Belajar mudah algoritma data mining k means
7 likes19,214 views

Belajar mudah algoritma data mining k-means by ilmubiner



![ilmubiner@gmail.com
Data Mining
http://ilmubiner.blogspot.com
Pengulangan ke-2
c1
c2
a
1.5
4.5
b
1
3.5
n
1
2
3
4
a
1
2
4
5
b
1
1
3
4
a
1.5
4.5
b
1
3.5
dc1
0.5
0.5
3.201562
4.609772
dc2
4.301163
2.357023
0.471405
1.885618
c1
Ok
Ok
Pengulangan ke-3
c1
c2
Karena centroid tidak mengalami perubahan (sama dengan centroid
sebelumnya) maka proses clustering selesai
[EoF]
Page 5 of 5
c2
Ok
Ok](https://image.slidesharecdn.com/belajarmudahalgoritmadataminingk-means-140212225030-phpapp02/85/Belajar-mudah-algoritma-data-mining-k-means-5-320.jpg)





















![[PPT] BAB 2 KONSEP DASAR SISTEM, INFORMASI DAN SISTEM TEKNOLOGI INFORMASI](https://cdn.slidesharecdn.com/ss_thumbnails/a694afcf-1d4d-48a3-8e3e-1f4ee5ad595d-161105173623-thumbnail.jpg?width=560&fit=bounds)








More Related Content
What's hot (20)
Viewers also liked (20)


















Similar to Belajar mudah algoritma data mining k means (20)




















