















2015 うちな?ICTヒ?シ?ネスフ?ランコンテストで使った資料
- 4. 2015うちな~ICTビジネスプラン発表会 クルーズ船、沖縄に初の4隻同時寄港?中国、台湾???海外から続々 ? ボイジャー?オブ?ザ?シーズ:中国の厦門(アモイ)から? 3848人が下船。 ? スーパースター?アクエリアス:台湾の基隆(キールン)から? 1672人が下船。 ? レジェンド?オブ?ザ?シーズ:同埠頭に厦門(アモイ)から 1975人をがぞれぞれ寄港した。 ? 引用元:沖縄タイムス+プラス(2015年7月29日)???????? http://www.okinawatimes.co.jp/article.php?id=126220
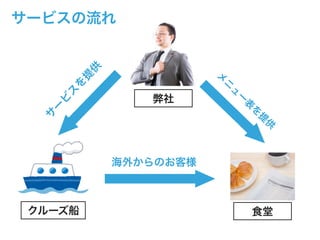
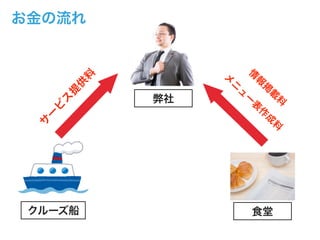
- 9. 2015うちな~ICTビジネスプラン発表会 DINING SURFERとは ? 沖縄の食堂に特化した飲食店検索サービス ? クルーズ船の運営会社と提携して運用 ? クルーズ船をご利用のお客様だけが利用できるWebサービス ? 中国語に最適化されたメニュー表を閲覧可能 ? GoogleMapを用いて食堂までの道のりをサポート ? クーポン利用でサービスも受けられる
- 14. 沖縄料理を翻訳してみた POWERED BY GOOGLE ? ?
- 15. 沖縄料理を翻訳してみた POWERED BY GOOGLE
- 16. 沖縄料理を翻訳してみた POWERED BY GOOGLE ? ? そこで登場するのがっ
- 17. 2015うちな~ICTビジネスプラン発表会 メニュー表作成アプリ ? 社内で利用する目的で作成 ? 誰でも簡単に作業出来る! ? さまざまな言语を拡张可能!
- 18. 2015うちな~ICTビジネスプラン発表会 メニュー表作成アプリ ? 社内で利用する目的で作成 ? 誰でも簡単に作業出来る! ? さまざまな言语を拡张可能! DEMO
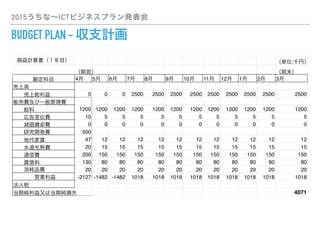
- 19. 2015うちな~ICTビジネスプラン発表会 BUDGET PLAN - 収支計画 損益計算書(1年目) (単位:千円) (期首) (期末) 勘定科目 4月 5月 6月 7月 8月 9月 10月 11月 12月 1月 2月 3月 売上高 ??売上総利益?????? 0 0 0 2500 2500 2500 2500 2500 2500 2500 2500 2500 販売費及び一般管理費 ??給料 1200 1200 1200 1200 1200 1200 1200 1200 1200 1200 1200 1200 ??広告宣伝費 10 5 5 5 5 5 5 5 5 5 5 5 ??減価償却費 0 0 0 0 0 0 0 0 0 0 0 0 ??研究開発費 500 ??地代家賃 47 12 12 12 12 12 12 12 12 12 12 12 ??水道光熱費 20 15 15 15 15 15 15 15 15 15 15 15 ??通信費 200 150 150 150 150 150 150 150 150 150 150 150 ??賃借料 130 80 80 80 80 80 80 80 80 80 80 80 ??消耗品費 20 20 20 20 20 20 20 20 20 20 20 20 ????営業利益 -2127 -1482 -1482 1018 1018 1018 1018 1018 1018 1018 1018 1018 法人税 当期純利益又は当期純損失 4071
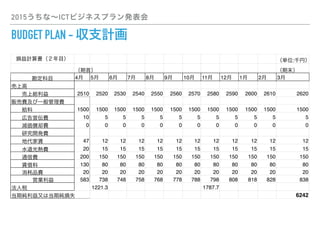
- 20. 2015うちな~ICTビジネスプラン発表会 BUDGET PLAN - 収支計画 損益計算書(2年目) (単位:千円) (期首) (期末) 勘定科目 4月 5月 6月 7月 8月 9月 10月 11月 12月 1月 2月 3月 売上高 ??売上総利益??????2510 2520 2530 2540 2550 2560 2570 2580 2590 2600 2610 2620 販売費及び一般管理費 ??給料 1500 1500 1500 1500 1500 1500 1500 1500 1500 1500 1500 1500 ??広告宣伝費 10 5 5 5 5 5 5 5 5 5 5 5 ??減価償却費 0 0 0 0 0 0 0 0 0 0 0 0 ??研究開発費 ??地代家賃 47 12 12 12 12 12 12 12 12 12 12 12 ??水道光熱費 20 15 15 15 15 15 15 15 15 15 15 15 ??通信費 200 150 150 150 150 150 150 150 150 150 150 150 ??賃借料 130 80 80 80 80 80 80 80 80 80 80 80 ??消耗品費 20 20 20 20 20 20 20 20 20 20 20 20 ????営業利益 583 738 748 758 768 778 788 798 808 818 828 838 法人税 1221.3 1787.7 当期純利益又は当期純損失 6242
- 21. 2015うちな~ICTビジネスプラン発表会 当ビジネスプランの問題点 ? DINING SURFERのメインページの作成をどうするか (自社内で作成?アウトソーシング?) ? コールセンターを利用したサポート体制をどうするか
- 22. 沖縄のおもてなしをせかいへ OKINAWA OMOTENASHI TO THE WORLD