Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
?
27 likes?21,027 views

Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ / Hadoop / Spark Conference Japan 2019 講演者: 関山 宜孝 (Amazon Web Services Japan) 昨今 Hadoop/Spark エコシステムで広く使われているクラウドストレージ。本講演では Amazon S3 を例に、Hadoop/Spark から見た S3 の動作や HDFS と S3 の使い分けをご説明します。また、AWS サポートに寄せられた多くのお問い合わせから得られた知見をもとに、Hadoop/Spark で S3 を最大限活用するベストプラクティス、パフォーマンスチューニング、よくあるハマりどころ、トラブルシューティング方法などをご紹介します。併せて、Hadoop/Spark に関係する S3 のサービスアップデート、S3 関連の Hadoop/Spark コミュニティの直近の開発状況についても解説します。 http://hadoop.apache.jp/hcj2019-program/













































Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
- 1. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Noritaka Sekiyama Senior Cloud Support Engineer, Amazon Web Services Japan 2019.03.14 Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ
- 2. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 関山 宜孝 (Noritaka Sekiyama) Senior Cloud Support Engineer - AWS サポートの中の人 - 専門は Big Data (EMR, Glue, Athena, …) - AWS Glue の専門家 - Apache Spark 好き Who I am... @moomindani
- 3. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 質問 ? Hadoop/Spark で S3 を既に使用中 ? Hadoop/Spark で今後 S3 の使用を検討中 ? Hadoop/Spark と S3 等のクラウドストレージの関係に興味あり 本日のセッションについて
- 4. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop/Spark と S3 の関係 HDFS と S3 の違いと使い分け Hadoop/Spark から見た S3 の動作 よくあるハマりどころとチューニング Hadoop/Spark に関係する S3/AWS サービスアップデート S3 関連の Hadoop/Spark コミュニティの直近の開発状況 アジェンダ
- 5. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop/Spark と S3 の関係
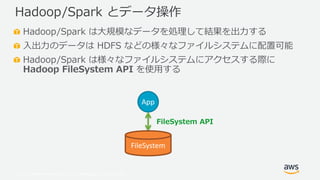
- 6. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop/Spark は大規模なデータを処理して結果を出力する 入出力のデータは HDFS などの様々なファイルシステムに配置可能 Hadoop/Spark は様々なファイルシステムにアクセスする際に Hadoop FileSystem API を使用する Hadoop/Spark とデータ操作 FileSystem App FileSystem API
- 7. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop FileSystem API ? Hadoop のファイルシステム操作用のインタフェース ? open: 入力ストリームをオープン ? create: ファイルを作成 ? append: ファイルを追記 ? getFileBlockLocations: 対象のブロックの位置を取得 ? rename: ファイルをリネーム ? mkdir: ディレクトリを作成 ? listFiles: ファイルをリスト ? delete: ファイルを削除 ? FileSystem API の異なる実装を利用すると HDFS 以外のデータストアを HDFS と同様の操作感で利用可能 ? LocalFileSystem, S3AFileSystem, EmrFileSystem Hadoop/Spark とファイルシステム
- 8. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HDFS とは ? 高スループットのデータアクセスを提供する分散ファイルシステム ? サイズの大きい (100MB+, GB, TB) ファイルに最適化 ? 低レイテンシが要求されたり、多数の小さいファイルがあるケースには向かない ? メタデータを管理する NameNode, データのブロックを管理?格納する DataNode で構成される ? Hadoop 3.x では Erasure Coding, Router based federation, Tiered storage, Ozone などの機能が活発に開発されている アクセス方法 ? Hadoop FileSystem API ? $ hadoop fs ... ? HDFS Web UI HDFS: Hadoop Distributed File System
