
















Cassandra
- 1. Cassandra
- 2. ╠²/
- 5. ╠²(allnewangel@gmail.com) 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 6. ņ╣┤ņé░ļō£ļØ╝
- 8. ╠²Key-Value
- 9. ╠²ĻĄ¼ņĪ░ņØś
- 11. ╠²BigTable
- 12. ╠²ņ╗¼ļ¤╝
- 13. ╠²ĻĖ░ļ░śņØś
- 14. ╠²ļŹ░ņØ┤ĒāĆ
- 15. ╠²ļ¬©ļŹĖĻ│╝
- 16. ╠²Amazon
- 17. ╠² DynamoņØś
- 18. ╠²ļČäņé░
- 19. ╠²ļ¬©ļŹĖņØä
- 20. ╠²ĻĖ░ļ░śņ£╝ļĪ£
- 22. ╠²ņØśĒĢ┤
- 23. ╠²2008ļģäņŚÉ
- 25. ╠²Ļ│ĄĻ░£ļÉ£
- 26. ╠²ļČäņé░
- 27. ╠²ļŹ░ņØ┤Ēä░
- 29. ╠²3ņøö
- 30. ╠²ņĢäĒīīņ╣śņØś
- 32. ╠²1ļģä
- 33. ╠²ļ¦īņØĖ
- 34. ╠²2010ļģä
- 35. ╠²2ņøö
- 36. ╠² Top-level
- 37. ╠²ņĢäĒīīņ╣ś
- 40. ╠²DynamoņØś
- 41. ╠²ĒŖ╣ņ¦ĢņØĖ
- 43. ╠²ņØ┤ņÜ®ĒĢ£
- 44. ╠²Key- Value
- 45. ╠²ņŖżĒåĀļ”¼ņ¦Ć,
- 46. ╠²Eventual
- 47. ╠²Consistency
- 48. ╠²ĻĄ¼ņĪ░ļź╝
- 49. ╠²Ļ░Ćņ¦ĆĻ│Ā
- 50. ╠²ņ׳ņ£╝ ļ®┤ņä£
- 51. ╠²įŲ╝ļ”¼
- 52. ╠²ĻĄ¼ņĪ░ļĪ£
- 53. ╠²GoogleņØś
- 54. ╠²BigTable
- 55. ╠²ĻĄ¼ņĪ░ņØĖ
- 56. ╠²Ļ│äņĖĄņĀü
- 57. ╠² Column
- 58. ╠²ĻĄ¼ņĪ░ļź╝
- 59. ╠²ļ░░Ļ▓Įņ£╝ļĪ£
- 60. ╠²ĒĢśĻ│Ā
- 61. ╠²ņ׳ņØī. 2 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 62. ņŻ╝ņÜö
- 64. ╠²ļ░░Ļ▓Įņ£╝ļĪ£
- 65. ╠²Key
- 66. ╠²ĻĄ¼Ļ░ä
- 67. ╠²ņäżņĀĢņ£╝ļĪ£
- 69. ╠²ņČöĻ░Ć
- 70. ╠²ļ░Å
- 72. ╠²ņĀäņ▓┤
- 73. ╠²ņĀČ─ņן
- 74. ╠²Ļ│ĄĻ░äņØ┤
- 75. ╠²ņ£ĀņŚ░ĒĢśĻ▓ī
- 76. ╠²ĒÖĢņן/ņČĢņåī
- 79. ╠²ļŹ░ņØ┤Ēä░
- 80. ╠²ļ│ĄņĀ£ļ│ĖņØä
- 81. ╠²ĻĄ¼ņä▒ĒĢśņŚ¼
- 82. ╠²ĒŖ╣ņĀĢ
- 83. ╠²ļģĖļō£
- 85. ╠²ņä£ļ╣äņŖżņŚÉ
- 86. ╠²ņśüĒ¢źņØä
- 87. ╠²ņŻ╝ņ¦Ć
- 88. ╠²ņĢŖĻ│Ā
- 89. ╠²ļŹ░ņØ┤Ēä░
- 90. ╠²ņ£Āņŗż
- 92. ╠²ĻĄ¼ņĪ░ļĪ£
- 93. ╠²Hash
- 95. ╠²ĒåĄĒĢ£
- 97. ╠²ļ╣ĀļźĖ
- 99. ╠²ņŗżņĀ£
- 100. ╠²ņŖżĒåĀļ”¼ņ¦Ć
- 101. ╠²ĻĄ¼ņĪ░ņŚÉ
- 102. ╠²ņĀüņÜ®
- 103. ╠²ņĀä
