







































AWSKRUG DS - ŽćįžĚīŪĄį žóĒžßÄŽčąžĖīÍįÄ žč§Ž¨īžóźžĄú ŽßěŽč•Žú®Ž¶¨ŽäĒ Ž¨łž†úŽď§
- 1. ŽćįžĚīŪĄį žóĒžßÄŽčąžĖīÍįÄ žč§Ž¨īžóźžĄú ŽßěŽč•Žú®Ž¶¨ŽäĒ Ž¨łž†úŽď§ ŪĀ¨Ž°úŪā§Žč∑žĽī ÍįēžõÖžĄĚ
- 2. Ž™©žį® ‚ÄĘParquet/ORC Deep Dive ‚ÄĘORC Schema Evolution with AWS Glue ‚ÄĘEMR (Í≤©ŪēėÍ≤Ć) tuning ŪēīŽ≥īÍłį - Cost/Performance
- 3. ŪöĆžā¨ žÜĆÍįú ‚ÄĘžßÄÍ∑łžě¨Í∑ł - No. 1 žó¨žĄĪ žáľŪēĎŽ™į Ž™®žĚĆžēĪ ‚ÄĘ2000ŽßĆ Žč§žöīŽ°úŽďú ‚ÄĘDAU 700K+, MAU 3M+ ‚ÄĘŽąĄž†Ā ÍĪįŽěėžē° 1ž°į 7ž≤úžĖĶ ‚ÄĘŽćįžĚīŪĄį žóĒžßÄŽčąžĖī ž†ąžį¨ žĪĄžö©ž§Ď!
- 4. žßÄÍ∑łžě¨Í∑ł ŽćįžĚīŪĄį žÜĆÍįú ‚ÄĘŽćįžĚīŪĄį Ž†ąžĚīŪĀ¨ 26TB+ ‚ÄĘS3 ‚ÄĘž†Ąž≤ī ŽďĪŽ°Ě žÉĀŪíą žąė 50M+ ‚Äʎ讞̾ ŪÖĆžĚīŽłĒ, JSON 19GB+ ‚ÄĘImpression log žĚľ 250M+ ‚ÄĘpeakžčú 5Ž∂Ąžóź 1.7M žąėžßĎ ‚ÄĘ33 DAG, 200+ daily tasks in Airflow
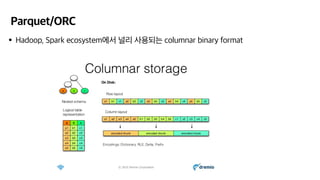
- 5. Parquet/ORC ‚ÄĘHadoop, Spark ecosystemžóźžĄú ŽĄźŽ¶¨ žā¨žö©ŽźėŽäĒ columnar binary format
- 6. Parquet vs ORC ‚ÄĘŽĎė Žč§ ŽĄźŽ¶¨ žďįžĚīŽäĒ columnar format ‚ÄĘParquetŽäĒ 2013ŽÖĄ ImpalažôÄ Ūē®ÍĽė ŽįúŪĎúŽź® (Cloudera + Twitter) ‚ÄĘORCŽäĒ 2013ŽÖĄ HivežôÄ Ūē®ÍĽė ŽįúŪĎúŽź® (Hortonworks + Facebook) ‚ÄĘžĶúÍ∑ľ ÍįúŽįú ŽŹôŪĖ• ‚ÄĘParquetŽäĒ 2020-01-13žóź 2.8.0 ŽįúŪĎú ‚ÄĘORCŽäĒ 2020-04-23žóź 1.6.3 ŽįúŪĎú ‚ÄĘŽßéžĚÄ žÜĆŪĒĄŪäłžõ®žĖī, ŪĒĄŽ†ąžěĄžõĆŪĀ¨žóźžĄú ORC žßÄžõź ŪôēŽĆÄ ž§Ď ‚ÄĘSpark - 2.3žóźžĄú VectorizedORCReader ž∂ĒÍįÄ (ParquetŽ≥īŽč§ ŽĻ†Ž¶Ą!) ‚ÄĘHive - Native support ‚ÄĘPresto ‚ÄĘAWS - Glue, Firehose ŽďĪžĚė Žč§žĖĎŪēú žĄúŽĻĄžä§žóźžĄú ORC žßÄžõź
- 7. ORC ‚ÄĘSelf-describing type-aware columnar file format for Hadoop workloads
