5강 - 멀티모달 및 모듈화.pptx
Download as pptx, pdf0 likes149 views

.
1 of 17
Download to read offline




Ad
Recommended
딥러닝을 활용한 뉴스 메타 태깅
딥러닝을 활용한 뉴스 메타 태깅if kakao
��
김기도(olaf.kido) / kakao corp.(미래미디어파트)
---
사용자에게 알맞은 뉴스를 전달하기 위해서는 언론사에서 전달해주는 기본 정보 이외에도 컨텐츠의 다양한 특성을 파악하여 이를 사용자와 연결 짓는 것이 중요합니다. 다양한 특성 정보들 중에서 기사의 유형이나 핵심 주제 같은 것들은 컨텐츠 본문을 자연어 처리해서만 얻을 수 있기 때문에 분석하기가 매우 까다롭습니다. 본 발표에서는 Deep Learning 기술을 사용한 '뉴스 메타 태깅 시스템'의 개발 사례를 소개합니다. 이 사례를 통해 분석 모델 학습부터 운영 시스템 개발 과정에서의 고민과 Lessons Learned를 공유하도록 하겠습니다.딥 러닝 자연어 처리를 학습을 위한 파워포인트. (Deep Learning for Natural Language Processing)
딥 러닝 자연어 처리를 학습을 위한 파워포인트. (Deep Learning for Natural Language Processing)WON JOON YOO
��
딥 러닝 자연어 처리를 공부하면서 여러가지 기법들을 파워 포인트 그림으로 그려보았습니다. 참고하시라고 업로드합니다.
감사합니다.딥 러닝 자연어 처리 학습을 위한 PPT! (Deep Learning for Natural Language Processing)
딥 러닝 자연어 처리 학습을 위한 PPT! (Deep Learning for Natural Language Processing)WON JOON YOO
��
딥 러닝 자연어 처리를 공부하면서 여러가지 기법들을 파워 포인트 그림으로 그려보았습니다. 2019년에 올렸던 파일에서 BERT 등 자료를 추가하여 두번째 버전을 업로드합니다.
감사합니다.Spark & Zeppelin을 활용한 머신러닝 실전 적용기
Spark & Zeppelin을 활용한 머신러닝 실전 적용기Taejun Kim
��
Zeppelin 노트북, 화재 뉴스 기사 데이터셋:
https://github.com/uosdmlab/playdata-zeppelin-notebook
2016년 10월 14일(금)에 "마루180"서 열린 "데이터야놀자"에서 진행한 세션 "Spark & Zeppelin을 활용한 머신러닝 실전 적용기" 슬라이드입니다. 많은 분들이 빠르고 쉽게 Spark ML을 시작했으면 하는 마음에서 발표를 준비했습니다! 실제로 Spark와 Zeppelin으로 머신러닝을 하며 발생한 문제점과 해결법, 간단한 텍스트 분류 예제와 성능 향상 사례 등의 내용을 담았습니다. 세션에서는 제플린 노트북과 슬라이드를 번갈아가며 진행하였는데, 노트북이 궁금하신 분들은 GitHub에 올려두었으니 직접 실행해보세요^^ (정말 열심히 정리했습니다 ㅠㅠ)
서울시립대학교 데이터마이닝연구실 김태준
*(�ݺ�ߣShare에서도 배달의민족 도현체 쓰고 싶어요)1.introduction(epoch#2)
1.introduction(epoch#2)Haesun Park
��
�ݺ�ߣs based on "Introduction to Machine Learning with Python" by Andreas Muller and Sarah Guido for Hongdae Machine Learning Study(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)
홍대 머신 러닝 스터디(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)의 "파이썬 라이브러리를 활용한 머신러닝"(옮긴이 박해선) 슬라이드 자료.Naive ML Overview
Naive ML OverviewChul Ju Hong
��
머신러닝에 대한 간단한 소개입니다.