- 9. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon S3 とは ? 高いスケーラビリティ、可用性、耐障害性 (99.999999999%)、セキュリティ、 およびパフォーマンスを提供するオブジェクトストレージサービス ? 主に、保管されたデータサイズと、リクエストに対して課金 ? 単一オブジェクトの最大サイズは 5TB ? オブジェクトはバケット配下のユニークなキー名で管理される ? ディレクトリは S3 コンソール上では疑似的に表現されるが、実態としては存在しない ? ファイルシステムではない アクセス方法 ? REST API (GET, SELECT, PUT, POST, COPY, LIST, DELETE, CANCEL, ...) ? AWS CLI ? AWS SDK ? S3 コンソール Amazon S3
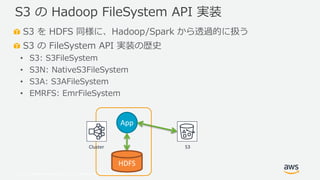
- 10. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. S3 を HDFS 同様に、Hadoop/Spark から透過的に扱う S3 の FileSystem API 実装の歴史 ? S3: S3FileSystem ? S3N: NativeS3FileSystem ? S3A: S3AFileSystem ? EMRFS: EmrFileSystem S3 の Hadoop FileSystem API 実装 Cluster S3 HDFS App
- 11. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HADOOP-574: want FileSystem implementation for Amazon S3 2006年に S3 をファイルシステムとして扱うために開発された ? S3 上のオブジェクトのデータ=ブロックのデータ(≠ファイルのデータ) ? ブロックを直接 S3 上に配置して管理 ? S3FileSystem を通してしか読み書きできない URL のプレフィックスに s3:// を使用 2016年に廃止済 https://issues.apache.org/jira/browse/HADOOP-574 S3: S3FileSystem
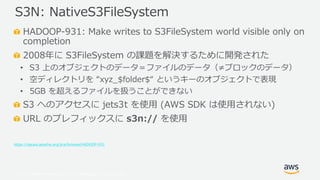
- 12. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HADOOP-931: Make writes to S3FileSystem world visible only on completion 2008年に S3FileSystem の課題を解決するために開発された ? S3 上のオブジェクトのデータ=ファイルのデータ(≠ブロックのデータ) ? 空ディレクトリを “xyz_$folder$“ というキーのオブジェクトで表現 ? 5GB を超えるファイルを扱うことができない S3 へのアクセスに jets3t を使用 (AWS SDK は使用されない) URL のプレフィックスに s3n:// を使用 https://issues.apache.org/jira/browse/HADOOP-931 S3N: NativeS3FileSystem
- 13. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HADOOP-10400: Incorporate new S3A FileSystem implementation 2014年に NativeS3FileSystem の課題を解決するために開発された ? 並列コピー/リネームに対応 ? 空ディレクトリの扱いを S3 コンソール互換に変更 ("xyz_$folder$“->”xyz/”) ? IAM ロール認証に対応 ? 5GB を超えるファイルに対応 / マルチパートアップロードに対応 ? S3 サーバーサイド暗号化に対応 ? エラーからのリカバリの改善 S3 へのアクセスに AWS SDK for Java を使用 URL のプレフィックスに s3a:// を使用 Amazon EMR は現時点で S3A を公式にサポートしていない https://issues.apache.org/jira/browse/HADOOP-10400 https://wiki.apache.org/hadoop/AmazonS3 S3A: S3AFileSystem
- 14. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon EMR における FileSystem 実装(EMR 上で使用可能) S3 の特性に合わせて Amazon 独自で開発 ? IAM ロール認証に対応 ? 5GB を超えるファイルに対応 / マルチパートアップロードに対応 ? S3 サーバーサイド/クライアントサイド暗号化に対応 ? EMRFS S3-optimized Committer を利用可能(後述) ? S3 SELECT によるプッシュダウンに対応(後述) S3 へのアクセスに AWS SDK for Java を使用 URL のプレフィックスに s3:// (または s3n://)を使用 https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-fs.html EMRFS: EmrFileSystem
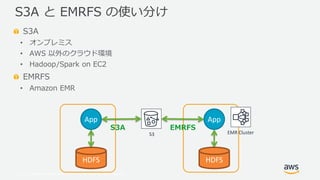