- 8. ORC ‚ÄĘKey features ‚ÄĘNative rich file types: tinyint, smallint, structs, lists, maps, unions, ‚Ķ ‚ÄĘParquetŽäĒ ž†úŪēúž†ĀžúľŽ°ú žßÄžõź (e.g. tinyintŽäĒ ParquetžóźžĄú Ž¨ľŽ¶¨ž†ĀžúľŽ°úŽäĒ 32bit)
- 9. ORC ‚ÄĘNative rich file types ‚ÄĘÍįĄŽč® žĄĪŽä• ŽĻĄÍĶź: string vs struct
- 10. ORC ‚ÄĘNative rich file types ‚ÄĘÍįĄŽč® žĄĪŽä• ŽĻĄÍĶź: string vs struct => structŽ°ú ŪĖąžĚĄ ŽēĆ ŪĆƞ̾ žö©ŽüČ 8.7% ÍįźžÜĆ
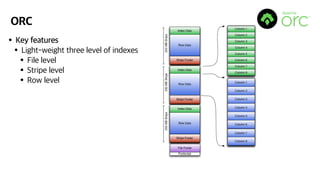
- 11. ORC ‚ÄĘKey features ‚ÄĘLight-weight three level of indexes ‚ÄĘFile level ‚ÄĘStripe level ‚ÄĘRow level
- 12. ORC ‚ÄĘKey features ‚ÄĘLight-weight three level of indexes ‚ÄĘžĄł ÍįÄžßÄ Žč®Í≥ĄžĚė metadataŽ•ľ žĚīžö©Ūēī Žď§žĖīžė§ŽäĒ žßąžĚėžĚė predicatežĚĄ filter Ūē† žąė žěąžĚĆ ‚ÄĘcolumn-level count, min, max, sum ŽďĪžĚī ŽčīÍ≤®žěąžĚĆ ‚ÄĘSELECT name, age FROM users WHERE age > 30 ‚ÄĘORC filežĚÄ nÍįúŽĚľÍ≥† ÍįÄž†ē (concurrency readable) ‚ÄĘFile level: maxÍįÄ 30žĚī žēĄŽčĆ filežĚÄ footerŽßĆ Ž≥īÍ≥† skip ‚ÄĘStripe level, Row levelžóź ŽĆÄŪēīžĄúŽŹĄ ŽŹôžĚľŪēėÍ≤Ć žĶúž†ĀŪôĒ ÍįÄŽä• ‚ÄĘÍįĀ rowŽ•ľ žĚŞ̥ ŽēĆŽäĒ name, age columnŽßĆ žĚĹÍ≥† ŽāėŽ®łžßÄŽäĒ discard
- 13. ORC ‚ÄĘLight-weight three level of indexes ‚ÄĘORC scanning with orc-tools to describe metadata
- 14. ORC ‚ÄĘKey features ‚ÄĘBlock-mode compression ‚ÄĘInteger: Run-length encoding ‚ÄĘString: Dictionary encoding ‚ÄĘSplittable ‚ÄĘžēēž∂ē (snappy, zlib, ‚Ķ) ŪõĄžóźŽŹĄ Ž≥ĎŽ†¨ ž≤ėŽ¶¨ ÍįÄŽä• ‚ÄĘJSON vs ORC (Parquet) ‚ÄĘJSON: full plain-textŽ•ľ žēĒŪėłŪôĒ ‚ÄĘORC: block (stripe) Žč®žúĄŽ°ú žēĒŪėłŪôĒ
