Ω‚’h: a semantic approach to recommending text advertisements for images
3 likes1,252 views

A Semantic Approach to Recommending Text Advertisements for Images - http://wanlab.poly.edu/recsys12/recsys/p179.pdf §ÚΩ‚’h§∑§Þ§∑§ø°£




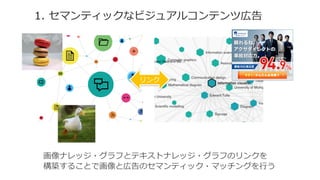
![•”•∏•Â•¢•Î?•≥•Û•∆•Û•ƒ?•ø©`•≤•√•»é⁄∏ʧŒÜñÓ}µ„
º»¥Ê§Œ? ÷∑®§Ω§Œ1
?? ª≠œÒ•¢•Œ•∆©`•∑•Á•Û
•ø©`•≤•√•»ª≠œÒ§¨”Χ®§È§Ï§Î§»°¢•È•Ÿ•Í•Û•∞§µ§Ï§øª≠œÒ§«”ñæö§∑§ø•‚•«•Î§«•¢•Œ•∆©`
•∑•Á•Û§Ú≥È≥ˆ°£
≥È≥ˆ§∑§ø•¢•Œ•∆©`•∑•Á•Û§Ú π§√§∆•Ï•≥•·•Û•…é⁄∏ʧڻ°§Í≥ˆ§π°£
•¢•Œ•∆©`•∑•Á•Û®P ?•∆•≠•π•»?•≥•Û•∆•Û•ƒ?•ø©`•≤•√•»§Œ•≠©`•Ô©`•…
[ÜñÓ}µ„]
?? ïrÈg§¨§´§´§Î
?? •¢•Œ•∆©`•∑•Á•Û§Œ∆∑Ÿ|§¨±£‘^§µ§Ï§ §§](https://image.slidesharecdn.com/asemanticapproachtorecommendingtext-150225045737-conversion-gate02/85/a-semantic-approach-to-recommending-text-advertisements-for-images-5-320.jpg)
![•”•∏•Â•¢•Î?•≥•Û•∆•Û•ƒ?•ø©`•≤•√•»é⁄∏ʧŒÜñÓ}µ„
º»¥Ê§Œ? ÷∑®§Ω§Œ2
?? ViCAD
◊Óœ»∂À§Œ•”•∏•Â•¢•Î?•≥•Û•∆•Û•ƒé⁄∏Ê•¢•Î•¥•Í•∫•ý°£
ª≠œÒÃÿè’ø’Èg§»•∆•≠•π•»Ãÿè’ø’Èg§Ú•÷•Í•√•∏§π§ÎÃÿè’ÐûìQ•‚•«•Î§Ú§ƒ§Ø§Î°£
∏˜é⁄∏Ê∫Ú—a§»•∆•≠•π•»§»§ŒÈvþB–‘§Ú?—‘’Z•‚•«•Î§«Õ∆∂®§π§Î°£
http://www.aaai.org/ocs/index.php/AAAI/AAAI10/paper/viewFile/1757/2203
?°°[ÜñÓ}µ„]
?? ª≠œÒ•¢•Œ•∆©`•∑•Á•Û§Ë§Í§œ¡º¡º§§•—•’•©©`•Þ•Û•π
?? …Ã?”√§« π§®§Î§€§…§Œæ´»∑§µ§œ≥ˆ§ª§ §§°£](https://image.slidesharecdn.com/asemanticapproachtorecommendingtext-150225045737-conversion-gate02/85/a-semantic-approach-to-recommending-text-advertisements-for-images-6-320.jpg)
































