µ–åùµƒ…˙≥…•Õ•√•»•Ô©`•Ø£®≥“¥°±∑£©
96 likes99,327 views

cvpaper.challenge §Œ Meta Study Group ∞k±Ì•π•È•§•… cvpaper.challenge §œ•≥•Û•‘•Â©`•ø•”•∏•Á•Û∑÷“∞§ŒΩÒ§Ú”≥§∑°¢•»•Ï•Û•…§ÚÑì§Í≥ˆ§πÃÙëȧ«§π°£’쌃•µ•Þ•Í?•¢•§•«•£•¢øº∞∏?◊h’ì?åg◊∞?’쌃Õ∂∏§À»°§ÍΩM§þ°¢∑≤§Ê§Î÷™◊R§Úπ≤”–§∑§Þ§π°£2019§ŒƒøòÀ°∏•»•√•◊ª·◊h30+±æÕ∂∏°π°∏2ªÿ“‘…œ§Œ•»•√•◊ª·◊hæW¡_µƒ•µ©`•Ÿ•§°π http://xpaperchallenge.org/cv/


![ª≠œÒ◊RÑe§ŒþMªØ
? DNNòã‘ϧŒ…ÓªØ
®C 2014ƒÍÌ林§È°∏òã‘ϧڧ˧ͅӧاπ§Î°π§ø§·§Œ÷™?§¨’˚§¶
®C ¨F‘⁄£®÷˜§Àª≠œÒ◊RÑe§«£©÷˜¡˜§ §Œ§œResidual Network
AlexNet [Krizhevsky+, ILSVRC2012]
VGGNet [Simonyan+, ILSVRC2014]
GoogLeNet [Szegedy+, ILSVRC2014/CVPR2015]
ResNet [He+, ILSVRC2015/CVPR2016]
ILSVRC2012 winner£¨DL§Œ?∏∂§±“€
16/19唕Օ√•»£¨deeper•‚•«•Î§Œ÷™◊R
ILSVRC2014 winner£¨22唕‚•«•Î
ILSVRC2015 winner£¨ 152唣°(ågÚY§«§œ103+唧‚)
4](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-4-320.jpg)
![À˚•ø•π•Ø§ÿ§Œþm?
? ª≠œÒ◊RÑe§«§¶§Þ§Ø§§§Ø§»•ø•π•ØÐû?§¨∆§≥§Î
®C R-CNN: ŒÔÃÂó ≥ˆ
®C FCN: •ª•Þ•Û•∆•£•√•Ø•ª•∞•·•Û•∆©`•∑•Á•Û
®C CNN+LSTM£®Seq2Seq£©: ª≠œÒ’h√˜?
®C Two-Stream CNN: Ñ”ª≠’J◊R
Person
Uma
Show and Tell [Vinyals+, CVPR15]
R-CNN [Girshick+, CVPR14]
FCN [Long+, CVPR15]
Two-Stream CNN [Simonyan+, NIPS14]
5](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-5-320.jpg)




