TUB-IRML at the MediaEval 2014 Violent Scenes Detection Task
Download as pptx, pdf0 likes77,395 views

The document describes a method for detecting violent scenes in videos using audio and visual features. It discusses representing video segments using sparse coding for audio and visual dictionaries. It also uses low-level motion and color descriptors. Violence is modeled by clustering video segments and learning different models for violence sub-concepts. Experimental results show that mid-level audio representations based on MFCC and sparse coding perform well, outperforming visual representations. Future work includes improving visual representations and further investigating feature space partitioning.








TUB-IRML at the MediaEval 2014 Violent Scenes Detection Task
- 1. TUB-IRML at MediaEval 2014 Violent Scenes Detection Task: Violence Modeling through Feature Space Partitioning Esra Acar, Sahin Albayrak Competence Center Information Retrieval & Machine Learning
- 2. Outline ?The Violence Detection Method ?Video Representation ? Violence Detection Model ?Results & Discussion ?Conclusions & Future Work 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 2
- 3. The Violence Detection Method ?The two main components of our method are: ? (1) the representation of video segments, and ? (2) the learning of a violence model. 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 3
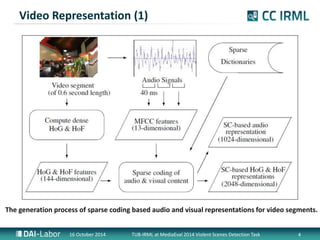
- 4. Video Representation (1) The generation process of sparse coding based audio and visual representations for video segments. 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 4
- 5. Video Representation (2) The generation of audio and visual dictionaries with sparse coding. 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 5
- 6. Video Representation (3) ? In addition to the mid-level audio and visual representations, we use low-level features which are: ?Motion-related descriptors ¨C Violent Flow (ViF) which is a descriptor proposed for real-time detection of violent crowd behaviors, and ? Static content representations ¨C Affect-related color descriptors such as statistics on saturation, brightness and hue in the HSL color space, and colorfulness. 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 6
- 7. Violence Detection Model ?Violence is a concept which can audio-visually be expressed in diverse manners. ?We learn multiple models for the violence concept instead of a unique model. ? Feature space partitioning by clustering video segments in the training dataset, and ? Learn a different model for each violence sub-concept. ?We perform a classifier selection to solve the classifier combination issue. 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 7
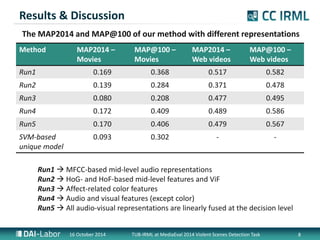
- 8. Results & Discussion The MAP2014 and MAP@100 of our method with different representations Method MAP2014 ¨C Movies MAP@100 ¨C Movies MAP2014 ¨C Web videos MAP@100 ¨C Web videos Run1 0.169 0.368 0.517 0.582 Run2 0.139 0.284 0.371 0.478 Run3 0.080 0.208 0.477 0.495 Run4 0.172 0.409 0.489 0.586 Run5 0.170 0.406 0.479 0.567 SVM-based 0.093 0.302 - - unique model Run1 ? MFCC-based mid-level audio representations Run2 ? HoG- and HoF-based mid-level features and ViF Run3 ? Affect-related color features Run4 ? Audio and visual features (except color) Run5 ? All audio-visual representations are linearly fused at the decision level 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 8
- 9. Conclusions & Future Work ?The mid-level audio representation based on MFCC and sparse coding ? provides promising performance in terms of MAP2014 and MAP@100 metrics, and ? also outperforms our visual representations. ? As a future work, we need to ? extend/improve our visual representation set, and ? further investigate the feature space partitioning concept. 16 October 2014 TUB-IRML at MediaEval 2014 Violent Scenes Detection Task 10
- 10. M.Sc. Competence Center Information Retrieval & Machine Learning www.dai-labor.de Fon Fax +49 (0) 30 / 314 ¨C 74 +49 (0) 30 / 314 ¨C 74 003 DAI-Labor Technische Universit?t Berlin Fakult?t IV ¨C Elektrontechnik & Informatik Sekretariat TEL 14 Ernst-Reuter-Platz 7 10587 Berlin, Deutschland 11 Esra Acar Researcher esra.acar@tu-berlin.de Thanks! 013 TUB-IRML at MediaEval 16 October 2014 2014 Violent Scenes Detection Task