More Related Content
Similar to Ω‚’h: a semantic approach to recommending text advertisements for images (6)
Ω‚’h: a semantic approach to recommending text advertisements for images
- 1. Ω‚’h: A SEMANTIC APPROACH TO RECOMMENDING TEXT ADVERTISEMENTS FOR IMAGES ª≠œÒ§Àåù§π§Îé⁄∏Ê•Ï•≥•·•Û•…§Œ•ª•Þ•Û•∆•£•√•Ø?•¢•◊•Ì©`•¡
- 2. §≥§Œ•π•È•§•…§À§ƒ§§§∆ §≥§Œ•π•È•§•…§œ A Semantic Approach to Recommending Text Advertisements for Images Weinan Zhang, Li Tian, Xinruo Sun, Haofen Wang, Yong Yu. Dept. of Computer Science and Engineering. Shanghai Jiao Tong University. §Ú∫Õ‘U?Ω‚’h§∑§ø§‚§Œ§«§π°£
- 3. §≥§Œ’쌃§À§ƒ§§§∆ ?? ÷¯’þ: Weinan Zhang …œ∫£ΩªÕ®¥Û—ß°˙UCLÀ˘ Ù°£ —–æø∑÷“∞§œRTB§‰•«•£•π•◊•Ï•§é⁄∏ʧ §…°£ §≥§Œ’쌃§ŒÀ˚§À§‚ °∏Optiomal Real-Time Bidding for Display Advertising°π § §…§Ú∞k±Ì°£ ?? ’쌃: ACM§Œ•Ï•≥•·•Û•…•∑•π•∆•ý•´•Û•’•°•Ï•Û•π2012§À÷≥ˆ§µ§Ï§ø §‚§Œ°£ °˙? Пp§œ§∑§∆§§§ §§°£
- 4. ∏≈“™ ◊ÓΩ¸§ŒWeb•µ•§•» ?? Facebook ?? Flickr èæ¿¥§Œ•≥•Û•∆•Û•ƒ?•ø©`•≤•√•»é⁄∏Ê(contextual target advertising)§«§œ°¢•Ê©`•∂§À‘V«Û§π§Îé⁄∏ʧڱÌ? 槫§≠§ §§°£ ?¥Û¡ø¡ø§Œª≠œÒ§»…Ÿ§∑§Œ•∆•≠•π•»
- 5. •”•∏•Â•¢•Î?•≥•Û•∆•Û•ƒ?•ø©`•≤•√•»é⁄∏ʧŒÜñÓ}µ„ º»¥Ê§Œ? ÷∑®§Ω§Œ1 ?? ª≠œÒ•¢•Œ•∆©`•∑•Á•Û •ø©`•≤•√•»ª≠œÒ§¨”Χ®§È§Ï§Î§»°¢•È•Ÿ•Í•Û•∞§µ§Ï§øª≠œÒ§«”ñæö§∑§ø•‚•«•Î§«•¢•Œ•∆©` •∑•Á•Û§Ú≥È≥ˆ°£ ≥È≥ˆ§∑§ø•¢•Œ•∆©`•∑•Á•Û§Ú π§√§∆•Ï•≥•·•Û•…é⁄∏ʧڻ°§Í≥ˆ§π°£ •¢•Œ•∆©`•∑•Á•Û®P ?•∆•≠•π•»?•≥•Û•∆•Û•ƒ?•ø©`•≤•√•»§Œ•≠©`•Ô©`•… [ÜñÓ}µ„] ?? ïrÈg§¨§´§´§Î ?? •¢•Œ•∆©`•∑•Á•Û§Œ∆∑Ÿ|§¨±£‘^§µ§Ï§ §§
