 2001
- 5. AdaBoost, 1996 Random Forests, 1999 Gradient Boosting Machine, 2001 Various improvements in tree boosting XGBoost package A BIT OF HISTORY
- 6. AdaBoost, 1996 Random Forests, 1999 Gradient Boosting Machine, 2001 Various improvements in tree boosting XGBoost package 1st Kaggle success: Higgs Boson Challenge 17/29 winning solutions in 2015 A BIT OF HISTORY
- 7. WHY DOES XGBOOST WIN "EVERY" MACHINE LEARNING COMPETITION? - (MASTER THESIS, D. NIELSEN, 2016) Source: https://github.com/dmlc/xgboost/tree/master/demo#machine-learning-challenge-winning-solutions
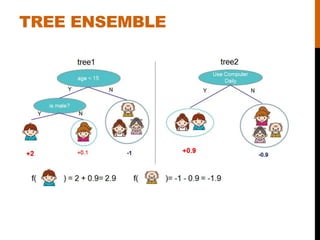
- 9. REGULARIZED LEARNING OBJECTIVE L = l( Ëyi, yi ) i ÃĨ + W( fk ) k ÃĨ W( f ) =gT + 1 2 l w 2 Source: http://xgboost.readthedocs.io/en/latest/model.html Ëyi = fk (xi ) k=1 K ÃĨ loss regularization # of leaves
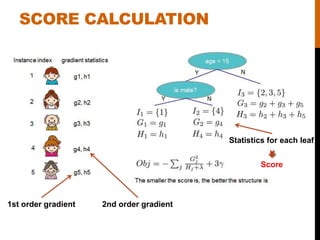
- 10. SCORE CALCULATION 1st order gradient 2nd order gradient Statistics for each leaf Score
- 11. ALGORITHM FEATURES ïž Regularized objective ïž Shrinkage and column subsampling ïž Split finding: exact & approximate, global & local ïž Weighted quantile sketch ïž Sparsity-awareness
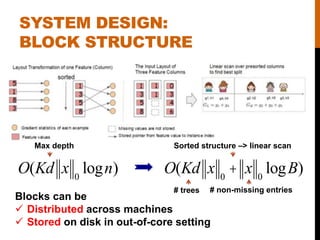
- 12. SYSTEM DESIGN: BLOCK STRUCTURE O(Kd x 0 logn) O(Kd x 0 + x 0 logB) Blocks can be ïž Distributed across machines ïž Stored on disk in out-of-core setting Sorted structure â> linear scan # trees Max depth # non-missing entries
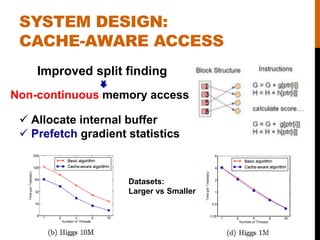
- 13. SYSTEM DESIGN: CACHE-AWARE ACCESS Improved split finding ïž Allocate internal buffer ïž Prefetch gradient statistics Non-continuous memory access Datasets: Larger vs Smaller
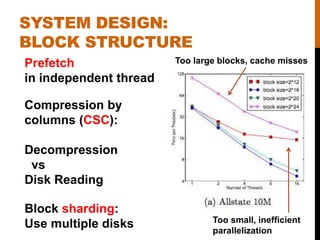
- 14. SYSTEM DESIGN: BLOCK STRUCTURE Compression by columns (CSC): Decompression vs Disk Reading Block sharding: Use multiple disks Too large blocks, cache misses Too small, inefficient parallelization Prefetch in independent thread
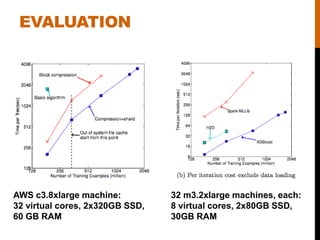
- 15. EVALUATION AWS c3.8xlarge machine: 32 virtual cores, 2x320GB SSD, 60 GB RAM 32 m3.2xlarge machines, each: 8 virtual cores, 2x80GB SSD, 30GB RAM
- 16. DATASETS Dataset n m Task Allstate 10M 4227 Insurance claim classification Higgs Boson 10M 28 Event classification Yahoo LTRC 473K 700 Learning to rank Criteo 1.7B 67 Click through rate prediction
- 17. WHATâS NEXT? Model Extensions DART (+ Dropouts) LinXGBoost Parallel Processing GPU FPGA Tuning Hyperparameter optimization More Applications XGBoost Scalability Weighted quantiles Sparsity-awareness Cache-awarereness Data compression