






























![Word Count
Tool s─▒n─▒f─▒ metodlar─▒
public int run(String[] args) throws Exception
{
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>n", getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new Job();
job.setJarByClass(WordCount.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new WordCount(), args);
System.exit(exitCode);
}](https://image.slidesharecdn.com/hadoop-devveri-com-121227143645-phpapp01/85/Hadoop-devveri-com-36-320.jpg)












![Ûrnek kurulum adım 10
ŌŚÅ NameNode formatlanmal─▒d─▒r
$ hadoop namenode -format
12/09/05 00:07:06 INFO namenode.NameNode: STARTUP_MSG:
/
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = devveri-HP-ProBook-6540b/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.0.3
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1335192; compiled by
'hortonfo' on Tue May 8 20:31:25 UTC 2012
/
12/09/05 00:07:06 INFO util.GSet: VM type = 32-bit
12/09/05 00:07:06 INFO util.GSet: 2% max memory = 9.1025 MB
12/09/05 00:07:06 INFO util.GSet: capacity = 2^21 = 2097152 entries
12/09/05 00:07:06 INFO util.GSet: recommended=2097152, actual=2097152
12/09/05 00:07:07 INFO namenode.FSNamesystem: fsOwner=devveri
12/09/05 00:07:07 INFO namenode.FSNamesystem: supergroup=supergroup
12/09/05 00:07:07 INFO namenode.FSNamesystem: isPermissionEnabled=true
12/09/05 00:07:07 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
12/09/05 00:07:07 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s),
accessTokenLifetime=0 min(s)
12/09/05 00:07:07 INFO namenode.NameNode: Caching file names occuring more than 10 times
12/09/05 00:07:07 INFO common.Storage: Image file of size 111 saved in 0 seconds.
12/09/05 00:07:07 INFO common.Storage: Storage directory /usr/java/hadoop-data/dfs/name has been successfully formatted.
12/09/05 00:07:07 INFO namenode.NameNode: SHUTDOWN_MSG:
/
SHUTDOWN_MSG: Shutting down NameNode at devveri-HP-ProBook-6540b/127.0.1.1
/](https://image.slidesharecdn.com/hadoop-devveri-com-121227143645-phpapp01/85/Hadoop-devveri-com-49-320.jpg)


















Hadoop @ devveri.com
- 1. Hadoop devveri.com Aral─▒k 2012 v1.3
- 2. Hakk─▒mda ŌŚÅ Marmara ├£ni. Elektronik ŌŚÅ Software Development Supervisor @ Gitti Gidiyor / eBay ŌŚÅ 12+ y─▒l yaz─▒l─▒m tecr├╝besi ŌŚÅ Java, C, C++, C# ŌŚÅ Big Data, Search, NoSQL Hakan ─░lter hilter@ebay.com twitter: devvericom http://tr.linkedin.com/in/hakanilter/