팀원들과 공부하기 위해서 짧게 만들어 본 자료라 많이 부족할 수 있습니다. 잘못된 부분은 지적해주시면 감사하겠습니다 :)딥러닝 세계에 입문하기 위반 분투
딥러닝 세계에 입문하기 위반 분투Ubuntu Korea Community
��
2018.11.10 - Ubuntu Fest, Daejeon (우분투 페스트, 대전)
딥러닝 세계에 입문하기 위반 분투 - 이수민
https://fest.ubuntu-kr.org
http://event.ubuntu-kr.org/2018/10/01/ubuntu-fest.htmlPython data analysis library
Python data analysis libraryDo Young Park
��
Data analysis tutorial for nano-degree class
numpy and pandas2.supervised learning(epoch#2)-3
2.supervised learning(epoch#2)-3Haesun Park
��
�ݺ�ߣs based on "Introduction to Machine Learning with Python" by Andreas Muller and Sarah Guido for Hongdae Machine Learning Study(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)
홍대 머신 러닝 스터디(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)의 "파이썬 라이브러리를 활용한 머신러닝"(옮긴이 박해선) 슬라이드 자료.4.representing data and engineering features(epoch#2)
4.representing data and engineering features(epoch#2)Haesun Park
��
�ݺ�ߣs based on "Introduction to Machine Learning with Python" by Andreas Muller and Sarah Guido for Hongdae Machine Learning Study(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)
홍대 머신 러닝 스터디(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)의 "파이썬 라이브러리를 활용한 머신러닝"(옮긴이 박해선) 슬라이드 자료.파이썬 데이터과학 1일차 - 초보자를 위한 데이터분석, 데이터시각화 (이태영)
파이썬 데이터과학 1일차 - 초보자를 위한 데이터분석, 데이터시각화 (이태영)Tae Young Lee
��
파이썬 데이터과학 - 기초 과정(1일차)
- 데이터분석, 데이터시각화
- jupyter notebook, numpy, pandas, matplotlib, seaborn
2차 과정은 따로 올리겠습니다.
문의 및 제안 : se2n@naver.com
데이터 소스 : https://github.com/sh2orc/datascience
Apache MXNet으로 배워보는 딥러닝(Deep Learning) - 김무현 (AWS 솔루션즈아키텍트)
Apache MXNet으로 배워보는 딥러닝(Deep Learning) - 김무현 (AWS 솔루션즈아키텍트)Amazon Web Services Korea
��
다양한 분야에서 좋은 성능을 보여주는 머신러닝의 한 종류인 딥 러닝에 대한 기본적인 개념과 이미지 분석에 많이 적용되는 Convolutional Neural Network 을 배워봅니다. 이를 구현하기 위한 딥러닝 프레임워크인 Apache MXNet에 대한 소개와 기본 사용법을 익혀보고, Fashion MNIST 데이터를 분류하는 CNN 모델을 구현하는 방법을 설명합니다."Dataset and metrics for predicting local visible differences" Paper Review
"Dataset and metrics for predicting local visible differences" Paper ReviewLEE HOSEONG
��
"Dataset and metrics for predicting local visible differences, 2018 SIGGPRAH" Paper ReviewML(KNN, Decision Tree), DL(RCNN, YOLO) educational slide
ML(KNN, Decision Tree), DL(RCNN, YOLO) educational slideBomm Kim
��
ML(KNN, Decision Tree), DL(RCNN, YOLO) educational slideMachine Learning Foundations (a case study approach) 강의 정리
Machine Learning Foundations (a case study approach) 강의 정리SANG WON PARK
��
실제 비즈니스에서 많이 활용되는 사례를 중심으로 어떻게 기존 데이터를 이용하여 알고리즘을 선택하고, 학습하여, 예측모델을 구축 하는지 jupyter notebook을 이용하여 실제 코드를 이용하여 실습할 수 있다.
강의 초반에 강조하는 것 처럼, 머신러닝 알고리즘은 나중에 자세히 설명하는 과정이 따로 있고, 이번 강의는 실제 어떻게 활용하는지에 완전히 초점이 맞추어져 있어서, 알고리즘은 아주 간략한 수준으로 설명해 준다. (좀 더 구체적인 내용은 심화과정이 따로 있음)
http://blog.naver.com/freepsw/221113685916 참고
https://github.com/freepsw/coursera/tree/master/ML_Foundations/A_Case_Study 코드 샘플[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기
[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기Joeun Park
��
서울 코엑스에서 진행된 파이콘 한국 2018에서 8월 19일에 발표한 내용입니다.