- 104. ╠² CommitLogņŚÉ
- 105. ╠²ļ│ĆĻ▓Įņé¼ĒĢŁņØä
- 106. ╠²ļ©╝ņĀĆ
- 107. ╠²ĻĖ░ļĪØ
- 108. ╠²ļ╣ĀļźĖ
- 109. ╠²ņä▒ļŖźņØä
- 110. ╠²ļ│┤ņ×ä
- 111. ╠² (MySQL
- 112. ╠²ļīĆļ╣ä
- 114. ╠²Schema
- 115. ╠²ņĀüņÜ®ņĢŖņØī
- 116. ╠²(Rowļ¦łļŗż
- 117. ╠²ņåŹņä▒ņØä
- 119. ╠²ņ▓śļ”¼
- 120. ╠²ĒĢ©ņłśļōżņØä
- 121. ╠²ļ¬©ļæÉ
- 122. ╠²ņ¦ĆņøÉĒĢśņ¦ĆļŖö
- 123. ╠²ņĢŖņØī 3 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 124. ņŻ╝ņÜö
- 126. ╠²ņĀĢņØśĒĢ┤
- 127. ╠²ļåōņØĆ
- 128. ╠²EntityņŚÉ
- 129. ╠²ļīĆĒĢ£
- 130. ╠²JOINņ¦ĆņøÉ
- 131. ╠²ņĢŖņØī(ņØæņÜ®
- 132. ╠²ĒÖśĻ▓ĮņŚÉ ņä£
- 133. ╠²ĻĄ¼Ēśä) l’ü¼ 1ņ░©
- 134. ╠²ņØĖļŹ▒ņŖżļŖö
- 135. ╠²Column
- 136. ╠²FamilyņØś
- 137. ╠²ColumnņØ┤ļ”äņØä
- 138. ╠²ĻĖ░ļ░ś
- 139. ╠²(2ņ░©
- 140. ╠²ņØĖ ļŹ▒ņŖżļŖö
- 141. ╠²ColumnņØś
- 142. ╠²Value) l’ü¼ ņé¼ņĀä
- 143. ╠²ņĀĢĒĢ┤ņ¦ä
- 144. ╠²ņØĖļŹ▒ņŖżņŚÉ
- 145. ╠²ļīĆĒĢ┤ņä£ļ¦ī
- 146. ╠²ņĀĢļĀ¼
- 147. ╠²ņłśĒ¢ē
- 148. ╠²Ļ░ĆļŖź(1ņ░©
- 149. ╠²:
- 150. ╠²Column ļ¬ģ,
- 151. ╠²2ņ░©
- 152. ╠²:
- 153. ╠²Column
- 155. ╠²ņĀäņåĪ
- 156. ╠²ĒöäļĪ£ĒåĀņĮ£ļĪ£
- 157. ╠²Thriftļź╝
- 158. ╠²ņØ┤ņÜ®.
- 159. ╠²ThriftļŖö
- 160. ╠²FacebookņŚÉņä£
- 161. ╠² ņŗ£ņ×æļÉ£
- 162. ╠²ĒöäļĪ£ņĀØĒŖĖļĪ£
- 163. ╠²Cross-Languageļź╝
- 164. ╠²ņ¦ĆņøÉĒĢśņŚ¼
- 165. ╠²ņ¢Ėņ¢┤ņŚÉ
- 166. ╠²ņØśņĪ┤ņä▒
- 167. ╠² ņŚåņØ┤
- 168. ╠²ļ¬©ļōĀ
- 169. ╠²ĒÖśĻ▓ĮņŚÉņä£
- 170. ╠²ņØ┤ņÜ®
- 171. ╠²Ļ░ĆļŖź l’ü¼ ļ¼╝ļ”¼
- 172. ╠²ĒīīņØ╝
- 173. ╠²ņĀČ─ņן
- 174. ╠²ĻĄ¼ņĪ░ļĪ£
- 175. ╠²SSTableņØä
- 176. ╠²ņé¼ņÜ® 4 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 177. įŲ╝ļ”¼
- 178. ╠²ņŖżĒåĀļ”¼ņ¦Ć
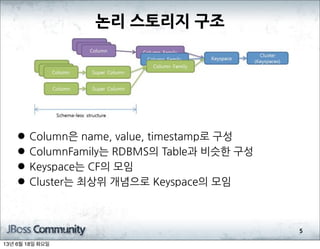
- 180. ╠²name,
- 181. ╠²value,