- 3. G├╝ndem ŌŚÅ Big Data (Dev veri) ŌŚÅ Hadoop ŌŚÅ HDFS ŌŚÅ MapReduce ŌŚÅ Hadoop Kurulum ŌŚÅ K├╝me Yap─▒s─▒ ŌŚÅ Hadoop Ekosistemi
- 4. Dev Veri
- 5. Dev Veri
- 6. Dev Veri Nedir Teknoloji > Internet > Sosyal Medya > Mobil > ... D├╝nya'daki verilerin %90'l─▒k k─▒sm─▒ son iki y─▒lda topland─▒ Yap─▒land─▒r─▒lm─▒┼¤ (structured) ve Yap─▒land─▒r─▒lmam─▒┼¤ (unstructured) verilerden meydana gelir ŌŚÅ Yap─▒land─▒r─▒lm─▒┼¤ veriler: ├╝r├╝n, kategori, m├╝┼¤teri, fatura, ├Čdeme... ŌŚÅ Yap─▒land─▒r─▒lmam─▒┼¤ veriler: tweet, payla┼¤─▒m, be─¤eni (like), e-posta, video, t─▒klama... %10 Yap─▒land─▒r─▒lm─▒┼¤, %90 Yap─▒land─▒r─▒lmam─▒┼¤
- 7. Dev Verinin 3 Boyutu B├╝y├╝kl├╝k (Volume) ŌŚÅ Facebook 70+PB, eBay 5+PB H─▒z (Velocity) ŌŚÅ Twitter'da herg├╝n 12TB twit at─▒l─▒yor ├će┼¤itlilik (Variety) ŌŚÅ Metin, sens├Čr verileri, ses, g├Čr├╝nt├╝, log dosyalar─▒
- 8. Dev Veri
- 9. Dev Veri'nin ├¢nemi ŌŚÅ Bu kadar veri tek ba┼¤─▒na bir anlam ifade etmiyor ŌŚÅ ├¢nemli olan Dev Veri i├¦erisinde saklanm─▒┼¤ olan bilgiyi ortaya ├¦─▒kart─▒p yapt─▒─¤─▒m─▒z i┼¤i daha iyi anlamak, belki de gelece─¤i tahmin etmeye ├¦al─▒┼¤mak ŌŚÅ Bu ger├¦ekle┼¤tirildi─¤inde; ŌŚŗ Mutlu m├╝┼¤teriler ŌŚŗ Daha fazla kazan├¦ ŌŚŗ Doland─▒r─▒c─▒l─▒kta azalma ŌŚŗ Daha sa─¤l─▒kl─▒ insanlar ŌŚŗ ...
- 10. Geleneksel Sistemlerin Problemleri ŌŚÅ RDBMS G├Čreceli olarak k├╝├¦├╝k boyutta veri, yap─▒land─▒r─▒lmam─▒┼¤ verilere uygun de─¤il ŌŚÅ Donan─▒m limitleri Daha fazla CPU, daha fazla RAM, daha fazla Disk = Daha fazla Maliyet ŌŚÅ Yaz─▒l─▒msal karma┼¤─▒kl─▒k Senkronizasyon, bant geni┼¤li─¤i, eri┼¤ilebilirlik, hata tolerans─▒
- 11. Peki ya ger├¦ek problem? Ger├¦ek problem: Veriyi i┼¤lemciye ula┼¤t─▒rabilmek! 100GB boyutundaki bir veriyi tipik bir disk ile (~75 MB/sn) aktarmak yakla┼¤─▒k 22 dakika!
- 12. Yeni bir yakla┼¤─▒m ŌŚÅ ├¢l├¦eklenebilir ŌŚÅ Tutarl─▒ ŌŚÅ Veri Garantili ŌŚÅ Eri┼¤ilebilir
- 13. Kim ├¦├Čzd├╝? ŌŚÅ Google File System (2003) ŌŚÅ MapReduce (2004) ŌŚÅ Big Table (2006)
- 14. ve Hadoop! Veri i┼¤leme ama├¦l─▒ da─¤─▒t─▒k uygulamalar yaz─▒lmas─▒n─▒ sa─¤layan bir platform ve a├¦─▒k kaynakl─▒ bir Apache projesidir.
- 15. G├╝ndem ŌŚÅ Big Data (Dev veri) ŌŚÅ Hadoop ŌŚÅ HDFS ŌŚÅ MapReduce ŌŚÅ Hadoop Kurulum ŌŚÅ K├╝me Yap─▒s─▒ ŌŚÅ Hadoop Ekosistemi
- 16. Neden Hadoop ŌŚÅ Esnek Her t├╝rl├╝ veriyi saklay─▒p analizini yapabilir ŌŚÅ ├¢l├¦eklenebilir Binlerce d├╝─¤├╝m bir araya getirilebilir ŌŚÅ Ekonomik A├¦─▒k kaynakl─▒, "commodity" donan─▒mda ├¦al─▒┼¤abilir
- 17. Nerede?
- 18. Nerede?