- 15. ORC ‚ÄĘParquet ŽßźÍ≥† ORCŽ•ľ žďįŽ©ī žĘčžĚÄ ž†źžĚī Ž≠ĒÍįÄžöĒ? ‚ÄĘRich data type: ž†ĀžĚÄ žö©ŽüČ, ŽĻ†Ž•ł ž≤ėŽ¶¨ žÜ掏Ą => Athena, S3 ŽĻĄžö© ž†ąÍįź ‚ÄĘPredicate filtering with index: ŽćĒžöĪ ŽĻ†Ž•ł ž≤ėŽ¶¨ žÜ掏Ą ‚ÄĘŪôúŽįúŪēú ÍįúŽįú ŽįŹ žú†žßÄŽ≥īžąė ‚ÄĘžč†Í∑ú feature žßÄžõź ŪôúŽįú: zstd compression codec (from FB) ‚ÄĘhttps://jira.apache.org/jira/browse/ORC-363 ‚ÄĘParquetŽäĒ žēĄžßĀ ÍįúŽįú ž§Ď: https://jira.apache.org/jira/browse/PARQUET-1124
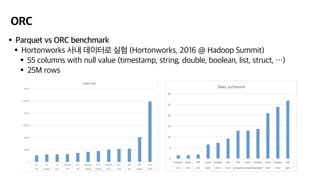
- 16. ORC ‚ÄĘParquet vs ORC benchmark ‚ÄĘHortonworks žā¨Žāī ŽćįžĚīŪĄįŽ°ú žč§Ūóė (Hortonworks, 2016 @ Hadoop Summit) ‚ÄĘ55 columns with null value (timestamp, string, double, boolean, list, struct, ‚Ķ) ‚ÄĘ25M rows
- 17. ORC ‚ÄĘParquet vs ORC benchmark ‚ÄĘžßÄÍ∑łžě¨Í∑łžóź ŽďĪŽ°ĚŽźú žÉĀŪíą ŽćįžĚīŪĄįŽ°ú žč§Ūóė ‚ÄĘ50M rows, JSON 19GB ‚ÄĘint, timestamp, string, list, tinyint ŽďĪ Žč§žĖĎŪēú column type ž°īžě¨ ‚ÄĘ(1) ŽćįžĚīŪĄį žÉĚžĄĪ ‚ÄĘORC/zlib: 1.9GB, 1m 30s (JSON ŽĆÄŽĻĄ žēēž∂ēŽ•† 90%) ‚ÄĘParquet/snappy: 3.6GB, 1m 30s (JSON ŽĆÄŽĻĄ žēēž∂ēŽ•† 81%) ‚ÄĘŽćįžĚīŪĄį ŪĀ¨ÍłįŽäĒ ParquetÍįÄ 90% ÍįÄŽüČ ŪĀľ
- 18. ORC ‚ÄĘParquet vs ORC benchmark ‚ÄĘžßÄÍ∑łžě¨Í∑łžóź ŽďĪŽ°ĚŽźú žÉĀŪíą ŽćįžĚīŪĄįŽ°ú žč§Ūóė ‚ÄĘ50M rows, JSON 19GB ‚ÄĘint, timestamp, string, list, tinyint ŽďĪ Žč§žĖĎŪēú column type ž°īžě¨ ‚ÄĘ(2) integer, list 2Íįú columnžóź ŽĆÄŪēī 10M rows projection w/ Athena ‚ÄĘORC/zlib: 38.05s, 550.7MB scanned ‚ÄĘParquet/snappy: 35.21s, 1.36GB scanned ‚ÄĘžÜ掏ĄŽäĒ ParquetÍįÄ 8% ŽĻ†Ž•īžßÄŽßĆ, ŽćįžĚīŪĄįŽäĒ 147% ŽßéžĚī žĚĹžĚĆ
- 19. ORC ‚ÄĘžēĹÍįĄžĚė Žč®ž†ź ‚ÄĘParquetŽ≥īŽč§ žú†Ž™ÖŪēėžßĄ žēäÍłį ŽēĆŽ¨łžóź AWS feature žßÄžõźžĚī ž°įÍłą ŽäźŽ¶ľ ‚ÄĘEMR: EMRFS S3 committerŽäĒ ParquetŽßĆ žßÄžõź ‚ÄĘAurora: Parquet exportŽßĆ žßÄžõź ‚ÄĘÍ∑łŽěėŽŹĄ ž†źž†ź ORC žßÄžõźžĚĄ ŽäėŽ¶¨Í≥† žěąžĖīžĄú žēěžúľŽ°úÍįÄ ÍłįŽĆÄŽź®!