- 182. ╠²timestampļĪ£
- 184. ╠²RDBMSņØś
- 185. ╠²TableĻ│╝
- 186. ╠²ļ╣äņŖĘĒĢ£
- 188. ╠²CFņØś
- 190. ╠²ņĄ£ņāüņ£ä
- 191. ╠²Ļ░£ļģÉņ£╝ļĪ£
- 192. ╠²KeyspaceņØś
- 193. ╠²ļ¬©ņ×ä 5 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 194. ļ¼╝ļ”¼
- 195. ╠²ņŖżĒåĀļ”¼ņ¦Ć
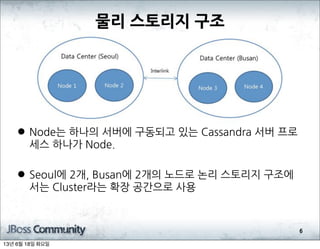
- 197. ╠²ĒĢśļéśņØś
- 198. ╠²ņä£ļ▓äņŚÉ
- 199. ╠²ĻĄ¼ļÅÖļÉśĻ│Ā
- 200. ╠²ņ׳ļŖö
- 201. ╠²Cassandra
- 202. ╠²ņä£ļ▓ä
- 203. ╠²ĒöäļĪ£ ņäĖņŖż
- 204. ╠²ĒĢśļéśĻ░Ć
- 206. ╠²2Ļ░£,
- 207. ╠²BusanņŚÉ
- 208. ╠²2Ļ░£ņØś
- 209. ╠²ļģĖļō£ļĪ£
- 210. ╠²įŲ╝ļ”¼
- 211. ╠²ņŖżĒåĀļ”¼ņ¦Ć
- 212. ╠²ĻĄ¼ņĪ░ņŚÉ ņä£ļŖö
- 213. ╠²ClusterļØ╝ļŖö
- 214. ╠²ĒÖĢņן
- 215. ╠²Ļ│ĄĻ░äņ£╝ļĪ£
- 216. ╠²ņé¼ņÜ® 6 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
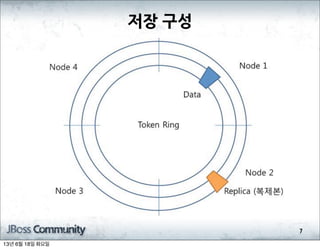
- 217. ņĀČ─ņן
- 218. ╠²ĻĄ¼ņä▒ 7 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 219. ļ¼┤Ļ▓░ņä▒
- 221. ╠²Ļ░ÖņØĆ
- 222. ╠²NoSQLņØĆ
- 223. ╠²ļ│┤ĒåĄ
- 224. ╠²CAP(BrewerņØś
- 225. ╠²ņØ┤ļĪĀ)ļĪ£
- 226. ╠² ļ¼┤Ļ▓░ņä▒
- 227. ╠²ņ£Āņ¦Ć ŌĆō C
- 228. ╠²:
- 229. ╠²Consistency
- 230. ╠²(ļ¼┤Ļ▓░ņä▒) ŌĆō A
- 231. ╠²:
- 232. ╠²Availability
- 233. ╠²(Ļ░ĆņÜ®ņä▒) ŌĆō P
- 234. ╠²:
- 235. ╠²Partition
- 236. ╠²tolerance
- 237. ╠²(ļČäĒĢĀņŚÉ
- 238. ╠²ļīĆĒĢ£
- 239. ╠²ļé┤ĻĄ¼ņä▒
- 240. ╠²:
- 241. ╠²ļČäĒĢĀ
- 243. ╠²2Ļ░Ćņ¦Ćļź╝
- 244. ╠²ļ¦īņĪ▒ĒĢśĻ│Ā
- 245. ╠²1Ļ░ĆļŖö
- 246. ╠²ņāüĒÖ®ņŚÉ
- 247. ╠²ņØśĒĢ┤
- 248. ╠²ļ¦īņĪ▒.
- 249. ╠² CassandraņØś
- 250. ╠²Ļ▓ĮņÜ░
- 251. ╠²APļź╝
- 252. ╠²ļ¦īņĪ▒.
- 253. ╠² l’ü¼ CņØś
- 254. ╠²Ļ▓ĮņÜ░
- 255. ╠²Eventual
- 256. ╠²ConsistencyņŚÉ
- 257. ╠²ņØśĒĢ┤
- 258. ╠²ļ¦īņĪ▒.