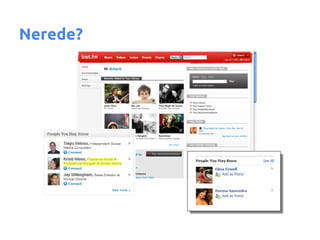
- 19. Gitti Gidiyor'da Hadoop ─░lgili di─¤er aramalar Nokkia arat─▒lm─▒┼¤ ama Nokia olarak d├╝zeltilmi┼¤ Nokia kelimesiyle daha ilgili oldu─¤u i├¦in Cep telefonu kategorisi daha ├╝stte yer al─▒yor
- 20. Gitti Gidiyor'da Hadoop "Metallica" ile ilgili di─¤er aramalar Mobil uygulama ana sayfada ki┼¤iselle┼¤tirilmi┼¤ ├╝r├╝n g├Čsterimi Autocomplete verisi
- 22. Hadoop ─░ki ana bile┼¤enden olu┼¤ur ŌŚÅ Hadoop Distributed File System (HDFS) ŌŚÅ MapReduce
- 23. G├╝ndem ŌŚÅ Big Data (Dev veri) ŌŚÅ Hadoop ŌŚÅ HDFS ŌŚÅ MapReduce ŌŚÅ Hadoop Kurulum ŌŚÅ K├╝me Yap─▒s─▒ ŌŚÅ Hadoop Ekosistemi
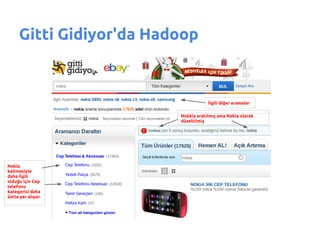
- 24. HDFS Verinin saklanmas─▒ndan sorumludur ŌŚÅ Da─¤─▒t─▒k bir dosya sistemidir ŌŚÅ Veriyi 64MB ya da 128MB'l─▒k bloklar halinde saklar ŌŚÅ Her blok k├╝me i├¦erisinde farkl─▒ d├╝─¤├╝mlere da─¤─▒t─▒l─▒r ŌŚÅ Her blo─¤un varsay─▒lan 3 kopyas─▒ tutulur ŌŚÅ Bu sayede verinin eri┼¤ilebilirli─¤i ve g├╝venilirli─¤i sa─¤lanm─▒┼¤ olur ŌŚÅ Ayn─▒ dosyaya ait bloklar farkl─▒ d├╝─¤├╝mlerde olabilir
- 25. HDFS ŌŚÅ Normal dosya sistemi ├╝zerinde ├¦al─▒┼¤─▒r: ext3, ext4, xfs ŌŚÅ B├╝y├╝k miktarda veri i├¦in yedekli depolama sa─¤lar ŌŚÅ D├╝┼¤├╝k maliyetli sunucular ├╝zerinde ├¦al─▒┼¤maya uygundur ŌŚÅ K├╝├¦├╝k ├¦ok dosya yerine b├╝y├╝k daha az dosya tutulmal─▒d─▒r ŌŚÅ Ortalama bir dosya 100MB civar─▒ olmal─▒d─▒r ŌŚÅ Rastlant─▒sal eri┼¤im yoktur (write once) ŌŚÅ B├╝y├╝k ve duraks─▒z (streaming) veri eri┼¤imine g├Čre optimize edilmi┼¤tir
- 26. HDFS Bloklar─▒n d├╝─¤├╝mler ├╝zerine da─¤─▒l─▒m ├Č░∙▓į▒─¤Š▒ blok 1 blok 2 blok 3 blok 4 blok 3 blok 2 Data Node 1 Data Node 2 blok 3 blok 4 blok 4 blok 1 blok 1 blok 2 Data Node 3 Data Node 4
- 27. HDFS Eri┼¤imi HDFS ├╝zerindeki verilere konsol ├╝zerinden hadoop fs komutu ile eri┼¤ilebilir: hadoop fs -ls Dosyalar─▒ listeler hadoop fs -mkdir <path> Klas├Čr olu┼¤turur hadoop fs -put <local> <target> Lokalden HDFS'e dosya kopyalar hadoop fs -get <source> <local> HDFS'den lokale dosya kopyalar hadoop fs -cat <filename> Dosya i├¦eri─¤ini konsola basar hadoop fs -rmr <filename> Dosyay─▒ siler
- 28. G├╝ndem ŌŚÅ Big Data (Dev veri) ŌŚÅ Hadoop ŌŚÅ HDFS ŌŚÅ MapReduce ŌŚÅ Hadoop Kurulum ŌŚÅ K├╝me Yap─▒s─▒ ŌŚÅ Hadoop Ekosistemi
- 29. MapReduce Veriyi i┼¤leme y├Čntemidir ŌŚÅ Fonksiyonel programlamadan esinlenilmi┼¤tir ŌŚÅ Map ve Reduce birer fonksiyondur ŌŚÅ Map fonksiyonu ile veri i├¦erisinden istenilen veriler anahtar-de─¤er format─▒nda se├¦ilir ŌŚÅ Reduce fonksiyonu ile de se├¦ilen bu veriler ├╝zerinde i┼¤lem yap─▒l─▒r, sonu├¦ yine anahtar-de─¤er olarak iletilir ŌŚÅ Map ve Reduce aras─▒nda Shuffle ve Sort a┼¤amalar─▒ vard─▒r
