础蝉补办耻蝉补による分散分析基盘构筑事例绍介
6 likes1,596 views

This is case study to use Asakusa framework on the Hadoop environment.





![8
サーバ側の構成 - Asakusa+EMR
Webサイト
のデータ
MySQL
抽出
データ
集計
データ
分析
MySQL
スレーブノード① スレーブノード② スレーブノード③
Hadoop分析基盤データ抽出 データ集計 データ分析
あらかじめ起動するスレーブノードの台数を記述
Amazon Web ServiceのEMR上で、Asakusaをベースとして構築すると、以下のような構成
となる。
Asakusa DSL/DMDL
(Asakusa Framework)
EMR起動オプションスクリプト
マスターノード
アプリケーション
EMR起動時にアプリケーショ
ンのファイルをS3からコピー
MySQLから「Windgate」
で直接データを取得
実行に必要な
ファイルをS3上
に格納しておく
Map/Reduce(DSLコンパイラ)
MapReduce(DSL)
S3
抽出
データ
データをS3から
「DirectI/O」で取得
集計
データ
集計結果を元に、
[Mahout]や[R]を
使って、高度なレコ
メンドや行動分析を
行うことも可能
Java
レコメンド生成
行動分析
実行結果を
S3に格納
プログラム
EMR](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-8-320.jpg)

![12
開発から実行までの手順
プログラム開発 ビルド デプロイ EMRジョブ登録 EMR起動
? 抽出データ入力用プ
ログラムをDMDL、
DSLで作成
? 集計用プログラムを
DSLで作成
? 集計データ出力用プ
ログラムをDMDL、
DSLで作成
? ブートストラップ用スク
リプトとステップ用スクリ
プトをシェルで作成
? 集計用データを格納
しておくフォルダをS3
上に作成
? [gradlew]コマンドで、
Asakusa
Framework、バッチ
用アーカイブを作成
? 作成したプログラムを
ビルド。jarファイルが
作成される。
? デプロイ用全ファイルを
含んだtar.gzファイル
が作成される。
? ビルドしたモジュール
[tar.gzファイル]をS3
上に配置
? ブートストラップ用スク
リプトとステップ用スクリ
プトAWS
management
ConsoleからS3に配
置
? EMRで実行するジョブ
を登録
? 作成したS3に集計入
力用データ(CSVファ
イル)を格納
? EMRを起動
? AWS
Management
Consoleで、EMR用
のEC2インスタンスが
起動されるのを確認
? 処理結果がS3上に
出力
? S3上の処理結果ファ
イル確認
AsakusaとEMR起動ツールセットアップ後、プログラムを作成してEMR上にデプロイ、登録し
EMRを起動してプログラムを実行させる。](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-12-320.jpg)

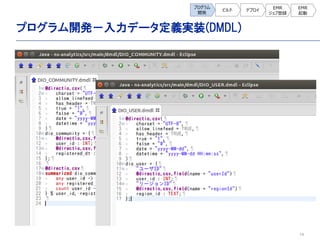
![15
プログラム開発- Importer実装
[getBasePath]でS3のパスを指定、
[getResourcePattern]で入力ファ
イル名を指定。入力ファイル名は、ワ
イルドカードで複数ファイルの読み込
みを可能にしておく。
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-15-320.jpg)
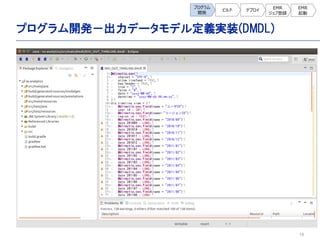
![20
プログラム開発- Exporter実装
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動
[getBasePath]でS3のパスを指定
し、[getResourcePattern]で出
力ファイル名を指定。出力フォルダー
はプログラムで自動的に作成される。](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-20-320.jpg)
![21
プログラム開発- スクリプト
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動
#!/bin/bash
set –e
### Change it ###
_bucket=s3fs.dev.emr.tokyo.projects
