A Star search algorithm with example (num)
Download as PPTX, PDF0 likes8 views
A star search
1 of 24
Download to read offline


![Optimality of A* Search Algorithm
ï‚´ Heuristic may be:
ï‚´ h(n) > actual cost
ï‚´ h(n) = actual cost
ï‚´ h(n) < actual cost
ï‚´ (1) h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not
possible]
ï‚´ (2) h(n) = actual cost [Best case scenario, if h(n) approximates actual cost, searching
uses minimum of node to the goal]
ï‚´ (3) h(n) < actual cost [ Admissible, Consistent Heuristics]](https://image.slidesharecdn.com/astarexample-250209175738-f235cc9c/85/A-Star-search-algorithm-with-example-num-12-320.jpg)
![Optimality of A* Search Algorithm
h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not
possible]](https://image.slidesharecdn.com/astarexample-250209175738-f235cc9c/85/A-Star-search-algorithm-with-example-num-13-320.jpg)
![Optimality of A* Search Algorithm
h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not
possible]](https://image.slidesharecdn.com/astarexample-250209175738-f235cc9c/85/A-Star-search-algorithm-with-example-num-14-320.jpg)
![Optimality of A* Search Algorithm
h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not
possible]
b………….> dest and cost (7+2+0=9) , or ……….>a and cost (2+9=11)](https://image.slidesharecdn.com/astarexample-250209175738-f235cc9c/85/A-Star-search-algorithm-with-example-num-15-320.jpg)
![Optimality of A* Search Algorithm
h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not
possible]
b………….> dest and cost (7+2+0=9) , or ……….>a and cost (2+9=11)
Actual cost from Sïƒ aïƒ bïƒ dest =2+3+2=7
h(n)=10 > actual cost = 7](https://image.slidesharecdn.com/astarexample-250209175738-f235cc9c/85/A-Star-search-algorithm-with-example-num-16-320.jpg)








Recommended
Lecture 14 Heuristic Search-A star algorithm
Lecture 14 Heuristic Search-A star algorithmHema Kashyap
Ìı
A* is a search algorithm that finds the shortest path through a graph to a goal state. It combines the best aspects of Dijkstra's algorithm and best-first search. A* uses a heuristic function to evaluate the cost of a path passing through each state to guide the search towards the lowest cost goal state. The algorithm initializes the start state, then iteratively selects the lowest cost node from its open list to expand, adding successors to the open list until it finds the goal state. A* is admissible, complete, and optimal under certain conditions relating to the heuristic function and graph structure.
Informed-search TECHNIQUES IN ai ml data science
Informed-search TECHNIQUES IN ai ml data sciencedevvpillpersonal
Ìı
Informed search algorithms use problem-specific heuristics to improve search efficiency over uninformed methods. The most common informed methods are best-first search, A* search, and memory-bounded variants like RBFS and SMA*. A* is optimal if the heuristic is admissible for tree searches or consistent for graph searches. Heuristics provide an estimate of the remaining cost to the goal and can significantly speed up search. Common techniques for generating heuristics include Manhattan distance.Heuristic Search in Artificial Intelligence | Heuristic Function in AI | Admi...
Heuristic Search in Artificial Intelligence | Heuristic Function in AI | Admi...RahulSharma4566
Ìı
Heuristic search uses heuristic functions to help optimize problem solving by trying to find solutions in the fewest steps or lowest cost. A heuristic function estimates the cost of reaching the goal state from any given node. There are two types of heuristic functions: admissible functions, which never overestimate cost, and non-admissible functions, which may overestimate cost. Admissible heuristics help guide search towards optimal solutions.2-Heuristic Search.ppt
2-Heuristic Search.pptMIT,Imphal
Ìı
Heuristic search techniques like A* use heuristics to guide the search for a solution. A* balances the cost to reach a node and an estimate of the remaining cost to reach the goal. If the heuristic is admissible (does not overestimate cost), A* is guaranteed to find an optimal solution. A worked example demonstrates A* finding the optimal path through a maze using Manhattan distance as the heuristic.AI Greedy and A-STAR Search
AI Greedy and A-STAR SearchAndrew Ferlitsch
Ìı
Abstract: This PDSG workship introduces basic concepts on Greedy and A-STAR search. Examples are given pictorially, as pseudo code and in Python.