- 259. ╠²ņ”ē
- 260. ╠²ļģĖļō£
- 261. ╠²ĻĄ¼ņä▒
- 262. ╠² ļ░Å
- 263. ╠²ņØĮĻ│Ā
- 264. ╠²ņōĖļĢīņØś
- 266. ╠²ļö░ļØ╝
- 267. ╠²ļŗ¼ļØ╝ņ¦É. 8 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 268. ņ║Éņŗ▒
- 269. ╠²ņ¦ĆņøÉ l’ü¼ Ļ░ü
- 270. ╠²CFļ¦łļŗż
- 271. ╠²Row
- 272. ╠²CacheņÖĆ
- 273. ╠²Key
- 274. ╠²Cacheļź╝
- 275. ╠²ņäżņĀĢ l’ü¼ Row
- 276. ╠²CacheļŖö
- 277. ╠²ņŗżņĀ£
- 278. ╠²ļŹ░ņØ┤Ēä░ļź╝
- 279. ╠²ļ®öļ¬©ļ”¼ņŚÉ
- 280. ╠²ņĀüņ×¼ĒĢ┤
- 281. ╠²ļåōļŖö
- 282. ╠²Ļ▓āņØä
- 283. ╠²
- 284. ╠²
- 285. ╠²
- 286. ╠² ņØśļ»Ė l’ü¼ Key
- 287. ╠²CacheļŖö
- 288. ╠²Keyļź╝
- 289. ╠²ņ║Éņŗ▒ĒĢ┤
- 290. ╠²ļåōļŖö
- 291. ╠²Ļ▓āņØä
- 292. ╠²ņØśļ»Ė l’ü¼ Ļ░Ćņן
- 293. ╠²ĻĖ░ļ│ĖņĀüņØĖ
- 294. ╠²ĒśĢĒā£ļĪ£
- 295. ╠²ņ║Éņŗ▒ņØä
- 296. ╠²ņ¦ĆņøÉ 9 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 297. Hector
- 299. ╠²ņ£äĒĢ£
- 300. ╠²ĒĢśņØ┤
- 301. ╠²ļĀłļ▓©
- 302. ╠²Ļ░Øņ▓┤
- 303. ╠²ņ¦ĆĒ¢ź
- 304. ╠²ņØĖĒä░ĒÄśņØ┤ņŖżļź╝
- 305. ╠²ņĀ£Ļ│Ą l’ü¼ ņóĆ
- 306. ╠²ļŹö
- 307. ╠²ļåÆņØĆ
- 308. ╠²ļĀłļ▓©ņØś
- 309. ╠²Ļ╣öļüöĒĢ£
- 310. ╠²APIļź╝
- 311. ╠²ņĀ£Ļ│ĄĒĢśļŖö
- 312. ╠²Java
- 314. ╠²ņ¦ĆņøÉ
- 316. ╠²ĒÆĆļ¦ü
- 319. ╠²(ņ×¼ņŗ£ļÅä
- 320. ╠²ņŚåņØī,
- 321. ╠²ņŚÉļ¤¼
- 322. ╠²ļ░£ņāØņŗ£
- 323. ╠²ļ░öļĪ£
- 325. ╠²(ĒżĻĖ░ĒĢśĻĖ░
- 326. ╠²ņĀä
- 327. ╠²ļŗżļźĖ
- 328. ╠²ĒśĖņŖżĒŖĖņŚÉ
- 329. ╠²ĒĢ£ļ▓ł
- 330. ╠² ļŹö
- 332. ╠²(ĒżĻĖ░ĒĢśĻĖ░
- 333. ╠²ņĀä
- 334. ╠²ļ¬©ļōĀ
- 335. ╠²ĒśĖņŖżĒŖĖņŚÉ
- 336. ╠²ņŗ£ļÅä,
- 338. ╠²ļĪ£ļō£
- 339. ╠²ļ░Ėļ¤░ņŗ▒
- 342. ╠²Ļ░ĆņÜ®ņä▒,
- 343. ╠²Ļ┤æļ▓öņ£äĒĢ£
- 344. ╠²ļĪ£Ļ╣ģ,
- 345. ╠²ĒÅ┤ļ¦ü
- 346. ╠²ĻĄ¼ņä▒,
- 347. ╠²Thrift
- 348. ╠²ņ║ĪņŖÉĒÖö,
- 349. ╠²ļ¬©ļōłĒÖö
- 350. ╠²ļō▒ 10 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
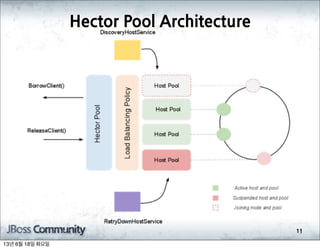
- 351. Hector
- 352. ╠²Pool
- 353. ╠²Architecture 11 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 354. Hector
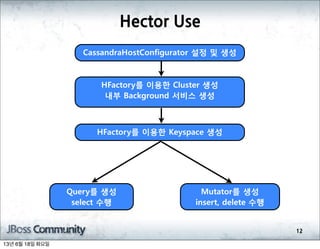
- 355. ╠²Use 12 CassandraHostConfigurator ņäżņĀĢ ļ░Å ņāØņä▒ HFactoryļź╝ ņØ┤ņÜ®ĒĢ£ Cluster ņāØņä▒ ļé┤ļČĆ Background ņä£ļ╣äņŖż ņāØņä▒ HFactoryļź╝ ņØ┤ņÜ®ĒĢ£ Keyspace ņāØņä▒ Queryļź╝ ņāØņä▒ select ņłśĒ¢ē Mutatorļź╝ ņāØņä▒ insert, delete ņłśĒ¢ē 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