exportUSER="hadoop“
exportHOME="/home/$USER“
Export ASAKUSA_HOME="$HOME/asakusa“
#_asakusafw_filename="asakusafw-*.tar.gz“
_asakusafw_filename="asakusafw-0.6.2.tar.gz“
_asakusafw_path="asakusafw/${_asakusafw_filename}“
# Deploy asakusafw
mkdir -p ${ASAKUSA_HOME}
hadoop fs –get "s3://${_bucket}/${_asakusafw_path}"
${ASAKUSA_HOME}
cd ${ASAKUSA_HOME}
tar -xzf ${_asakusafw_filename}
find ${ASAKUSA_HOME} -name"*.sh" | xargs chmod
u+x
#!/bin/bash
. ~/.bash_profileexportUSER="hadoop“
exportHOME="/home/$USER“
exportASAKUSA_HOME="$HOME/asakusa“
export_CMD_LOG="$ASAKUSA_HOME/job-step.log“
# Run YAESS
echo "$0 $*" >> $_CMD_LOG
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh"$@"
2>&1 | tee -a $_CMD_LOG
exit "${PIPESTATUS[0]}"
ブートストラップ用スクリプト ステップ用スクリプト](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-21-320.jpg)
![22
ビルド-gradlew実行
[gradlew]でデプロイ用Asakusa
Framework、バッチアプリのアーカ
イブを作成
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-22-320.jpg)
![23
デプロイ-アーカイブの配置
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動
S3に[gradlew]で作成されたモ
ジュール、Asakusa Framework、
バッチアプリのアーカイブを配置する。
ここではS3Foxを利用してアーカイブ
を配置している。](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-23-320.jpg)
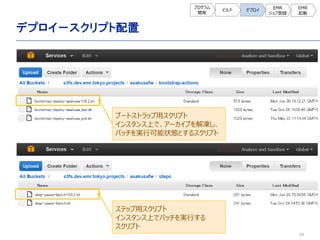
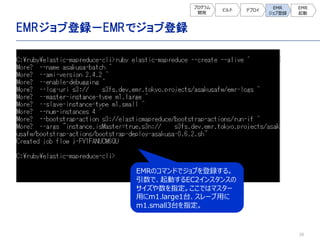
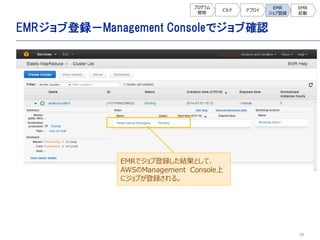
![28
EMR起動- EMRステップ登録
ジョブ登録時に生成されたジョブフロー
IDを確認して、そのジョブフローIDに
対してステップ[test-step]を登録
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-28-320.jpg)
![29
EMR起動- Management Consoleで登録ステップ確認
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動
EMRステップ登録の結果として、AWS
Management Console上でステップ
[test-step]が登録される。この状態か
ら、ジョブが実行される。](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-29-320.jpg)
![31
EMR起動-処理終了
プログラム
開発
ビルド デプロイ
EMR
ジョブ登録
EMR
起動
Statusが[Completed]で、
実行したジョブが終了。](https://image.slidesharecdn.com/asakusa-140723055133-phpapp01/85/Asakusa-31-320.jpg)

础蝉补办耻蝉补による分散分析基盘构筑事例绍介
- 1. 2014年7月11日