- 15. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. S3A ? オンプレミス ? AWS 以外のクラウド環境 ? Hadoop/Spark on EC2 EMRFS ? Amazon EMR S3A と EMRFS の使い分け EMR ClusterS3 HDFS App HDFS App S3A EMRFS
- 16. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 上の選択肢 ? EMR: 主要なユースケースをカバー ? Hadoop/Spark on EC2: EMR が適さない特定ユースケース向け ? マルチマスター (ただし EMR でも Coming Soon) /AmazonWebServices/a-deep-dive-into-whats-new-with-amazon-emr-ant340r1-aws-reinvent-2018/64 ? EMRにない特定のアプリケーションバージョンの組み合わせが必要 ? 特定の Hadoop/Spark ディストリビューションを使用 ? Glue: サーバーレス Spark として使用可能 Hadoop/Spark と AWS
- 17. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HDFS と S3 の違いと使い分け
- 18. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop FileSystem API 経由で透過的にアクセス可能 URL プレフィックス(“hdfs://”, “s3://”, “s3a://”)を指定 HDFS と S3 の共通点
- 19. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 極めて高い I/O パフォーマンスが必要な場合 データのアクセス頻度が高い場合 一時データを配置する場合 高い整合性が必要な場合 ? S3 の結果整合性が許容できず、いずれの対処方法も許容できない場合 データ保管と I/O のコストを固定したい場合 データローカリティが効く場合 (ノード間のネットワーク帯域が1G程度の場合) データ配置先の機器の物理的な配置をコントロールしたい場合 HDFS が適したワークロード?データ
- 20. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 極めて高い可用性?耐障害性が必要な場合 ? 耐障害性: 99.999999999% ? 可用性:99.99% アクセス頻度の低いコールドデータを長期間保存する場合 ? “S3 標準” 以外に、”標準 –IA” などの安価なストレージクラスも利用可能 https://aws.amazon.com/s3/storage-classes/ データサイズに対するコストを抑えたい場合 ? 同じサイズの HDFS に比べてサイズ単価のコストが小さい(外部の試算では 1/5 以下) データサイズが巨大または大きく増え続ける場合 ? ストレージ容量の限界がないため、空き容量等の管理が不要 S3 が適したワークロード?データ (1/2)
- 21. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. コンピューティング用クラスタとストレージを分離したい場合 ? 処理が終わったクラスタを廃棄してもデータは S3 上に残る 複数のクラスタ/アプリケーションから共用したい場合 ? 複数の Hadoop/Spark クラスタから同一のファイルシステムを使用 ? EMR, Glue, Athena, Redshift Spectrum, Hadoop/Spark on EC2 等 (Hadoop の仕組み以外を含めて) セキュリティを一元管理したい場合 ? IAM, S3 バケットポリシー, VPC Endpoint, Glue Data Catalog 等 ? 今後 LakeFormation により利便性が向上する見込み ※デフォルトファイルシステム(fs.defaultFS)には使用できない https://aws.amazon.com/premiumsupport/knowledge-center/configure-emr-s3-hadoop-storage/ S3 が適したワークロード?データ (2/2)
- 22. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop/Spark から見た S3 の動作
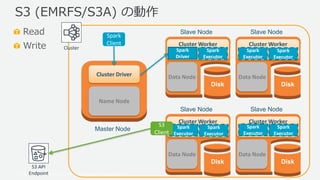
- 23. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Read Write S3 (EMRFS/S3A) の動作 Master Node Name Node Cluster Driver Disk Slave Node Data Node Cluster Worker Disk Slave Node Data Node Cluster Worker Disk Slave Node Data Node Cluster Worker Spark Driver Disk Slave Node Data Node Cluster Worker Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor Spark Executor S3 Client Spark Client Cluster S3 API Endpoint