- 7. •”•∏•Â•¢•Î?•≥•Û•∆•Û•ƒ?•ø©`•≤•√•»é⁄∏ʧŒÜñÓ}µ„ π≤Õ®§ŒÜñÓ} 1. ?ª≠œÒ§Œ•ø•∞§»é⁄∏ʧŒ∑÷≤º§¨ÆêÆê§ §Î ?°°◊ÛáÌProblem1 ?°°°∏Pleurodont ?Agama°π(•§•∞•¢• §Œ√˚ ?°°«∞)§À◊Óþm§ é⁄∏ʧœ≥ˆ§ª§ §§°£ 2. ?“‚Œ∂µƒ•þ•π•Þ•√•¡ ?°°◊ÛáÌProblem2 ?°°°∏Tiger°π§´§È ?°°°∏Tiger ?Woods°π§‰°∏Missouri ?Tigers ?°° ?Apparel°π§¨≥ˆ§∆§≠§∆§∑§Þ§¶°£
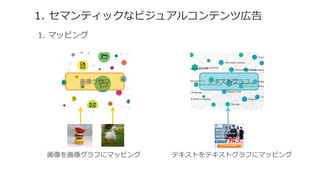
- 11. 1. •ª•Þ•Û•∆•£•√•Ø§ •”•∏•Â•¢•Î•≥•Û•∆•Û•ƒé⁄∏Ê 1. ?•Þ•√•‘•Û•∞ •∆•≠•π•»•∞•È•’ª≠œÒ•∞•È•’ ª≠œÒ§Úª≠œÒ•∞•È•’§À•Þ•√•‘•Û•∞ •∆•≠•π•»§Ú•∆•≠•π•»•∞•È•’§À•Þ•√•‘•Û•∞
- 13. 1. •ª•Þ•Û•∆•£•√•Ø§ •”•∏•Â•¢•Î•≥•Û•∆•Û•ƒé⁄∏Ê •Ø•Ì•π?• •Ï•√•∏?•Þ•√•¡•Û•∞Èv ˝¶¨ ¶∑: ?ª≠œÒ§´§Èª≠œÒ•∞•È•’§Œ•Œ©`•…§ÿ§Œ•Þ•√•‘•Û•∞ ¶µ: ?é⁄∏ʧ´§È•∆•≠•π•»•∞•È•’§Œ•Œ©`•…§ÿ§Œ•Þ•√•‘•Û•∞
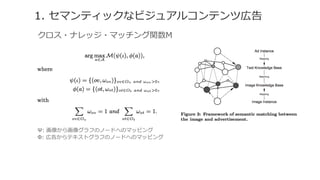
- 15. 2. ?∂®¡x •∆•≠•π•»Ãÿè’ø’Èg é⁄∏Êø’Èg(ß°)§»é⁄∏Ê(ß—) ∏˜é⁄∏ʧœ•∆•≠•π•»§ŒÃÿè’•Ÿ•Ø•»•Î§Àåù§∑°¢ ? ti: •∆•≠•π•»§ŒÃÿè’ m: Ãÿè’¡ø :ß—§À§™§±§Î•∆•≠•π•»Ãÿè’tk§ŒÓl∂» ª≠œÒÃÿè’ø’Èg ª≠œÒø’Èg(¶©)§»ª≠œÒ(¶…) ∏˜ª≠œÒ§œª≠œÒÃÿè’•Ÿ•Ø•»•Î§Àåù§∑°¢ ? vi: ª≠œÒ§ŒÃÿè’ n: Ãÿè’¡ø :i§À§™§±§Îª≠œÒÃÿè’vk§ŒÓl∂»
- 16. 2. ?∂®¡x •∆•≠•π•»• •Ï•√•∏•∞•È•’ Ot§œ•Œ©`•…ºØ∫œ Et§œ•®•√•∏ Ot: •Œ©`•… Et: •®•√•∏ ª≠œÒ• •Ï•√•∏•∞•È•’ Ov§œ•Œ©`•…ºØ∫œ Ev§œ•®•√•∏ Ov: •Œ©`•… Ev: •®•√•∏