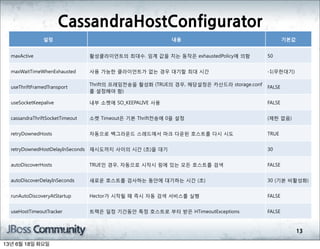
- 356. CassandraHostConfigurator 13 ņäżņĀĢ ļé┤ņÜ® ĻĖ░ļ│ĖĻ░Æ maxActive ĒÖ£ņä▒Ēü┤ļØ╝ņØ┤ņ¢ĖĒŖĖņØś ņĄ£ļīĆņłś. ņ×äĻ│ä Ļ░ÆņØä ņ╣śļŖö ļÅÖņ×æņØĆ exhaustedPolicyņŚÉ ņØśĒĢ© 50 maxWaitTimeWhenExhausted ņé¼ņÜ® Ļ░ĆļŖźĒĢ£ Ēü┤ļØ╝ņØ┤ņ¢ĖĒŖĖĻ░Ć ņŚåļŖö Ļ▓ĮņÜ░ ļīĆĻĖ░ĒĢĀ ņĄ£ļīĆ ņŗ£Ļ░ä -1(ļ¼┤ĒĢ£ļīĆĻĖ░) useThriftFramedTransport ThriftņØś ĒöäļĀłņ×äņĀäņåĪņØä ĒÖ£ņä▒ĒÖö (TRUEņØś Ļ▓ĮņÜ░, ĒĢ┤ļŗ╣ņäżņĀĢņØĆ ņ╣┤ņé░ļō£ļØ╝ storage.conf ļź╝ ņäżņĀĢĒĢ┤ņĢ╝ ĒĢ©) FALSE useSocketKeepalive ļé┤ļČĆ ņåīņ╝ōņŚÉ SO_KEEPALIVE ņé¼ņÜ® FALSE cassandraThriftSocketTimeout ņåīņ╝ō TimeoutņØĆ ĻĖ░ļ│Ė ThriftņĀäņåĪņŚÉ 0ņØä ņäżņĀĢ (ņĀ£ĒĢ£ ņŚåņØī) retryDownedHosts ņ×ÉļÅÖņ£╝ļĪ£ ļ░▒ĻĘĖļØ╝ņÜ┤ļō£ ņŖżļĀłļō£ņŚÉņä£ ļ¦łĒü¼ ļŗżņÜ┤ļÉ£ ĒśĖņŖżĒŖĖļź╝ ļŗżņŗ£ ņŗ£ļÅä TRUE retryDownedHostDelayInSeconds ņ×¼ņŗ£ļÅäĻ╣īņ¦Ć ņé¼ņØ┤ņØś ņŗ£Ļ░ä (ņ┤ł)ņØä ļīĆĻĖ░ 30 autoDiscoverHosts TRUEņØĖ Ļ▓ĮņÜ░, ņ×ÉļÅÖņ£╝ļĪ£ ņŗ£ņ×æņŗ£ ļ¦üņŚÉ ņ׳ļŖö ļ¬©ļōĀ ĒśĖņŖżĒŖĖļź╝ Ļ▓Ćņāē FALSE autoDiscoverDelayInSeconds ņāłļĪ£ņÜ┤ ĒśĖņŖżĒŖĖļź╝ Ļ▓Ćņé¼ĒĢśļŖö ļÅÖņĢłņŚÉ ļīĆĻĖ░ĒĢśļŖö ņŗ£Ļ░ä (ņ┤ł) 30 (ĻĖ░ļ│Ė ļ╣äĒÖ£ņä▒ĒÖö) runAutoDiscoveryAtStartup HectorĻ░Ć ņŗ£ņ×æļÉĀ ļĢī ņ”ēņŗ£ ņ×ÉļÅÖ Ļ▓Ćņāē ņä£ļ╣äņŖżļź╝ ņŗżĒ¢ē FALSE useHostTimeoutTracker ĒŖĖļ×ÖņØĆ ņØ╝ņĀĢ ĻĖ░Ļ░äļÅÖņĢł ĒŖ╣ņĀĢ ĒśĖņŖżĒŖĖļĪ£ ļČĆĒä░ ļ░øņØĆ HTimeoutExceptions FALSE 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 358. ╠²ņ×ÉļÅÖ
- 360. ╠²ļ¦üņŚÉ
- 361. ╠²ņ׳ļŖö
- 362. ╠²ļ¬©ļōĀ
- 363. ╠²ļģĖļō£ļź╝
- 364. ╠²Ļ░Ćņ¦ĆĻ│Ā
- 365. ╠²ņÖĆņä£
- 366. ╠²ļÅÖņØ╝ĒĢ£
- 367. ╠²ņäżņĀĢņØä
- 368. ╠² ņĀüņÜ®. l’ü¼ ņØ┤
- 369. ╠²ĻĖ░ļŖźņØĆ
- 370. ╠²ĒŖ╣ņĀĢ
- 371. ╠²ĒĢśļō£ņø©ņ¢┤
- 372. ╠²ļ░Å
- 373. ╠²ļäżĒŖĖņøīĒü¼
- 374. ╠²ĻĄ¼ņä▒ņŚÉņä£
- 375. ╠²ņĀ£ļīĆļĪ£,
- 376. ╠²ļśÉļŖö
- 377. ╠² ļÅÖņ×æĒĢśņ¦Ć
- 378. ╠²ņĢŖļŖö
- 379. ╠²ļ¬ć
- 380. ╠²Ļ░Ćņ¦Ć
- 381. ╠²ņĀ£ĒĢ£
- 382. ╠²ņØä
- 383. ╠²Ļ░Ćņ¦ĆĻ│Ā
- 384. ╠²ņ׳ņ¢┤ņä£
- 385. ╠²ĻĖ░ļ│ĖņĀüņ£╝ļĪ£