- 20. ORC in ZIGZAG ‚ÄĘž†Ąž≤ī ŽćįžĚīŪĄį Ž†ąžĚīŪĀ¨ŽäĒ ORCŽ°ú žĚīŽ£®žĖīž†ł žěąžĚĆ ‚ÄĘS3 žö©ŽüČ 26TB+ (w/ ORC/zlib) ‚ÄĘS3 žö©ŽüČ 50TB (w/ Parquet/snappy) ‚ÄĘS3 žö©ŽüČ 260TB (w/ JSON) ‚ÄĘÍłįž°ī JSON, CSV, Parquet ŪĆƞ̾žĚĄ ÍĪįžĚė ŽĆÄŽ∂ÄŽ∂Ą ORCŽ°ú conversion ‚ÄĘSpark, Athena (+ Glue) Ž°ú žĚĹžĖīžĄú žā¨žö© ‚ÄĘtinyint, smallint, struct ŽďĪ rich type žā¨žö©žĚĄ ŪÜĶŪēī Ūö®žú® ž¶ĚŽĆÄ (+ Glue) ‚ÄĘŽĻąŽ≤ąŪēėÍ≤Ć žĚĹŪ칎äĒ columnžĚÄ bloom filter columnžóź ŽďĪŽ°ĚŪēīžĄú filterŽ•ľ ŽĻ†Ž•īÍ≤Ć Ūē† žąėŽŹĄ žěąžĚĆ
- 21. Schema evolution ‚ÄĘÍįúŽįúŪĆÄ: table schemaÍįÄ ŽįĒŽÄĆžóąžĖīžöĒ! log schemaÍįÄ ŽįĒŽÄĆžóąžĖīžöĒ! ūüėÉ ‚ÄĘŽćįžĚīŪĄįŪĆÄ: ‚Ķ ūüėá
- 22. Schema evolution ‚ÄĘParquet/ORCŽäĒ self-describing format žĚīžßÄŽßƂĶ ‚ÄĘŪēīŽčĻ ž†ēŽ≥īŽäĒ ŪĆƞ̾ Žāīžóź žěąÍłį ŽēĆŽ¨łžóź schemaŽ•ľ žēĆÍłį žúĄŪēīžĄúŽäĒ Ž™®Žď† filežĚĄ žĚĹžĖīžēľ Ūē® ‚ÄĘfiležĚĄ žóīžĖīŽ≥īÍłį ž†ĄÍĻƞߥ schemaŽ•ľ žēĆÍłį žĖīŽ†§žõÄ (ÍīÄŽ¶¨ŽŹĄ žĖīŽ†§žõÄ) ‚ÄĘExternal metadata storežóźžĄú schemaŽ•ľ ž£ľžěÖŪēėŽ©ī žĖīŽĖ®ÍĻĆ? ‚ÄĘÍīÄŽ¶¨ŽŹĄ žČĹÍ≥†, filežĚĄ žĚŞ̥ ŪēĄžöĒŽŹĄ žóÜŽč§! ‚ÄĘŽĆÄŪĎúž†ĀžĚł External metadata store ŽĎź Íįú: ‚ÄĘHive ‚ÄĘGlue
- 23. Schema evolution
- 24. Schema evolution ‚ÄĘŪēėžßÄŽßĆ sourcežĚė schemaÍįÄ ŽįĒŽÄĆŽ©ī žĖīŽĖĽÍ≤Ć Žź†ÍĻĆ? ‚ÄĘÍłįŽ≥łž†ĀžúľŽ°ú HiveŽāė Glue ÍįôžĚÄ metastore žóźžĄúŽäĒ schema enforcementŽ•ľ ž†Āžö©ŪēėÍ≥† žěąžĚĆ ‚ÄĘSchema validation on write ‚ÄĘŽćįžĚīŪĄįŽ•ľ write Ūē† ŽēĆ metastorežĚė schemažôÄ Žč§Ž•īŽ©ī žč§ŪĆ® ž≤ėŽ¶¨ ‚ÄĘŽ≥ÄÍ≤ĹŽźú schemažóź ŽĒįŽĚľ schemaÍįÄ žóÖŽćįžĚīŪäł ŽźėžĖīžēľ ŪēúŽč§ ‚ÄĘEvolution