Belajar mudah algoritma data mining k means
- 1. ilmubiner@gmail.com Data Mining http://ilmubiner.blogspot.com Belajar Mudah Algoritma Data Mining Clustering : k-means Clustering atau analisis cluster adalah : ŌĆó Proses pembentukan kelompok data (cluster) dari himpunan data yang tidak diketahui kelompok-kelompok atau kelas-kelasnya. ŌĆó Proses menentukan data-data termasuk ke dalam cluster yang mana. Bisa dibilang, clustering merupakan proses untuk mengetahui kelas-kelas atau taksonomi atau botryologi, atau analisis topologi dari data-data yang ada. Dilihat dari kacamata data mining, clustering bukanlah proses klasifikasi. Karena dalam proses klasifikasi, data dikelompokkan ke dalam kelas-kelas yang telah diketahui sebelumnya. Ada beberapa metode atau model untuk melakukan clustering, antara lain : ŌĆó Model connectivity. ŌĆó Model centroid. ŌĆó Model density. ŌĆó Model subspace. ŌĆó Model group. ŌĆó Model graph based. Algoritma k-means merupakan model centroid. Model centroid adalah model yang menggunakan centroid untuk membuat cluster. Centroid adalah ŌĆ£titik tengahŌĆØ suatu cluster. Centroid berupa nilai. Centroid digunakan untuk menghitung jarak suatu objek data terhadap centroid. Suatu objek data termasuk dalam suatu cluster jika memiliki jarak terpendek terhadap centroid cluster tersebut. Secara umum algoritma k-means adalah : 1. Menentukan banyaknya cluster (k). 2. Menentukan centroid. 3. Apakah centroid-nya berubah? a. Jika ya, hitung jarak data dari centroid. b. Jikat tidak, selesai. 4. Mengelompokkan data berdasarkan jarak yang terdekat. Diagram alir (flowchart) algoritma k-means ada pada Gambar 1. Sedangkan Gambar 2 merupakan contoh posisi titik-titik data dan centroid-centroid-nya (lingkaran yang lebih besar. Gambar 1. Diagram Alir Algoritma k-means Page 1 of 5
- 2. ilmubiner@gmail.com Data Mining http://ilmubiner.blogspot.com Untuk lebih jelasnya, berikut pembahasan pemakaian algoritma k-means. Tabel 1 berisi data sumber yang akan dianalisis cluster-nya : Tabel 1. Data Sumber n 1 2 3 4 a 1 2 4 5 b 1 1 3 4 Gambar 2. Contoh Cluster 1. Tentukan banyaknya cluster adalah dua (k = 2) yang akan dibuat. Banyaknya cluster harus lebih kecil dari pada banyaknya data (k < n). 2. Tentukan centroid setiap cluster. Untuk menentukan centroid awal (initial centroid) banyak metode yang dapat digunakan. Di sini metode yang digunakan adalah mengambil data dari data sumber, secara acak atau random (Sel yang berwarna kuning dan hijau di Tabel 1). Tabel 2. Centroid pada Pengulangan ke-0 c1 c2 a 1 2 b 1 1 Untuk pengulangan berikutnya (pengulangan ke-1 sampai selesai), centroid baru dihitung dengan menghitung nilai rata-rata data pada setiap cluster. Jika centroid baru berbeda dengan centroid sebelumnya, maka proses dilanjutkan ke langkah berikutnya. Namun jika centroid yang baru dihitung sama dengan centroid sebelumnya, maka proses clustering selesai. 3. Hitung jarak data dengan centroid. Rumus-rumus untuk menghitung jarak antara lain : a. Euclidean. b. Manhattan / City Block. c. Minkowski. Rumus yang digunakan di sini adalah rumus Euclidean Distance : Page 2 of 5
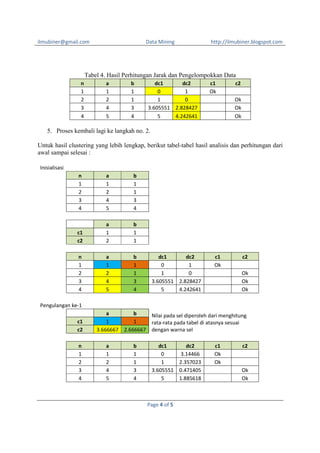
- 3. ilmubiner@gmail.com = = = = = , Data Mining = ( http://ilmubiner.blogspot.com ŌłÆ ) Jarak data dengan cluster 1 adalah : ( , ) = ( ( +, ) = ( ( , ( , ) = ( ) = ( % + ŌłÆ ) +( ŌłÆ ) +( ŌłÆ ŌłÆ ) +( ) +( % + ŌłÆ !) = (1 ŌłÆ 1) + (1 ŌłÆ 1) = 0 ŌłÆ !) = (5 ŌłÆ 1) + (4 ŌłÆ 1) = 5 ŌłÆ ŌłÆ !) !) = = (2 ŌłÆ 1) + (1 ŌłÆ 1) = 1 (4 ŌłÆ 1) + (3 ŌłÆ 1) = 3.605551 Jarak data dengan cluster 2 adalah : ( , ) = ( ( +, ) = ( ( , ( , ) = ( ) = ( % + ŌłÆ ) +( ŌłÆ ) +( ŌłÆ ŌłÆ ) +( ) +( % + ŌłÆ !) = (1 ŌłÆ 2) + (1 ŌłÆ 1) = 1 ŌłÆ !) = (5 ŌłÆ 2) + (4 ŌłÆ 1) = 4.242641 ŌłÆ ŌłÆ !) !) = = (2 ŌłÆ 2) + (1 ŌłÆ 1) = 0 (4 ŌłÆ 2) + (3 ŌłÆ 1) = 2.828427 Untuk seterusnya, hitung jarak pada setiap baris data, dan hasilnya seperti pada Tabel 3. Tabel 3. Hasil Perhitungan Jarak n 1 2 3 4 a 1 2 4 5 b 1 1 3 4 dc1 dc2 0 1 1 0 3.605551 2.828427 5 4.242641 4. Kelompokkan data sesuai dengan cluster-nya, yaitu data yang memiliki jarak terpendek. Contoh; karena ( , ) < ( , ) maka masuk ke dalam cluster 1. Pada Tabel 4, data n = 1 masuk ke dalam cluster 1 karena dc1 < dc2, sedangkan data n = 2, 3, 4 masuk ke dalam cluster 2 karena dc2 < dc1. Page 3 of 5
- 4. ilmubiner@gmail.com Data Mining http://ilmubiner.blogspot.com Tabel 4. Hasil Perhitungan Jarak dan Pengelompokkan Data n 1 2 3 4 a 1 2 4 5 b 1 1 3 4 dc1 dc2 0 1 1 0 3.605551 2.828427 5 4.242641 c1 Ok c2 Ok Ok Ok 5. Proses kembali lagi ke langkah no. 2. Untuk hasil clustering yang lebih lengkap, berikut tabel-tabel hasil analisis dan perhitungan dari awal sampai selesai : Inisialisasi n 1 2 3 4 a 1 2 4 5 b 1 1 3 4 c1 c2 a 1 2 b 1 1 n 1 2 3 4 a 1 2 4 5 b 1 1 3 4 dc1 dc2 0 1 1 0 3.605551 2.828427 5 4.242641 c1 Ok c2 Ok Ok Ok Pengulangan ke-1 c1 c2 n 1 2 3 4 a b Nilai pada sel diperoleh dari menghitung 1 1 rata-rata pada tabel di atasnya sesuai 3.666667 2.666667 dengan warna sel a 1 2 4 5 b 1 1 3 4 dc1 dc2 0 3.14466 1 2.357023 3.605551 0.471405 5 1.885618 Page 4 of 5 c1 Ok Ok c2 Ok Ok
- 5. ilmubiner@gmail.com Data Mining http://ilmubiner.blogspot.com Pengulangan ke-2 c1 c2 a 1.5 4.5 b 1 3.5 n 1 2 3 4 a 1 2 4 5 b 1 1 3 4 a 1.5 4.5 b 1 3.5 dc1 0.5 0.5 3.201562 4.609772 dc2 4.301163 2.357023 0.471405 1.885618 c1 Ok Ok Pengulangan ke-3 c1 c2 Karena centroid tidak mengalami perubahan (sama dengan centroid sebelumnya) maka proses clustering selesai [EoF] Page 5 of 5 c2 Ok Ok