데이터 전처리와 Feature Engineering에 대해 다룹니다.
[파이콘 한국 2018 프로그램 | 땀내를 줄이는 Data와 Feature 다루기](https://www.pycon.kr/2018/program/47)
이 발표내용은 8월 17일 금요일에 진행되었던 다음 2개의 튜토리얼을 바탕으로 작성되었습니다.
* [공공데이터로 파이썬 데이터 분석 입문하기(3시간) — 파이콘 한국 2018](https://www.pycon.kr/2018/program/tutorial/6)
* [청와대 국민청원 데이터로 파이썬 자연어처리 입문하기(3시간) — 파이콘 한국 2018](https://www.pycon.kr/2018/program/tutorial/7)[Dissertation] Zero-Shot Demographic Inference on Edge Devices from Unstructu...
[Dissertation] Zero-Shot Demographic Inference on Edge Devices from Unstructu...Kim Dongmin
��
<Thesis details>
- https://www.riss.kr/link?id=T17157631
- Awarded Best Paper in Graduate School of Engineering, Yonsei University
<Keywords>
Small language models ; open weight models ; edge computing ; edge AI ; privacy-preserving AI ; zero-shot inference ; Retrieval Augmented Generation (RAG) ; demographic inference ; Normalization of Unstructured data ; 소형 언어 모델 ; 오픈 웨이트 모델 ; 엣지 컴퓨팅 ; 엣지 AI ; 개인정보 보호형 AI ; 제로 샷 추론 ; 검색 증강 생성(RAG) ; 인구 통계적 특성 추론 ; 비정형 데이터 정형화효율적인 후보물질검증 및 분자성질분석을 위한 분자 그래프 파운데이션 모델 구축
효율적인 후보물질검증 및 분자성질분석을 위한 분자 그래프 파운데이션 모델 구축Network Science Lab, The Catholic University of Korea
��
가톨릭대학교 네트워크과학 연구실 유망기술 설명회 자료230727_HB_JointJournalClub.pptx
230727_HB_JointJournalClub.pptxNetwork Science Lab, The Catholic University of Korea
��
1) The document proposes a graph-based method using graph convolutional networks to address challenges in sequential recommendation, such as extracting implicit preferences from long behavior sequences and adapting to changing user preferences over time.
2) It constructs an interest graph from user behaviors and designs an attentive graph convolutional network and dynamic pooling technique to aggregate implicit signals into explicit preferences.
3) Experimental results on two large-scale datasets show the proposed method significantly outperforms state-of-the-art sequential recommendation methods.More Related Content
Similar to 5강 - 멀티모달 및 모듈화.pptx (20)
Python data analysis library
Python data analysis libraryDo Young Park
��
Data analysis tutorial for nano-degree class
numpy and pandas2.supervised learning(epoch#2)-3
2.supervised learning(epoch#2)-3Haesun Park
��
�ݺ�ߣs based on "Introduction to Machine Learning with Python" by Andreas Muller and Sarah Guido for Hongdae Machine Learning Study(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)
홍대 머신 러닝 스터디(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)의 "파이썬 라이브러리를 활용한 머신러닝"(옮긴이 박해선) 슬라이드 자료.4.representing data and engineering features(epoch#2)
4.representing data and engineering features(epoch#2)Haesun Park
��
�ݺ�ߣs based on "Introduction to Machine Learning with Python" by Andreas Muller and Sarah Guido for Hongdae Machine Learning Study(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)
홍대 머신 러닝 스터디(https://www.meetup.com/Hongdae-Machine-Learning-Study/) (epoch #2)의 "파이썬 라이브러리를 활용한 머신러닝"(옮긴이 박해선) 슬라이드 자료.파이썬 데이터과학 1일차 - 초보자를 위한 데이터분석, 데이터시각화 (이태영)
파이썬 데이터과학 1일차 - 초보자를 위한 데이터분석, 데이터시각화 (이태영)Tae Young Lee
��
파이썬 데이터과학 - 기초 과정(1일차)
- 데이터분석, 데이터시각화
- jupyter notebook, numpy, pandas, matplotlib, seaborn
2차 과정은 따로 올리겠습니다.