- 25. Schema evolution ‚ÄĘQ: self-describing formatžĚÄ file Žāīžóź schemaÍįÄ žěąŽäĒŽćį, evolutionžĚĄ ŪēėŽ†§Ž©ī ž†Ąž≤ī ŪĆƞ̾žĚĄ Žč§žčú žĚĹÍ≥† Žč§žčú žć®žēľŪēėŽäĒ Í≤É žēĄŽčĆÍįÄžöĒ? ‚ÄĘA: Í≤Ĺžöįžóź ŽĒįŽĚľ Žč§Ž•īŽč§! ‚Äʎ觞ĚĆ Í≤Ĺžöįžóź ŽĆÄŪēīžĄúŽäĒ ž†Ąž≤ī file evolution žóÜžĚī metastore update ŽßĆžúľŽ°ú ŪēīÍ≤į ÍįÄŽä• ‚ÄĘAppend column ‚ÄĘUpcast (byte -> short -> integer) ‚Äʎ觞ĚĆ Í≤ĹžöįžóźŽäĒ ž†Ąž≤ī file evolution ŪēĄžöĒ ‚ÄĘSchemažĚė ŽĀĚžĚī žēĄŽčĆ Í≥≥žóźžĄú column insert/delete ‚ÄĘChange data type
- 26. Schema evolution ‚ÄĘGlue + ORCŽ•ľ žĚīžö©Ūēú schema evolution Í≥ľž†ē
- 27. Schema evolution ‚ÄĘGlue + ORCŽ•ľ žĚīžö©Ūēú schema evolution Í≥ľž†ē 1. SourcežĚė schema change ÍįźžßÄ (Ž≥īŪÜĶžĚÄ error ŽįúžÉĚ) 2. GluežĚė ŪēīŽčĻ tableŽ°ú Žď§žĖīÍįÄžĄú žßĀž†Ď schema evolution žąėŪĖČ 1. Edit schema -> Add column
- 28. Schema evolution ‚ÄĘGlue + ORCŽ•ľ žĚīžö©Ūēú schema evolution Í≥ľž†ē 1. SourcežĚė schema change ÍįźžßÄ (Ž≥īŪÜĶžĚÄ error ŽįúžÉĚ) 2. GluežĚė ŪēīŽčĻ tableŽ°ú Žď§žĖīÍįÄžĄú žßĀž†Ď schema evolution žąėŪĖČ 1. Edit schema -> Add column 2. Edit table -> Table propertiesžóźžĄú žßĀž†Ď JSON žąėž†ē
- 29. Schema evolution ‚ÄĘGlue + ORCŽ•ľ žĚīžö©Ūēú schema evolution Í≥ľž†ē 1. SourcežĚė schema change ÍįźžßÄ (Ž≥īŪÜĶžĚÄ error ŽįúžÉĚ) 2. GluežĚė ŪēīŽčĻ tableŽ°ú Žď§žĖīÍįÄžĄú žßĀž†Ď schema evolution žąėŪĖČ 1. Edit schema -> Add column 2. Edit table -> Table propertiesžóźžĄú žßĀž†Ď JSON žąėž†ē 3. EMRFS consistent viewŽ•ľ žā¨žö©ŪēúŽč§Ž©ī, ŽįĒŽÄź tabležóź ŽĆÄŪēī emrfs sync ŪēĄžöĒ ‚ÄĘEvolution žčúž†źžóź žĚīŽĮł ŽĚĄžõĆž†łžěąŽäĒ clusterŽäĒ ŽćįžĚīŪĄįŽ•ľ ž†úŽĆÄŽ°ú write Ūē† žąė žóÜžĚĆ ‚ÄĘžčúž†ź žĚīŪõĄžóź ŽĚĄžöī EMRžĚÄ ÍīúžįģžĚĆ
- 30. Schema evolution ‚ÄʎߧŽ≤ą žąėŽŹôžúľŽ°ú ŪēėÍłį Í∑ÄžįģŽč§Ž©ī, ‚ÄĘSpark + Glue APIŽ•ľ ŪÜĶŪēī žěźŽŹôžúľŽ°ú ÍĶ¨ŪėĄ ÍįÄŽä•