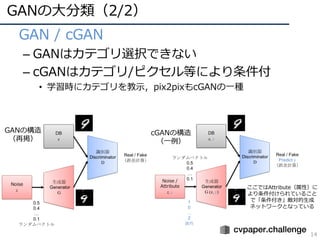
![GAN§Œ÷˜“™§ ¡˜§Ï
12
? ’ì?•Í•π•»
1. GAN£®•™•Í•∏• •Î§ŒGAN£©
? [Goodfellow, NIPS2014] https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
2. DCGAN£®Æí§þÞz§þ唧Œ π?£©
? [Radford, ICLR2016] https://arxiv.org/abs/1511.06434
3. Pix2Pix£®pixelÕ¨?§¨åùèÍ∏∂§Ø§»§§§¶“‚Œ∂§«Conditional§ GAN£©
? [Isola, CVPR2017] https://arxiv.org/abs/1611.07004
4. CycleGAN£®pix2pix§ŒΩÃéü§ §∑∞Ê£©
? [Zhu, ICCV2017] https://arxiv.org/pdf/1703.10593.pdf
5. ACGAN£®•´•∆•¥•Í◊RÑe§‚Õ¨ïr§Àåg ©§∑§∆•≥•Û•«•£•∑•Á•Û§»§∑§ø£©
? [Odera, ICML2017] https://arxiv.org/abs/1610.09585
6. WGAN/SNGAN£®—ß¡ï∞≤∂®ªØ£©
? [Arjovsky, ICML2017] http://proceedings.mlr.press/v70/arjovsky17a.html
? [Miyato, ICLR2018] https://arxiv.org/abs/1802.05957
7. PGGAN£®?æ´∂»ªØ£©
? [Karras, ICLR2018] https://arxiv.org/abs/1710.10196
8. Self-Attention GAN£®•¢•∆•Û•∑•Á•ÛôCòã§ÚíÒ?£©
? [Zhang, arXiv 1805.08318] https://arxiv.org/abs/1805.08318
9. BigGAN£®≥¨?æ´ºöGAN£©
? [Brock, ICLR2019] https://arxiv.org/abs/1809.11096
# 2018ƒÍ10?ïrµ„§«§Œ’{ñÀ](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-12-320.jpg)
![GAN£®Generative Adversarial Networks£©
[Goodfellow, NIPS2014]£®1/9£©
15
? •™•Í•∏• •Î§ŒGAN
®C Generator£®G£©£∫DB£®x£©§Œ∑÷≤º§Ú‘Ÿ¨F£¨ª≠œÒ§Ú?≥…
®C Discriminator£®D£©£∫DB§´§È??§µ§Ï§ø§‚§Œ§´G§À§Ë§Í?≥…§µ§Ï§ø
ª≠œÒ§´§Ú≈–∂œ
®C Min-Max§ÚΩ‚§Ø§≥§»§«•«©`•ø∑÷≤º§Ú‘Ÿ¨F£¨≥ˆ?ø’Èg§Ú’{’˚
GAN§Œòã‘Ï
£®‘Ÿí˜£©
D§Ú◊Ó?ªØ£®G§œD§Ú°±?§≠§Ø°±Ú_§∑§ø§§£©
G§Ú◊Ó?ªØ£®G§œDB§Œ∑÷≤º§À•’•£•√•»§µ§ª§ø§§£©
? G§œ•Œ•§•∫z§Ú??§»§∑§∆ª≠œÒ?≥…
? Pz(z)§œ?≥…§µ§Ï§ø≥ˆ?∑÷≤º
? Pdata(x)§œDB§Œ∑÷≤º](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-15-320.jpg)
![DCGAN£®Deep Convolutional GAN£©[Radford, ICLR2016] £®2/9£©
16
? GAN§Œòã‘ϧڅÓå”Æí§þÞz§þ•Õ•√•»§À÷√§≠ìQ§®
®C Conv layer§Œ π?£®òã‘ϧœœ¬áÌ£©
? Linear/Pooling layer§ÚConv layer§À÷√§≠ìQ§®
? —ß¡ï∞≤∂®ªØ§Œ§ø§·£¨Batch Norm.§‚D/G§À◊∑º”
? ªÓ–‘ªØÈv ˝§œ£¨G: ReLU, D: LeakyReLU
®C ΩÃéü§ §∑Ãÿ蒱̨F
? —ß¡ïúg§þ§ŒD§Ú π?§∑§ø§È£¨82.8%@CIFAR-10
? SVHN§À§ƒ§§§∆§‚Õ¨òî§À¡º∫√§ æ´∂»
£¥å”§ŒÆí§þÞz§þòã‘ϧÀ§Ë§Í
òã≥…§µ§Ï§∆§§§Î](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-16-320.jpg)
![DCGAN£®Deep Convolutional GAN£©[Radford, ICLR2016] £®2?/9£©
17
? GAN§Œòã‘ϧڅÓå”Æí§þÞz§þ•Õ•√•»§À÷√§≠ìQ§®
®C À„–gµƒª≠œÒ?≥…£®”“œ¬áÌ£©
? Word2Vec§Œ§Ë§¶§Àº”À„/úpÀ„§À§Ë§Îª≠œÒ?≥…§¨ø…ƒÐ
? ÓܧŒªÿÐû§‚interpolation§«±Ì¨Fø…ƒÐ
?§∑À„£¨“˝§≠À„§ §…÷±∏–µƒ§ ±Ì¨F
§«ª≠œÒ?≥…§Úåg¨F§∑§ø£ø](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-17-320.jpg)
![Pix2Pix[Isola, CVPR2017] £®3/9£©
18
? •‘•Ø•ª•ÎÕ¨?§¨åùèͧ∑§øª≠œÒâ‰ìQ
®C •‘•Ø•ª•ÎÈg§«Ãıº˛∏∂§±§Ú?§ §√§øGAN§»◊Ω§®§Î§≥§»§¨§«§≠§Î
? èæ¿¥§œÑe°©§À◊h’짵§Ï§∆§≠§øª≠œÒâ‰ìQ§Œ—ß¡ï§ÚÖg?§ŒñòΩM§þ§«åg ©
? Enc-Decòã‘ϧŒ§‚§Œ§¿§±§«§ §Ø£¨U-Net§ÚG§»§∑§∆íÒ?
? •È•Ÿ•Î§œª≠œÒ§»â‰ìQ§∑§øª≠œÒ£®œ¬á̧Œ§Ë§¶§À??£©
Ög?§ŒñòΩM§þ£®Ög?•‚•«•Î
§«§ §§£©§«—} ˝§Œ•‘•Ø•ª•Î
Õ¨?§Œœýª•ª≠œÒâ‰ìQ§ÀåùèÍ£Æ
•È•Ÿ•Î®ÆRGBª≠œÒ£¨•∞•Ï©`
•π•±©`•Îª≠œÒ®Æ•´•È©`ª≠œÒ£¨
æĪ≠®ÆŒÔê≠œÒ§ §…£Æ
Twitter§«§œ#edges2cats
§¨”–√˚£Æ](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-18-320.jpg)
![CycleGAN[Zhu, ICCV2017] £®4/9£©
19
? ª≠œÒÈg§ŒΩÃéü§¨§ §§àˆ∫œ§Œpix2pix
®C 2§ƒ§Œ•…•·•§•Ûâ‰ìQ§ÀÈv§π§ÎÈv ˝§Úåg◊∞£®G: X->Y, F: Y->X£©
? X->Y->X?/Y->X->Y?§À§™§§§∆X§»X?, Y§»Y?§Œ’`≤Ó§Ú»°§Î£®Cycle
Consistency Loss£©
? Discriminator Dx, Dy§‚∫¨§ýågª≠œÒ§ §Œ§´£¨â‰ìQª≠œÒ§ §Œ§´§Ú‘uÅ˝
? ?µƒÈv ˝§œX/Y§Àåù§π§ÎAdversarial Loss§»Cycle Consistency Loss§Ú
Õ¨ïr◊ÓþmªØ
®C ågÚY
? AMT§À§Ë§Í•¡•Â©`•Í•Û•∞•∆•π•»§Úåg ©
? ågÚY§«§œBiGAN, CoGAN, feature loss + GAN, SimGAN§»?ð^
pix2pix§Œ§Ë§¶§ £¨∂ýòî§ •…•·•§•Û§Œ
â‰ìQ§»§§§¶Ãÿ–‘§Ú“˝§≠æ@§§§«§§§Î£Æ§≥
§Œª≠œÒâ‰ìQ§ÚΩÃéü§ §∑§«?§¶§»§≥§Ì§¨
–¬“é–‘§«§¢§Î£ÆSNS…œ§«§œ•¶•Þ§Ú•∑•Þ
•¶•Þ§À§π§Î§»§§§¶÷iºº–g£®£ø£©§ÚÒl π
§∑§∆’ì?§Ú–˚Ū§∑§∆§§§ø£Æ](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-19-320.jpg)
![ACGAN£®Auxiliary Classifier GAN£©[Odera, ICML2017] £®5/9£©
20
? Ãıº˛∏∂§≠GAN§Úé⁄§·§øºº–g£ø
®C GAN§Œ•ø•π•Ø§Œ§þ§«§ §Ø£¨•´•∆•¥•Í◊RÑe§‚•ø•π•Ø§»§∑§∆◊∑º”
®C ?≥…ª≠œÒ§ŒΩ‚œÒ∂»§ÚœÚ…œ£®64 [pixel] >> 128 [pixel]£©
? ≥ı§·§∆•«©`•ø•Ÿ©`•π§»§∑§∆ImageNet§Ú¿˚?
®C D§Àåù§∑§∆•Ø•È•π•È•Ÿ•Î§Œ¥_¬ ∑÷≤º§Ú∑µ»¥§µ§ª§∆’`≤Ó§Ú”ãÀ„
cGAN§Œòã‘Ï
£®‘Ÿí˜£© ? åg◊∞…œ§Œ??§œ•´•∆•¥•Í§»•Œ•§•∫§Ú
þBΩY§∑§ø•Ÿ•Ø•»•Î
? G§œ•´•∆•¥•Í§‚º”Œ∂§∑§∆ª≠œÒ§Ú?≥…
? D§Œ≥ˆ?§œ•´•∆•¥•Í§»Real/Fake](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-20-320.jpg)
![WGAN£®Wasserstein GAN£©[Arjovsky, ICML2017]
SNGAN£®Spectral Normalization GAN£©[Miyato, ICLR2018]
21
? GAN§Œ—ß¡ï∞≤∂®ªØ
®C WGAN
? ∑÷≤ºÈgæýÎx§Œ?ð^?∑®§«§¢§ÎEMD£®Earth Mover Distance£©§Úåß?§∑§∆
—ß¡ï∞≤∂®ªØ
? 5ªÿCritic§Ú—ß¡ï°¢1ªÿG§Ú—ߡ琉¿R§Í∑µ§∑
? •Í•◊•∑•√•ƒþBæA–‘£®Èv ˝§ŒÉA§≠§¨”–ΩÁ§ÀÖߧާÎ; sigmoid, relu§œ•Í•◊
•∑•√•ƒþBæA£©§Ú?§§§∆•—•È•·©`•ø§ŒπÝáϧÚõQ∂®§π§Î§»—ߡ裡∞≤∂®ªØ§π§Î
? BN≤ª“™
? èæ¿¥§œD§À∫œ§Ô§ª§∆G§¨—ß¡ï§∑§∆§§§ø§¨°¢WGAN§œG§Úª˘ú §À§∑§∆D§Ú—ß
¡ï§π§Î
®C SNGAN
? •Í•◊•∑•√•ƒ÷∆ºs£®§π§þ§Þ§ª§Û£¨§¢§Þ§Í¿ÌΩ‚§«§≠§∆§§§ §§•«•π£©§¨÷ÿ“™§«D§Œ’˝ÑtªØ§»§∑§∆Ñøπ˚•¢•Í
®C D§Àåù§∑§∆∏˜å”§ÀSpectral Normalization§Úåß?§π§Î§»—ߡ裡§¶§Þ§ØþM?
? BN§ §…èæ¿¥§Œ—ß¡ï∞≤∂®ªØ?∑®§Ú?§§§∫§À∞≤∂®ªØ
? ø÷§È§Ø≥ı§·§∆1•‚•«•Î§«ImageNet§Œ1,000•´•∆•¥•Í§Ú?≥…§«§≠§ø§»‘uÅ˝
£®6/9£©](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-21-320.jpg)
![PGGAN£®Progressive Growing GAN£©[Karras, ICLR2018]£®7/9£©
22
®C °∏–Ï°©§À≥…?§π§Î°π“™Àÿ£®”“áÌ£©§À§Ë§Í£¨
? ª≠œÒ?≥…§Àåù§π§Î—ߡ琉∞≤∂®–‘§Ú?§·—ߡ琉Öß ¯§ÚÀŸ§Ø§∑§ø
? ΩYπ˚µƒ§À£¨ª≠œÒ?≥…§ŒΩ‚œÒ∂»§Ú?§·§Î§≥§»§Àÿïœ◊
®C ΩYπ˚
? CIFAR-10§À§ƒ§§§∆§œSoTA£®IS: 8.80£©
? Öß ¯§¨‘Á§Ø§ §Î£®2 ®C 6 times faster£©
§Ω§ŒÀ˚£¨?∑Úµ„
? 唧Ú◊∑º”§π§ÎÎH§À÷ÿ§þ£®¶¡£©§Úâດ
? Minibatch discrimination§ÚÖgºÉªØ§∑§ø
Minibatch standard deviation£∫•þ•À
•–•√•¡ƒ⁄§«òÀú ∆´≤Ó§Ú”ãÀ„/∆Ωæ˘§∑§∆D
§Œ◊ÓΩK唧ÀΩy∫œ
? 唧¥§»§Œ’˝ÑtªØ§Ú?§¶•—•È•·©`•ø§À§Ë
§Í—ß¡ï¬ §Ú’{’˚](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-22-320.jpg)
![SAGAN£®Self-Attention GAN£©[Zhang, arXiv2018] £®8/9£©
23
? •¢•∆•Û•∑•Á•ÛôCòã§Ú?§§§øGAN§Œ?æ´ºöªØ
®C ÷˜§ÀåùœÛŒÔ§À◊≈?§∑§∆‘îºö§Ú√˪≠
? ª≠œÒƒ⁄§Œ•—•ø©`•Û§À§™§±§Î“¿¥ÊÈvÇS§Œ≥È≥ˆ£¨”ãÀ„§ŒÑø¬ –‘§Œ?§«
”–¿˚
®C IS: 52.52 (higher is better), FID: 18.65 (lower is better)
? «∞ ˆ§ŒSNGAN§œ36.80@IS, 27.62@FID
SAGAN§À§™§±§Î•¢•∆•Û•∑•Á•Û•‚•∏•Â©`•Î
•¢•∆•Û•∑•Á•Û§À§Ë§Î◊≈?µ„](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-23-320.jpg)
![BigGAN[Brock, ICLR2019]£®9/9£©
24
? ◊Ó§‚?æ´ºö§ ª≠œÒ§Ú?≥…§π§ÎGAN£®2019ƒÍ2?¨F‘⁄£©
®C Big§»∫Ù§–§Ï§Î¿Ì”…
? 512•∞•È•’•£•√•Ø•Ð©`•…£®ågÎH§œGoogle…Á§ŒTensor Processing Unit£© π?
? ª≠œÒDB§À§œ3É|√∂ª≠œÒ∫¨§ýJFT-300M§ÚíÒ?
? •–•√•¡•µ•§•∫2,048£¨ª≠œÒ•µ•§•∫ 512 [pixel]Àƒ?
®C Truncated Trick
? •‚©`•…±¿â≤§Ú∑¿§∞§ø§·§Œºº–g
? «–∂œ’˝“é∑÷≤º§ŒπÝáÏ’{’˚§À§Ë§Í£¨∂ýòî–‘§»ª≠Ÿ|§Ú¥_±£
BigGAN§Œ≥ˆ?; ?Èg§¨?§∆§‚åg
ÎH§Œ–¥’ʧ´?≥…ΩYπ˚§ §Œ§´≈–Ñe¿ß
Îy
◊Ûá̧œGoogle Collaboratory§À§∆≥ˆ?
https://colab.research.google.com/github/te
nsorflow/hub/blob/master/examples/colab/b
iggan_generation_with_tf_hub.ipynb](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-24-320.jpg)