- 30. MapReduce Daha kolay anla┼¤─▒labilir olmas─▒ i├¦in SQL'e benzetmek gerekirse; ŌŚÅ WHERE ile yap─▒lan filtreleme gibi Map a┼¤amas─▒nda sadece ihtiyac─▒m─▒z olan veriler se├¦ilir ŌŚÅ Reduce a┼¤amas─▒nda ise SUM, COUNT, AVG gibi birle┼¤tirme i┼¤lemleri yap─▒l─▒r
- 31. MapReduce ŌŚÅ Map a┼¤amas─▒ndaki i┼¤lemler k├╝me ├╝zerinde paralel olarak ├¦al─▒┼¤─▒r ŌŚÅ Bu sayede k├╝menin b├╝y├╝kl├╝─¤├╝ne g├Čre veriler h─▒zl─▒ bir ┼¤ekilde i┼¤lenebilir hale gelmi┼¤ olur ŌŚÅ Her i┼¤ par├¦ac─▒─¤─▒ verinin belirli bir par├¦as─▒n─▒ i┼¤ler ŌŚÅ ─░┼¤ par├¦ac─▒klar─▒ m├╝mk├╝nse ├╝zerinde ├¦al─▒┼¤t─▒─¤─▒ d├╝─¤├╝mdeki verileri i┼¤ler. Buna Data Localization denir
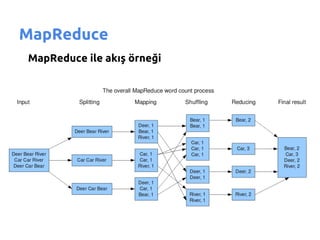
- 32. MapReduce MapReduce ile ak─▒┼¤ ├Č░∙▓į▒─¤Š▒
- 33. MapReduce ŌŚÅ Uygulama geli┼¤tirilirken sadece Map ve Reduce metodlar─▒ yaz─▒l─▒r, geri kalan i┼¤leyi┼¤ otomatik ger├¦ekle┼¤ir ŌŚÅ Hadoop tamamen Java ile geli┼¤tirildi─¤i i├¦in MapReduce uygulamalar─▒ Java ile yaz─▒l─▒r, jar olarak paketlenir ŌŚÅ Streaming ├Čzelli─¤i sayesinde Python, C++, Php gibi farkl─▒ dillerde de kullan─▒labilir
- 34. Word Count Map Metodu public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString().toLowerCase(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { Text word = new Text(tokenizer.nextToken()); context.write(word, new IntWritable(1)); } }
- 35. Word Count Reduce Metodu public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } context.write(key, new IntWritable(sum)); }
- 36. Word Count Tool s─▒n─▒f─▒ metodlar─▒ public int run(String[] args) throws Exception { if (args.length != 2) { System.err.printf("Usage: %s [generic options] <input> <output>n", getClass().getSimpleName()); ToolRunner.printGenericCommandUsage(System.err); return -1; } Job job = new Job(); job.setJarByClass(WordCount.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new WordCount(), args); System.exit(exitCode); }
- 37. Word Count MapReduce program─▒n─▒ ├¦al─▒┼¤t─▒rma $ hadoop jar <jarfile> <classname> <args...> $ hadoop jar devveri-mapreduce-0.0.1-SNAPSHOT.jar com.devveri.hadoop.mapreduce.WordCount test.txt devveri 12/07/09 23:44:41 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 12/07/09 23:44:41 INFO input.FileInputFormat: Total input paths to process : 1 12/07/09 23:44:41 INFO mapred.JobClient: Running job: job_201204231254_5522 12/07/09 23:44:42 INFO mapred.JobClient: map 0% reduce 0% 12/07/09 23:44:56 INFO mapred.JobClient: map 100% reduce 0% 12/07/09 23:45:08 INFO mapred.JobClient: map 100% reduce 100% 12/07/09 23:45:13 INFO