- 2. 2 本日のアジェンダ ? 自己紹介 ? Asakusa+Hadoop(EMR)を利用した背景 ? ユーザ毎で収集?分析したいデータ ? データ分析ツールの比較 ? 分析基盤システム全体構成 ? サーバ側の構成 - Asakusa+EMR ? (参考)サーバ側の構成 – Apache Hadoop ? 集計イメージ ? Asakusa利用のために用意しておくもの ? 開発から実行までの手順 ? Asakusa+Hadoop(EMR)を使ってみての感想
- 3. 3 自己紹介 ? 氏名 福垣内 孝造(ふくがうち こうぞう) ? 所属 アクセンチュア株式会社 テクノロジーコンサルティング本部 シニアプリンシパル ソフトウェア会社に7年間勤務 ? 担当領域 ? 通信、ハイテク産業におけるシステムインテグレーションのテクニカルアーキテク チャ設計?構築 ? JavaベースのCustom Development(特にWeb系)アプリケーション開発リード ? OSSやクラウドをベースとしたシステムインテグレーションのソリューション、アプリ ケーション構築の推進、テクニカルレビュー ? 出身 広島県
- 4. 4 Asakusa+Hadoop(EMR)を利用した背景 プロジェクトで「Hadoop」によるデータ分析処理を試したいという要望があり、具体的に何が できるかを把握するため、まずは分析基盤を構築してみることにした。 ユーザ毎にサイトの 利用状況を把握し たい。 ビッグデータの分析 で具体的に使える ツールを確認したい。 ? PV、CVRではなく、ユーザ毎でサイト利用状況やアクション間の相関を知りたい。 ? サービスインからRDBMS内に蓄積された数千万件のレコードを活用したい。 ? 分析はSQL文のみで行ってきたが、レコード件数の増加で処理時間が増えてきた。 ? Apache Hadoopだと、HBase、HDFS、Hive、Pig、MapReduce等、初めて 聞くIT用語が多く、すぐに使い方が分からない。 ? 短期間での導入を目指しているが、HiveやPigで処理を記述できるようになるまで 時間がかかりそう。 ? SQL文だけでは処理に時間がかかるような大容量で複雑な分析では、Hadoop、 HANA、Teradata、RedShift等ある中で、分析プラットフォームに向くのがどれか を判断したい。 ? 分析プラットフォームの初期導入段階なので、できるだけコストは抑えたい。 Asakusa+Hadoop(EMR)の組み合わせなら、短期間でかつ初期導入費用も抑えた分析 プラットフォームを作れないか。 Hadoop環境を簡 単に構築したい。
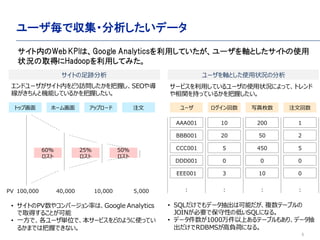
- 5. 5 ユーザ毎で収集?分析したいデータ サイトの足跡分析 ユーザを軸とした使用状況の分析 トップ画面 ホーム画面 アップロード 注文 ? サイトのPV数やコンバージョン率は、Google Analytics で取得することが可能 ? 一方で、各ユーザ単位で、本サービスをどのように使ってい るかまでは把握できない。 100,000 40,000 10,000 5,000PV ユーザ ログイン回数 写真枚数 注文回数 エンドユーザがサイト内をどう訪問したかを把握し、SEOや導 線がきちんと機能しているかを把握したい。 サービスを利用しているユーザの使用状況によって、トレンド や相関を持っているかを把握したい。 AAA001 BBB001 CCC001 DDD001 10 20 5 0 0 0 200 50 450 1 2 5 : : : : ? SQLだけでもデータ抽出は可能だが、複数テーブルの JOINが必要で保守性の低いSQLになる。 ? データ件数が1000万件以上あるテーブルもあり、データ抽 出だけでRDBMSが高負荷になる。 60% ロスト 25% ロスト 50% ロスト サイト内のWeb KPIは、Google Analyticsを利用していたが、ユーザを軸としたサイトの使用 状況の取得にHadoopを利用してみた。 EEE001 3 10 0
- 6. 6 データ分析ツールの比較 SQL?PL/SQL Hadoop Redshift?HANA?Oracle ? ソフトウェアを新規にインストール することなく、SQL文だけでデー タを抽出できる。 ? テーブルを参照するだけで新規 のプログラム開発が不要。 ? データを抽出するまでの初期導 入は早い。 ? リアルタイムで見たい時に見たい 切り口でデータを参照することが できる。 ? TB、PB級のデータボリュームを 扱うことができる。 ? データをINSERTするだけで集 計結果を参照できる。 ? 複数のテーブルをJoinしてデー タを抽出すると、保守性の低い SQL文となる。 ? データ抽出の頻繁な変更に対 応しづらい。 ? データ件数が多くなればなるほど、 処理時間がかかる。 ? OSSの組み合わせだけで実装 できるので、初期導入費用は 安い。 ? データボリュームが多くなってもス ケールアウトで対応できるため、 処理時間が劇的に遅くならない。 ? リアルタイムでデータを集計、抽 出した結果を参照するような処 理には向かない。 ? データ件数が少ない場合は SQL文の方が速い。 ? MapReduceにHiveやPigを 使うと、習得が難しい。 ? 初期導入費用が高い。 ? データを抽出するまでに、ソフト ウェアの仕様を理解する必要が あり、時間がかかる。 ? ハイスペックなサーバが必要。 Pros Cons 易 安 少 難 高 多 大容量のデータを扱いたいが、高価なBI用ソフトウェアまでは不要なため、Hadoopを選択。 データ量 費用 導入
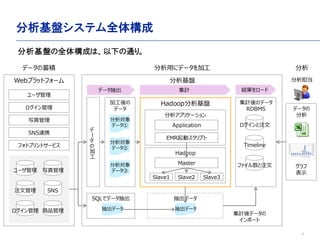
- 7. 7 分析基盤システム全体構成 Webプラットフォーム ユーザ管理 ログイン管理 SNS連携 フォトプリントサービス ユーザ管理 写真管理 注文管理 SNS ログイン管理 商品管理 写真管理 分析基盤 デ ー タ の 加 工 Hadoop分析基盤加工後の データ SQLでデータ抽出 分析対象 データ① 分析対象 データ② 抽出データ 集計後のデータ RDBMS 分析アプリケーション Application EMR起動スクリプト Hadoop Master Slave1 Slave2 Slave3 ログインと注文 Timeline ファイル数と注文 抽出データ 抽出データ 集計後データの インポート データの 分析 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00% 0 200 400 600 800 1000 1200 1400 1600 1800 グラフ 表示 分析担当 データ抽出 集計 結果をロード データの蓄積 分析用にデータを加工 分析 分析基盤の全体構成は、以下の通り。 分析対象 データ③
- 8. 8 サーバ側の構成 - Asakusa+EMR Webサイト のデータ MySQL 抽出 データ 集計 データ 分析 MySQL スレーブノード① スレーブノード② スレーブノード③ Hadoop分析基盤データ抽出 データ集計 データ分析 あらかじめ起動するスレーブノードの台数を記述 Amazon Web ServiceのEMR上で、Asakusaをベースとして構築すると、以下のような構成 となる。 Asakusa DSL/DMDL (Asakusa Framework) EMR起動オプションスクリプト マスターノード アプリケーション EMR起動時にアプリケーショ ンのファイルをS3からコピー MySQLから「Windgate」 で直接データを取得 実行に必要な ファイルをS3上 に格納しておく Map/Reduce(DSLコンパイラ) MapReduce(DSL) S3 抽出 データ データをS3から 「DirectI/O」で取得 集計 データ 集計結果を元に、 [Mahout]や[R]を 使って、高度なレコ メンドや行動分析を 行うことも可能 Java レコメンド生成 行動分析 実行結果を S3に格納 プログラム EMR
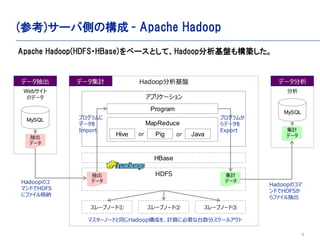
- 9. 9 (参考)サーバ側の構成 - Apache Hadoop Webサイト のデータ MySQL 抽出 データ 集計 データ 分析 MySQL スレーブノード① スレーブノード② スレーブノード③ Hadoop分析基盤データ抽出 データ集計 データ分析 HDFS アプリケーション 集計 データ MapReduce Hive Pig Java Program or or HBase 抽出 データ Hadoopのコ マンドでHDFS にファイル格納 マスターノードと同じHadoop構成を、計算に必要な台数分スケールアウト Hadoopのコマ ンドでHDFSか らファイル抽出 Apache Hadoop(HDFS?HBase)をベースとして、Hadoop分析基盤も構築した。 プログラムに データを Import プログラムか らデータを Export
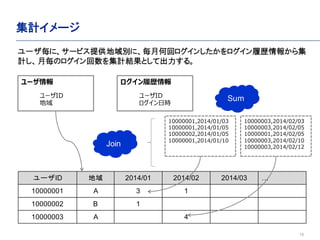