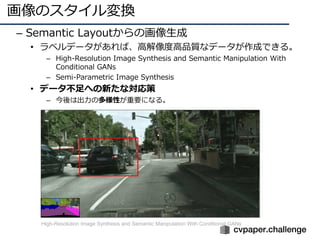

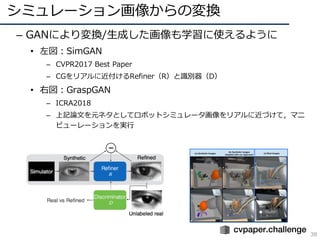
![ΩÃéü§¢§Í—ß¡ï vs. üoΩÃéü/»ıΩÃéü
39
? …Ÿ¡ø/üo •È•Ÿ•Î§«ΩÃéü”–§Í§ÀÑŸ§ƒ£°£®§»§§§¶•‚•¡•Ÿ©`•∑•Á•Û£©
? Cut/Paste—ß¡ï£∫º»¥Ê§Œ•ª•∞•·•Û•»•È•Ÿ•Î§Ú«–§ÍŸN§Í
§∑§∆GAN§À§Ë§Í?»ª§´∑Ò§´§Ú≈–∂œ
®C ?»ª£∫•π•±©`•Î§‰•≥•Û•∆•≠•π•»§Œ•∫•Ï§¨§ §§§´£ø
? ΩÃéü§ §∑—ߡ匿90%§Œæ´∂»§Þ§«¿¥§ø
[Remez+, ECCV18]Oral
Cut/Paste§«º»¥Ê•ª•∞•·•Û•»•È•Ÿ•Î§Úâດ£¨GAN§À§Ë§Í•π•±©`•Î§‰•≥•Û•∆•≠•π•»§¨?»ª§´§…§¶§´
§Ú≈–∂œ§π§Î§≥§»§«Ñøπ˚µƒ§À—ߡ•Û•◊•Î§Ú?≥…](https://image.slidesharecdn.com/190226ganmetastudygroup-190225043759/85/GAN-39-320.jpg)












![[DLðÜ’iª·]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=560&fit=bounds)

![[DLðÜ’iª·]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=560&fit=bounds)



![[DLðÜ’iª·]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)


![[DLHacks]StyleGAN§»BigGAN§ŒStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=560&fit=bounds)
![SSII2022 [SS1] •À•Â©`•È•Î3D±Ì¨F§Œ◊Ó–¬Ñ”œÚ? •À•Â©`•È•Î•Õ•√•»§«§ §Û§«§‚±Ì§ª§Î£ø£ø ??](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=560&fit=bounds)


![SSII2021 [OS2-01] Ðû“∆—ߡ琉ª˘µA£∫Æê§ §Î•ø•π•Ø§Œ÷™◊R§Ú¿˚”√§π§Î§ø§·§ŒôC–µ—ߡ琉∑Ω∑®](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=560&fit=bounds)



![SSII2022 [SS2] …Ÿ§ §§•«©`•ø§‰•È•Ÿ•Î§ÚÑø¬ µƒ§ÀªÓ”√§π§ÎôC–µ—ߡﺺ–g ? ◊„§Í§ §§«ÈàÛ§Ú§…§Œ§Ë§¶§À—a§¶§´£ø?](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)


![[DLðÜ’iª·]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/171222stargan-171225064145-thumbnail.jpg?width=560&fit=bounds)
![[DLðÜ’iª·] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=560&fit=bounds)




More Related Content
What's hot (20)
Similar to µ–åùµƒ…˙≥…•Õ•√•»•Ô©`•Ø£®≥“¥°±∑£© (18)










![[DLðÜ’iª·]Blind Video Temporal Consistency via Deep Video Prior](https://cdn.slidesharecdn.com/ss_thumbnails/20201030deepvideoprior-201030024757-thumbnail.jpg?width=560&fit=bounds)





Recently uploaded (11)











