1 of 6
Downloaded 13 times





Ad
Recommended
Introduction of "TrailBlazer" algorithm
Introduction of "TrailBlazer" algorithmKatsuki Ohto
?
The document presents a paper titled "Blazing the Trails Before Beating the Path: Sample-Efficient Monte-Carlo Planning" which details a nested Monte-Carlo planning algorithm for Markov Decision Processes (MDP). It aims to efficiently estimate the value of states while minimizing calls to a generative model, addressing the trade-off between the number of actions and acceptable estimation error. The paper also discusses theoretical guarantees and the sample complexity performance of the proposed algorithm.Fast and Probvably Seedings for k-Means
Fast and Probvably Seedings for k-MeansKimikazu Kato
?
The document proposes a new MCMC-based algorithm for initializing centroids in k-means clustering that does not assume a specific distribution of the input data, unlike previous work. It uses rejection sampling to emulate the distribution and select initial centroids that are widely scattered. The algorithm is proven mathematically to converge. Experimental results on synthetic and real-world datasets show it performs well with a good trade-off of accuracy and speed compared to existing techniques.InfoGAN: Interpretable Representation Learning by Information Maximizing
Gen...
InfoGAN: Interpretable Representation Learning by Information Maximizing
Gen...Shuhei Yoshida
?
Unsupervised learning of disentangled representations was the goal. The approach was to use GANs and maximize the mutual information between generated images and input codes. This led to the benefit of obtaining interpretable representations without supervision and at substantial additional costs.Dual Learning for Machine Translation (NIPS 2016)
Dual Learning for Machine Translation (NIPS 2016)Toru Fujino
?
The paper introduces a dual learning algorithm that utilizes monolingual data to improve neural machine translation. The algorithm trains two translation models in both directions simultaneously. Experimental results show that when trained with only 10% of parallel data, the dual learning model achieves comparable results to baseline models trained on 100% of data. The dual learning mechanism also outperforms baselines when trained on full data and can help address the lack of large parallel corpora.Value iteration networks
Value iteration networksFujimoto Keisuke
?
Value Iteration Networks is a machine learning method for robot path planning that can operate in new environments not seen during training. It works by predicting optimal actions through learning reward values for each state and propagating rewards to determine the sum of future rewards. The method was shown to be effective for planning in grid maps and continuous control tasks, and was even applied to navigation of Wikipedia links.Interaction Networks for Learning about Objects, Relations and Physics
Interaction Networks for Learning about Objects, Relations and PhysicsKen Kuroki
?
The document discusses a study aimed at developing a general-purpose learnable physics engine that can understand various physical dynamics through interaction networks. The model was tested on simulated scenarios, showcasing better performance compared to alternative approaches in learning physical interactions. Key findings suggest the potential for expansion and application to larger systems while questioning the efficiency and advantages over existing models.Introduction of “Fairness in Learning: Classic and Contextual Bandits”
Introduction of “Fairness in Learning: Classic and Contextual Bandits”Kazuto Fukuchi
?
1. The document discusses fairness constraints in contextual bandit problems and classic bandit problems.
2. It shows that for classic bandits, Θ(k^3) rounds are necessary and sufficient to achieve a non-trivial regret under fairness constraints.
3. For contextual bandits, it establishes a tight relationship between achieving fairness and Knows What it Knows (KWIK) learning, where KWIK learnability implies the existence of fair learning algorithms.Safe and Efficient Off-Policy Reinforcement Learning
Safe and Efficient Off-Policy Reinforcement Learningmooopan
?
This document summarizes the Retrace(λ) reinforcement learning algorithm presented by Remi Munos, Thomas Stepleton, Anna Harutyunyan and Marc G. Bellemare. Retrace(λ) is an off-policy multi-step reinforcement learning algorithm that is safe (converges for any policy), efficient (makes best use of samples when policies are close), and has lower variance than importance sampling. Empirical results on Atari 2600 games show Retrace(λ) outperforms one-step Q-learning and existing multi-step methods.Conditional Image Generation with PixelCNN Decoders
Conditional Image Generation with PixelCNN Decoderssuga93
?
The document summarizes research on conditional image generation using PixelCNN decoders. It discusses how PixelCNNs sequentially predict pixel values rather than the whole image at once. Previous work used PixelRNNs, but these were slow to train. The proposed approach uses a Gated PixelCNN that removes blind spots in the receptive field by combining horizontal and vertical feature maps. It also conditions PixelCNN layers on class labels or embeddings to generate conditional images. Experimental results show the Gated PixelCNN outperforms PixelCNN and achieves performance close to PixelRNN on CIFAR-10 and ImageNet, while training faster. It can also generate portraits conditioned on embeddings of people.Improving Variational Inference with Inverse Autoregressive Flow
Improving Variational Inference with Inverse Autoregressive FlowTatsuya Shirakawa
?