- 387. ╠²ĻĖ░ļŖźņØĆ
- 388. ╠²ņé¼ņÜ®ĒĢśļĀżļ®┤
- 391. ╠²ņäżņĀĢļÉśņ¢┤ņĢ╝
- 393. ╠²ņ”ēņŗ£
- 394. ╠²ļÅÖņ×æņŗ£ļŖö
- 396. ╠²ņśĄņģśņØä
- 397. ╠² TRUEļĪ£
- 398. ╠²ņäżņĀĢ 14 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 400. ╠²ņŗżĒī©
- 401. ╠²ĒśĖņŖżĒŖĖ
- 403. ╠²ĒśĖņŖżĒŖĖļź╝
- 405. ╠²Ļ░äĻ▓®ņ£╝ļĪ£
- 406. ╠²ņ×¼ņŗ£ļÅäļź╝
- 407. ╠²ĒĢśļŖö
- 408. ╠²Ļ│ĀĻ░ĆņÜ®ņä▒
- 410. ╠²30ņ┤ł(ĻĖ░ļ│ĖĻ░Æ)
- 411. ╠²Ļ░äĻ▓®ņ£╝ļĪ£
- 413. ╠²ConnectionņØä
- 414. ╠²ņ▓┤Ēü¼,
- 415. ╠²DownļÉ£
- 416. ╠²HostņØś
- 417. ╠²ņ×¼ņŚ░Ļ▓░
- 418. ╠²ņŗ£ļÅä 15 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 419. Defining
- 420. ╠²Consistency
- 422. ╠²Keyspace
- 423. ╠²ņāØņä▒
- 424. ╠²ņŗ£ņŚÉ
- 426. ╠²HectorļÅä
- 427. ╠²ļŗżļźĖ
- 430. ╠²Consistency
- 431. ╠²Level ŌĆō ANY
- 432. ╠²:
- 433. ╠²ņØ╝ļČĆ
- 434. ╠²ReplicaĻ░Ć
- 435. ╠²ņØæļŗĄĒĢĀ
- 436. ╠²ļĢī
- 437. ╠²Ļ╣īņ¦Ć
- 438. ╠²ĻĖ░ļŗżļ”╝ ŌĆō ONE
- 439. ╠²:
- 440. ╠²ĒĢśļéśņØś
- 441. ╠²ReplicaĻ░Ć
- 442. ╠²ņØæļŗĄĒĢĀ
- 443. ╠²ļĢī
- 444. ╠²Ļ╣īņ¦Ć
- 445. ╠²ĻĖ░ļŗżļ”╝ ŌĆō TWO
- 446. ╠²:
- 447. ╠²ļæÉ
- 448. ╠²Ļ░£ņØś
- 449. ╠²ReplicaĻ░Ć
- 450. ╠²ņØæļŗĄĒĢĀ
- 451. ╠²ļĢī
- 452. ╠²Ļ╣īņ¦Ć
- 454. ╠²:
- 455. ╠²ņäĖ
- 456. ╠²Ļ░£ņØś
- 457. ╠²ReplicaĻ░Ć
- 458. ╠²ņØæļŗĄĒĢĀ
- 459. ╠²ļĢī
- 460. ╠²Ļ╣īņ¦Ć
- 462. ╠²:
- 463. ╠²ņŚ░Ļ▓░ņØ┤ņłśļ”ĮļÉ£
- 465. ╠²:
- 466. ╠²Ļ░ü
- 468. ╠²quorumņØä
- 470. ╠²:
- 471. ╠²ReplicaņØś
- 472. ╠²quorumņØä
- 475. ╠²:
- 476. ╠²Ēü┤ļØ╝ņØ┤ņ¢ĖĒŖĖņŚÉ
- 477. ╠²ļ░śĒÖśĒĢśĻĖ░
- 478. ╠²ņĀäņŚÉ
- 479. ╠²ļ¬©ļōĀ
- 480. ╠²Replicaļź╝
- 483. ╠²CFņŚÉ
- 484. ╠²ļīĆĒĢ┤
- 485. ╠²ņ×æņŚģ
- 486. ╠²ņ£ĀĒśĢļ│äļĪ£
- 487. ╠²LevelņØä
- 488. ╠²ņäżņĀĢĒĢĀ
- 489. ╠²ņłś
- 490. ╠²ņ׳ņØī
- 491. ╠² (ņØĮĻĖ░,
- 492. ╠²ņō░ĻĖ░) 16 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 493. ļŗ©ņØ╝
- 494. ╠²Ē¢ēņŚÉ
- 495. ╠²ļīĆĒĢ£
- 496. ╠²ņ▓śļ”¼
- 497. ╠²ņāśĒöī /**
- 498. ╠²*
- 499. ╠²Insert
- 500. ╠²a
- 501. ╠²Single
- 502. ╠²Row
- 503. ╠²with
- 504. ╠²a
- 505. ╠²Single
- 506. ╠²Column