- 31. Schema evolution ‚ÄʎߧŽ≤ą žąėŽŹôžúľŽ°ú ŪēėÍłį Í∑ÄžįģŽč§Ž©ī, ‚ÄĘSpark + Glue APIŽ•ľ ŪÜĶŪēī žěźŽŹôžúľŽ°ú ÍĶ¨ŪėĄ ÍįÄŽä• ‚ÄĘž£ľžĚėŪē† žā¨Ūē≠ ‚ÄĘGlue SDKÍįÄ žć© žĻúž†ąŪēėžßĄ žēäžĚĆ ‚ÄĘŪÖĆžĚīŽłĒžĚī ŪĀį Í≤Ĺžöį, schema partÍįÄ žó¨Žü¨ ÍįúŽ°ú ž™ľÍįúžßÄŽäĒŽćį ŽßąžßÄŽßČ partŽ•ľ žąėŽŹôžúľŽ°ú žįĺžēĄž§ėžēľ Ūē®
- 32. EMR Tuning ‚ÄĘž†Āž†ąŪēú architecture + ž†Āž†ąŪēú file format + ž†Āž†ąŪēú schema store ‚ÄĘŽćįžĚīŪĄįŽ•ľ žěė ÍįÄžßÄÍ≥† ŽÜÄŽ©ī ŽźúŽč§! ‚ÄĘžĖīŽĖĽÍ≤Ć ŪēėŽ©ī ŽĆÄžö©ŽüČ ŽćįžĚīŪĄįŽ•ľ ž†úžĚľ žěė ÍįÄžßÄÍ≥† ŽÜÄ žąė žěąžĚĄÍĻĆ? ‚ÄĘŽ≥Ķžě°ŪēėÍ≤Ć ŽÜÄÍ≥† žč∂žĚĄ ŽēĆ: S3 + EMR + Spark + Glue ‚ÄĘAd-hocžúľŽ°ú ŽÜÄÍ≥† žč∂žĚĄ ŽēĆ: S3 + Athena + Glue
- 33. EMR Tuning
- 34. EMR Tuning ‚ÄĘ(1) žĶúžč† Ž≤Ąž†ĄžĚė EMR žā¨žö©ŪēėÍłį ‚ÄĘSparkžĚė žÜ掏ĄžóźŽäĒ žÉĚÍįĀŽ≥īŽč§ Žč§žĖĎŪēú componentŽď§žĚī žėĀŪĖ•žĚĄ ŽĮłžĻ® ‚ÄĘHadoop, Hive ‚ÄĘSpark <-> S3 connector ÍĶ¨ŪėĄÍįôžĚÄ Í≤ÉžĚī Žď§žĖīžěąžĚĆ ‚ÄĘhttps://jira.apache.org/jira/browse/HIVE-16295 ‚ÄĘhttps://jira.apache.org/jira/browse/HADOOP-13786 ‚ÄĘZeppelin, Jupyter ‚ÄĘScala, Java
- 35. EMR Tuning ‚ÄĘ(1) žĶúžč† Ž≤Ąž†ĄžĚė EMR žā¨žö©ŪēėÍłį ‚ÄĘ2020ŽÖĄ 4žõĒžóź Žāėžė® EMR 6.0.0žĚÄ Žč§žĖĎŪēú major upgradeŽ•ľ ŪŹ¨Ūē® ‚ÄĘHadoop, Hive -> 3.x ‚ÄĘS3OutputCommitter ŽďĪžóź zero-rename ÍłįŽä•žĚī ž∂ĒÍįÄŽźėžĖī žÜ掏ĄÍįÄ žõĒŽďĪŪěą ŪĖ•žÉĀ ‚ÄĘScala -> 2.12 ‚ÄĘchangeÍįÄ ŽßéžĚÄ ŽßĆŪĀľ Ūēú Ž≤ą ŽÜďžĻėŽ©ī ŽĒįŽĚľÍįÄÍłįÍįÄ žČĹžßÄ žēäžúľŽĮÄŽ°ú, ž£ľÍłįž†ĀžúľŽ°ú žóÖŽćįžĚīŪäł Í∂Ćžě•
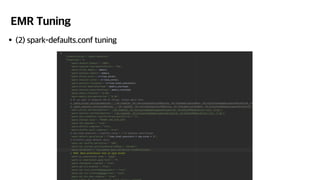