- 18. 3. • •Ï•√•∏?•Ÿ©`•π ?•∆•≠•π•»?• •Ï•√•∏•Ÿ©`•π ?°°°˙ ?Wikipedia ?ª≠œÒ• •Ï•√•∏•Ÿ©`•π ?°°°˙ ?ImageNet/WordNet ?•÷•Í•√•∏?• •Ï•√•∏ ?°°°˙ ?YAGO
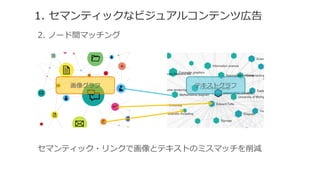
- 21. 4. •Þ•√•‘•Û•∞£¶•Þ•√•¡•Û•∞ ¶µ???•∆•≠•π•»?•Þ•√•‘•Û•∞Èv ˝ ?°°é⁄∏ʧŒ¬‘¬‘’Z§ §…§ŒÃÿ ‚±Ì¨F§»Wikipedia§Ú•Þ•√•¡•Û•∞§π§Î§ø§·§À ?°°ESA•¢•Î•¥•Í•∫•ý§Ú π?”√°£ ?°° ?°°°˙ ?TFIDF÷ÿ§þ∏∂§± ?°¡ ?Ól∂»∂» ?°°°˘ESA(Explicit ?Semantic ?Analysis)§À§ƒ§§§∆§œœ¬”õ≤Œ’’ ?°°?°°http://www.cs.technion.ac.il/~°´gabr/resources/code/esa/esa.html é⁄∏ʺØ∫œƒ⁄§À§™§±§ÎÖg’Z£®•’•Ï©`•∫£©§ŒÓl∂»∂»
- 22. 4. •Þ•√•‘•Û•∞£¶•Þ•√•¡•Û•∞ ¶◊???ª≠œÒ?•Þ•√•‘•Û•∞Èv ˝ ?°°ImageNet§Œª≠œÒ§»•´•∆•¥•Í©`§ŒÎAå”òã‘ϧڔñæö•«©`•ø§»§∑°¢ ?°°÷ÿ?–ƒ∑®§À§Ë§Î§Œ•≥•µ•§•ÛÓêÀ∆Èv ˝¶»(¶…, ?ßýv)§Ú π§√§∆Ω¸À∆Çé§Úµ√§Î°£ ?°°°˙ ?ågÚY§«§œk=7, ?¶ÿ=0.6§¨¡º¡º§§•—•’•©©`•Þ•Û•π§¿§√§ø°£ ¶ÿ§œ◊Êœ»•Œ©`•…§Œ÷ÿ§þ ov§Œ◊Êœ»
- 23. 4. •Þ•√•‘•Û•∞£¶•Þ•√•¡•Û•∞ ¶¨???•Ø•Ì•π?• •Ï•√•∏•Ÿ©`•π?•Þ•√•¡•Û•∞Èv ˝ ?°°2§ƒ§Œ?∑Ω∑®§ÚågÚY°£ ?°°?LOD ?Descroption ?Overlap(LODDO) ?•Í•Û•Ø•…•™©`•◊•Û•«©`•ø§Ú 𧶠?°°?°°http://rd.springer.com/chapter/10.1007/978-©\??3-©\??642-©\??29923-©\??0_?18#page-©\??1 ?°°?Hierarchy-©\??based ?Matching ?ÎAå”–Õ∑÷Óê•Ÿ©`•π§Œ•ª•Þ•Û•∆•£•√•Ø•Þ•√•¡•Û•∞
- 25. 5. •¢•Î•¥•Í•∫•ý§Þ§»§· ?? •™•’•È•§•Û•◊•Ì•ª•π£∫ 1.? é⁄∏ʧ»Wikipedia§Œ•Œ©`•…§ŒÈvþB∂»∂»§Ú”ãÀ„§∑§∆§™§Ø°£ 2.? ESA§À§Ë§Íé⁄∏ʧ´§È∏˜•Œ©`•…§ÿ§ŒƒÊ•§•Û•«•√•Ø•π§Úòã∫B°£ °˘ó À˜À˜•®•Û•∏•Û§«?