mapred.JobClient: Job complete: job_201204231254_5522 12/07/09 23:45:13 INFO mapred.JobClient: Counters: 29 12/07/09 23:45:13 INFO mapred.JobClient: Job Counters 12/07/09 23:45:13 INFO mapred.JobClient: Launched reduce tasks=1 12/07/09 23:45:13 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=11984 12/07/09 23:45:13 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 12/07/09 23:45:13 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 12/07/09 23:45:13 INFO mapred.JobClient: Launched map tasks=1 12/07/09 23:45:13 INFO mapred.JobClient: Data-local map tasks=1 12/07/09 23:45:13 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=10033 12/07/09 23:45:13 INFO mapred.JobClient: File Output Format Counters 12/07/09 23:45:13 INFO mapred.JobClient: Bytes Written=31 12/07/09 23:45:13 INFO mapred.JobClient: FileSystemCounters 12/07/09 23:45:13 INFO mapred.JobClient: FILE_BYTES_READ=61 ...
- 38. G├╝ndem ŌŚÅ Big Data (Dev veri) ŌŚÅ Hadoop ŌŚÅ HDFS ŌŚÅ MapReduce ŌŚÅ Hadoop Kurulum ŌŚÅ K├╝me Yap─▒s─▒ ŌŚÅ Hadoop Ekosistemi
- 39. Hadoop Kurulumu ŌŚÅ Apache s├╝r├╝m├╝ d─▒┼¤─▒nda Cloudera, Hortonworks gibi firmalar─▒n da─¤─▒t─▒mlar─▒ da kullan─▒labilir ŌŚÅ Farkl─▒ s├╝r├╝mleri bulunuyor 1.0.X - current stable version, 1.0 release 1.1.X - current beta version, 1.1 release 2.X.X - current alpha version 0.23.X - simmilar to 2.X.X but missing NN HA. 0.22.X - does not include security 0.20.203.X - old legacy stable version 0.20.X - old legacy version ŌŚÅ K├╝me olarak (full cluster) ya da tek sunucuya (pseudo- distributed) kurulabilir ŌŚÅ deb, rpm veya tarball olarak indirilip kurulabilir
- 40. ├¢rnek kurulum ad─▒m 1 ŌŚÅ JDK 1.6, openssh-server ve rsync sistemde olmal─▒ $ sudo apt-get install ssh $ sudo apt-get install rsync
- 41. ├¢rnek kurulum ad─▒m 2 ŌŚÅ Sunucular aras─▒ ┼¤ifresiz ba─¤lant─▒ gerekir $ ssh localhost The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is 00:ab:cd:ef:12:23:56:ab:ba:c4:89: 11:d8:22:33:1b. Are you sure you want to continue connecting (yes/no)? yes ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
- 42. ├¢rnek kurulum ad─▒m 3 ŌŚÅ Kurulumun yap─▒laca─¤─▒ klas├Črler ayarlan─▒r $ sudo mkdir /usr/java $ sudo chown -R devveri:devveri /usr/java $ mkdir /usr/java/hadoop-data
- 43. ├¢rnek kurulum ad─▒m 4 ŌŚÅ Apache sunucusundan son s├╝r├╝m indirilir $ cd /usr/java/ $ wget "http://www.eu.apache.org/dist/hadoop/ common/hadoop-1.0.4/hadoop-1.0.4.tar.gz" $ gzip -dc hadoop-1.0.4.tar.gz | tar xf - $ ln -s /usr/java/hadoop-1.0.4 /usr/java/hadoop