- 24. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Split とは ? Hadoop/Spark が処理する対象のデータを分割したチャンク ? 分割可能なフォーマット(bzip2等)のデータは定義されたサイズで分割される よくある問題 ? 多数の小さいファイルから大量の Split が生成されオーバーヘッドが増大 ? 分割不可な巨大ファイルが入力となりメモリが枯渇 Split のデフォルトサイズ ? HDFS: 128MB (推奨:HDFS Blockサイズ = Split サイズ) ? S3 EMRFS: 64MB (fs.s3.block.size) ? S3 S3A: 32MB (fs.s3a.block.size) 分割可能なファイルに対する S3 へのリクエスト ? S3 GetObject API にて Range パラメータで Content Length を指定 ? ステータスコード: 206 (Partial Content) S3 (EMRFS/S3A) の動作: Split
- 25. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. ハマりどころとチューニング - S3 整合性モデル
- 26. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 新規オブジェクトの PUT: 書き込み後の読み込み整合性 ? PUT したオブジェクトを直後に GET すると一貫した結果が得られる 存在しないオブジェクトの HEAD/GET: 結果整合性 ? PUT 前のオブジェクトを存在確認のために HEAD/GET して、 その後にオブジェクトを PUT して GET すると結果整合性となる PUT および DELETE の上書き: 結果整合性 ? 既存オブジェクトを PUT して GET すると古いデータが返却される場合がある ? 既存オブジェクトを DELETE して GET すると削除済データが返却される場合がある オブジェクトの LIST: 結果整合性 ? 新規オブジェクトを PUT して直後に LIST すると、追加されたオブジェクトがリストに 含まれない場合がある ? 既存オブジェクトを DELETE して直後に LIST すると、削除済のオブジェクトがリスト に含まれる場合がある https://docs.aws.amazon.com/AmazonS3/latest/dev/Introduction.html#ConsistencyModel S3 整合性モデル
- 27. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 例:複数ステップの ETL データ処理パイプライン ? ステップ1: 入力の生データを整形、フォーマット変換 ? ステップ2: 変換後のデータを入力として統計処理 想定される問題 ? ステップ1で S3 に出力したデータが、直後に実行されるステップ2 の入力と するデータのリストに含まれない場合がある 影響が出やすいワークロード ? 複数のジョブで構成され、迅速かつ連続的で厳密な処理が必要なワークロード S3 整合性モデルによる Hadoop/Spark への影響
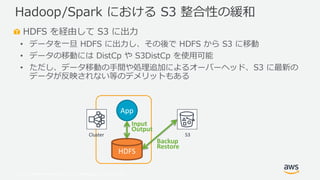
- 28. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HDFS を経由して S3 に出力 ? データを一旦 HDFS に出力し、その後で HDFS から S3 に移動 ? データの移動には DistCp や S3DistCp を使用可能 ? ただし、データ移動の手間や処理追加によるオーバーヘッド、S3 に最新の データが反映されない等のデメリットもある Hadoop/Spark における S3 整合性の緩和 Cluster S3 HDFS App Input Output Backup Restore
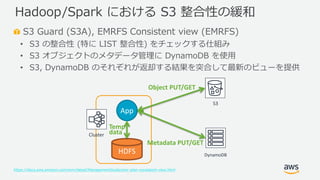
- 29. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. S3 Guard (S3A), EMRFS Consistent view (EMRFS) ? S3 の整合性 (特に LIST 整合性) をチェックする仕組み ? S3 オブジェクトのメタデータ管理に DynamoDB を使用 ? S3, DynamoDB のそれぞれが返却する結果を突合して最新のビューを提供 https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-consistent-view.html Hadoop/Spark における S3 整合性の緩和 Cluster S3 HDFS App Temp data DynamoDB Object PUT/GET Metadata PUT/GET
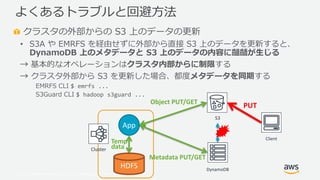
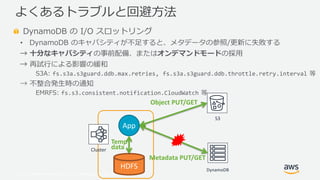
- 30. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. クラスタの外部からの S3 上のデータの更新 ? S3A や EMRFS を経由せずに外部から直接 S3 上のデータを更新すると、 DynamoDB 上のメタデータと S3 上のデータの内容に齟齬が生じる → 基本的なオペレーションはクラスタ内部からに制限する → クラスタ外部から S3 を更新した場合、都度メタデータを同期する EMRFS CLI $ emrfs ... S3Guard CLI $ hadoop s3guard ... よくあるトラブルと回避方法 Cluster S3 HDFS App Temp data DynamoDB Object PUT/GET Metadata PUT/GET Client PUT