- 507. ╠²*/ MutatorString ╠²mutator ╠²= ╠²HFactory.createMutator(keyspace, ╠²stringSerializer); mutator.insert(jsmith, ╠²Standard1, ╠²HFactory.createStringColumn(first, ╠²John)); /**
- 508. ╠²*
- 509. ╠²Retrieve
- 510. ╠²a
- 511. ╠²Single
- 512. ╠²Column
- 513. ╠²*/ ColumnQueryString, ╠²String, ╠²String ╠²columnQuery ╠²= ╠² ╠² ╠² ╠²HFactory.createStringColumnQuery(keyspace); columnQuery.setColumnFamily(Standard1).setKey(jsmith).setName(first); QueryResultHColumnString, ╠²String ╠²result ╠²= ╠²columnQuery.execute(); /**
- 514. ╠²*
- 515. ╠²Removing
- 516. ╠²a
- 517. ╠²Single
- 518. ╠²Column
- 519. ╠²*/ mutator.delete(jsmith, ╠²Standard1, ╠²first, ╠²stringSerializer); 17 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 520. ļŗżņżæ
- 521. ╠²Ē¢ēņŚÉ
- 522. ╠²ļīĆĒĢ£
- 523. ╠²ņ▓śļ”¼
- 524. ╠²ņāśĒöī
- 525. ╠²1 /**
- 526. ╠²*
- 527. ╠²Insert
- 528. ╠²Multiple
- 529. ╠²Columns
- 530. ╠²with
- 531. ╠²Mutator
- 532. ╠²*/ mutator.addInsertion(jsmith, ╠²Standard1, HFactory.createStringColumn(first, ╠²John)) .addInsertion(jsmith, ╠²Standard1, ╠²HFactory.createStringColumn(last, ╠²Smith)) .addInsertion(jsmith, ╠²Standard1, ╠²HFactory.createStringColumn(middle, ╠²Q)); mutator.execute(); /**
- 533. ╠²*
- 534. ╠²Retrieving
- 535. ╠²Multiple
- 536. ╠²Columns
- 537. ╠²with
- 538. ╠²SliceRange
- 539. ╠²*/ SliceQueryString, ╠²String ╠²q ╠²= ╠²HFactory.createSliceQuery(ko, ╠²se, ╠²se, ╠²se); q.setColumnFamily(cf) .setKey(jsmith) .setColumnNames(first, ╠²last, ╠²middle); ResultColumnSliceString, ╠²String ╠²r ╠²= ╠²q.execute(); 18 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 540. ļŗżņżæ
- 541. ╠²Ē¢ēņŚÉ
- 542. ╠²ļīĆĒĢ£
- 543. ╠²ņ▓śļ”¼
- 544. ╠²ņāśĒöī
- 545. ╠²2 /**
- 546. ╠²*
- 547. ╠²Deleting
- 548. ╠²Multiple
- 549. ╠²Columns
- 550. ╠²with
- 551. ╠²Mutator
- 552. ╠²*/ mutator.delete(jsmith, ╠²Standard1, ╠²null, ╠²stringSerializer); mutator.addDeletion(jsmith, ╠²Standard1, ╠²middle, ╠²stringSerializer) .addDeletion(jsmith, ╠²Standard1, ╠²last, ╠²stringSerializer) .execute(); /**