- 44. ├¢rnek kurulum ad─▒m 5 ŌŚÅ K├╝me ile ilgili genel ayarlar conf/core-site.xml dosyas─▒nda bulunur <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/java/hadoop-data</value> </property> </configuration>
- 45. ├¢rnek kurulum ad─▒m 6 ŌŚÅ HDFS ile ilgili ayarlar conf/hdfs-site.xml dosyas─▒ i├¦erisinde bulunur <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
- 46. ├¢rnek kurulum ad─▒m 7 ŌŚÅ MapReduce ile ilgili ayarlar conf/mapred-site.xml dosyas─▒ i├¦erisinde bulunur <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
- 47. ├¢rnek kurulum ad─▒m 8 ŌŚÅ Hadoop ile ilgili ortam de─¤i┼¤kenleri conf/hadoop-env. sh dosyas─▒nda bulunur export JAVA_HOME=/usr/java/jdk export HADOOP_HEAPSIZE=512 export HADOOP_HOME_WARN_SUPPRESS="TRUE"
- 48. ├¢rnek kurulum ad─▒m 9 ŌŚÅ .bash_profile ya da .bash_rc dosyalar─▒nda $PATH de─¤i┼¤keni ayarlanmal─▒d─▒r JAVA_HOME=/usr/java/jdk PATH=$PATH:$JAVA_HOME/bin HADOOP_HOME=/usr/java/hadoop PATH=$PATH:$HADOOP_HOME/bin
- 49. ├¢rnek kurulum ad─▒m 10 ŌŚÅ NameNode formatlanmal─▒d─▒r $ hadoop namenode -format 12/09/05 00:07:06 INFO namenode.NameNode: STARTUP_MSG: / STARTUP_MSG: Starting NameNode STARTUP_MSG: host = devveri-HP-ProBook-6540b/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.0.3 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1335192; compiled by 'hortonfo' on Tue May 8 20:31:25 UTC 2012 / 12/09/05 00:07:06 INFO util.GSet: VM type = 32-bit 12/09/05 00:07:06 INFO util.GSet: 2% max memory = 9.1025 MB 12/09/05 00:07:06 INFO util.GSet: capacity = 2^21 = 2097152 entries 12/09/05 00:07:06 INFO util.GSet: recommended=2097152, actual=2097152 12/09/05 00:07:07 INFO namenode.FSNamesystem: fsOwner=devveri 12/09/05 00:07:07 INFO namenode.FSNamesystem: supergroup=supergroup 12/09/05 00:07:07 INFO namenode.FSNamesystem: isPermissionEnabled=true 12/09/05 00:07:07 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100 12/09/05 00:07:07 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s) 12/09/05 00:07:07 INFO namenode.NameNode: Caching file names occuring more than 10 times 12/09/05 00:07:07 INFO common.Storage: Image file of size 111 saved in 0 seconds. 12/09/05 00:07:07 INFO common.Storage: Storage directory /usr/java/hadoop-data/dfs/name has been successfully formatted. 12/09/05 00:07:07 INFO namenode.NameNode: SHUTDOWN_MSG: / SHUTDOWN_MSG: Shutting down NameNode at devveri-HP-ProBook-6540b/127.0.1.1 /
- 50. G├╝ndem ŌŚÅ Big Data (Dev veri) ŌŚÅ Hadoop ŌŚÅ HDFS ŌŚÅ MapReduce ŌŚÅ Hadoop Kurulum ŌŚÅ K├╝me Yap─▒s─▒ ŌŚÅ Hadoop Ekosistemi