- 31. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. DynamoDB の I/O スロットリング ? DynamoDB のキャパシティが不足すると、メタデータの参照/更新に失敗する → 十分なキャパシティの事前配備、またはオンデマンドモードの採用 → 再試行による影響の緩和 S3A: fs.s3a.s3guard.ddb.max.retries, fs.s3a.s3guard.ddb.throttle.retry.interval 等 → 不整合発生時の通知 EMRFS: fs.s3.consistent.notification.CloudWatch 等 よくあるトラブルと回避方法 Cluster S3 HDFS App Temp data DynamoDB Object PUT/GET Metadata PUT/GET
- 32. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. ハマりどころとチューニング - マルチパートアップロード
- 33. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. サイズの大きいデータに対してマルチパートアップロードを使用 ? S3A/EMRFS ともに同様の動作 ? サイズの閾値はパラメータで指定 EMRFS: fs.s3n.multipart.uploads.split.size 等 S3A: fs.s3a.multipart.threshold 等 EMRの場合: EMRFS S3-optimized Commiter (後述)を有効化すると、 データのサイズによらず常にマルチパートアップロードを使用 Hadoop/Spark とマルチパートアップロード
- 34. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. マルチパートアップロードの開始 ? 開始リクエストを送信してアップロードIDを取得 各パートのアップロード ? アップロードIDとパート番号を添えてアップロード ? 明示的に完了/中止しないとパートは残存し、ストレージ課金が継続 マルチパートアップロードの完了/中止 ? パート番号に基づいて昇順に連結したオブジェクトを S3 上に生成 ? 個々のパートは解放され、ストレージも解放される マルチパートアップロードの流れ マルチパート アップロード の開始 各パートの アップロード マルチパート アップロード の完了/中止
- 35. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 未完了のパートの残存 ? ジョブの Abort 等により未完了のパート(課金対象)が残存する場合がある ? 未完了のパートは S3 コンソールから確認できない → S3 バケットのライフサイクル設定により未完了のパートを定期的に削除 → マルチパート関連のパラメータを設定 EMRFS: fs.s3.multipart.clean.enabled 等 S3A: fs.s3a.multipart.purge 等 → AWS CLI で以下のコマンドを実行してパート有無を確認可能 よくあるトラブルと回避方法 $ aws s3api list-multipart-uploads --bucket bucket-name
- 36. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. ハマりどころとチューニング - S3 リクエストパフォーマンス
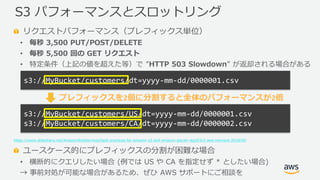
- 37. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. リクエストパフォーマンス(プレフィックス単位) ? 毎秒 3,500 PUT/POST/DELETE ? 毎秒 5,500 回の GET リクエスト ? 特定条件(上記の値を超えた等)で ”HTTP 503 Slowdown” が返却される場合がある /AmazonWebServices/best-practices-for-amazon-s3-and-amazon-glacier-stg203r2-aws-reinvent-2018/50 ユースケース的にプレフィックスの分割が困難な場合 ? 横断的にクエリしたい場合 (例では US や CA を指定せず * としたい場合) → 事前対処が可能な場合があるため、ぜひ AWS サポートにご相談を S3 パフォーマンスとスロットリング s3://MyBucket/customers/dt=yyyy-mm-dd/0000001.csv s3://MyBucket/customers/US/dt=yyyy-mm-dd/0000001.csv s3://MyBucket/customers/CA/dt=yyyy-mm-dd/0000002.csv プレフィックスを2個に分割すると全体のパフォーマンスが2倍
- 38. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. S3 コネクションの調整 ? S3 リクエストの同時実行数を調整するためにコネクションの数を調整可能 EMRFS: fs.s3.maxConnections 等 S3A: fs.s3a.connection.maximum 等 S3 リクエストの再試行 ? リクエストのスロットリングに備え、リクエストの再試行の動作を調整可能 EMRFS: fs.s3.retryPeriodSeconds (EMR 5.14以降), fs.s3.maxRetries (EMR 5.12以前) 等 S3A: fs.s3a.retry.throttle.limit, fs.s3a.retry.throttle.interval 等 S3 パフォーマンス関係のチューニング
- 39. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. ハマりどころとチューニング - その他