- 553. ╠²*
- 554. ╠²Getting
- 555. ╠²Multiple
- 556. ╠²Rows
- 557. ╠²with
- 558. ╠²MultigetSliceQuery
- 559. ╠²*/ MultigetSliceQueryString, ╠²String, ╠²String ╠²multigetSliceQuery ╠²= ╠² ╠² ╠² ╠²HFactory.createMultigetSliceQuery(keyspace, ╠²stringSerializer, ╠²stringSerializer, ╠² stringSerializer); multigetSliceQuery.setColumnFamily(Standard1); multigetSliceQuery.setKeys(fake_key_0, ╠²fake_key_1, ╠² ╠² ╠² ╠²fake_key_2, ╠²fake_key_3, ╠²fake_key_4); multigetSliceQuery.setRange(, ╠², ╠²false, ╠²3); ResultRowsString, ╠²String, ╠²String ╠²result ╠²= ╠²multigetSliceQuery.execute(); 19 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 560. ļŗżņżæ
- 561. ╠²Ē¢ēņŚÉ
- 562. ╠²ļīĆĒĢ£
- 563. ╠²ņ▓śļ”¼
- 564. ╠²ņāśĒöī
- 565. ╠²3 /**
- 566. ╠²*
- 567. ╠²Getting
- 568. ╠²Multiple
- 569. ╠²Rows
- 570. ╠²with
- 571. ╠²RangeSlicesQuery
- 572. ╠²*/ RangeSlicesQueryString, ╠²String, ╠²String ╠²rangeSlicesQuery ╠²= HFactory.createRangeSlicesQuery(keyspace, ╠²stringSerializer, ╠²stringSerializer, ╠² stringSerializer); rangeSlicesQuery.setColumnFamily(Standard1); rangeSlicesQuery.setKeys(fake_key_0, ╠²fake_key_4); rangeSlicesQuery.setRange(, ╠², ╠²false, ╠²3); ResultOrderedRowsString, ╠²String, ╠²String ╠²result ╠²= ╠²rangeSlicesQuery.execute(); 20 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 573. ņé¼ņÜ®ņŗ£
- 575. ╠²Ēü┤ļלņŖż
- 576. ╠²ļé┤ņŚÉņä£
- 577. ╠²MapĒśĢĒā£ļĪ£
- 578. ╠²ļŹ░ņØ┤Ēä░ļź╝
- 580. ╠²ņéĮņ×ģ,
- 581. ╠²ņéŁņĀ£ņŗ£
- 582. ╠²ņé¼ņÜ®ļÉśļŖö
- 583. ╠²addInsertionņØ┤ļéś
- 585. ╠²MapņŚÉ
- 586. ╠²ļŹ░ņØ┤Ēä░ļź╝
- 588. ╠²ļ¬ģļĀ╣ņØä
- 590. ╠²ĒĢśĻ│Ā
- 591. ╠²MapņØä
- 593. ╠²ņé¼ņØ┤ņ”łņŚÉ
- 594. ╠²ļö░ļØ╝ņä£
- 595. ╠²ņĀüņĀłĒĢ£
- 596. ╠²execute()Ļ░Ć
- 597. ╠²ĒśĖņČ£ļÉśņ¦Ć
- 598. ╠²ņĢŖ ņØäļĢī
- 599. ╠²OOMļ░£ņāØņØ┤
- 600. ╠²Ļ░ĆļŖźĒĢ© 21 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝
- 601. JBoss
- 602. ╠²Community
- 604. ╠²JBoss
- 605. ╠²User
- 606. ╠²Group
- 607. ╠²(http://cafe.naver.com/jbossug) 22 13ļģä 6ņøö 18ņØ╝ ĒÖöņÜöņØ╝