- 36. EMR Tuning ‚ÄĘ(2) spark-defaults.conf tuning ‚ÄĘSparkžóźžĄú žĄĪŽä•žóź žėĀŪĖ•žĚĄ ŽĮłžĻėŽäĒ ž§ĎžöĒŪēú žöĒžÜĆŽď§ ‚ÄĘExecutor ‚ÄĘExecutor Íįúžąė, ExecutorŽßąŽč§ Ūē†ŽčĻŽźú žěźžõź (CPU core, memory) ‚ÄĘPartition ‚ÄĘExecutorÍįÄ žēĄŽ¨īŽ¶¨ ŽßéžēĄŽŹĄ partition ÍįúžąėÍįÄ Ž∂Äž°ĪŪēėŽ©ī executorÍįÄ ŽÜÄ žąė žěąžĚĆ ‚ÄĘŽįėŽĆÄŽ°ú, partition ÍįúžąėÍįÄ ŽĄąŽ¨ī ŽßéžēĄŽŹĄ executorÍįÄ ž†ú žó≠Ūē†žĚĄ ŪēėžßÄ Ž™ĽŪē®
- 37. EMR Tuning ‚ÄĘ(2) spark-defaults.conf tuning ‚ÄĘExecutor žĄ§ž†ē ‚ÄĘžßÄÍ∑łžě¨Í∑łžóźžĄúŽäĒ 4xlarge instance žā¨žö© ‚ÄĘ16 core, 128GB memŽ°ú executor 3Íįú žā¨žö© ‚ÄĘ1 executor - 5 core, 32GB mem ‚ÄĘ128GB ž§Ď žēĹ 5GB ž†ēŽŹĄŽäĒ OSŽāė YARN ŽďĪžĚī ž†źžú† (overhead)
- 38. EMR Tuning ‚ÄĘ(2) spark-defaults.conf tuning ‚ÄĘExecutor žĄ§ž†ē ‚ÄĘžßÄÍ∑łžě¨Í∑łžóźžĄúŽäĒ 4xlarge instance žā¨žö© ‚ÄĘ16 core, 128GB memŽ°ú executor 3Íįú žā¨žö© ‚ÄĘ1 executor - 5 core, 32GB mem ‚ÄĘ128GB ž§Ď žēĹ 5GB ž†ēŽŹĄŽäĒ OSŽāė YARN ŽďĪžĚī ž†źžú† (overhead) ‚ÄĘ32GB žĚīžÉĀžúľŽ°ú Ūē†ŽčĻŪēėŽäĒ Í≤ĹžöįžóźŽäĒ compressed oopsÍįÄ disable ŽźėžĖī žė§Ū칎†§ žĄĪŽä• žÜźŪēīŽ•ľ Ž≥ľ žąė žěąžĚĆ (žēĄžėą ŽćĒ ŽßéžĚī Ūē†ŽčĻŪēėŽäĒ Í≤ÉžĚī žĘčžĚĆ) ‚ÄĘŽā®ŽäĒ 1 coreŽäĒ Hadoop daemonžĚī žā¨žö© ‚ÄĘ5 coreŽäĒ 2015ŽÖĄŽ∂ÄŪĄį ŽāīŽ†§ž†łžė§ŽäĒ magic number ‚ÄĘtoo many - context switching ŽēĆŽ¨łžóź žĄĪŽä• ž†ÄŪēė ‚ÄĘfew - ŪēėŽāėžĚė JVMžĚĄ Í≥Ķžú†ŪēėŽäĒ žĚėŽĮłÍįÄ ŽĖ®žĖīžßź ‚ÄĘdata broadcast žčú ÍįôžĚÄ executor žēąžóź žěąžúľŽ©ī ŽįĒŽ°ú ž†ĎÍ∑ľ ÍįÄŽä•
- 39. EMR Tuning ‚ÄĘ(2) spark-defaults.conf tuning ‚ÄĘExecutor žĄ§ž†ē