µ–åùµƒ…˙≥…•Õ•√•»•Ô©`•Ø£®≥“¥°±∑£©
- 1. î≥åùµƒ?≥…•Õ•√•»•Ô©`•Ø Generative Adversarial Networks; GAN ?å˘ ‘£–€ 1 http://xpaperchallenge.org/cv
- 2. 3rdAI 2 http://www.image-net.org/ http://cvpr2017.thecvf.com/ 1st AI 2nd AI 3rd AI 1st - 3rd AI Why 3rd AI? Architecture£®Algorithm£© Data Machine
- 3. Ãÿ§À•«©`•ø§œ÷ÿ“™ 3 ImageNet§œ•«©`•ø§Œ÷ÿ“™–‘§Ú√˜§È§´§À§∑§ø ®C 14,000,000+ imgs / 20,000+ categories ®C 2007ƒÍ§´§È•«©`•ø§ÚÖߺأ¨2009ƒÍCVPR∞k±Ì http://fungai.org/images/blog/imagenet-logo.png https://www.ted.com/talks/fei_fei_li_how_we_re_teaching_computers_t o_understand_pictures/up-next?language=ja ”“§œStanford§Œ? ◊Û§œ«∞À˘ Ù§ŒPrinceton …œ§Œæv§œWorldPeace~ ¿ΩÁ∆Ω∫Õ~§Ú?§π£®§È§∑§§£© Fei-Fei?§ŒTEDÑ”ª≠£®”“£©ŸY?¿R§Í§ŒøýÑ∫§‰£¨2000ƒÍ¥˙µ±ïr§œ•¢•Î •¥•Í•∫•ý?…œ÷˜¡x§«•«©`•ø§ÚÖߺاπ§Î§≥§»§¨¿ÌΩ‚§µ§Ï§ §´§√§ø
- 4. ª≠œÒ◊RÑe§ŒþMªØ ? DNNòã‘ϧŒ… ®C 2014ƒÍÌ林§È°∏òã‘ϧڧ˧ͅӧاπ§Î°π§ø§·§Œ÷™?§¨’˚§¶ ®C ¨F‘⁄£®÷˜§Àª≠œÒ◊RÑe§«£©÷˜¡˜§ §Œ§œResidual Network AlexNet [Krizhevsky+, ILSVRC2012] VGGNet [Simonyan+, ILSVRC2014] GoogLeNet [Szegedy+, ILSVRC2014/CVPR2015] ResNet [He+, ILSVRC2015/CVPR2016] ILSVRC2012 winner£¨DL§Œ?∏∂§±“€ 16/19唕Օ√•»£¨deeper•‚•«•Î§Œ÷™◊R ILSVRC2014 winner£¨22唕‚•«•Î ILSVRC2015 winner£¨ 152唣°(ågÚY§«§œ103+唧‚) 4
- 5. À˚•ø•π•Ø§ÿ§Œþm? ? ª≠œÒ◊RÑe§«§¶§Þ§Ø§§§Ø§»•ø•π•ØÐû?§¨∆§≥§Î ®C R-CNN: ŒÔÃÂó ≥ˆ ®C FCN: •ª•Þ•Û•∆•£•√•Ø•ª•∞•·•Û•∆©`•∑•Á•Û ®C CNN+LSTM£®Seq2Seq£©: ª≠œÒ’h√˜? ®C Two-Stream CNN: Ñ”ª≠’J◊R Person Uma Show and Tell [Vinyals+, CVPR15] R-CNN [Girshick+, CVPR14] FCN [Long+, CVPR15] Two-Stream CNN [Simonyan+, NIPS14] 5
- 6. î≥åùµƒ?≥…•Õ•√•»•Ô©`•Ø£®GAN£© 6 ? ª≠œÒ?≥…§Ú?§¶§ø§·§Œòã‘ϧ»§∑§∆÷∞∏ ®C ¨F‘⁄£¨?≥…/•«©`•ø§Œ∑÷≤º§ÚΩ¸§≈§±§Î–‘Ÿ|§´§È∂ý òî§ àˆ?§ÀèÍ? ®C ≥¨Ω‚œÒ£¨Æê≥£ó ÷™£¨•«©`•øíàèà § §… GAN§Œòã‘Ï https://medium.com/@sunnerli/the- missing-piece-of-gan-d091604a615a –Ï°©§Àır√˜§À§ §Î•«©`•ø BigGAN https://arxiv.org/pdf/1809.11096.pdf £®◊¢£©œ¬§œGAN§À§Ë§Í?≥…§µ§Ï§øª≠œÒ§«§π
- 7. GAN§Œí২§Í 7 ? °∏’ì? ˝∂ý§π§Æ£°°πÜñÓ}£®ΩYæ÷Ω‚õQ§ §È§∫°£°££© ®C GAN Zoo§À§œ501 GANs£®Èá”E: 2019/02/03£© ®C ågÎH ?GAN§»ðd§ª§Î¿˝§œ…Ÿ§ §Ø£¨∫Œ±∂§‚§ŒGAN ’ì?§¨Ã·∞∏§µ§Ï§Î GAN Zoo§À§œ∂ý§Ø§Œ~GAN§¨ÅK§÷ https://github.com/hindupuravinash/the-gan-zoo GAN§Œ÷¯’þGoodfellow?§‚GAN’ì?10þx§ÚΩBΩÈ https://twitter.com/goodfellow_ian/status/968249713924255744
- 8. GAN§Œí২§Í§Œ±≥æ∞ 8 ? æÞ?§ŒºÁ§À°∏§π§∞°π?§∆§ÎöððX§µ ®C £®§¥¥Ê÷™£©arXiv & GitHub§Œ?ªØ ®C arXiv§À§œ?°©50º˛«∞··§Œ’ì? ®C GitHub§œDL§∑§∆§π§∞§À π?ø… ? •≥•þ•Â•À•∆•£§«Q&A/–Þ’˝§«§≠§Î?ªØ https://chainer.org/images/logo.png http://pytorch.org/docs/master/_static/pytorch-logo-dark.svg https://www.tensorflow.org/_static/image s/tensorflow/logo.png DNN§Œ•’•Ï©`•ý•Ô©`•Ø’˘§§§¨þ^ü·
- 9. GANs§Ú’{ñÀ§π§Î√„è䪷 9 ? —–æø•≥•þ•Â•À•∆•£*ƒ⁄§«√„è䪷§ÚΩY≥… ®C §Ω§Œ√˚§‚GANs Study Group£®GAN-SG£© ®C ≥ı?’þ§¨3•ˆ?§«GANs•◊•Ì§Ú?÷∏§π£°√„è䪷 ? ’ì?§Œµ⁄?÷¯’þ§À§ §Ï§Î•Ï•Ÿ•Î§ÚœÎ∂® *cvpaper.challenge http://xpaperchallenge.org/cv Twitter§«§‚•·•Û•–©`§ÚƒººØ£¨Õ‚≤ø≤Œº”’þ§Ú ˝√˚◊∑º” https://twitter.com/HirokatuKataoka/status/1051485745 574105088
- 10. GANs§Ú’{ñÀ§π§Î√„è䪷 10 ? §§§´§À’{§Ÿ§ø§´£ø 1. •∞•Î©`•◊§Ú3∑÷∏Ó ? Challenger (C), Master (M), Observer (O)§À∑÷∏Ó ? •·•§•Û§œC£®9√˚£©§«M£®6√˚£©§ÀŸ|Üñ§∑§ §¨§È’{ñÀ 2. ÷˜“™9’ì?£®¥Œ•⁄©`•∏£©§Ú’i§þ÷˜“™§ ?√}§Ú∞—Œ’ ? C§¨’{ñÀ£¨M§À¥_’J§∑§ §¨§ÈõQ∂® ? •¢•Î•¥•Í•∫•ý§»§∑§∆§Œ?§≠§ ≪اڕ‘•√•Ø•¢•√•◊ 3. åg◊∞/•∆©`•Þ‘O∂®§Ú?µƒ§»§∑§ø•∞•Î©`•◊§À∑÷∏Ó åg◊∞ •∆©`•Þ ‘O∂® ®π ’ì?§œ’i§ý§¨£¨§Ω§Ï“‘…œ§À•≥©`•«•£•Û•∞§Ú•·•§•Û§Àåg © ®π ≥…π˚ŒÔ£∫åg◊∞§Œ•ð•§•Û•»§‰Ã·∞∏§ŒGAN§ÚŸY¡œ§À§∆÷≥ˆ ®π ’ì?’{ñÀ§ÚæW¡_µƒ§À?§§£¨–¬“é§À•∆©`•Þ§Ú‘O∂® ®π ≥…π˚ŒÔ£∫æW¡_µƒ•µ©`•Ÿ•§§ŒŸY¡œ