문의 및 제안 : se2n@naver.com
데이터 소스 : https://github.com/sh2orc/datascience
Apache MXNet으로 배워보는 딥러닝(Deep Learning) - 김무현 (AWS 솔루션즈아키텍트)
Apache MXNet으로 배워보는 딥러닝(Deep Learning) - 김무현 (AWS 솔루션즈아키텍트)Amazon Web Services Korea
��
다양한 분야에서 좋은 성능을 보여주는 머신러닝의 한 종류인 딥 러닝에 대한 기본적인 개념과 이미지 분석에 많이 적용되는 Convolutional Neural Network 을 배워봅니다. 이를 구현하기 위한 딥러닝 프레임워크인 Apache MXNet에 대한 소개와 기본 사용법을 익혀보고, Fashion MNIST 데이터를 분류하는 CNN 모델을 구현하는 방법을 설명합니다."Dataset and metrics for predicting local visible differences" Paper Review
"Dataset and metrics for predicting local visible differences" Paper ReviewLEE HOSEONG
��
"Dataset and metrics for predicting local visible differences, 2018 SIGGPRAH" Paper ReviewML(KNN, Decision Tree), DL(RCNN, YOLO) educational slide
ML(KNN, Decision Tree), DL(RCNN, YOLO) educational slideBomm Kim
��
ML(KNN, Decision Tree), DL(RCNN, YOLO) educational slideMachine Learning Foundations (a case study approach) 강의 정리
Machine Learning Foundations (a case study approach) 강의 정리SANG WON PARK
��
실제 비즈니스에서 많이 활용되는 사례를 중심으로 어떻게 기존 데이터를 이용하여 알고리즘을 선택하고, 학습하여, 예측모델을 구축 하는지 jupyter notebook을 이용하여 실제 코드를 이용하여 실습할 수 있다.
강의 초반에 강조하는 것 처럼, 머신러닝 알고리즘은 나중에 자세히 설명하는 과정이 따로 있고, 이번 강의는 실제 어떻게 활용하는지에 완전히 초점이 맞추어져 있어서, 알고리즘은 아주 간략한 수준으로 설명해 준다. (좀 더 구체적인 내용은 심화과정이 따로 있음)
http://blog.naver.com/freepsw/221113685916 참고
https://github.com/freepsw/coursera/tree/master/ML_Foundations/A_Case_Study 코드 샘플[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기
[PyCon KR 2018] 땀내를 줄이는 Data와 Feature 다루기Joeun Park
��
서울 코엑스에서 진행된 파이콘 한국 2018에서 8월 19일에 발표한 내용입니다.
데이터 전처리와 Feature Engineering에 대해 다룹니다.
[파이콘 한국 2018 프로그램 | 땀내를 줄이는 Data와 Feature 다루기](https://www.pycon.kr/2018/program/47)
이 발표내용은 8월 17일 금요일에 진행되었던 다음 2개의 튜토리얼을 바탕으로 작성되었습니다.
* [공공데이터로 파이썬 데이터 분석 입문하기(3시간) — 파이콘 한국 2018](https://www.pycon.kr/2018/program/tutorial/6)
* [청와대 국민청원 데이터로 파이썬 자연어처리 입문하기(3시간) — 파이콘 한국 2018](https://www.pycon.kr/2018/program/tutorial/7)[Dissertation] Zero-Shot Demographic Inference on Edge Devices from Unstructu...