Level: Fundamental
Requirements: Should have prior familiarity with Graph Search. No prior programming knowledge is required. Jarrar.lecture notes.aai.2011s.ch4.informedsearch
Jarrar.lecture notes.aai.2011s.ch4.informedsearchPalGov
Ìı
This document summarizes various informed search algorithms including greedy best-first search, A* search, and memory-bounded heuristic search algorithms like recursive best-first search and simple memory-bounded A* search. It discusses how heuristics can be used to guide the search towards optimal solutions more efficiently. Admissible and consistent heuristics are defined and their role in guaranteeing optimality of A* search is explained. Methods for developing effective heuristic functions are also presented.BCS515B Module3 vtu notes : Artificial Intelligence Module 3.pdf
BCS515B Module3 vtu notes : Artificial Intelligence Module 3.pdfSwetha A
Ìı
BCS515B Module3 vtu notes :
Artificial Intelligence 
Heuristic Searching: A* Search
Heuristic Searching: A* SearchIOSR Journals
Ìı
A* search is an algorithm that finds the shortest path between a starting node and a goal node. It uses a heuristic function to determine the order in which it explores nodes. The heuristic estimates the cost to get from each node to the goal. A* search explores nodes with the lowest total cost, which is the cost to reach the node plus the heuristic estimate to reach the goal from that node. A* search is admissible and optimal if the heuristic is admissible, meaning it never overestimates the actual cost. While efficient, A* search can require significant memory for large search problems. Future work could apply A* search techniques to pathfinding for robots.A* and Min-Max Searching Algorithms in AI , DSA.pdf
A* and Min-Max Searching Algorithms in AI , DSA.pdfCS With Logic
Ìı
A* and Min-Max Searching Algorithms in AI. Search algorithms are algorithms designed to search for or retrieve elements from a data structure, where they are stored. It is a searching algorithm that is used to find the shortest path between an initial and a final point. Mini-Max algorithm is a recursive or backtracking algorithm that is used in decision-making and game theory.Apriori algorithm
Apriori algorithmnouraalkhatib
Ìı
The document discusses the Apriori algorithm and modifications using hashing and graph-based approaches for mining association rules from transactional datasets. The Apriori algorithm uses multiple passes over the data to count support for candidate itemsets and prune unpromising candidates. Hashing maps itemsets to integers for efficient counting of support. The graph-based approach builds a tree structure linking frequent itemsets. Both modifications aim to improve efficiency over the original Apriori algorithm. The document also notes challenges in designing perfect hash functions for this application.
Search 2
Search 2Tribhuvan University
Ìı
Heuristic search techniques use problem-specific knowledge beyond what is given in the problem statement to guide the search for a solution more efficiently. This document discusses various heuristic search algorithms including best-first search, greedy best-first search, A* search, local search techniques like hill-climbing and simulated annealing, and genetic algorithms. Key aspects like admissibility and monotonicity of heuristics that allow algorithms like A* to find optimal solutions are also covered. Examples of applying these techniques to problems like the 8-puzzle and n-queens are provided.Heuristic Searching Algorithms Artificial Intelligence.pptx
Heuristic Searching Algorithms Artificial Intelligence.pptxSwagat Praharaj
Ìı
The document discusses various heuristic search algorithms used in artificial intelligence including hill climbing, A*, best first search, and mini-max algorithms. It provides descriptions of each algorithm, including concepts, implementations, examples, and applications. Key points covered include how hill climbing searches for better states, how A* uses a cost function to find optimal paths, and how best first search uses a priority queue to search nodes in order of estimated cost to reach the goal.Searchadditional2
Searchadditional2chandsek666
Ìı
The document discusses various informed search strategies including best-first search, greedy best-first search, A* search, and local search algorithms like hill-climbing search and simulated annealing search. It explains how heuristic functions can help guide search toward solutions more efficiently. Key aspects covered are how A* search uses an evaluation function f(n) = g(n) + h(n) to expand the most promising nodes first, and how hill-climbing search gets stuck at local optima but simulated annealing incorporates randomness to help escape them.Informed Search.pptx
Informed Search.pptxMohanKumarP34
Ìı
The document describes a lecture on informed search strategies for artificial intelligence given at Sri Krishna College of Engineering and Technology. It discusses various informed search techniques including best-first search, greedy search, A* search, and heuristic functions. Completing the lecture will help students understand search strategies and solve problems using strategic approaches. Key concepts covered include heuristic search, local search and optimization techniques like hill-climbing, simulated annealing and genetic algorithms.Game Paper