- 12. GAN§Œ÷˜“™§ ¡˜§Ï 12 ? ’ì?•Í•π•» 1. GAN£®•™•Í•∏• •Î§ŒGAN£© ? [Goodfellow, NIPS2014] https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf 2. DCGAN£®Æí§þÞz§þ唧Œ π?£© ? [Radford, ICLR2016] https://arxiv.org/abs/1511.06434 3. Pix2Pix£®pixelÕ¨?§¨åùèÍ∏∂§Ø§»§§§¶“‚Œ∂§«Conditional§ GAN£© ? [Isola, CVPR2017] https://arxiv.org/abs/1611.07004 4. CycleGAN£®pix2pix§ŒΩÃéü§ §∑∞Ê£© ? [Zhu, ICCV2017] https://arxiv.org/pdf/1703.10593.pdf 5. ACGAN£®•´•∆•¥•Í◊RÑe§‚Õ¨ïr§Àåg ©§∑§∆•≥•Û•«•£•∑•Á•Û§»§∑§ø£© ? [Odera, ICML2017] https://arxiv.org/abs/1610.09585 6. WGAN/SNGAN£®—ß¡ï∞≤∂®ªØ£© ? [Arjovsky, ICML2017] http://proceedings.mlr.press/v70/arjovsky17a.html ? [Miyato, ICLR2018] https://arxiv.org/abs/1802.05957 7. PGGAN£®?æ´∂»ªØ£© ? [Karras, ICLR2018] https://arxiv.org/abs/1710.10196 8. Self-Attention GAN£®•¢•∆•Û•∑•Á•ÛôCòã§ÚíÒ?£© ? [Zhang, arXiv 1805.08318] https://arxiv.org/abs/1805.08318 9. BigGAN£®≥¨?æ´ºöGAN£© ? [Brock, ICLR2019] https://arxiv.org/abs/1809.11096 # 2018ƒÍ10?ïrµ„§«§Œ’{ñÀ
- 13. GAN§Œ?∑÷Ó꣮1/2£© 13 ? GAN / pix2pix ®C GAN§œ•Œ•§•∫£®•È•Û•¿•ý•∑©`•…£©§´§Èª≠œÒ?≥… ®C pix2pix§œª≠œÒ??§À§Ë§Íâ‰ìQ ? •‘•Ø•ª•ÎÕ¨?§ŒåùèÍÈvÇS§Ú?§π•È•Ÿ•Î§¢§Ï§–â‰ìQø… GAN§Œòã‘Ï £®‘Ÿí˜£© pix2pix§Œòã‘Ï
- 14. GAN§Œ?∑÷Ó꣮2/2£© 14 ? GAN / cGAN ®C GAN§œ•´•∆•¥•Íþxík§«§≠§ §§ ®C cGAN§œ•´•∆•¥•Í/•‘•Ø•ª•Îµ»§À§Ë§ÍÃıº˛∏∂ ? —ß¡ïïr§À•´•∆•¥•Í§ÚΩÃ?£¨pix2pix§‚cGAN§Œ?∑N GAN§Œòã‘Ï £®‘Ÿí˜£© cGAN§Œòã‘Ï £®?¿˝£© §≥§≥§«§œAttribute£® Ù–‘£©§À §Ë§ÍÃıº˛∏∂§±§È§Ï§∆§§§Î§≥§» §«°∏Ãıº˛∏∂§≠°πî≥åùµƒ?≥… •Õ•√•»•Ô©`•Ø§»§ §√§∆§§§Î
- 15. GAN£®Generative Adversarial Networks£© [Goodfellow, NIPS2014]£®1/9£© 15 ? •™•Í•∏• •Î§ŒGAN ®C Generator£®G£©£∫DB£®x£©§Œ∑÷≤º§Ú‘Ÿ¨F£¨ª≠œÒ§Ú?≥… ®C Discriminator£®D£©£∫DB§´§È??§µ§Ï§ø§‚§Œ§´G§À§Ë§Í?≥…§µ§Ï§ø ª≠œÒ§´§Ú≈–∂œ ®C Min-Max§ÚΩ‚§Ø§≥§»§«•«©`•ø∑÷≤º§Ú‘Ÿ¨F£¨≥ˆ?ø’Èg§Ú’{’˚ GAN§Œòã‘Ï £®‘Ÿí˜£© D§Ú◊Ó?ªØ£®G§œD§Ú°±?§≠§Ø°±Ú_§∑§ø§§£© G§Ú◊Ó?ªØ£®G§œDB§Œ∑÷≤º§À•’•£•√•»§µ§ª§ø§§£© ? G§œ•Œ•§•∫z§Ú??§»§∑§∆ª≠œÒ?≥… ? Pz(z)§œ?≥…§µ§Ï§ø≥ˆ?∑÷≤º ? Pdata(x)§œDB§Œ∑÷≤º
- 16. DCGAN£®Deep Convolutional GAN£©[Radford, ICLR2016] £®2/9£© 16 ? GAN§Œòã‘ϧڅÓå”Æí§þÞz§þ•Õ•√•»§À÷√§≠ìQ§® ®C Conv layer§Œ π?£®òã‘ϧœœ¬áÌ£© ? Linear/Pooling layer§ÚConv layer§À÷√§≠ìQ§® ? —ß¡ï∞≤∂®ªØ§Œ§ø§·£¨Batch Norm.§‚D/G§À◊∑º” ? ªÓ–‘ªØÈv ˝§œ£¨G: ReLU, D: LeakyReLU ®C ΩÃéü§ §∑Ãÿ蒱̨F ? —ß¡ïúg§þ§ŒD§Ú π?§∑§ø§È£¨82.8%@CIFAR-10 ? SVHN§À§ƒ§§§∆§‚Õ¨òî§À¡º∫√§ æ´∂» £¥å”§ŒÆí§þÞz§þòã‘ϧÀ§Ë§Í òã≥…§µ§Ï§∆§§§Î
- 17. DCGAN£®Deep Convolutional GAN£©[Radford, ICLR2016] £®2?/9£© 17 ? GAN§Œòã‘ϧڅÓå”Æí§þÞz§þ•Õ•√•»§À÷√§≠ìQ§® ®C À„–gµƒª≠œÒ?≥…£®”“œ¬áÌ£© ? Word2Vec§Œ§Ë§¶§Àº”À„/úpÀ„§À§Ë§Îª≠œÒ?≥…§¨ø…ƒÐ ? ÓܧŒªÿÐû§‚interpolation§«±Ì¨Fø…ƒÐ ?§∑À„£¨“˝§≠À„§ §…÷±∏–µƒ§ ±Ì¨F §«ª≠œÒ?≥…§Úåg¨F§∑§ø£ø
- 18. Pix2Pix[Isola, CVPR2017] £®3/9£© 18 ? •‘•Ø•ª•ÎÕ¨?§¨åùèͧ∑§øª≠œÒâ‰ìQ ®C •‘•Ø•ª•ÎÈg§«Ãıº˛∏∂§±§Ú?§ §√§øGAN§»◊Ω§®§Î§≥§»§¨§«§≠§Î ? èæ¿¥§œÑe°©§À◊h’짵§Ï§∆§≠§øª≠œÒâ‰ìQ§Œ—ß¡ï§ÚÖg?§ŒñòΩM§þ§«åg © ? Enc-Decòã‘ϧŒ§‚§Œ§¿§±§«§ §Ø£¨U-Net§ÚG§»§∑§∆íÒ? ? •È•Ÿ•Î§œª≠œÒ§»â‰ìQ§∑§øª≠œÒ£®œ¬á̧Œ§Ë§¶§À??£© Ög?§ŒñòΩM§þ£®Ög?•‚•«•Î §«§ §§£©§«—} ˝§Œ•‘•Ø•ª•Î Õ¨?§Œœýª•ª≠œÒâ‰ìQ§Àåùè꣮ •È•Ÿ•Î®ÆRGBª≠œÒ£¨•∞•Ï©` •π•±©`•Îª≠œÒ®Æ•´•È©`ª≠œÒ£¨ æĪ≠®ÆŒÔê≠œÒ§ §…£Æ Twitter§«§œ#edges2cats §¨”–√˚£Æ
- 19. CycleGAN[Zhu, ICCV2017] £®4/9£© 19 ? ª≠œÒÈg§ŒΩÃéü§¨§ §§àˆ∫œ§Œpix2pix ®C 2§ƒ§Œ•…•·•§•Ûâ‰ìQ§ÀÈv§π§ÎÈv ˝§Úåg◊∞£®G: X->Y, F: Y->X£© ? X->Y->X?/Y->X->Y?§À§™§§§∆X§»X?, Y§»Y?§Œ’`≤Ó§Ú»°§Î£®Cycle Consistency Loss£© ? Discriminator Dx, Dy§‚∫¨§ýågª≠œÒ§ §Œ§´£¨â‰ìQª≠œÒ§ §Œ§´§Ú‘uÅ˝ ? ?µƒÈv ˝§œX/Y§Àåù§π§ÎAdversarial Loss§»Cycle Consistency Loss§Ú Õ¨ïr◊ÓþmªØ ®C ågÚY ? AMT§À§Ë§Í•¡•Â©`•Í•Û•∞•∆•π•»§Úåg © ? ågÚY§«§œBiGAN, CoGAN, feature loss + GAN, SimGAN§»?ð^ pix2pix§Œ§Ë§¶§ £¨∂ýòî§ •…•·•§•Û§Œ â‰ìQ§»§§§¶Ãÿ–‘§Ú“˝§≠æ@§§§«§§§Î£Æ§≥ §Œª≠œÒâ‰ìQ§ÚΩÃéü§ §∑§«?§¶§»§≥§Ì§¨ –¬“é–‘§«§¢§Î£ÆSNS…œ§«§œ•¶•Þ§Ú•∑•Þ •¶•Þ§À§π§Î§»§§§¶÷iºº–g£®£ø£©§ÚÒl π §∑§∆’ì?§Ú–˚Ū§∑§∆§§§ø£Æ