The document discusses the improvement of variational inference using Inverse Autoregressive Flow (IAF), which is shown to be computationally efficient and flexible for modeling complex posteriors in Variational Autoencoders (VAEs). It compares various inference models, including Diagonal/Full Covariance Gaussian distributions, Hamiltonian Flow, Normalizing Flows, and presents the capabilities and limitations of each method. The proposed IAF is evaluated through experiments on image generation tasks, demonstrating its effectiveness over existing methods.[DL輪読会]Convolutional Sequence to Sequence Learning
[DL輪読会]Convolutional Sequence to Sequence LearningDeep Learning JP
?
2017/5/19
Deep Learning JP:
http://deeplearning.jp/seminar-2/
論文紹介 Combining Model-Based and Model-Free Updates for Trajectory-Centric Rein...
論文紹介 Combining Model-Based and Model-Free Updates for Trajectory-Centric Rein...Kusano Hitoshi
?
The document discusses an integrated algorithm that combines model-based and model-free updates for trajectory-centric reinforcement learning, enhancing both data efficiency and compatibility with unknown dynamics. It details a two-stage approach integrating the strengths of existing methods (PI2 and LQR-FLM) to optimize policy performance across various robotic tasks. Experimental results demonstrate significant performance improvements in simulated and real-world applications, indicating the effectiveness of the proposed approach.NIPS 2016 Overview and Deep Learning Topics
NIPS 2016 Overview and Deep Learning Topics Koichi Hamada
?
The document provides an overview of the NIPS 2016 conference, detailing its agenda, topics like deep learning, generative adversarial networks (GANs), and recurrent neural networks (RNNs). It highlights the increase in participation and key features such as acceptance rates and types of presentations. Additionally, it discusses various recent developments and research presented at the conference in deep learning and GANs.Differential privacy without sensitivity [NIPS2016読み会資料]
Differential privacy without sensitivity [NIPS2016読み会資料]Kentaro Minami
?
The document discusses differential privacy and its application in statistical learning, specifically focusing on the Gibbs posterior method without the need for sensitivity. It presents a new approach to achieve (ε, δ)-differential privacy for Gibbs posteriors applicable to Lipschitz and convex loss functions. Additionally, it highlights the use of Langevin Monte Carlo methods as privacy-preserving approximate posterior sampling techniques.Matching networks for one shot learning
Matching networks for one shot learningKazuki Fujikawa
?
The document summarizes the paper "Matching Networks for One Shot Learning". It discusses one-shot learning, where a classifier can learn new concepts from only one or a few examples. It introduces matching networks, a new approach that trains an end-to-end nearest neighbor classifier for one-shot learning tasks. The matching networks architecture uses an attention mechanism to compare a test example to a small support set and achieve state-of-the-art one-shot accuracy on Omniglot and other datasets. The document provides background on one-shot learning challenges and related work on siamese networks, memory augmented neural networks, and attention mechanisms.More Related Content
Viewers also liked (11)
Safe and Efficient Off-Policy Reinforcement Learning
Safe and Efficient Off-Policy Reinforcement Learningmooopan
?
This document summarizes the Retrace(λ) reinforcement learning algorithm presented by Remi Munos, Thomas Stepleton, Anna Harutyunyan and Marc G. Bellemare. Retrace(λ) is an off-policy multi-step reinforcement learning algorithm that is safe (converges for any policy), efficient (makes best use of samples when policies are close), and has lower variance than importance sampling. Empirical results on Atari 2600 games show Retrace(λ) outperforms one-step Q-learning and existing multi-step methods.Conditional Image Generation with PixelCNN Decoders
Conditional Image Generation with PixelCNN Decoderssuga93
?
The document summarizes research on conditional image generation using PixelCNN decoders. It discusses how PixelCNNs sequentially predict pixel values rather than the whole image at once. Previous work used PixelRNNs, but these were slow to train. The proposed approach uses a Gated PixelCNN that removes blind spots in the receptive field by combining horizontal and vertical feature maps. It also conditions PixelCNN layers on class labels or embeddings to generate conditional images. Experimental results show the Gated PixelCNN outperforms PixelCNN and achieves performance close to PixelRNN on CIFAR-10 and ImageNet, while training faster. It can also generate portraits conditioned on embeddings of people.Improving Variational Inference with Inverse Autoregressive Flow
Improving Variational Inference with Inverse Autoregressive FlowTatsuya Shirakawa
?