- 51. K├╝me Yap─▒s─▒ ŌŚÅ Hadoop k├╝mesini durdurup ba┼¤latmak i├¦in bin klas├Čr├╝ alt─▒ndaki script'ler kullan─▒l─▒r start-all.sh K├╝meyi ├¦al─▒┼¤t─▒r─▒r stop-all.sh K├╝meyi durdurur start-dfs.sh Sadece HDFS s├╝re├¦lerini ├¦al─▒┼¤t─▒r─▒r stop-dfs.sh HDFS s├╝re├¦lerini durdurur start-mapred.sh Sadece MapReduce s├╝re├¦lerini ├¦al─▒┼¤t─▒r─▒r stop-mapred.sh MapReduce s├╝re├¦lerini durdurur
- 52. Hadoop S├╝re├¦leri Hadoop k├╝mesi i├¦erisinde birlikte ├¦al─▒┼¤an birka├¦ farkl─▒ s├╝re├¦ vard─▒r ŌŚÅ NameNode ŌŚÅ SecondaryNameNode ŌŚÅ DataNode ŌŚÅ JobTracker ŌŚÅ TaskTracker
- 53. NameNode Ana (master) d├╝─¤├╝md├╝r ŌŚÅ Hangi blok, hangi dosya nerededir takip eder ŌŚÅ Her t├╝rl├╝ dosya i┼¤leminden sorumludur ŌŚÅ Veri de─¤il sadece metadata saklar ŌŚÅ Her zaman ayakta olmak zorundad─▒r NameNode ├¦al─▒┼¤maz ise t├╝m k├╝me ├¦al─▒┼¤maz hale gelir ŌŚÅ H─▒zl─▒ eri┼¤im a├¦─▒s─▒ndan verileri haf─▒zada tutar ŌŚÅ ├ć├Čkmeye kar┼¤─▒ diske bilgileri senkronize eder ŌŚÅ Bu verileri mutlaka yedeklenmelidir
- 54. SecondaryNameNode NameNode yede─¤i de─¤ildir! ŌŚÅ Sadece NameNode taraf─▒ndan yap─▒lmayan baz─▒ g├Črevleri yerine getirir
- 55. DataNode Verilerin bulundu─¤u d├╝─¤├╝md├╝r ŌŚÅ Blok halinde dosyalar─▒ saklar ŌŚÅ Yedekli oldu─¤u i├¦in kapanmas─▒ halinde veri kayb─▒ ya┼¤anmaz ŌŚÅ Veriler bu d├╝─¤├╝mlerde oldu─¤u i├¦in analiz i┼¤lemleri de bu d├╝─¤├╝mler ├╝zerinde ├¦al─▒┼¤─▒r ŌŚÅ K├╝me i├¦erisinde birden fazla olabilir (olmal─▒d─▒r) ŌŚÅ 4000+ d├╝─¤├╝me kadar b├╝y├╝yebilir ŌŚÅ Say─▒s─▒ artt─▒k├¦a performans─▒ lineer olarak artar!
- 56. JobTracker MapReduce i┼¤lerini takip eder ŌŚÅ NameNode gibi tektir ŌŚÅ ─░stemciler MapReduce i┼¤lerini JobTracker'a g├Čnderir ŌŚÅ ─░┼¤leri di─¤er d├╝─¤├╝mlere da─¤─▒t─▒r ŌŚÅ ─░┼¤ par├¦ac─▒klar─▒n─▒n durumunu takip eder ŌŚÅ Bir i┼¤ par├¦ac─▒─¤─▒nda sorun olursa bunu sonland─▒rarak yeni bir tekrar ├¦al─▒┼¤t─▒r─▒r ŌŚÅ Baz─▒ durumlarda ayn─▒ i┼¤i yapan birden fazla i┼¤ par├¦ac─▒─¤─▒ ├¦al─▒┼¤t─▒rabilir
- 57. TaskTracker MapReduce i┼¤lemlerini ├¦al─▒┼¤t─▒r─▒r ŌŚÅ DataNode ile ayn─▒ d├╝─¤├╝mde bulunur ŌŚÅ JobTracker taraf─▒ndan g├Čnderilen i┼¤ par├¦ac─▒klar─▒ndan sorumludur ŌŚÅ Map ve Reduce g├Črevlerini ├¦al─▒┼¤t─▒r─▒p sonu├¦lar─▒n─▒ JobTracker'a iletir
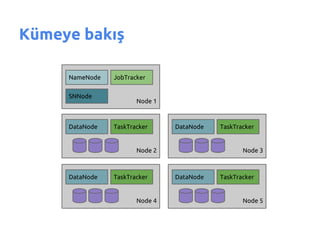
- 58. K├╝meye bak─▒┼¤ NameNode JobTracker SNNode Node 1 DataNode TaskTracker DataNode TaskTracker Node 2 Node 3 DataNode TaskTracker DataNode TaskTracker Node 4 Node 5
- 61. G├╝ndem ŌŚÅ Big Data (Dev veri) ŌŚÅ Hadoop ŌŚÅ HDFS ŌŚÅ MapReduce ŌŚÅ Hadoop Kurulum ŌŚÅ K├╝me Yap─▒s─▒ ŌŚÅ Hadoop Ekosistemi
- 62. Hadoop Ecosystem Hadoop ├¦at─▒s─▒ alt─▒nda bir├¦ok proje bar─▒n─▒r ŌŚÅ Hive ŌŚÅ Pig ŌŚÅ HBase ŌŚÅ Mahout ŌŚÅ Impala ŌŚÅ Di─¤erleri: Sqoop, Flume, Avro, Zookeeper, Oozie, Cascading...