- 20. ACGAN£®Auxiliary Classifier GAN£©[Odera, ICML2017] £®5/9£© 20 ? Ãıº˛∏∂§≠GAN§Úé⁄§·§øºº–g£ø ®C GAN§Œ•ø•π•Ø§Œ§þ§«§ §Ø£¨•´•∆•¥•Í◊RÑe§‚•ø•π•Ø§»§∑§∆◊∑º” ®C ?≥…ª≠œÒ§ŒΩ‚œÒ∂»§ÚœÚ…œ£®64 [pixel] >> 128 [pixel]£© ? ≥ı§·§∆•«©`•ø•Ÿ©`•π§»§∑§∆ImageNet§Ú¿˚? ®C D§Àåù§∑§∆•Ø•È•π•È•Ÿ•Î§Œ¥_¬ ∑÷≤º§Ú∑µ»¥§µ§ª§∆’`≤Ó§Ú”ãÀ„ cGAN§Œòã‘Ï £®‘Ÿí˜£© ? åg◊∞…œ§Œ??§œ•´•∆•¥•Í§»•Œ•§•∫§Ú þBΩY§∑§ø•Ÿ•Ø•»•Î ? G§œ•´•∆•¥•Í§‚º”Œ∂§∑§∆ª≠œÒ§Ú?≥… ? D§Œ≥ˆ?§œ•´•∆•¥•Í§»Real/Fake
- 21. WGAN£®Wasserstein GAN£©[Arjovsky, ICML2017] SNGAN£®Spectral Normalization GAN£©[Miyato, ICLR2018] 21 ? GAN§Œ—ß¡ï∞≤∂®ªØ ®C WGAN ? ∑÷≤ºÈgæýÎx§Œ?ð^?∑®§«§¢§ÎEMD£®Earth Mover Distance£©§Úåß?§∑§∆ —ß¡ï∞≤∂®ªØ ? 5ªÿCritic§Ú—ß¡ï°¢1ªÿG§Ú—ߡ琉¿R§Í∑µ§∑ ? •Í•◊•∑•√•ƒþBæA–‘£®Èv ˝§ŒÉA§≠§¨”–ΩÁ§ÀÖߧާÎ; sigmoid, relu§œ•Í•◊ •∑•√•ƒþBæA£©§Ú?§§§∆•—•È•·©`•ø§ŒπÝáϧÚõQ∂®§π§Î§»—ߡ裡∞≤∂®ªØ§π§Î ? BN≤ª“™ ? èæ¿¥§œD§À∫œ§Ô§ª§∆G§¨—ß¡ï§∑§∆§§§ø§¨°¢WGAN§œG§Úª˘ú §À§∑§∆D§Ú—ß ¡ï§π§Î ®C SNGAN ? •Í•◊•∑•√•ƒ÷∆ºs£®§π§þ§Þ§ª§Û£¨§¢§Þ§Í¿ÌΩ‚§«§≠§∆§§§ §§•«•π£©§¨÷ÿ“™§«D§Œ’˝ÑtªØ§»§∑§∆Ñøπ˚•¢•Í ®C D§Àåù§∑§∆∏˜å”§ÀSpectral Normalization§Úåß?§π§Î§»—ߡ裡§¶§Þ§ØþM? ? BN§ §…èæ¿¥§Œ—ß¡ï∞≤∂®ªØ?∑®§Ú?§§§∫§À∞≤∂®ªØ ? ø÷§È§Ø≥ı§·§∆1•‚•«•Î§«ImageNet§Œ1,000•´•∆•¥•Í§Ú?≥…§«§≠§ø§»‘uÅ˝ £®6/9£©
- 22. PGGAN£®Progressive Growing GAN£©[Karras, ICLR2018]£®7/9£© 22 ®C °∏–Ï°©§À≥…?§π§Î°π“™Àÿ£®”“áÌ£©§À§Ë§Í£¨ ? ª≠œÒ?≥…§Àåù§π§Î—ߡ琉∞≤∂®–‘§Ú?§·—ߡ琉Öß ¯§ÚÀŸ§Ø§∑§ø ? ΩYπ˚µƒ§À£¨ª≠œÒ?≥…§ŒΩ‚œÒ∂»§Ú?§·§Î§≥§»§Àÿïœ◊ ®C ΩYπ˚ ? CIFAR-10§À§ƒ§§§∆§œSoTA£®IS: 8.80£© ? Öß ¯§¨‘Á§Ø§ §Î£®2 ®C 6 times faster£© §Ω§ŒÀ˚£¨?∑Úµ„ ? 唧Ú◊∑º”§π§ÎÎH§À÷ÿ§þ£®¶¡£©§Úâດ ? Minibatch discrimination§ÚÖgºÉªØ§∑§ø Minibatch standard deviation£∫•þ•À •–•√•¡ƒ⁄§«òÀú ∆´≤Ó§Ú”ãÀ„/∆Ωæ˘§∑§∆D §Œ◊ÓΩK唧ÀΩy∫œ ? 唧¥§»§Œ’˝ÑtªØ§Ú?§¶•—•È•·©`•ø§À§Ë §Í—ß¡ï¬ §Ú’{’˚
- 23. SAGAN£®Self-Attention GAN£©[Zhang, arXiv2018] £®8/9£© 23 ? •¢•∆•Û•∑•Á•ÛôCòã§Ú?§§§øGAN§Œ?æ´ºöªØ ®C ÷˜§ÀåùœÛŒÔ§À◊≈?§∑§∆‘îºö§Ú√˪≠ ? ª≠œÒƒ⁄§Œ•—•ø©`•Û§À§™§±§Î“¿¥ÊÈvÇS§Œ≥È≥ˆ£¨”ãÀ„§ŒÑø¬ –‘§Œ?§« ”–¿˚ ®C IS: 52.52 (higher is better), FID: 18.65 (lower is better) ? «∞ ˆ§ŒSNGAN§œ36.80@IS, 27.62@FID SAGAN§À§™§±§Î•¢•∆•Û•∑•Á•Û•‚•∏•Â©`•Î •¢•∆•Û•∑•Á•Û§À§Ë§Î◊≈?µ„
- 24. BigGAN[Brock, ICLR2019]£®9/9£© 24 ? ◊Ó§‚?æ´ºö§ ª≠œÒ§Ú?≥…§π§ÎGAN£®2019ƒÍ2?¨F‘⁄£© ®C Big§»∫Ù§–§Ï§Î¿Ì”… ? 512•∞•È•’•£•√•Ø•Ð©`•…£®ågÎH§œGoogle…Á§ŒTensor Processing Unit£© π? ? ª≠œÒDB§À§œ3É|√∂ª≠œÒ∫¨§ýJFT-300M§ÚíÒ? ? •–•√•¡•µ•§•∫2,048£¨ª≠œÒ•µ•§•∫ 512 [pixel]Àƒ? ®C Truncated Trick ? •‚©`•…±¿â≤§Ú∑¿§∞§ø§·§Œºº–g ? «–∂œ’˝“é∑÷≤º§ŒπÝáÏ’{’˚§À§Ë§Í£¨∂ýòî–‘§»ª≠Ÿ|§Ú¥_±£ BigGAN§Œ≥ˆ?; ?Èg§¨?§∆§‚åg ÎH§Œ–¥’ʧ´?≥…ΩYπ˚§ §Œ§´≈–Ñe¿ß Îy ◊Ûá̧œGoogle Collaboratory§À§∆≥ˆ? https://colab.research.google.com/github/te nsorflow/hub/blob/master/examples/colab/b iggan_generation_with_tf_hub.ipynb
- 26. GAN§Œ¥˙±Ìµƒ§ ‘uÅ˝?∑®£®1/3£©Inception Score ? ’ì?•ø•§•»•Î ®C Improved Techniques for Training GANs ? ÷¯’þ√˚ ®C Tim Salimans et al. ? íÒíkª·◊h ®C NIPS 2016 ? ’ì?URL ®C http://papers.nips.cc/paper/6124-improved-techniques-for-training-gans ? •≥©`•…URL ®C https://github.com/openai/improved-gan ? §“§»§≥§» ®C Inception Score£®IS£©§ŒÃ·∞∏£®ågÎH§Œ’ì?§À§œGAN§ÀÈv§π§Î∑N°©§Œ∏ƒ…∆∑®§Ú”õðd£©
- 27. GAN§Œ¥˙±Ìµƒ§ ‘uÅ˝?∑®£®1/3£©Inception Score ? ?≥…ª≠œÒ§¨ °∞ŒÔÕ´•∆•¥•Í§»§∑§∆◊RÑe§∑§‰§π§§§´°± and °∞ŒÔÕ´•∆•¥•Í§¨ ∂ýòî§ ≥ˆ?§»§ §√§∆§§§Î§´°±§À§ƒ§§§∆‘uÅ˝ ®C ◊RÑe∆˜ Inception Model §À?≥…ª≠œÒ x §Ú??§∑§∆≥ˆ?§Œ•´•∆•¥•Íy§Œ¥_¬ ∑÷ ≤º p(y|x) §Ú?§§§Î ®C p(y) §»§ŒKL divergence§Ú”ãÀ„£¨»´§∆§Œxi§Àåù§∑§∆’˝“éªØ§∑§∆exp”ãÀ„§∑§ø §‚§Œ§¨IS ®C ∏˜xi§Àåù§∑§∆p(y|x) §¨peaky§«§¢§Î£®?–≈§Ú≥÷§√§∆•´•∆•¥•Í§ÚÕ∆∂®£©§€§…IS §œ?§§ ? •Ø•È•¶•…•Ω©`•∑•Û•∞£®AMT£©§À§Ë§Í?ð^§∑§∆£¨IS§Œ”–Ñø–‘§Ú¥_§´§·§ø ®C AMT§À§Ë§Í£¨?Èg§À§‚‘uÅ˝§∑§∆§‚§È§√§ø ®C IS§»AMT§ŒœýÈv§¨?§È§Ï§ø§Œ§«”–Ñø§»≈–∂œ < @IS ◊Û§Œª≠œÒ»∫§Ë§Í§‚”“§Œª≠œÒ»∫§Œ?§¨Ñ”ŒÔ §È§∑§§Ãÿè’§Ú◊Ω§®§∆§§§Î§Œ§«IS§œ?§§ £®§¿§¨?≥…§»§∑§∆§œ≤ª?∑÷£©