The document discusses the improvement of variational inference using Inverse Autoregressive Flow (IAF), which is shown to be computationally efficient and flexible for modeling complex posteriors in Variational Autoencoders (VAEs). It compares various inference models, including Diagonal/Full Covariance Gaussian distributions, Hamiltonian Flow, Normalizing Flows, and presents the capabilities and limitations of each method. The proposed IAF is evaluated through experiments on image generation tasks, demonstrating its effectiveness over existing methods.[DL輪読会]Convolutional Sequence to Sequence Learning
[DL輪読会]Convolutional Sequence to Sequence LearningDeep Learning JP
?
2017/5/19
Deep Learning JP:
http://deeplearning.jp/seminar-2/
論文紹介 Combining Model-Based and Model-Free Updates for Trajectory-Centric Rein...
論文紹介 Combining Model-Based and Model-Free Updates for Trajectory-Centric Rein...Kusano Hitoshi
?
The document discusses an integrated algorithm that combines model-based and model-free updates for trajectory-centric reinforcement learning, enhancing both data efficiency and compatibility with unknown dynamics. It details a two-stage approach integrating the strengths of existing methods (PI2 and LQR-FLM) to optimize policy performance across various robotic tasks. Experimental results demonstrate significant performance improvements in simulated and real-world applications, indicating the effectiveness of the proposed approach.NIPS 2016 Overview and Deep Learning Topics
NIPS 2016 Overview and Deep Learning Topics Koichi Hamada
?
The document provides an overview of the NIPS 2016 conference, detailing its agenda, topics like deep learning, generative adversarial networks (GANs), and recurrent neural networks (RNNs). It highlights the increase in participation and key features such as acceptance rates and types of presentations. Additionally, it discusses various recent developments and research presented at the conference in deep learning and GANs.Differential privacy without sensitivity [NIPS2016読み会資料]
Differential privacy without sensitivity [NIPS2016読み会資料]Kentaro Minami
?
The document discusses differential privacy and its application in statistical learning, specifically focusing on the Gibbs posterior method without the need for sensitivity. It presents a new approach to achieve (ε, δ)-differential privacy for Gibbs posteriors applicable to Lipschitz and convex loss functions. Additionally, it highlights the use of Langevin Monte Carlo methods as privacy-preserving approximate posterior sampling techniques.Matching networks for one shot learning
Matching networks for one shot learningKazuki Fujikawa
?
The document summarizes the paper "Matching Networks for One Shot Learning". It discusses one-shot learning, where a classifier can learn new concepts from only one or a few examples. It introduces matching networks, a new approach that trains an end-to-end nearest neighbor classifier for one-shot learning tasks. The matching networks architecture uses an attention mechanism to compare a test example to a small support set and achieve state-of-the-art one-shot accuracy on Omniglot and other datasets. The document provides background on one-shot learning challenges and related work on siamese networks, memory augmented neural networks, and attention mechanisms.时系列データ3
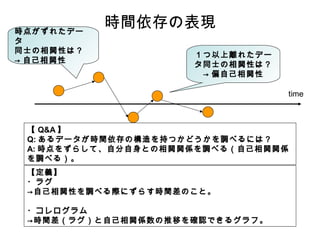
- 2. 時点がずれたデー タ 同士の相関性は? → 自己相関性 時間依存の表現 1つ以上離れたデー タ同士の相関性は? → 偏自己相関性 time 【 Q&A 】 Q: あるデータが時間依存の構造を持つかどうかを調べるには? A: 時点をずらして、自分自身との相関関係を調べる(自己相関関係 を調べる)。 【定義】 ?ラグ →自己相関性を調べる際にずらす時間差のこと。 ?コレログラム →時間差(ラグ)と自己相関係数の推移を確認できるグラフ。
- 4. 時系列データの定常性 「データが独立に抽出された標本である」という前提では、時間依存性を 調べられない。 束縛を弱めつつ、適した条件を考える 弱定常性 1.平均が時間によらず 一定 2.分散が時間によらず 一定 3.自己共分散がラグ h のみに依存 ( 時間によら ず一定) ホワイトノイズ 1.平均が 0 2.分散が一定 3.自己共分散が 0
- 5. 自己回帰モデル Rt = μ + Φ*Rt-1 + εt 1. εt はホワイトノイズ。→自己相関性が無い (過去時点の値には依存しない)。 2. |Φ|<1 という条件が、 Rt が定常性を満たすための条 件。 3. Φ=1 の場合、単位根を持つ時系列。 ※)はじめに対象データが単位根を有するかを調べ るべき。
- 6. 自己回帰モデル Rt = μ + Φ*Rt-1 + εt 1. εt はホワイトノイズ。→自己相関性が無い (過去時点の値には依存しない)。 2. |Φ|<1 という条件が、 Rt が定常性を満たすための条 件。 3. Φ=1 の場合、単位根を持つ時系列。 ※)はじめに対象データが単位根を有するかを調べ るべき。