[Dissertation] Zero-Shot Demographic Inference on Edge Devices from Unstructu...Kim Dongmin
��
<Thesis details>
- https://www.riss.kr/link?id=T17157631
- Awarded Best Paper in Graduate School of Engineering, Yonsei University
<Keywords>
Small language models ; open weight models ; edge computing ; edge AI ; privacy-preserving AI ; zero-shot inference ; Retrieval Augmented Generation (RAG) ; demographic inference ; Normalization of Unstructured data ; 소형 언어 모델 ; 오픈 웨이트 모델 ; 엣지 컴퓨팅 ; 엣지 AI ; 개인정보 보호형 AI ; 제로 샷 추론 ; 검색 증강 생성(RAG) ; 인구 통계적 특성 추론 ; 비정형 데이터 정형화More from Network Science Lab, The Catholic University of Korea (20)
효율적인 후보물질검증 및 분자성질분석을 위한 분자 그래프 파운데이션 모델 구축
효율적인 후보물질검증 및 분자성질분석을 위한 분자 그래프 파운데이션 모델 구축Network Science Lab, The Catholic University of Korea
��
가톨릭대학교 네트워크과학 연구실 유망기술 설명회 자료230727_HB_JointJournalClub.pptx
230727_HB_JointJournalClub.pptxNetwork Science Lab, The Catholic University of Korea
��
1) The document proposes a graph-based method using graph convolutional networks to address challenges in sequential recommendation, such as extracting implicit preferences from long behavior sequences and adapting to changing user preferences over time.
2) It constructs an interest graph from user behaviors and designs an attentive graph convolutional network and dynamic pooling technique to aggregate implicit signals into explicit preferences.
3) Experimental results on two large-scale datasets show the proposed method significantly outperforms state-of-the-art sequential recommendation methods.S.M.Lee, Invited Talk on "Machine Learning-based Anomaly Detection"
S.M.Lee, Invited Talk on "Machine Learning-based Anomaly Detection"Network Science Lab, The Catholic University of Korea
��
S.M.Lee gave a talk at the homecoming event of NS-CUK.230724_Thuy_Labseminar.pptx
230724_Thuy_Labseminar.pptxNetwork Science Lab, The Catholic University of Korea
��
This document proposes the NGNN framework to improve the representation power of graph neural networks. NGNN extracts rooted subgraphs around each node and applies a base GNN independently to learn subgraph representations. These are then aggregated to obtain final node representations. The document outlines limitations of existing GNNs, describes the NGNN framework, and poses research questions about its theoretical power, performance improvements over base GNNs, results on benchmarks, and computational overhead. Key experiments are conducted on graph isomorphism, molecular property prediction, and node classification datasets to evaluate NGNN.230724-JH-Lab Seminar.pptx
230724-JH-Lab Seminar.pptxNetwork Science Lab, The Catholic University of Korea
��
This document presents a novel Claim-guided Hierarchical Graph Attention Network (ClaHi-GAT) model for rumor detection using undirected interaction graphs. The model uses multi-level attention - post-level attention considers the content of individual tweets, while event-level attention compares tweets responding to the same claim. This allows the model to better capture features indicative of rumors. Experimental results on three Twitter datasets show the proposed model achieves superior performance for rumor classification and early detection compared to previous structure-based methods.Technical Report on "Lecture Quality Prediction using Graph Neural Networks"
Technical Report on "Lecture Quality Prediction using Graph Neural Networks"Network Science Lab, The Catholic University of Korea
��
A technical report authored by Jooho Lee, Ho Beom Kim, and Hyo Eun Lee as a project outcome exhibited on the 2023 CUK Competition on Data Analytics.Presentation for "Lecture Quality Prediction using Graph Neural Networks"
Presentation for "Lecture Quality Prediction using Graph Neural Networks"Network Science Lab, The Catholic University of Korea
��
Presentation slides authored by Jooho Lee, Ho Beom Kim, and Hyo Eun Lee as a project outcome exhibited on the 2023 CUK Competition on Data Analytics.NS-CUK Seminar: J.H.Lee, Review on "Graph Neural Networks with convolutional ...
NS-CUK Seminar: J.H.Lee, Review on "Graph Neural Networks with convolutional ...Network Science Lab, The Catholic University of Korea
��
This document presents a novel graph neural network (GNN) convolutional layer based on Auto-Regressive Moving Average (ARMA) filters. The ARMA layer aims to address limitations of existing GNN layers that use polynomial filters by providing a more flexible frequency response with fewer parameters. It models graph signals using parallel stacks of recurrent operations to approximate high-order neighborhoods efficiently. Experimental results show the ARMA layer outperforms other GNN architectures on tasks like node classification, graph signal classification, and graph regression. Future work could explore incorporating text and content metadata into graph convolutional models.NS-CUK Seminar: V.T.Hoang, Review on "Are More Layers Beneficial to Graph Tra...