- 28. GAN§Œ¥˙±Ìµƒ§ ‘uÅ˝?∑®£®2/3£©Frechet Inception Distance ? ’ì?•ø•§•»•Î ®C GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium ? ÷¯’þ√˚ ®C Martin Heusel et al. ? íÒíkª·◊h ®C arXiv preprint 1706.08500 ? ’ì?URL ®C https://arxiv.org/pdf/1706.08500.pdf ? •≥©`•…URL ®C https://github.com/mseitzer/pytorch-fid ? §“§»§≥§» ®C ’˝Ω‚ª≠œÒ»∫/?≥…ª≠œÒ»∫§Œ∑÷≤ºÈg§ŒæýÎx§ÚÀ„≥ˆ§π§ÎFrechet Inception Distance (FID) §ŒÃ·∞∏
- 29. GAN§Œ¥˙±Ìµƒ§ ‘uÅ˝?∑®£®2/3£©Frechet Inception Distance ? •Í•¢•Îª≠œÒ»∫ pw(?)§»?≥…ª≠œÒ»∫ p(?)§Œ∑÷≤ºÈg§ŒæýÎx§Ú”ãÀ„§π§Î÷∏òÀ ®C èæ¿¥∑®§ŒÜñÓ}£∫◊RÑe∆˜§À§Ë§Î ¬··¥_¬ §œ•Œ•§•∫§Œ”∞Ìë§Ú∂ý∑÷§À Ч±§∆§∑§Þ§¶ ®C §Ω§Œ§ø§·£¨∑÷≤ºÈg§À§Ë§Î?ð^§¨÷ÿ“™§«§¢§Î ? ∂ý¥Œ‘™’˝“é∑÷≤º§»Å¢∂®§∑§øÎH§Œ£¨px§»p§ŒæýÎx§ÚFrechet Distance§À§Ë §Í”ãÀ„ ®C Frechet Dsitance£®•’•Ï•∑•ßæýÎx£©§œ«˙æÄÈg§ŒæýÎx§Úúy§Î÷∏òÀ§«§¢§Î ®C §≥§≥§«§œ∂ý¥Œ‘™’˝“é∑÷≤º§Ú«˙æħ»?◊ˆ§∑§∆æýÎx§Ú”ãÀ„ á̧œ§Ω§Ï§æ§Ï£¨ª≠œÒ§À•Œ•§•∫ §Úðd§ª§øÎH§ŒFID§Œâ‰ªØ£Æ◊Û …œ: •¨•¶•∑•¢•Û•Œ•§•∫£¨÷–—Î …œ: •¨•¶•∑•¢•Û•÷•È©`£¨”“…œ: •È•Û•¿•ý§Œ?æÿ–Œ£¨◊Ûœ¬: §Õ §∏§Ïª≠œÒ£¨÷–—Îœ¬: §¥§Þâc•Œ •§•∫£¨”“œ¬: Æê§ §Îª≠œÒ§ŒªÏ Õ¨
- 30. GAN§Œ¥˙±Ìµƒ§ ‘uÅ˝?∑®£®3/3£©GAN-train/test ? ’ì?•ø•§•»•Î ®C How good is my GAN? ? ÷¯’þ√˚ ®C Shmelkov et al. ? íÒíkª·◊h ®C ECCV 2018 ? ’ì?URL ®C https://hal.inria.fr/hal-01850447/document ? •◊•Ì•∏•ß•Ø•»URL ®C http://thoth.inrialpes.fr/research/ganeval/ ? §“§»§≥§» ®C GAN?≥…ª≠œÒ§À§Ë§Íª≠œÒ◊RÑe§Œtrain/test§Úåg ©§∑§∆£¨?≥…ª≠œÒ§Œ‘uÅ˝§Ú?§¶
- 31. GAN§Œ¥˙±Ìµƒ§ ‘uÅ˝?∑®£®3/3£©GAN-train/test ? GAN?≥…ª≠œÒ§À§Ë§Íª≠œÒ◊RÑe§Œtrain/test§Úåg ©§∑§∆£¨?≥…ª≠œÒ§Ú‘uÅ˝ ®C GAN-train ? GAN?≥…ª≠œÒ§«—ߡ•Í•¢•Îª≠œÒ§«•∆•π•» ? ?≥…ª≠œÒ§¨∂ýòî§ •´•∆•¥•Í§Ú±Ì¨F§«§≠§∆§§§Î§´£ø ®C GAN-test ? •Í•¢•Îª≠œÒ§«—ߡGAN?≥…ª≠œÒ§«•∆•π•» ? ?≥…ª≠œÒ§œ◊RÑe§∑µ√§Î§¿§±•Ø•™•Í•∆•£§Œ?§§ª≠œÒ§À§ §√§∆§§§Î§´£ø ? GAN§œ•«©`•øíàèà§À π§®§Î§´£ø ®C ¥§®§œNo£®ÖgºÉ§ cGAN§«§œ…œ?§Ø§§§´§ §§£© ®C ågª≠œÒ+GAN?≥…ª≠œÒ§À§Ë§Î•«©`•øíàèড়æ´∂»µÕœ¬£®”“œ¬±Ì≤Œ’’£© •Í•¢•Îª≠œÒ§«—ß¡ï? ª≠œÒ◊RÑe§Œ•∆•π•» GAN?≥…ª≠œÒ§«—ß ¡ï?•Í•¢•Îª≠œÒ§«ª≠ œÒ◊RÑe§Œ•∆•π•» (-1.7%) (-6.5%) (-6.0%) ågª≠œÒ§Œ§þ ågª≠œÒ+GAN?≥…ª≠œÒ GAN§«§œ•´•∆•¥•Í§Œ÷–Èg∏∂Ω¸£®interpolation image£©§Ú?≥…§π§Î§≥§»§‚§¢§Í£¨•Ø•È•πæ≥ΩÁ§Àêô ”∞Ìë§Ú”Χ®§∆§§§Î£ø
- 32. GAN§ÀÈv§π§Î’{ñÀ—–æø ? ’ì?•ø•§•»•Î ®C Are GANs Created Equal? A Large-Scale Study ? ÷¯’þ√˚ ®C Mario Lucic et al. ? íÒíkª·◊h ®C NeurIPS 2018 (arXiv preprint 1711.10337) ? ’ì?URL ®C https://arxiv.org/pdf/1711.10337.pdf ? •≥©`•…URL ®C https://github.com/google/compare_gan ? §“§»§≥§» ®C ◊Óœ»∂À§ŒGANs§Ú?ð^§∑§øΩYπ˚£¨•œ•§•—©`•—•È•·©`•ø•¡•Â©`•À•Û•∞¥Œµ⁄§«§…§Œ•‚•«•Î§‚ À∆§ø§Ë§¶§ •π•≥•¢§À§ §√§ø§≥§»§ÚàÛ∏Ê
- 33. Are GANs Created Equal? ? æW¡_µƒ§´§ƒ?“郣§ GAN§Œ‘uÅ˝§ÀÈv§π§Î’{ñÀ ®C §Ë§Í?≥…ΩYπ˚§Ú‘uÅ˝§«§≠§Î§»øº§®§È§Ï§Î‘uÅ˝÷∏òÀ§»§∑§∆FID§ÚíÒ?£®IS§Œ? µ„§ÚËa§þ§∆£© ®C GANs§Œ?∑®§œ¥Œ•⁄©`•∏§Œ±Ì§Ú≤Œ’’ ? •’•ß•¢§ ?ð^ ®C •‚•«•Î£®¥Œ•⁄©`•∏±Ì≤Œ’’£©§Œòã‘ϧœâ‰∏¸§∑§ §§ ®C •œ•§•—©`•—•È•·©`•ø§Ú’{’˚ ®C 4§ƒ§Œ¥˙±Ìµƒ§ •«©`•ø£®CelebA, CIFAR10, Fashion-MNIST, MNIST£©»´§∆ §Àåù§∑§∆‘uÅ˝ ? ΩYπ˚§´§È§Œøº≤Ï ®C ”ãÀ„•≥•π•»£®budget£©§Ú§´§±§Î§»§…§Œ•‚•«•Î§‚ÓêÀ∆§∑§øFID§Ú”õÂh ®C •—•È•·©`•øÃΩÀ˜§œ•«©`•ø•ª•√•»§À“¿¥Ê£¨?§≠§ •‚•«•Î§€§…»´§∆§Œ•«©`•ø§Àåù èͧ∑§‰§π§§ ®C FÇé, Pre., Rec.§«§œ?§Ø§ §Í§‰§π§§•‚•«•Î§¨§¢§Î£®’ì?§«§œNS GAN£© ? £®”ãÀ„•≥•π•»§ÚπÃ∂®§∑§ §§œÞ§Í£©FID§«§Œ∏Ç’˘§œ“‚Œ∂§¨§ §§
- 34. ∏≈“™: Are GANs Created Equal? ? ?ð^§π§Î•¢©`•≠•∆•Ø•¡•„§»§Ω§Œ’`≤ÓÈv ˝£®D, G£©
- 36. ª≠œÒ§Œ•π•ø•§•Îâ‰ìQ ®C Semantic Layout§´§È§Œª≠œÒ?≥… ? •È•Ÿ•Î•«©`•ø§¨§¢§Ï§–°¢?Ω‚œÒ∂»?∆∑Ÿ|§ •«©`•ø§¨◊˜≥…§«§≠§Î°£ ®C High-Resolution Image Synthesis and Semantic Manipulation With Conditional GANs ®C Semi-Parametric Image Synthesis ? •«©`•ø≤ª?§ÿ§Œ–¬§ø§ åùèÍ≤þ ®C ΩÒ··§œ≥ˆ?§Œ∂ýòî–‘§¨÷ÿ“™§À§ §Î°£ High-Resolution Image Synthesis and Semantic Manipulation With Conditional GANs
- 37. ª≠œÒ§Œ•π•ø•§•Îâ‰ìQ 37 ®C Semantic Layout§´§È§ŒèÕ‘™£¨•€•Û•»§À•≠•Ï•§§À§ §Î ? §≥§Ï§œ§‚§¶£¨∏˜??§«—ß¡ï•«©`•ø§À 𧶧∑§´§ §§ ? £®£±£©•∑•þ•Â•Ï©`•ø§Ú•ª•Þ•Û•∆•£•√•Ø•È•Ÿ•Î§ÀèÕ‘™£¨£®£≤£©§≥§Œ? ∑®§«•ª•Þ•Û•∆•£•√•Ø•È•Ÿ•Î§Ú»Œ“‚§Œ•Í•¢•Îª≠œÒ§ÀèÕ‘™ ? £®£±£©§»£®£≤£©§ÚåùèÍ∏∂§±§Ï§–—ߡ琉?≥ˆ?ª≠œÒ§¨ÕÍ≥…£°