- 40. EMR Tuning ‚ÄĘ(2) spark-defaults.conf tuning ‚ÄĘÍįĀžĘÖ žěźžěėŪēú tips ‚ÄĘpartition Íįúžąė: ÍłįŽ≥łÍįížĚÄ 200žĚīÍ≥†, žĹĒŽďúžóźžĄú repartitionžĚīŽāė coalesceŽ°ú žĄ§ž†ē ÍįÄŽä• ‚ÄĘJVM GC: G1GC žā¨žö© ž∂Ēž≤ú ‚ÄĘJava 9Ž∂ÄŪĄī G1žĚī ÍłįŽ≥łžĚīÍ≥†, 11žóźŽäĒ ZGCÍįÄ žěąžßÄŽßĆ, SparkŽäĒ žēĄžßĀ Java 8 ‚ÄĘSpark 3.0žóźžĄ† 11+žĚĄ žßÄžõźŪēúŽč§ŽäĒ žĖėÍłįÍįÄ žěąžĚĆ ‚ÄĘhttps://issues.apache.org/jira/browse/SPARK-24417 ‚ÄĘÍįĀžĘÖ compress option: žā¨žö© ž∂Ēž≤ú ‚ÄĘSerializer: Kyro serializer ž∂Ēž≤ú ‚ÄĘžĚīŽĮł Ž™áŽ™á ÍĶįŽćįžóźŽäĒ Žď§žĖīÍįÄ žěąžßÄŽßĆ, žēĄžßĀ ÍłįŽ≥łÍįížĚÄ žēĄŽčė
- 41. EMR Tuning ‚ÄĘ(2) spark-defaults.conf tuning
- 42. EMR Tuning ‚ÄĘ(3) ÍłįŪÉÄ config tuning ‚ÄĘYARN (yarn-site) ‚ÄĘŪĀį ŪĀīŽü¨žä§ŪĄįŽ•ľ žā¨žö©ŪēúŽč§Ž©ī Fair scheduler ž†Āžö© ž∂Ēž≤ú (ÍłįŽ≥łžĚÄ FIFO) ‚ÄĘDominantResourceCalculator ‚ÄĘYARNžĚī containeržóź žěźžõźžĚĄ Ūē†ŽčĻŪē† ŽēĆ žā¨žö©ŪēėŽäĒ calculator ‚ÄĘÍłįŽ≥łžĚÄ DefaultŽ°ú, DominantÍįÄ žĘÄ ŽćĒ žßĄŪôĒŽźú Ž≤Ąž†Ą ‚ÄĘHive (hive-site) ‚ÄĘHivežóźŽŹĄ ÍįĀžĘÖ configÍįÄ žěąŽäĒŽćį Sparkžóź ž†Āžö©ŽźėŽäĒ žßÄ ŪôēžĚł ŪēĄžöĒ ‚ÄĘZeppelin, Jupyter ‚ÄĘHeap memžĚĄ ŽäėŽ¶¨Í≥† G1GC ž†Āžö© ž∂Ēž≤ú
- 43. EMR Tuning ‚ÄĘŽĻĄžö© ž†ąÍįź - Spot instance ‚ÄĘžĶúŽĆÄ 80% žĚīžÉĀ žčłÍ≤Ć žďł žąė žěąžĚĆ ‚Äʎ觎ßĆ, spotžúľŽ°ú žā¨žö©ŪēėŽäĒ ŽßĆŪĀľ resource preemption žúĄŪóėžĚī žěąžĚĆ ‚ÄĘinstanceŽ•ľ ŽļŹÍłįŽ©ī cluster žā¨ŽßĚ
- 44. EMR Tuning ‚ÄĘŽĻĄžö© ž†ąÍįź - Spot instance ‚ÄĘŽļŹÍłįžßÄ žēäÍ≥† žěė žā¨žö©ŪēėŽäĒ Ž≤ē ‚ÄĘBidding price ‚ÄĘSpot fleet ‚ÄĘMulti AZ ‚ÄĘSpot block
- 45. žßÄÍ∑łžě¨Í∑łŽäĒ ŽćįžĚīŪĄį žóĒžßÄŽčąžĖī žĪĄžö© ž§Ď! ‚ÄĘŽįúŪĎúžěźžĚė žó≠ŽüČÍ≥ľ ÍīÄÍ≥Ą žóÜžĚī Žāīžö©žĚī ŪĚ•ŽĮłŽ°úžöįžÖ®Žč§Ž©ī‚Ķ ‚ÄĘž†úÍ≤Ć ŽßźžĒÄ Ž∂ÄŪÉĀŽďúŽ¶ĹŽčąŽč§! ūüĎÄ
- 46. žĪÖ ŪõĄžõź - ŽĒ•Žü¨Žč̞̥ žúĄŪēú žąėŪēô ‚ÄĘQ&Ažóź žßąŽ¨łŪēīž£ľžčúŽäĒ Ž∂ĄÍĽė ŽďúŽ¶ĹŽčąŽč§! ‚ÄĘžĪÖžĚÄ 4Í∂Ć žěąžäĶŽčąŽč§! ‚ÄĘhttps://wikibook.co.kr/mathdl/
- 47. THANK YOU!