NoSQL distilled ņÖ£ NoSQLņØĖĻ░Ć
3 likes1,605 views

NoSQL Distilled 1ņן ņÖ£ NoSQLņØĖĻ░Ć?












































More Related Content
What's hot (20)
Viewers also liked (20)







![[NoSQL] 2ņן. ņ¦æĒĢ®ņĀü ļŹ░ņØ┤Ēä░ ļ¬©ļŹĖ](https://cdn.slidesharecdn.com/ss_thumbnails/2-130323002448-phpapp02-thumbnail.jpg?width=560&fit=bounds)










Similar to NoSQL distilled ņÖ£ NoSQLņØĖĻ░Ć (20)




















More from Choonghyun Yang (20)




















NoSQL distilled ņÖ£ NoSQLņØĖĻ░Ć
- 1. NoSQL Distilled ņÖ£ NoSQLņØĖĻ░Ć? ╣«æņČ®╦│ä
- 3. ļÅäņĀäņ×É NoSQL ŌĆó ņĀłļīĆ Ļ░¢Ńģćņ×É Ļ┤ĆĻ│äĒśĢ DBņØś ņóģļ¦É? ŌĆó Ļ│╝ļīĆ Ļ┤æĻ│Ā?
- 4. NoSQLņØś ļ¦żļĀź ŌĆó ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģś Ļ░£ļ░£ ņāØņé░ņä▒ ŌĆō ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśĻ│╝ DB ņāüĒśĖ ņ×æņÜ® ļŗ©ņł£ĒÖö. ŌĆó ļīĆĻĘ£ļ¬© ļŹ░ņØ┤Ēä░ ŌĆō ņŚ¼ļ¤¼ļīĆļĪ£ ĻĄ¼ņä▒ļÉ£ Ēü┤ļ¤¼ņŖżĒä░ ĒÖśĻ▓Į.
- 5. Ļ┤ĆĻ│äĒśĢ DBņØś Ļ░Ćņ╣ś ŌĆó ļŹ░ņØ┤Ēä░ ņĀĆņן ŌĆō DBņØś ļ¬ģĒÖĢĒĢ£ Ļ░Ćņ╣śļŖö ļŹ░ņØ┤Ēä░ ļ│┤Ļ┤Ć. ŌĆō ĒīīņØ╝ ņŗ£ņŖżĒģ£ļ│┤ļŗż ļø░ņ¢┤ļé£ ņ£ĄĒåĄņä▒.
- 6. Ļ┤ĆĻ│äĒśĢ DBņØś Ļ░Ćņ╣ś ŌĆó ļÅÖņŗ£ņä▒Ļ│╝ ĒåĄĒĢ® ŌĆō ļŗżņłśņØś ņé¼ņÜ®ņ×ÉĻ░Ć ļÅÖņŗ£ņŚÉ ļŹ░ņØ┤Ēä░ļź╝ ļ│┤Ļ│Ā ņłśņĀĢ Ļ░ĆļŖź . ŌĆō ĒŖĖļ×Öņ×░ņģś ļ¦żņ╗żļŗłņ”ś. ŌĆō ņä£ļĪ£ ļŗżļźĖ ņ╗┤ĒåĀļäīĒŖĖĻ░ä ĒåĄĒĢ® DB Ļ│Ąņ£Ā.
- 7. Ļ┤ĆĻ│äĒśĢ DBņØś Ļ░Ćņ╣ś ŌĆó Ēæ£ņżĆ ļ¬©ļŹĖ ŌĆō ļ▓żļŹöĻ░Ć ļŗ¼ļØ╝ļÅä SQL ĻĄ¼ļČäņØĆ Ļ▒░ņØś ļ╣äņŖĘ. ŌĆō ĒŖĖļ×£ņףņģś ļÅÖņ×æ ņ░©ņØ┤ ņŚåņØī. ŌĆō ļ▓żĒä░Ļ░ä ĒĢĄņŗ¼ ļ®öņ╗żļŗłņ”ś Ļ░ÖņØī.