- 40. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. よくあるトラブル ? S3 上の Hive テーブルに書き込む際に性能が出ない ? 書き込みの並列性が不足している ? (最終的な出力だけでなく) 中間データも (HDFS ではなく) S3 に書き込む 回避方法 ? 並列性 ? hive.mv.files.threads ? 中間データ ? hive.blobstore.use.blobstore.as.scratchdir = false ? 10倍高速化する事例も https://issues.apache.org/jira/browse/HIVE-14269 https://issues.apache.org/jira/browse/HIVE-14270 Hive Write パフォーマンスのチューニング
- 41. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. よくあるトラブル ? S3A 経由のファイルアップロードが遅い ? アップロード時にディスク/メモリが枯渇する 回避方法 ? S3A Fast Upload 関連のパラメータをチューニングする ? fs.s3a.fast.upload.buffer: disk, array, bytebuffer ? fs.s3a.fast.upload.active.blocks S3A Fast Upload のチューニング
- 42. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop/Spark に関係する S3/AWS サービスアップデート
- 43. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 以前のリクエストパフォーマンス ? 毎秒 100 回の PUT/LIST/DELETE リクエスト ? 毎秒 300 回の GET リクエスト 現在のリクエストパフォーマンス(プレフィックス単位) ? 毎秒 3,500 PUT/POST/DELETE ? 毎秒 5,500 回の GET リクエスト 2018.7: S3 リクエストパフォーマンス改善
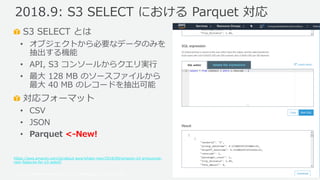
- 44. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. S3 SELECT とは ? オブジェクトから必要なデータのみを 抽出する機能 ? API, S3 コンソールからクエリ実行 ? 最大 128 MB のソースファイルから 最大 40 MB のレコードを抽出可能 対応フォーマット ? CSV ? JSON ? Parquet <-New! https://aws.amazon.com/jp/about-aws/whats-new/2018/09/amazon-s3-announces- new-features-for-s3-select/ 2018.9: S3 SELECT における Parquet 対応
- 45. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. EMRFS で S3 SELECT による Pushdown に対応 ? 期待できる効果: パフォーマンス向上、データ転送の削減 ? 対応アプリケーション: Hive, Spark, Presto ? 有効化手順: 各アプリケーションの設定を追加 ※ワークロードに応じて S3 SELECT の実施有無を自動判定するわけではない ? 有効なケース: ? クエリによって元データの半分以上をフィルタアウトする場合 ? S3 と EMR の間で十分なネットワーク帯域がある場合 ? Pushdown 対象のカラムのデータ型が S3 SELECT と Hive/Spark/Presto の両方でサポートされている場合 → S3 SELECT がアプリケーションと実際のワークロードに適しているか確認 するため、有効/無効の両方でベンチマークを実施することを推奨 Hive: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-hive-s3select.html Spark: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-s3select.html Presto: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-presto-s3select.html 2018.10: EMRFS の S3 SELECT による Pushdown
- 46. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. EMRFS S3-optimized committer とは ? EMR 5.19.0 以降で導入された Output Committer (5.20.0 以降デフォルト) ? Spark SQL / DataFrames / Datasets を使用して Parquet ファイルを書 き込む Spark ジョブで使用される ? S3 マルチパートアップロードの仕組みを活用 メリット ? ジョブ/タスクコミットフェーズ中に S3 への LIST/RENAME オペレーション を回避し、アプリケーションのパフォーマンスを向上 ? ジョブ/タスクコミットフェーズで S3 結果整合性による問題を回避し、タスク 失敗時のジョブの正確性を向上 https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark-s3-optimized-committer.html https://aws.amazon.com/blogs/big-data/improve-apache-spark-write-performance-on-apache-parquet-formats-with-the-emrfs-s3-optimized-committer/ 2018.11: EMRFS S3-optimized committer