Game PaperSiddharth Gupta
Ìı
This document summarizes a student project that implemented the A* pathfinding algorithm using a heap data structure to improve performance in a 2D Pacman game. The project aimed to make the AI of enemy ghosts more challenging by increasing the efficiency of the pathfinding algorithm. It describes A* pathfinding and how using a heap data structure to store node data improves performance over the traditional stack structure by decreasing search time. Experimental results showed that implementing A* with a heap reduced pathfinding time compared to without a heap. The conclusion states that machine learning for pathfinding was not used due to the time required for development and potential unpredictability in games.A* Algorithm
A* Algorithmmaharajdey
Ìı
The document describes the A* algorithm, a pathfinding algorithm that is an improvement on Dijkstra's algorithm. A* uses a heuristic function to estimate the cost of the shortest path to the goal, in order to guide the search towards the most promising paths. This makes it more efficient than Dijkstra's algorithm for large graphs. The heuristic must be admissible, meaning it cannot overestimate costs, to guarantee an optimal solution. Consistent heuristics also guarantee optimality. A* minimizes the cost function f(n)=g(n)+h(n), where g(n) is the cost to reach node n and h(n) is the heuristic estimate from n to the goal. Examples are givenHeuristic Search, Best First Search.pptx
Heuristic Search, Best First Search.pptxdevhamnah
Ìı
Artificial Intelligence - Heuristic Search also called Informed Search Strategies

3. Coprocessor.ppt
3. Coprocessor.pptMDTahsinAmin3
Ìı
Coprocessors were introduced in the 1970s to offload floating-point arithmetic operations from main processors. A coprocessor is a specialized circuit that performs tasks like floating-point operations faster than the main processor. Coprocessors extend capabilities and increase processing speed. They are used for tasks the main processor cannot perform directly, like trigonometric or logarithmic functions. Coprocessors interface with the main processor via instruction monitoring or command registers, and perform calculations to aid the main processor. Common coprocessors include the 8087, 80287, and 80387 which added floating-point support to processors like the 8086, 80286, and 80386 respectively.82C55 PPI (1).ppt
82C55 PPI (1).pptMDTahsinAmin3
Ìı
The 82C55 is a programmable peripheral interface chip that can interface TTL-compatible I/O devices to microprocessors. It has 24 programmable I/O pins grouped into three ports (A, B, C) and can operate in three modes to control input, output, and handshaking signals. Mode 0 provides simple I/O, mode 1 adds strobed I/O, and mode 2 uses port C for bi-directional port A control. The 82C55 is commonly used to interface keyboards and printers to PCs and can control a stepper motor by energizing its coils in sequence through port groups.7chap007_data modeling and analysis_14-7-19.ppt
7chap007_data modeling and analysis_14-7-19.pptMDTahsinAmin3
Ìı
This document outlines the key concepts of data modeling and entity relationship diagrams as presented in Chapter 7 of the textbook "Systems Analysis and Design Methods" by Whitten, Bentley, and Dittman. It defines core data modeling terms like entities, attributes, relationships, keys, and normalization. It provides examples of how these concepts are represented in entity relationship diagrams and relational database design. The chapter aims to teach readers how to logically model systems data through entity relationship diagrams.3.1measure of central tendency.pptx
3.1measure of central tendency.pptxMDTahsinAmin3
Ìı
The document discusses different measures of central tendency including the mean, median, and mode. It defines central tendency as a central value that is representative of a data set and is calculated using all values while being free from extremes. The document notes that measures of central tendency ensure easy calculation and eligibility for further mathematical treatment. It then lists common measures like the arithmetic mean, geometric mean, harmonic mean, median, and mode.Chapter-8_Multiplexing.pptx
Chapter-8_Multiplexing.pptxMDTahsinAmin3
Ìı
Frequency division multiplexing (FDM) allows multiple signals to be transmitted simultaneously across a single communication channel by assigning each signal a unique frequency band. At the receiving end, filters separate the signals by frequency for delivery. FDM is commonly used in telephone networks and cellular systems. Time division multiplexing (TDM) transmits signals in sequential time slots allocated in a repeating frame. Synchronous TDM pre-assigns slots while statistical TDM dynamically allocates slots. TDM is used in digital transmission and SONET networks. Multiplexing techniques improve bandwidth utilization by allowing multiple users to share transmission capacity.Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...
Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...J. Agricultural Machinery
Ìı
Optimal use of resources, including energy, is one of the most important principles in modern and sustainable agricultural systems. Exergy analysis and life cycle assessment were used to study the efficient use of inputs, energy consumption reduction, and various environmental effects in the corn production system in Lorestan province, Iran. The required data were collected from farmers in Lorestan province using random sampling. The Cobb-Douglas equation and data envelopment analysis were utilized for modeling and optimizing cumulative energy and exergy consumption (CEnC and CExC) and devising strategies to mitigate the environmental impacts of corn production. The Cobb-Douglas equation results revealed that electricity, diesel fuel, and N-fertilizer were the major contributors to CExC in the corn production system. According to the Data Envelopment Analysis (DEA) results, the average efficiency of all farms in terms of CExC was 94.7% in the CCR model and 97.8% in the BCC model. Furthermore, the results indicated that there was excessive consumption of inputs, particularly potassium and phosphate fertilizers. By adopting more suitable methods based on DEA of efficient farmers, it was possible to save 6.47, 10.42, 7.40, 13.32, 31.29, 3.25, and 6.78% in the exergy consumption of diesel fuel, electricity, machinery, chemical fertilizers, biocides, seeds, and irrigation, respectively. 

More Related Content
Similar to A Star search algorithm with example (num) (13)
Heuristic Searching: A* Search
Heuristic Searching: A* SearchIOSR Journals
Ìı
A* search is an algorithm that finds the shortest path between a starting node and a goal node. It uses a heuristic function to determine the order in which it explores nodes. The heuristic estimates the cost to get from each node to the goal. A* search explores nodes with the lowest total cost, which is the cost to reach the node plus the heuristic estimate to reach the goal from that node. A* search is admissible and optimal if the heuristic is admissible, meaning it never overestimates the actual cost. While efficient, A* search can require significant memory for large search problems. Future work could apply A* search techniques to pathfinding for robots.A* and Min-Max Searching Algorithms in AI , DSA.pdf
A* and Min-Max Searching Algorithms in AI , DSA.pdfCS With Logic
Ìı
A* and Min-Max Searching Algorithms in AI. Search algorithms are algorithms designed to search for or retrieve elements from a data structure, where they are stored. It is a searching algorithm that is used to find the shortest path between an initial and a final point. Mini-Max algorithm is a recursive or backtracking algorithm that is used in decision-making and game theory.Apriori algorithm
Apriori algorithmnouraalkhatib
Ìı
The document discusses the Apriori algorithm and modifications using hashing and graph-based approaches for mining association rules from transactional datasets. The Apriori algorithm uses multiple passes over the data to count support for candidate itemsets and prune unpromising candidates. Hashing maps itemsets to integers for efficient counting of support. The graph-based approach builds a tree structure linking frequent itemsets. Both modifications aim to improve efficiency over the original Apriori algorithm. The document also notes challenges in designing perfect hash functions for this application.Search 2
Search 2Tribhuvan University
Ìı
Heuristic search techniques use problem-specific knowledge beyond what is given in the problem statement to guide the search for a solution more efficiently. This document discusses various heuristic search algorithms including best-first search, greedy best-first search, A* search, local search techniques like hill-climbing and simulated annealing, and genetic algorithms. Key aspects like admissibility and monotonicity of heuristics that allow algorithms like A* to find optimal solutions are also covered. Examples of applying these techniques to problems like the 8-puzzle and n-queens are provided.Heuristic Searching Algorithms Artificial Intelligence.pptx
Heuristic Searching Algorithms Artificial Intelligence.pptxSwagat Praharaj
Ìı
The document discusses various heuristic search algorithms used in artificial intelligence including hill climbing, A*, best first search, and mini-max algorithms. It provides descriptions of each algorithm, including concepts, implementations, examples, and applications. Key points covered include how hill climbing searches for better states, how A* uses a cost function to find optimal paths, and how best first search uses a priority queue to search nodes in order of estimated cost to reach the goal.Searchadditional2
Searchadditional2chandsek666
Ìı
The document discusses various informed search strategies including best-first search, greedy best-first search, A* search, and local search algorithms like hill-climbing search and simulated annealing search. It explains how heuristic functions can help guide search toward solutions more efficiently. Key aspects covered are how A* search uses an evaluation function f(n) = g(n) + h(n) to expand the most promising nodes first, and how hill-climbing search gets stuck at local optima but simulated annealing incorporates randomness to help escape them.Informed Search.pptx
Informed Search.pptxMohanKumarP34
Ìı