- 10. 10 ユーザID 地域 2014/01 2014/02 2014/03 … 10000001 A 3 1 10000002 B 1 10000003 A 4 集計イメージ 10000001,2014/01/03 10000001,2014/01/05 10000002,2014/01/05 10000001,2014/01/10 ユーザ情報 ユーザID 地域 ログイン履歴情報 ユーザID ログイン日時 Sum Join 10000003,2014/02/03 10000003,2014/02/05 10000001,2014/02/05 10000003,2014/02/10 10000003,2014/02/12 ユーザ毎に、サービス提供地域別に、毎月何回ログインしたかをログイン履歴情報から集 計し、月毎のログイン回数を集計結果として出力する。
- 11. 11 EMR 起動ツール Asakusa利用のために用意しておくもの Asakusa 開発環境 ? VMware Player上にUbuntuをインストールし、Jinrikisha(開発環境のイン ストーラ)で開発環境(Asakusa Framework/Java/Hadoop/Eclipse…) を一括インストール ? その他、ビルドツール(Gradle)やDMDLエディタプラグイン、shahuをインストー ル ? ※上記はAsakusa Frameworkのドキュメント通り ? EMRを起動するためのコマンドラインツール(Amazon Elastic Map Reduce Command Line Interface)をインストール – コマンドラインツールのインストールにはRubyが必要 – AWSの認証情報(アクセスキーID、シークレットアクセスキー)が必要 Asakusaでプログラムを開発するための環境構築と、Amazon Web Serviceから提供される EMR起動ツールをセットアップする。
- 12. 12 開発から実行までの手順 プログラム開発 ビルド デプロイ EMRジョブ登録 EMR起動 ? 抽出データ入力用プ ログラムをDMDL、 DSLで作成 ? 集計用プログラムを DSLで作成 ? 集計データ出力用プ ログラムをDMDL、 DSLで作成 ? ブートストラップ用スク リプトとステップ用スクリ プトをシェルで作成 ? 集計用データを格納 しておくフォルダをS3 上に作成 ? [gradlew]コマンドで、 Asakusa Framework、バッチ 用アーカイブを作成 ? 作成したプログラムを ビルド。jarファイルが 作成される。 ? デプロイ用全ファイルを 含んだtar.gzファイル が作成される。 ? ビルドしたモジュール [tar.gzファイル]をS3 上に配置 ? ブートストラップ用スク リプトとステップ用スクリ プトAWS management ConsoleからS3に配 置 ? EMRで実行するジョブ を登録 ? 作成したS3に集計入 力用データ(CSVファ イル)を格納 ? EMRを起動 ? AWS Management Consoleで、EMR用 のEC2インスタンスが 起動されるのを確認 ? 処理結果がS3上に 出力 ? S3上の処理結果ファ イル確認 AsakusaとEMR起動ツールセットアップ後、プログラムを作成してEMR上にデプロイ、登録し EMRを起動してプログラムを実行させる。
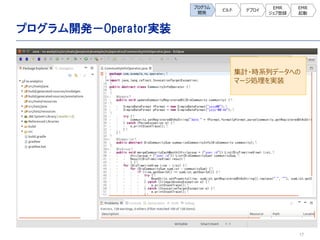
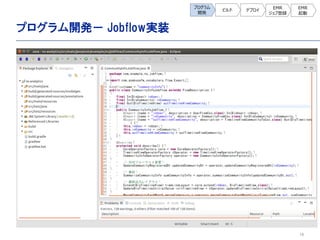
- 13. 13 抽出データ 入力用 プログラム 分析用に作成したプログラム ? 入力データ定義実装(DMDL) ? Importerプログラム(DSL) ? 入力データ格納用ディレクトリ(S3) 集計用 プログラム 集計データ 出力用 プログラム ? 出力データ定義実装(DMDL) ? Exporterプログラム(DSL) ? Operator実装プログラム(DSL) ? JobFlowプログラム(DSL) プログラム 開発 ビルド デプロイ EMR ジョブ登録 EMR 起動 ユーザID、日付のデータ項目の定義 集計用データを読み込むプログラム 集計用のCSVファイルを格納するディレクトリ MapReduceで集計するプログラム 実行するジョブを定義したプログラム ユーザID、月、回数のデータ項目の定義 集計データを出力するプログラム データロード、集計、集計結果出力と、EMR用の4種類のプログラムを作成する。 EMR用 スクリプト ? ブートストラップ用スクリプト(shell) ? ステップ用スクリプト(shell) バッチを実行可能状態にするスクリプト バッチを実行するスクリプト
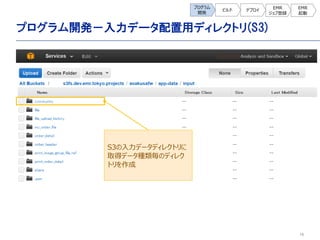
- 16. 16 プログラム開発-入力データ配置用ディレクトリ(S3) プログラム 開発 ビルド デプロイ EMR ジョブ登録 EMR 起動 S3の入力データディレクトリに 取得データ種類毎のディレク トリを作成