- 63. Hive ŌŚÅ Facebook taraf─▒ndan geli┼¤tirilmi┼¤tir ŌŚÅ SQL benzeri HiveQL dili ile Java kullanmadan MapReduce uygulamalar─▒ yaz─▒lmas─▒n─▒ sa─¤lar ŌŚÅ ├¢ncelikle HDFS ├╝zerindeki dosyalar tablo olarak tan─▒t─▒l─▒r ŌŚŗ create table member_visits (member_id string, visit_count int) row format delimited fields terminated by 't' stored as textfile; ŌŚŗ load data inpath '/usr/hadoop/anyfile' into table members; ŌŚÅ Daha sonra bu sanal tablolar sorgulanabilir ŌŚŗ select avg(visit_count) from member_visits where visit_count > 0;
- 64. Pig ŌŚÅ Yahoo taraf─▒ndan geli┼¤tirilmi┼¤tir ŌŚÅ MapReduce yazmak i├¦in "DataFlow" dili olarak adland─▒r─▒lan, SQL'den farkl─▒ kendine ├Čzg├╝ PigLatin dili kullan─▒l─▒r ŌŚÅ Join destekler, daha kolay ve performansl─▒ MapReduce programalar─▒ yazmay─▒ sa─¤lar ŌŚŗ A = LOAD 'companies.csv' USING PigStorage() AS (productId:int, productName:chararray); B = FILTER A BY productId > 3; C = FOREACH B GENERATE *; DUMP C;
- 65. HBase ŌŚÅ Hadoop ├╝zerinde ├¦al─▒┼¤an NoSQL veritaban─▒d─▒r ŌŚÅ Google Big Table ├Črnek al─▒narak geli┼¤tirilmi┼¤tir ŌŚÅ Esnek ┼¤ema yap─▒s─▒ ile binlerce kolon, petabyte'larca sat─▒rdan olu┼¤an veriyi saklayabilir ŌŚÅ HDFS ├╝zerinde ├¦al─▒┼¤t─▒─¤─▒ndan MapReduce destekler ŌŚÅ Veriye eri┼¤iminde baz─▒ k─▒s─▒tlar vard─▒r ŌŚÅ Verilere anahtar ├╝zerinden ya da partial table scan ile eri┼¤ilebilir ŌŚÅ ─░kincil indeks, karma┼¤─▒k sorgu ├¦al─▒┼¤t─▒rma deste─¤i yoktur
- 66. Mahout ŌŚÅ Hadoop ├╝zerinde ├¦al─▒┼¤abilen Machine Learning algoritmalar─▒n─▒ i├¦eren bir k├╝t├╝phanedir ŌŚÅ Recommendation ŌŚÅ Clustering ŌŚÅ Classification
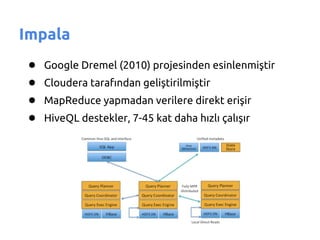
- 67. Impala ŌŚÅ Google Dremel (2010) projesinden esinlenmi┼¤tir ŌŚÅ Cloudera taraf─▒ndan geli┼¤tirilmi┼¤tir ŌŚÅ MapReduce yapmadan verilere direkt eri┼¤ir ŌŚÅ HiveQL destekler, 7-45 kat daha h─▒zl─▒ ├¦al─▒┼¤─▒r
- 68. Sorular ?
- 69. DevVeri.com Hakk─▒nda Big Data, Search, NoSQL her t├╝rl├╝ yaz─▒lar─▒n─▒z─▒ bekliyoruz!