- 47. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. FileOutputCommitter との違い ? FileOutputCommitterV1: 2段階の RENAME ? 個々のタスクの出力をコミットするときの RENAME ? 完了/成功タスクの出力からジョブ全体の出力をコミットするときの RENAME ? FileOutputCommitterV2: 1段階の RENAME ? ファイルを直接最終出力先にコミットするときの RENAME ? 注:ジョブ完了前に部分的なデータが可視となる (いずれのバージョンでも、一旦一時領域に出力して RENAMEする) ? EMRFS S3-optimized committer ? S3 マルチパートアップロードの特性を活用して RENAME を回避 RENAME に注目する理由 ? HDFS に対する RENAME:メタデータのみの操作 ? S3 に対する RENAME:N 回のデータのコピーおよび元データの削除→遅い 2018.11: EMRFS S3-optimized committer
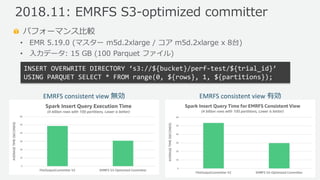
- 48. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. パフォーマンス比較 ? EMR 5.19.0 (マスター m5d.2xlarge / コア m5d.2xlarge x 8台) ? 入力データ: 15 GB (100 Parquet ファイル) 2018.11: EMRFS S3-optimized committer EMRFS consistent view 無効 EMRFS consistent view 有効 INSERT OVERWRITE DIRECTORY ‘s3://${bucket}/perf-test/${trial_id}’ USING PARQUET SELECT * FROM range(0, ${rows}, 1, ${partitions});
- 49. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Provisioned ? Read/Write I/O に対してそれぞれ事前にキャパシティを設定 Ondemand ? キャパシティの設定不要(ワークロードに応じてパフォーマンスを自動調整) ? EMRFS consistent view, S3 Guard でキャパシティの予測が難しい場合に便利 https://aws.amazon.com/jp/blogs/news/amazon-dynamodb-on-demand-no-capacity-planning-and-pay-per-request-pricing/ 2018.11: DynamoDB Ondemand
- 50. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. S3 関連の Hadoop/Spark コミュニティの直近の開発状況
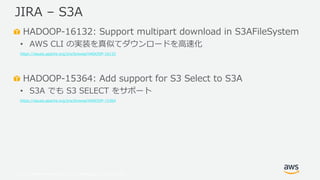
- 51. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HADOOP-16132: Support multipart download in S3AFileSystem ? AWS CLI の実装を真似てダウンロードを高速化 https://issues.apache.org/jira/browse/HADOOP-16132 HADOOP-15364: Add support for S3 Select to S3A ? S3A でも S3 SELECT をサポート https://issues.apache.org/jira/browse/HADOOP-15364 JIRA – S3A
- 52. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HADOOP-15999: S3Guard: Better support for out-of-band operations ? S3Guard 以外から書き換えられたファイルのハンドリングを改善 https://issues.apache.org/jira/browse/HADOOP-15999 HADOOP-15837: DynamoDB table Update can fail S3A FS init ? DynamoDB AutoScaling 有効時の S3Guard の初期化処理を改善 https://issues.apache.org/jira/browse/HADOOP-15837 HADOOP-15619: ?ber-JIRA: S3Guard Phase IV: Hadoop 3.3 features ? Hadoop 3.3 の S3Guard 関連の親 JIRA (Hadoop 3.0, 3.1, 3.2 それぞれ別JIRA) https://issues.apache.org/jira/browse/HADOOP-15619 HADOOP-15426: Make S3guard client resilient to DDB throttle events and network failures ? DynamoDB でスロットリングが発生したときの S3Guard CLI の動作を改善 https://issues.apache.org/jira/browse/HADOOP-15426 HADOOP-15349: S3Guard DDB retryBackoff to be more informative on limits exceeded ? DynamoDB でスロットリングが発生したときの S3Guard の動作を改善 JIRA – S3Guard