- 21. 21 プログラム開発- スクリプト プログラム 開発 ビルド デプロイ EMR ジョブ登録 EMR 起動 #!/bin/bash set –e ### Change it ### _bucket=s3fs.dev.emr.tokyo.projects exportUSER="hadoop“ exportHOME="/home/$USER“ Export ASAKUSA_HOME="$HOME/asakusa“ #_asakusafw_filename="asakusafw-*.tar.gz“ _asakusafw_filename="asakusafw-0.6.2.tar.gz“ _asakusafw_path="asakusafw/${_asakusafw_filename}“ # Deploy asakusafw mkdir -p ${ASAKUSA_HOME} hadoop fs –get "s3://${_bucket}/${_asakusafw_path}" ${ASAKUSA_HOME} cd ${ASAKUSA_HOME} tar -xzf ${_asakusafw_filename} find ${ASAKUSA_HOME} -name"*.sh" | xargs chmod u+x #!/bin/bash . ~/.bash_profileexportUSER="hadoop“ exportHOME="/home/$USER“ exportASAKUSA_HOME="$HOME/asakusa“ export_CMD_LOG="$ASAKUSA_HOME/job-step.log“ # Run YAESS echo "$0 $*" >> $_CMD_LOG $ASAKUSA_HOME/yaess/bin/yaess-batch.sh"$@" 2>&1 | tee -a $_CMD_LOG exit "${PIPESTATUS[0]}" ブートストラップ用スクリプト ステップ用スクリプト
- 26. 26 EMRジョブ登録-Management Consoleでジョブ確認 プログラム 開発 ビルド デプロイ EMR ジョブ登録 EMR 起動 EMRでジョブ登録した結果として、 AWSのManagement Console上 にジョブが登録される。
- 29. 29 EMR起動- Management Consoleで登録ステップ確認 プログラム 開発 ビルド デプロイ EMR ジョブ登録 EMR 起動 EMRステップ登録の結果として、AWS Management Console上でステップ [test-step]が登録される。この状態か ら、ジョブが実行される。
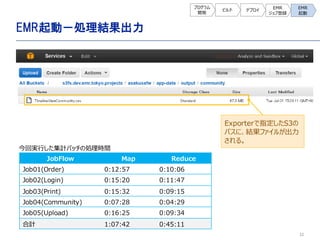
- 32. 32 EMR起動-処理結果出力 プログラム 開発 ビルド デプロイ EMR ジョブ登録 EMR 起動 JobFlow Map Reduce Job01(Order) 0:12:57 0:10:06 Job02(Login) 0:15:20 0:11:47 Job03(Print) 0:15:32 0:09:15 Job04(Community) 0:07:28 0:04:29 Job05(Upload) 0:16:25 0:09:34 合計 1:07:42 0:45:11 今回実行した集計バッチの処理時間 Exporterで指定したS3の パスに、結果ファイルが出力 される。
- 33. 33 Asakusa+Hadoop(EMR)を使ってみての感想 ? MapReduceを特に意識することなくHadoopの 動きを体験できる。 ? 初期導入のコストを抑えることができるのでお試し で使うには最適。1ヶ月約6千円 ? 開発環境構築から実行まで至れりつくせりなツー ルがある (IDE(Eclipse)で開発可能/テスト/ビ ルド/データ連携) ? DSLをEclipseで使えば、従来の使い慣れた環 境とさほど違わずプログラミング開発できる。 良かった点 今後は、Asakusaの適用事例を集めながら、Asakusaデザインパターンのようなものを作り、 ベストプラクティスやサンプルコードを活用しやすい形で紹介していきたい。 ? 事例が少なく、今回の使い方よりもっといいやり方、 実装方法があるのかが分からなかった。 ? S3とEMRの連携は手探りで行った。 ? Asakusaのトレーニングを受けていないと、用語、 演算子、機能の面でとりかかりが難しい。 ? これから実例がでてくるであろう、「SPARK」のよう な新しい技術とAsakusaとの連携と、Hadoopと の使い分け。 改善点&今後の期待