—‘§¶•…•≠•Â•·•Û•»§´§È•≠©`•Ô©`•…§ÿ§Œ•§•Û•«•√•Ø•π ?? •™•Û•È•§•Û•◊•Ì•ª•π£∫ 1.? åùœÛª≠œÒ§Úi§»§∑§∆°¢ImageNet§Œ•Œ©`•…k §Úµ√§Î§ø§·§À¶◊(i)§Ú§Ë§÷°£ 2.? YAGO§«ImageNet§Œ•Œ©`•…§» Wikipedia§Œ•Œ©`•…§Ú•Í•Û•Ø§π§Î°£ 3.? Wikipedia•Œ©`•…§À•Í•Û•Ø§µ§Ï§øé⁄∏Ê •Í•π•»§Ú»°µ√§π§Î°£L 4.? ¶¨§«Lƒ⁄§Œé⁄∏ʧ»åùœÛª≠œÒi§ŒÈvþB∂»∂»§Ú”ãÀ„§π§Î°£ 5.? é⁄∏Ê•Í•π•»§À•È•Û•Ø§Ú§ƒ§±§Î°£
- 27. ågÚY ?±»ð^§∑§ø•¢•Î•¥•Í•∫•ý ?? Annotation ?+ ?Search(AS) ª≠œÒ•¢•Œ•∆©`•∑•Á•Û ?? Annotation ?+ ?Expansion ?+ ?Search(ASEx) ª≠œÒ•¢•Œ•∆©`•∑•Á•Û•ª•Þ•Û•∆•£•√•Øíàèà ?? ViCAD °˘«∞ ˆ ?? ImageAdSense(§≥§Œ’ì’ì?Œƒ§Œ? ÷∑®) iAdSense-©\??LODDO ?°°iAdSense§«•Ø•Ì•π• •Ï•√•∏•Þ•√•¡•Û•∞§ÀLODDO§Ú π?”√°£ iAdSense-©\??Tree ?°°iAdSense§«•Ø•Ì•π• •Ï•√•∏•Þ•√•¡•Û•∞§ÀÎAå”–Õ∑÷Óê•Þ•√•¡§Ú π?”√°£ iAdSense-©\??OneLayer?°°iAdSense§«•Ø•Ì•π• •Ï•√•∏•Þ•√•¡•Û•∞§Ú π?”√§∑§ §§°£
- 28. ågÚY ‘uÅ˝?∑Ω∑® ?? 6?»À§Œ—ß?…˙§ÀÖf?¡¶¡¶§Ú“¿Óm°£ ?? …Ÿ§ §Ø§»§‚2?»À“‘…œ§¨°∏é⁄∏ʧ»ª≠œÒ§ÀÈvþB§¨§¢§Î°π§»≈–∂®§∑§øàˆ∫œ §À•´•¶•Û•»1°¢§Ω§¶§«§ §§àˆ∫œ§œ0§»§π§Î°£ ?? ª≠œÒ§»é⁄∏ʧŒ•⁄•¢§«•π•≥•¢∆Ωæ˘§Ú»°§Î°£ ?? P@n(precision ?at ?position ?n)§«‘uÅ˝°£(n§œtop-©\??n) ¶–i§œ°¢åùœÛª≠œÒ§»i∑¨?ƒø§Œ•Ï•≥•·•Û•…é⁄∏ʧŒ•⁄•¢§Œ∆Ωæ˘•π•≥•¢
- 29. ΩYπ˚ iAdSense-©\??OneLayer§œÀ˚§ŒiAdsense§À?±»§Ÿ§∆ ˝Ç駨µÕ§§ °˙ ?•Ø•Ì•π• •Ï•√•∏•Þ•√•¡•Û•∞§¨±ÿ“™ ViCAD§œAS§Ë§ÍÉû§Ï§∆§§§Î§¨iAdSense§À§œ¡”¡”§Î°£ °˙ ?ª≠œÒ§Œ•ø•∞÷–§À•Œ•§•∫§¨∂ý§Ø°¢òã?Œƒ•Þ•√•¡§»§§§¶“‚Œ∂§«§œAS§»Õ¨§∏ÜñÓ}§Ú±ß§®§∆§§§Î°£ iAdSense-©\??LODDO ?> ?ASEx ?16.4%°¸ iAdSense-©\??LODDO ?> ?ViCAD ?20.7%°¸