- 53. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. HADOOP-15281: Distcp to add no-rename copy option ? DistCp で (主に S3 等のために) RENAME なしで動作するオプションを追加 https://issues.apache.org/jira/browse/HADOOP-15281 HIVE-20517: Creation of staging directory and Move operation is taking time in S3 ? Hive で S3 に出力する際に、Staging ディレクトリにコピーしてから 最終的 な出力先にコピー (RENAME) する従来の処理を、直接出力するように変更 https://issues.apache.org/jira/browse/HIVE-20517 JIRA – Others
- 54. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 問題 ? Spark でデータ出力する際は、一時ファイルに書き出してから Rename する ? S3 上のテーブルに対しても S3 に一時ファイルを出力するため、遅い ? HIVE-14270 の関連 Issue 方針 ? 一時ファイルは HDFS に、結果ファイルは S3 に出力するように分ける ? パフォーマンスの向上、S3 コストの削減が可能な見込み 現在のステータス ? 手元の実装で計測したパフォーマンスは約 2倍 https://issues.apache.org/jira/browse/SPARK-21514 SPARK-21514:Hive has updated with new support for S3 and InsertIntoHiveTable.scala should update also
- 55. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. おわりに
- 56. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Hadoop/Spark と S3 の関係 HDFS と S3 の違いと使い分け Hadoop/Spark から見た S3 の動作 よくあるハマりどころとチューニング Hadoop/Spark に関係する S3/AWS サービスアップデート S3 関連の Hadoop/Spark コミュニティの直近の開発状況 おわりに
- 57. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Appendix
- 58. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. 一時的なクラスタ ? バッチジョブ ? 単発のデータ変換 ? 機械学習 ? 他の DWH やデータレイクへの ETL 永続的なクラスタ ? アドホックジョブ ? ストリーミング処理 ? 継続的なデータ変換 ? ノートブック ? 実験 Hadoop/Spark on AWS の主なユースケース
- 59. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. リソース?デーモンログ系 ? Name Node ログ ? Data Node ログ ? HDFS ブロックレポート リクエストログ系 ? HDFS 監査ログ メトリクス系 ? Hadoop Metrics v2 HDFS でトラブルシューティングに役立つ情報
- 60. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. リクエストログ系 ? S3 アクセスログ ? S3 バケットにてあらかじめ設定すると、S3 にアクセスログが出力される ? CloudTrail ? 管理イベント:コントロールプレーンの操作を記録 ? データイベント:データプレーンの操作を記録(事前に有効化が必要) メトリクス系 ? CloudWatch S3 メトリクス ? ストレージメトリクス – バケットサイズとオブジェクト数の2種類 – 1日1回更新 ? リクエストメトリクス(事前に有効化が必要) – 各種リクエスト数(GET, PUT, HEAD, …)や 4XX/5XXエラー数などの16種類 – 1分間隔で更新 S3 でトラブルシューティングに役立つ情報
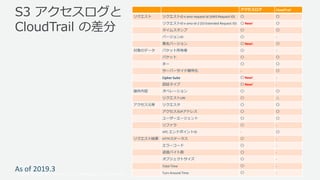
- 61. ? 2019, Amazon Web Services, Inc. or its Affiliates. All rights reserved. S3 アクセスログと CloudTrail の差分 アクセスログ CloudTrail リクエスト リクエストID x-amz-request-id (AWS Request ID) 〇 〇 リクエストID x-amz-id-2 (S3 Extended Request ID) 〇 New! 〇 タイムスタンプ 〇 〇 バージョンID 〇 - 署名バージョン 〇 New! 〇 対象のデータ バケット所有者 〇 - バケット 〇 〇 キー 〇 〇 サーバーサイド暗号化 - 〇 Cipher Suite 〇 New! - 認証タイプ 〇 New! - 操作内容 オペレーション 〇 〇 リクエストURI 〇 △ アクセス元等 リクエスタ 〇 〇 アクセス元IPアドレス 〇 〇 ユーザーエージェント 〇 〇 リファラ 〇 - VPC エンドポイントID - 〇 リクエスト結果 HTTPステータス 〇 - エラーコード 〇 - 送信バイト数 〇 - オブジェクトサイズ 〇 - Total Time 〇 - Turn Around Time 〇 - As of 2019.3