- 38. •∑•þ•Â•Ï©`•∑•Á•Ûª≠œÒ§´§È§Œâ‰ìQ 38 ®C GAN§À§Ë§Íâ‰ìQ/?≥…§∑§øª≠œÒ§‚—ß¡ï§À π§®§Î§Ë§¶§À ? ◊ÛáÌ£∫SimGAN ®C CVPR2017 Best Paper ®C CG§Ú•Í•¢•Î§ÀΩ¸∏∂§±§ÎRefiner£®R£©§»◊RÑe∆˜£®D£© ? ”“áÌ£∫GraspGAN ®C ICRA2018 ®C …œ”õ’ì?§Ú‘™•Õ•ø§»§∑§∆•Ì•Ð•√•»•∑•þ•Â•Ï©`•øª≠œÒ§Ú•Í•¢•Î§ÀΩ¸§≈§±§∆£¨•Þ•À •‘•Â©`•Ï©`•∑•Á•Û§Úåg?
- 39. ΩÃéü§¢§Í—ß¡ï vs. üoΩÃéü/»ıΩÃéü 39 ? …Ÿ¡ø/üo •È•Ÿ•Î§«ΩÃéü”–§Í§ÀÑŸ§ƒ£°£®§»§§§¶•‚•¡•Ÿ©`•∑•Á•Û£© ? Cut/Paste—ß¡ï£∫º»¥Ê§Œ•ª•∞•·•Û•»•È•Ÿ•Î§Ú«–§ÍŸN§Í §∑§∆GAN§À§Ë§Í?»ª§´∑Ò§´§Ú≈–∂œ ®C ?»ª£∫•π•±©`•Î§‰•≥•Û•∆•≠•π•»§Œ•∫•Ï§¨§ §§§´£ø ? ΩÃéü§ §∑—ߡ匿90%§Œæ´∂»§Þ§«¿¥§ø [Remez+, ECCV18]Oral Cut/Paste§«º»¥Ê•ª•∞•·•Û•»•È•Ÿ•Î§Úâດ£¨GAN§À§Ë§Í•π•±©`•Î§‰•≥•Û•∆•≠•π•»§¨?»ª§´§…§¶§´ §Ú≈–∂œ§π§Î§≥§»§«Ñøπ˚µƒ§À—ߡ•Û•◊•Î§Ú?≥…
- 40. ?»ª§ ◊ÀÑð§Ú§»§Íµ√§Î§´£ø 40 ? Õ∆∂®§∑§ø◊ÀÑð§¨?»ª§´£ø§Úî≥åùµƒ—ß¡ï ? «∞∞ΧœÕ®≥£§Œ◊ÀÑðÕ∆∂® ®C 3¥Œ‘™§Œ◊ÀÑð£®∫¨£∫–Œ◊¥?•´•·•È◊ÀÑ𣩧ÚèÕ‘™ ®C 2¥Œ‘™§ÿ§Œ‘ŸÕ∂”∞’`≤Ó§‚”ãÀ„ ? ··∞ΧÀ◊ÀÑðDB§»§Œ?ð^§«?»ª§´∑Ò§´§Ú≈–∂œ
- 42. åg◊∞§Œ≤Œøº£®1/3£© 42 ? PyTorch Tutorial ®C GAN£®•™•Í•∏• •Î£©§Ú»´§∆main.py§ÀºØºs ®C ª≠œÒ◊RÑe§‰RNN, ª≠œÒ’h√˜?§‚åg◊∞ ? ∆Ω“◊§ •≥©`•…§«åg◊∞§µ§Ï§∆§§§Î§Œ§«≥ı—ß’þ§À§œ§Ô§´§Í§‰§π§§ ? •‚•«•Î∂®¡x£¨DB§Œ•¿•¶•Û•Ì©`•…£¨loader§‚mainƒ⁄§À https://github.com/yunjey/pytorch-tutorial/tree/master/tutorials/03-advanced/generative_adversarial_network
- 43. åg◊∞§Œ≤Œøº£®2/3£© 43 ? PyTorch examples ®C DCGAN§Ú»´§∆main.py§ÀºØºs ®C PyTorchÈ_∞k’þ§À§Ë§Î•¡•Â©`•»•Í•¢•Î ? §≥§¡§È§‚GAN§ŒÀ˚§À§‚•µ•Û•◊•Î§¨ÿN∏ª ? ImageNet§œ?“郣§ £®∑÷…¢£©—ß¡ï§À§‚åùèÍ ? èäªØ—ß¡ï/?’ZÑI¿Ì•‚•«•Î§‚ÖßÂh https://github.com/pytorch/examples/tree/master/dcgan
- 44. åg◊∞§Œ≤Œøº£®3/3£© 44 ? GitHub@NVIDIA ®C PGGAN, pix2pixHD§ §…—–æøòIøɧÚπ´È_ ®C §‚§¡§Ì§Û£¨GAN“‘Õ‚§Œ—–æøòIøɧ‚∂ý ˝ https://github.com/NVIDIA/
- 45. GAN§«è䧧—–æøôCÈv£®∆ÛòIæ飩 45 ? Google Brain/DeepMind ®C Goodfellow?@Google Brain ? GAN§¿§±§«§ §ØìîÑ”•Œ•§•∫£®Adversarial Examples£©§Ú º§·§» §∑§øôC–µ—ߡ琉•ª•≠•Â•Í•∆•£§À§‚◊¢? ®C —–æø’þ§¨ºØ∫œ§π§Î≠hæ≥ ? •¢•´•«•þ•√•Ø§À≤–§Î§Ë§Í§‚?¥˝”ˆ ®C àRµπµƒ§ ”ãÀ„? ? GPU£®TPU?£© π§§∑≈Ó}£ø ? e.g. BigGAN§Œ512TPU@DeepMind ®C •◊•È•√•»•’•©©`•ý ? TensorFlow£®§≥§Ï§œ¡º§Ø?§Î£© ? Collaboratory£®§≥§¡§È§œ—–æø’þ§œ∂˜ê{ Ч±§∆§Î§´≤ª√˜£©
- 46. GAN§«è䧧—–æøôCÈv£®∆ÛòIæ飩 46 ? NVIDIA ®C àRµπµƒ§ ”ãÀ„? ? GPU π§§∑≈Ó}£ø ? ’ì?§À§œ§Ë§ØDGX-1§Ú π§§§Þ§∑§ø§»ï¯§§§∆§¢§Î ®C PGGAN/pix2pixHD ? PGGAN https://arxiv.org/abs/1710.10196 ? pix2pixHD https://arxiv.org/abs/1711.11585 ®C §‰§œ§Í—–æø’þ§¨ºØ∫œ£¨•≥©`•…§Þ§»§·
- 47. GAN§«è䧧—–æøôCÈv£®π˙ƒ⁄∆ÛòIæ飩 47 ? PFN ®C ”ãÀ„? ? Private Super Computer ®C åm?§µ§Û ? Spectral Normalization for GAN https://openreview.net/pdf?id=B1QRgziT- ? Projection Discriminator https://openreview.net/pdf?id=ByS1VpgRZ ®C ˝Sß’Êò‰§µ§Û ? TGAN https://arxiv.org/abs/1611.06624 ? TGANv2 https://arxiv.org/abs/1811.09245 ®C §Ω§Œ§€§´§À§‚èä?§ —–æø’þ§¨æA°©≤Œ? ? ML/CV§œ§‚§¡§Ì§Û£¨Math/NLP/Robotics/HCI§ §…
- 48. GAN§«è䧧—–æøôCÈv£®?—ßæ飩 48 ? A. Efros—–æø “ @UC Berkeley ®C pix2pix, CycleGAN ? A. Torralba—–æø “ @MIT ®C GAN Dissection ®C 3D GAN£®2Dª≠œÒ??§À§Ë§Í3DèÕ‘™£©
- 49. GAN≥ı—ß’þQ&A 49 ? Q. •∞•È•’•£•√•Ø•Ð©`•…??∑÷£ø A. åg◊∞§‰—–æø§œ§«§≠§Î§¨£¨•–•√•¡•µ•§•∫§¨?§µ§Ø§ §Í§¨§¡ ? Q. •–•√•¡•µ•§•∫?§µ§Ø§∆§‚?’…∑Ú£ø A. pix2pix/CycleGANµ»§Œâ‰ìQœµ§œ•–•√•¡•µ•§•∫§¨?§µ§Ø§∆§‚æ´∂»§œ§Ω§≥§Ω§≥≥ˆ§Î§Œ§«—– æø?çœ≥ˆ§Î§¨£¨GAN/cGAN§œ∂ý§§?§¨•Ÿ•ø©` ? Q. §‰§œ§ÍGPU§œ∂ý§§?§¨§Ë§§£ø A. £®µ±»ª§¿§±§…£©∂ý§§?§¨•—•È•·©`•ø/•‚•«•ÎÃΩÀ˜§ §…—–æø?È_∞k§Ú”–¿˚§ÀþM§·§È§Ï§Î ? Q. GPU ˝§Ú§ø§Ø§µ§Ûâ৉§∑§∆—–æø?È_∞k§π§Î§À§œ£ø A. ABCI£®Æbæt—–§ŒAIòÚ∂…§∑•Ø•È•¶•…£©§¨•™•π•π•·£° >> https://abci.ai/ja/ ? Q. •™•π•π•·§Œ—–æø?È_∞k?∑®§œ£ø A. GAN§œ—ß¡ïÌò∑¨§¨÷ÿ“™§ §Œ§«§¶§Þ§Ø§§§√§ø?∑®§ §…§Àè槧£¨•∆•Û•◊•Ï©`•»§Àµ±§∆§œ§· §∆§§§ØþM§·?§¨•∞•√•…
- 50. GAN≥ı—ß’þQ&A 50 ? Q. GAN£®•¨•Û£© vs. GAN£®•Æ•„•Û£©£ø A. √„èä§∑§∆§‚ΩYæ÷§Ë§Ø•Ô•´•È• •§