The document describes a lecture on informed search strategies for artificial intelligence given at Sri Krishna College of Engineering and Technology. It discusses various informed search techniques including best-first search, greedy search, A* search, and heuristic functions. Completing the lecture will help students understand search strategies and solve problems using strategic approaches. Key concepts covered include heuristic search, local search and optimization techniques like hill-climbing, simulated annealing and genetic algorithms.Game Paper
Game PaperSiddharth Gupta
Ìı
This document summarizes a student project that implemented the A* pathfinding algorithm using a heap data structure to improve performance in a 2D Pacman game. The project aimed to make the AI of enemy ghosts more challenging by increasing the efficiency of the pathfinding algorithm. It describes A* pathfinding and how using a heap data structure to store node data improves performance over the traditional stack structure by decreasing search time. Experimental results showed that implementing A* with a heap reduced pathfinding time compared to without a heap. The conclusion states that machine learning for pathfinding was not used due to the time required for development and potential unpredictability in games.A* Algorithm
A* Algorithmmaharajdey
Ìı
The document describes the A* algorithm, a pathfinding algorithm that is an improvement on Dijkstra's algorithm. A* uses a heuristic function to estimate the cost of the shortest path to the goal, in order to guide the search towards the most promising paths. This makes it more efficient than Dijkstra's algorithm for large graphs. The heuristic must be admissible, meaning it cannot overestimate costs, to guarantee an optimal solution. Consistent heuristics also guarantee optimality. A* minimizes the cost function f(n)=g(n)+h(n), where g(n) is the cost to reach node n and h(n) is the heuristic estimate from n to the goal. Examples are givenHeuristic Search, Best First Search.pptx
Heuristic Search, Best First Search.pptxdevhamnah
Ìı
Artificial Intelligence - Heuristic Search also called Informed Search StrategiesMore from MDTahsinAmin3 (6)
3. Coprocessor.ppt
3. Coprocessor.pptMDTahsinAmin3
Ìı
Coprocessors were introduced in the 1970s to offload floating-point arithmetic operations from main processors. A coprocessor is a specialized circuit that performs tasks like floating-point operations faster than the main processor. Coprocessors extend capabilities and increase processing speed. They are used for tasks the main processor cannot perform directly, like trigonometric or logarithmic functions. Coprocessors interface with the main processor via instruction monitoring or command registers, and perform calculations to aid the main processor. Common coprocessors include the 8087, 80287, and 80387 which added floating-point support to processors like the 8086, 80286, and 80386 respectively.82C55 PPI (1).ppt
82C55 PPI (1).pptMDTahsinAmin3
Ìı
The 82C55 is a programmable peripheral interface chip that can interface TTL-compatible I/O devices to microprocessors. It has 24 programmable I/O pins grouped into three ports (A, B, C) and can operate in three modes to control input, output, and handshaking signals. Mode 0 provides simple I/O, mode 1 adds strobed I/O, and mode 2 uses port C for bi-directional port A control. The 82C55 is commonly used to interface keyboards and printers to PCs and can control a stepper motor by energizing its coils in sequence through port groups.7chap007_data modeling and analysis_14-7-19.ppt
7chap007_data modeling and analysis_14-7-19.pptMDTahsinAmin3
Ìı
This document outlines the key concepts of data modeling and entity relationship diagrams as presented in Chapter 7 of the textbook "Systems Analysis and Design Methods" by Whitten, Bentley, and Dittman. It defines core data modeling terms like entities, attributes, relationships, keys, and normalization. It provides examples of how these concepts are represented in entity relationship diagrams and relational database design. The chapter aims to teach readers how to logically model systems data through entity relationship diagrams.3.1measure of central tendency.pptx
3.1measure of central tendency.pptxMDTahsinAmin3
Ìı
The document discusses different measures of central tendency including the mean, median, and mode. It defines central tendency as a central value that is representative of a data set and is calculated using all values while being free from extremes. The document notes that measures of central tendency ensure easy calculation and eligibility for further mathematical treatment. It then lists common measures like the arithmetic mean, geometric mean, harmonic mean, median, and mode.Chapter-8_Multiplexing.pptx
Chapter-8_Multiplexing.pptxMDTahsinAmin3
Ìı
Frequency division multiplexing (FDM) allows multiple signals to be transmitted simultaneously across a single communication channel by assigning each signal a unique frequency band. At the receiving end, filters separate the signals by frequency for delivery. FDM is commonly used in telephone networks and cellular systems. Time division multiplexing (TDM) transmits signals in sequential time slots allocated in a repeating frame. Synchronous TDM pre-assigns slots while statistical TDM dynamically allocates slots. TDM is used in digital transmission and SONET networks. Multiplexing techniques improve bandwidth utilization by allowing multiple users to share transmission capacity.Recently uploaded (20)
Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...
Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...J. Agricultural Machinery
Ìı
Optimal use of resources, including energy, is one of the most important principles in modern and sustainable agricultural systems. Exergy analysis and life cycle assessment were used to study the efficient use of inputs, energy consumption reduction, and various environmental effects in the corn production system in Lorestan province, Iran. The required data were collected from farmers in Lorestan province using random sampling. The Cobb-Douglas equation and data envelopment analysis were utilized for modeling and optimizing cumulative energy and exergy consumption (CEnC and CExC) and devising strategies to mitigate the environmental impacts of corn production. The Cobb-Douglas equation results revealed that electricity, diesel fuel, and N-fertilizer were the major contributors to CExC in the corn production system. According to the Data Envelopment Analysis (DEA) results, the average efficiency of all farms in terms of CExC was 94.7% in the CCR model and 97.8% in the BCC model. Furthermore, the results indicated that there was excessive consumption of inputs, particularly potassium and phosphate fertilizers. By adopting more suitable methods based on DEA of efficient farmers, it was possible to save 6.47, 10.42, 7.40, 13.32, 31.29, 3.25, and 6.78% in the exergy consumption of diesel fuel, electricity, machinery, chemical fertilizers, biocides, seeds, and irrigation, respectively. Air pollution is contamination of the indoor or outdoor environment by any ch...
Air pollution is contamination of the indoor or outdoor environment by any ch...dhanashree78
Ìı
Air pollution is contamination of the indoor or outdoor environment by any chemical, physical or biological agent that modifies the natural characteristics of the atmosphere.
Household combustion devices, motor vehicles, industrial facilities and forest fires are common sources of air pollution. Pollutants of major public health concern include particulate matter, carbon monoxide, ozone, nitrogen dioxide and sulfur dioxide. Outdoor and indoor air pollution cause respiratory and other diseases and are important sources of morbidity and mortality.
WHO data show that almost all of the global population (99%) breathe air that exceeds WHO guideline limits and contains high levels of pollutants, with low- and middle-income countries suffering from the highest exposures.
Air quality is closely linked to the earth’s climate and ecosystems globally. Many of the drivers of air pollution (i.e. combustion of fossil fuels) are also sources of greenhouse gas emissions. Policies to reduce air pollution, therefore, offer a win-win strategy for both climate and health, lowering the burden of disease attributable to air pollution, as well as contributing to the near- and long-term mitigation of climate change.
Mathematics behind machine learning INT255 INT255__Unit 3__PPT-1.pptx
Mathematics behind machine learning INT255 INT255__Unit 3__PPT-1.pptxppkmurthy2006
Ìı
Mathematics behind machine learning INT255 
Multi objective genetic approach with Ranking
Multi objective genetic approach with Rankingnamisha18
Ìı
Multi objective genetic approach with Ranking Wireless-Charger presentation for seminar .pdf
Wireless-Charger presentation for seminar .pdfAbhinandanMishra30
Ìı
Wireless technology used in charger


US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...
US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...Thane Heins NOBEL PRIZE WINNING ENERGY RESEARCHER
Ìı
Preface: The ReGenX Generator innovation operates with a US Patented Frequency Dependent Load
Current Delay which delays the creation and storage of created Electromagnetic Field Energy around
the exterior of the generator coil. The result is the created and Time Delayed Electromagnetic Field
Energy performs any magnitude of Positive Electro-Mechanical Work at infinite efficiency on the
generator's Rotating Magnetic Field, increasing its Kinetic Energy and increasing the Kinetic Energy of
an EV or ICE Vehicle to any magnitude without requiring any Externally Supplied Input Energy. In
Electricity Generation applications the ReGenX Generator innovation now allows all electricity to be
generated at infinite efficiency requiring zero Input Energy, zero Input Energy Cost, while producing
zero Greenhouse Gas Emissions, zero Air Pollution and zero Nuclear Waste during the Electricity
Generation Phase. In Electric Motor operation the ReGen-X Quantum Motor now allows any
magnitude of Work to be performed with zero Electric Input Energy.
Demonstration Protocol: The demonstration protocol involves three prototypes;
1. Protytpe #1, demonstrates the ReGenX Generator's Load Current Time Delay when compared
to the instantaneous Load Current Sine Wave for a Conventional Generator Coil.
2. In the Conventional Faraday Generator operation the created Electromagnetic Field Energy
performs Negative Work at infinite efficiency and it reduces the Kinetic Energy of the system.
3. The Magnitude of the Negative Work / System Kinetic Energy Reduction (in Joules) is equal to
the Magnitude of the created Electromagnetic Field Energy (also in Joules).