NS-CUK Seminar: V.T.Hoang, Review on "Are More Layers Beneficial to Graph Tra...Network Science Lab, The Catholic University of Korea
��
The document proposes a novel graph transformer model called DeepGraph. DeepGraph uses substructure sampling to encode local graph information and add substructure tokens. It applies localized self-attention on substructures using a mask. The document experiments with DeepGraph on various graph datasets and analyzes its performance as its depth increases. Deeper models show diminishing returns, indicating a limitation of increasing depth in graph transformers.NS-CUK Seminar: S.T.Nguyen Review on "Accurate learning of graph representati...
NS-CUK Seminar: S.T.Nguyen Review on "Accurate learning of graph representati...Network Science Lab, The Catholic University of Korea
��
This document summarizes a research paper on Graph Multiset Pooling, a new method for graph pooling using a Graph Multiset Transformer (GMT). The GMT treats graph pooling as a multiset encoding problem and uses multi-head attention to capture relationships among nodes. It satisfies the injectiveness and permutation invariance properties needed to be as powerful as the Weisfeiler-Lehman graph isomorphism test. Experimental results show the GMT outperforms other pooling methods on tasks like graph classification, reconstruction, and generation. The GMT provides a powerful and efficient way to learn meaningful representations of entire graphs.Joo-Ho Lee: Topographic-aware wind forecasting system using multi-modal spati...
Joo-Ho Lee: Topographic-aware wind forecasting system using multi-modal spati...Network Science Lab, The Catholic University of Korea
��
A presentation of Joo-Ho Lee on the 2023 Conference of Korea Institute of Smart Media (KISM).Ho-Beom Kim: Detection of Influential Unethical Expressions through Construct...
Ho-Beom Kim: Detection of Influential Unethical Expressions through Construct...Network Science Lab, The Catholic University of Korea
��
A presentation of Ho-Beom Kim on the 2023 Conference of Korea Institute of Smart Media (KISM).NS-CUK Seminar: J.H.Lee, Review on "Hyperbolic graph convolutional neural net...
NS-CUK Seminar: J.H.Lee, Review on "Hyperbolic graph convolutional neural net...Network Science Lab, The Catholic University of Korea
��
This document summarizes a research paper that introduces Hyperbolic Graph Convolutional Networks (HGCNs) to address limitations of previous Euclidean graph neural networks. HGCNs map node features to hyperbolic spaces and use a novel attention-based aggregation scheme to capture hierarchical structure. The paper presents HGCNs, evaluates them on citation networks, disease propagation trees, protein networks and flight networks, and finds they outperform Euclidean baselines for link prediction and node classification by learning more interpretable hierarchical representations.Sang_Graphormer.pdf
Sang_Graphormer.pdfNetwork Science Lab, The Catholic University of Korea
��
This document presents Graphormer, a Transformer-based model for graph representation learning. Graphormer achieves state-of-the-art performance on graph tasks by introducing three novel encodings: centrality encoding to capture node importance, spatial encoding to encode structural relations between nodes, and edge encoding to incorporate edge features. Experiments show Graphormer outperforms GNN baselines by over 10% on various graph datasets and tasks.NS-CUK Seminar: S.T.Nguyen, Review on "Do Transformers Really Perform Bad for...
NS-CUK Seminar: S.T.Nguyen, Review on "Do Transformers Really Perform Bad for...Network Science Lab, The Catholic University of Korea
��
This document presents Graphormer, a Transformer-based model for graph representation learning. Graphormer achieves state-of-the-art performance on graph tasks by introducing three novel encodings: centrality encoding to capture node importance, spatial encoding to encode structural relations using shortest path distance, and edge encoding using edge features. Experiments show Graphormer outperforms GNN baselines by over 10% on various graph datasets and leaderboards.NS-CUK Seminar: S.T.Nguyen, Review on "DeeperGCN: All You Need to Train Deepe...