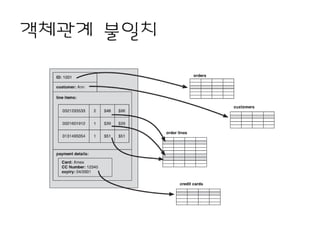
- 8. Ļ┤ĆĻ│äĒśĢ DBņØś ļČłļ¦ī ŌĆó Ļ░Øņ▓┤ Ļ┤ĆĻ│ä ļČłņØ╝ņ╣ś ŌĆō Ļ┤ĆĻ│äĒśĢ DBļŖö Ļ┤ĆĻ│äņÖĆ ĒŖ£ĒöīļĪ£ ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░ĒÖö. ŌĆō Ļ┤ĆĻ│äĒśĢ ĒŖ£ĒöīņĢłņØś Ļ░ÆņØĆ ļŗ©ņł£ĒĢ┤ņĢ╝ ĒĢ©. ŌĆō ņżæņ▓®ļÉ£ ļĀłņĮöļō£ļéś ļŗżļźĖ ĻĄ¼ņĪ░ļź╝ ĒżĒĢ© ĒĢĀ ņłś ņŚåņØī. ŌĆō Ļ░Øņ▓┤ ļé┤ ļŹ░ņØ┤Ēä░ ĻĄ¼ņĪ░ļŖö ļ│Ąņ×ĪĒĢ£ ĻĄ¼ņä▒. ŌĆō Ļ░Øņ▓┤ ņ¦ĆĒ¢ź DBņØś ļō▒ņןŌĆ” ĒĢśņ¦Ćļ¦ī ņŗżĒī©. ŌĆō Hibernate, iBATISņØś ĒöäļĀłņ×ä ņøīĒü¼ ļō▒ņן. ŌĆó DBļéś ņ┐╝ļ”¼ ņä▒ļŖźņŚÉ ļīĆĒĢ£ ņØ┤ņŖł
- 10. ĒåĄĒĢ® DB ŌĆó ņä£ļĪ£ ļŗżļźĖ componentĻ░ä Ļ│ĄĒåĄ DB ņé¼ņÜ®. ŌĆó ņØ╝Ļ┤ĆļÉ£ ļŹ░ņØ┤Ēä░ ļÅÖņ×æ, ņ╗żļ«żļŗłņ╝ĆņØ┤ņģś Ē¢źņāü. ŌĆó ĒåĄĒĢ®ņØĆ ņØĖĒĢ£ ļ│Ąņ×ĪĒĢ£ ĻĄ¼ņĪ░ ŌĆó ņåŹņä▒ ņČöĻ░ĆļĪ£ ņØĖĒĢ£ ĒāĆ component ņ┐╝ļ”¼ ņä▒ ļŖź ņĀĆĒĢś. ŌĆó ļŹ░ņØ┤Ēä░ ņĀĢĒĢ®ņä▒ ļ│┤ņן ļ¬╗ĒĢ©.
- 11. ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģś DB ŌĆó ļŗ©ņØ╝ componentĻ░Ć ĒĢśļéśņØś DB ņé¼ņÜ®. ŌĆó ņŖżĒéżļ¦ł ņ£Āņ¦Ćļ░Å Ļ░£ņäĀņØ┤ ņē¼ņøīņ¦É. ŌĆó ļŹ░ņØ┤Ēä░ņØś ņĀĢĒĢ®ņä▒ņØĆ ĒĢ┤ļŗ╣ componentĻ░Ć ņ▒ģ ņ×ä. ŌĆó Component ĒåĄĒĢ®ņØĆ SOA(Service Oriented Architecture).
- 12. Ēü┤ļ¤¼ņŖżĒä░ņØś Ļ│ĄĻ▓® ŌĆó 2000ļģäļīĆ ļōżņ¢┤ ļīĆĻĘ£ļ¬© ļŹ░ņØ┤Ēä░ ņ¦æĒĢ® ļō▒ņן ŌĆō ņø╣ņé¼ņØ┤ĒŖĖ ņé¼ņÜ®ņ×É ĒÖ£ļÅÖ ņČöņĀü ŌĆó ļ¦üĒü¼, ņåīņģ£, ļäżĒŖĖņøīĒü¼ ĒÖ£ļÅÖ ļĪ£ĻĘĖ, ļ¦żĒĢæ ļŹ░ņØ┤Ēä░. ŌĆó ļīĆĻĘ£ļ¬© ņé¼ņØ┤ĒŖĖļŖö ņŚäņ▓Łļé£ ņłśņØś ļ░®ļ¼Ėņ×ÉņŚÉĻ▓ī ņä£ļ╣äņŖż ņĀ£Ļ│Ą. ŌĆō ļŹ░ņØ┤Ēä░ņÖĆ ĒŖĖļלĒöĮ ņ”ØĻ░Ć ŌĆó ĒĢ┤Ļ▓░ļ░®ļ▓Ģ : ņłśĒÅē ĒÖĢņן, ņłśņ¦ü ĒÖĢņן