4. When the Conventional Faraday Generator is placed On-Load, Negative Work is performed and
the speed of the system decreases according to Lenz's Law of Induction.
5. In order to maintain the System Speed and the Electric Power magnitude to the Loads,
additional Input Power must be supplied to the Prime Mover and additional Mechanical Input
Power must be supplied to the Generator's Drive Shaft.
6. For example, if 100 Watts of Electric Power is delivered to the Load by the Faraday Generator,
an additional >100 Watts of Mechanical Input Power must be supplied to the Generator's Drive
Shaft by the Prime Mover.
7. If 1 MW of Electric Power is delivered to the Load by the Faraday Generator, an additional >1
MW Watts of Mechanical Input Power must be supplied to the Generator's Drive Shaft by the
Prime Mover.
8. Generally speaking the ratio is 2 Watts of Mechanical Input Power to every 1 Watt of Electric
Output Power generated.
9. The increase in Drive Shaft Mechanical Input Power is provided by the Prime Mover and the
Input Energy Source which powers the Prime Mover.
10. In the Heins ReGenX Generator operation the created and Time Delayed Electromagnetic Field
Energy performs Positive Work at infinite efficiency and it increases the Kinetic Energy of the
system.
Best KNow Hydrogen Fuel Production in the World The cost in USD kwh for H2
Best KNow Hydrogen Fuel Production in the World The cost in USD kwh for H2Daniel Donatelli
Ìı
The cost in USD/kwh for H2
Daniel Donatelli
Secure Supplies Group
Index
• Introduction - Page 3
• The Need for Hydrogen Fueling - Page 5
• Pure H2 Fueling Technology - Page 7
• Blend Gas Fueling: A Transition Strategy - Page 10
• Performance Metrics: H2 vs. Fossil Fuels - Page 12
• Cost Analysis and Economic Viability - Page 15
• Innovations Driving Leadership - Page 18
• Laminar Flame Speed Adjustment
• Heat Management Systems
• The Donatelli Cycle
• Non-Carnot Cycle Applications
• Case Studies and Real-World Applications - Page 22
• Conclusion: Secure Supplies’ Leadership in Hydrogen Fueling - Page 27

G8 mini project for alcohol detection and engine lock system with GPS tracki...
G8 mini project for alcohol detection and engine lock system with GPS tracki...sahillanjewar294
Ìı
b.tech final year projects report for csedecarbonization steel industry rev1.pptx
decarbonization steel industry rev1.pptxgonzalezolabarriaped
Ìı
Webinar Decarbonization steel industry
Engineering at Lovely Professional University (LPU).pdf
Engineering at Lovely Professional University (LPU).pdfSona
Ìı
LPU’s engineering programs provide students with the skills and knowledge to excel in the rapidly evolving tech industry, ensuring a bright and successful future. With world-class infrastructure, top-tier placements, and global exposure, LPU stands as a premier destination for aspiring engineers.Taykon-Kalite belgeleri
Taykon-Kalite belgeleriTAYKON
Ìı
Kalite Politikamız
Taykon Çelik için kalite, hayallerinizi bizlerle paylaştığınız an başlar. Proje çiziminden detayların çözümüne, detayların çözümünden üretime, üretimden montaja, montajdan teslime hayallerinizin gerçekleştiğini gördüğünüz ana kadar geçen tüm aşamaları, çalışanları, tüm teknik donanım ve çevreyi içine alır KALİTE.Indian Soil Classification System in Geotechnical Engineering
Indian Soil Classification System in Geotechnical EngineeringRajani Vyawahare
Ìı
This PowerPoint presentation provides a comprehensive overview of the Indian Soil Classification System, widely used in geotechnical engineering for identifying and categorizing soils based on their properties. It covers essential aspects such as particle size distribution, sieve analysis, and Atterberg consistency limits, which play a crucial role in determining soil behavior for construction and foundation design. The presentation explains the classification of soil based on particle size, including gravel, sand, silt, and clay, and details the sieve analysis experiment used to determine grain size distribution. Additionally, it explores the Atterberg consistency limits, such as the liquid limit, plastic limit, and shrinkage limit, along with a plasticity chart to assess soil plasticity and its impact on engineering applications. Furthermore, it discusses the Indian Standard Soil Classification (IS 1498:1970) and its significance in construction, along with a comparison to the Unified Soil Classification System (USCS). With detailed explanations, graphs, charts, and practical applications, this presentation serves as a valuable resource for students, civil engineers, and researchers in the field of geotechnical engineering. Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...
Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...J. Agricultural Machinery
Ìı
US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...
US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...Thane Heins NOBEL PRIZE WINNING ENERGY RESEARCHER
Ìı
A Star search algorithm with example (num)
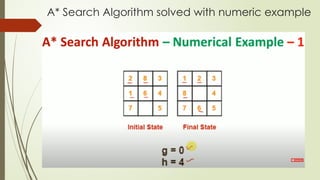
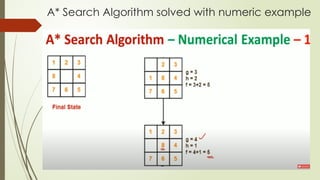
- 1. A* Search Algorithm ï‚´ A* Search Algorithm solved with numeric example
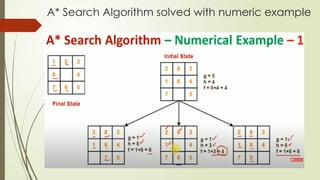
- 2. A* Search Algorithm solved with numeric example
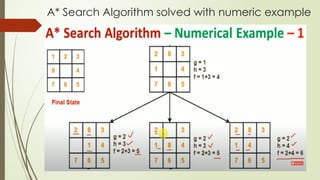
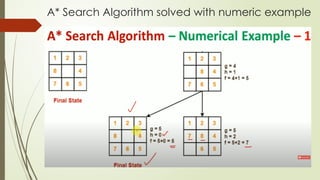
- 3. A* Search Algorithm solved with numeric example
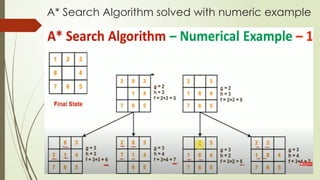
- 4. A* Search Algorithm solved with numeric example
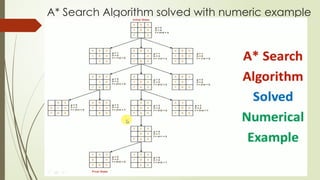
- 5. A* Search Algorithm solved with numeric example
- 6. A* Search Algorithm solved with numeric example
- 7. A* Search Algorithm solved with numeric example
- 8. A* Search Algorithm solved with numeric example
- 9. A* Search Algorithm solved with numeric example
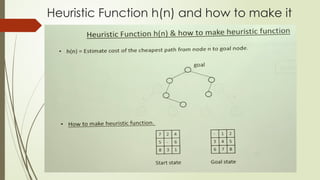
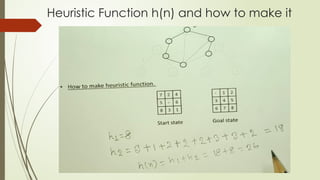
- 10. Heuristic Function h(n) and how to make it
- 11. Heuristic Function h(n) and how to make it
- 12. Optimality of A* Search Algorithm ï‚´ Heuristic may be: ï‚´ h(n) > actual cost ï‚´ h(n) = actual cost ï‚´ h(n) < actual cost ï‚´ (1) h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not possible] ï‚´ (2) h(n) = actual cost [Best case scenario, if h(n) approximates actual cost, searching uses minimum of node to the goal] ï‚´ (3) h(n) < actual cost [ Admissible, Consistent Heuristics]
- 13. Optimality of A* Search Algorithm h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not possible]
- 14. Optimality of A* Search Algorithm h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not possible]
- 15. Optimality of A* Search Algorithm h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not possible] b………….> dest and cost (7+2+0=9) , or ……….>a and cost (2+9=11)
- 16. Optimality of A* Search Algorithm h(n) > actual cost [Optimum solution can be overlooked, optimum solution is not possible] b………….> dest and cost (7+2+0=9) , or ……….>a and cost (2+9=11) Actual cost from Sïƒ aïƒ bïƒ dest =2+3+2=7 h(n)=10 > actual cost = 7
- 17. Optimality of A* Search Algorithm ï‚´ h(n) < actual cost, if this relation maintains for every node, then we say this this Admissible Heuristics.
- 18. Optimality of A* Search Algorithm
- 19. Optimality of A* Search Algorithm
- 20. Optimality of A* Search Algorithm
- 21. Optimality of A* Search Algorithm
- 22. Optimality of A* Search Algorithm If Heuristic admissible but not consistent, it may not be provided optimum solution. For optimum solution, heuristic must be consistent. If it consistent, it must be admissible.
- 23. Optimality of A* Search Algorithm
- 24. Random Variable ï‚´ The domain