NS-CUK Seminar: S.T.Nguyen, Review on "DeeperGCN: All You Need to Train Deepe...Network Science Lab, The Catholic University of Korea
��
The document discusses challenges faced by Graph Convolutional Networks (GCNs) when stacked deeply, such as vanishing gradients and limited representation power in large-scale graphs. It presents contributions including a novel generalized aggregation function, parameter tuning for GCN tasks, and enhanced GCN power through modified graph skip connections and normalization layers. The findings include the effectiveness of generalized mean-max aggregation functions and the importance of residual connections and dynamic parameter learning in improving GCN performance.S.M.Lee, Invited Talk on "Machine Learning-based Anomaly Detection"
S.M.Lee, Invited Talk on "Machine Learning-based Anomaly Detection"Network Science Lab, The Catholic University of Korea
��
Technical Report on "Lecture Quality Prediction using Graph Neural Networks"
Technical Report on "Lecture Quality Prediction using Graph Neural Networks"Network Science Lab, The Catholic University of Korea
��
Presentation for "Lecture Quality Prediction using Graph Neural Networks"
Presentation for "Lecture Quality Prediction using Graph Neural Networks"Network Science Lab, The Catholic University of Korea
��
NS-CUK Seminar: J.H.Lee, Review on "Graph Neural Networks with convolutional ...
NS-CUK Seminar: J.H.Lee, Review on "Graph Neural Networks with convolutional ...Network Science Lab, The Catholic University of Korea
��
NS-CUK Seminar: V.T.Hoang, Review on "Are More Layers Beneficial to Graph Tra...
NS-CUK Seminar: V.T.Hoang, Review on "Are More Layers Beneficial to Graph Tra...Network Science Lab, The Catholic University of Korea
��
NS-CUK Seminar: S.T.Nguyen Review on "Accurate learning of graph representati...
NS-CUK Seminar: S.T.Nguyen Review on "Accurate learning of graph representati...Network Science Lab, The Catholic University of Korea
��
Joo-Ho Lee: Topographic-aware wind forecasting system using multi-modal spati...
Joo-Ho Lee: Topographic-aware wind forecasting system using multi-modal spati...Network Science Lab, The Catholic University of Korea
��
Ho-Beom Kim: Detection of Influential Unethical Expressions through Construct...
Ho-Beom Kim: Detection of Influential Unethical Expressions through Construct...Network Science Lab, The Catholic University of Korea
��
NS-CUK Seminar: J.H.Lee, Review on "Hyperbolic graph convolutional neural net...
NS-CUK Seminar: J.H.Lee, Review on "Hyperbolic graph convolutional neural net...Network Science Lab, The Catholic University of Korea
��
NS-CUK Seminar: S.T.Nguyen, Review on "Do Transformers Really Perform Bad for...
NS-CUK Seminar: S.T.Nguyen, Review on "Do Transformers Really Perform Bad for...Network Science Lab, The Catholic University of Korea
��
NS-CUK Seminar: S.T.Nguyen, Review on "DeeperGCN: All You Need to Train Deepe...
NS-CUK Seminar: S.T.Nguyen, Review on "DeeperGCN: All You Need to Train Deepe...Network Science Lab, The Catholic University of Korea
��
Ad
5강 - 멀티모달 및 모듈화.pptx
- 1. Nam Gyu Jung Intelligent Information Processing Lab Dept. of Computer Engineering Gachon University E-mail: jng6017@gachon.ac.kr 2023.07.31
- 2. 1 멀티모달 데이터 모듈화 및 모델 통합
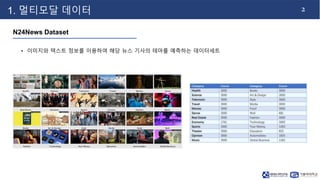
- 3. 2 1. 멀티모달 데이터 N24News Dataset • 이미지와 텍스트 정보를 이용하여 해당 뉴스 기사의 테마를 예측하는 데이터세트
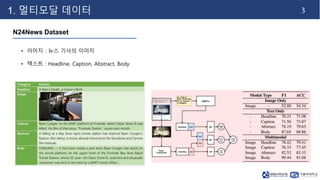
- 4. 3 1. 멀티모달 데이터 N24News Dataset • 이미지 : 뉴스 기사의 이미지 • 텍스트 : Headline, Caption, Abstract, Body
- 5. 4 1. 멀티모달 데이터 멀티모달 기반 모델 • 각각 분석을 위한 모델 적용 후 feature 단계 혹은 prediction 단계에서 융합하여 사용함 ViT features prediction Roberta features prediction
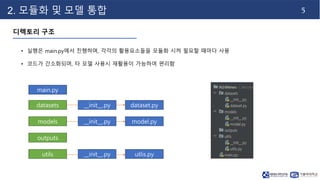
- 6. 5 2. 모듈화 및 모델 통합 디렉토리 구조 • 실행은 main.py에서 진행하며, 각각의 활용요소들을 모듈화 시켜 필요할 때마다 사용 • 코드가 간소화되며, 타 모델 사용시 재활용이 가능하여 편리함 main.py datasets dataset.py models model.py __init__.py __init__.py outputs utils utlis.py __init__.py
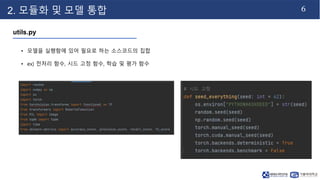
- 7. 6 2. 모듈화 및 모델 통합 utils.py • 모델을 실행함에 있어 필요로 하는 소스코드의 집합 • ex) 전처리 함수, 시드 고정 함수, 학습 및 평가 함수
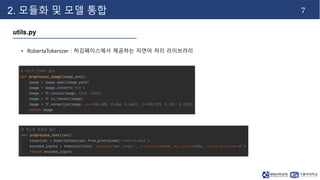
- 8. 7 2. 모듈화 및 모델 통합 utils.py • RobertaTokenizer : 허깅페이스에서 제공하는 자연어 처리 라이브러리
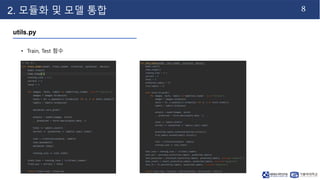
- 9. 8 2. 모듈화 및 모델 통합 utils.py • Train, Test 함수
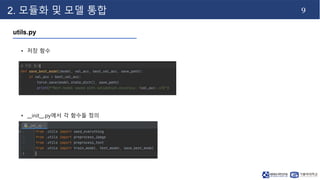
- 10. 9 2. 모듈화 및 모델 통합 utils.py • 저장 함수 • __init__.py에서 각 함수들 정의
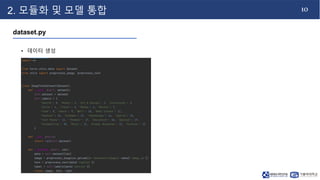
- 11. 10 2. 모듈화 및 모델 통합 dataset.py • 데이터 생성
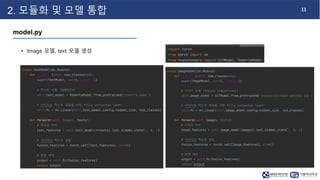
- 12. 11 2. 모듈화 및 모델 통합 model.py • Image 모델, text 모델 생성
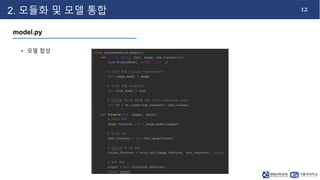
- 13. 12 2. 모듈화 및 모델 통합 model.py • 모델 합성
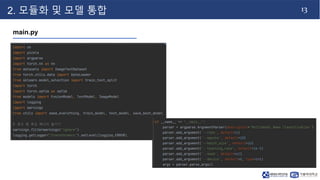
- 14. 13 2. 모듈화 및 모델 통합 main.py
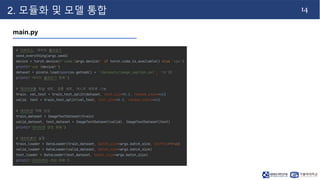
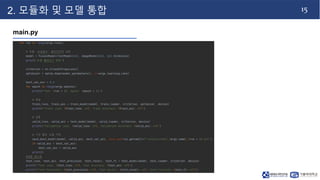
- 15. 14 2. 모듈화 및 모델 통합 main.py
- 16. 15 2. 모듈화 및 모델 통합 main.py