- 13. ņłśņ¦üĒÖĢņןĻ│╝ ņłśĒÅēĒÖĢņן ŌĆó ņłśņ¦üĒÖĢņן ŌĆō ņןļ╣äņŚÉ ļŹö ļ¦ÄņØĆ ĒöäļĪ£ņäĖņŖż, ļööņŖżĒü¼ ņŖżĒåĀļ”¼ņ¦Ć ļ░Å ļ®ö ļ¬©ļ”¼ ņןņ░®. ŌĆō ņŗżņ¦łņĀü ĒĢ£Ļ│ä ļ░Å Ļ░ĆĻ▓®ņØ┤ ļ╣äņīł. ŌĆó ņłśĒÅēĒÖĢņן ŌĆō Ļ░Æņŗ╝ ņןļ╣äļź╝ ļ¬©ņĢä Ēü┤ļ¤¼ņŖżĒä░ļĪ£ ĻĄ¼ņä▒. ŌĆō Ēü┤ļ¤¼ņŖżĒä░ ĻĄ¼ņä▒ņØĆ ļŗżņłśņØś ņןļ╣äņżæ ĒĢ£ļīĆĻ░Ć ņŗżĒī©ļÅä ņżæ ļŗ©ļÉśņ¦Ć ņĢŖņØī. ŌĆō Ļ┤ĆĻ│äĒśĢ DBļŖö ņ¦ĆņøÉĒĢśņ¦Ć ņĢŖņØī. ŌĆō ļ╣ģĒģīņØ┤ļĖöĻ│╝ ļŗżņØ┤ļéśļ¬© ļģ╝ļ¼Ė.
- 14. NoSQLņØś ņČ£Ēśä ŌĆó 1990ļģäļīĆ ņśżĒöł ņåīņŖż Ļ┤ĆĻ│äĒśĢ DBņØś ņØ┤ļ”äņ£╝ ļĪ£ ņ▓śņØī ļō▒ņן. ŌĆō ņĢäļ¼┤ļ¤░ ņśüĒ¢źņØä ļü╝ņ╣śņ¦Ć ļ¬╗ĒĢ©. ŌĆó Ēśäņ×¼ NoSQL ņÜ®ņ¢┤ņØś ĻĖ░ņøÉņØĆ ļ╣äĻ│ĄņŗØ ļ¬©ņ×äņØś ņØ┤ļ”ä(2009ļģä) ŌĆō ņāłļĪ£ņÜ┤ DBļź╝ ņĢīĻ│Ā ņŗČņ¢┤ ĒĢśļŖö ļ¬©ņ×ä. ŌĆō ļ│╝ļō£ļ¬©ĒŖĖ,ņ╣┤ņé░ļō£ļØ╝,ļŗżņØ┤ļģĖļ¦łņØ┤ĒŖĖ,Hļ▓ĀņØ┤ņŖż,ĒĢś ņØ┤ĒŹ╝ĒģīņØ┤ļĖö,ņ╣┤ņÜ░ņ╣ś DB,ļ¬ĮĻ│Ā DBĻ░Ć ņ░ĖņŚ¼.
- 15. NoSQLņØ┤ļ×Ć? ŌĆó SQLņØä ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖņØī. ŌĆō ņØ╝ļČĆ SQLņØĆ ņ¦łņØśņ¢┤ ņ¦ĆņøÉ. ŌĆó ņśżĒöł ņåīņŖż ĒöäļĪ£ņĀØĒŖĖ. ŌĆó ļīĆļČĆļČä Ēü┤ļ¤¼ņŖżĒä░ ĒÖśĻ▓ĮņŚÉņä£ ņŗżĒ¢ēĒĢĀ ļ¬®ņĀü. ŌĆó Not Only SQL = NOSQL != NoSQL
- 16. NoSQLņØś ĻĖ░ļ│Ė Ļ░£ļģÉ ŌĆśA Bigtable is a sparse, distributed, persistent, multidimensional, sorted map.ŌĆÖ ŌĆó Map ŌĆó ņśüĻĄ¼ņĀüņØ┤ļŗż. ŌĆó ļČäņé░ĻĖ░ļ░śņØ┤ļŗż. ŌĆó ņĀĢļĀ¼ĻĖ░ļŖź. ŌĆó ļŗżņ░©ņøÉņĀüņØ┤ļŗż. ŌĆó ņŚēņä▒ĒĢśļŗż.